
MapReduce编程模型-单词统计处理
要想使用Hadoop的MapReduce,必须将进行统计的文件内容保存到HDFS中
对于MapReduce而言,实际上是属于两个层次的概念:
◎Map阶段:对数据的处理阶段
◎Reduce阶段:对处理后的数据进行计算
范例:定义一个要进行统计的原始文件
|
Hello MLDN Hello Yootk Hello Bye Bye Bye Hello MLDN |
处理流程如下:
|
Map处理 |
排序处理 |
合并处理 |
Reduce处理 |
|
<Hello,1> <MLDN,1> <Hello,1> <Yootk,1> <Hello,1> <Bye,1> <Bye,1> <Bye,1> <Hello,1> <MLDN,1> |
<Bye,1> <Bye,1> <Bye,1> <Hello,1> <Hello,1> <Hello,1> <Hello,1> <MLDN,1> <MLDN,1> <Yootk,1> |
<Bye,1,1,1> <Hello,1,1,1,1> <MLDN,1,1> <Yootk,1> |
<Bye,3> <Hello,4> <MLDN,2> <Yootk,1> |
整个的操作称为一个完整的作业“Job”
要进行代码编写需要使用Hadoop中提供的*.jar文件(hadoop-2.7.2\share\hadoop)
需要配置如下几个路径的开发包:
◎common组件包
○hadoop-2.7.2\share\hadoop\common
○hadoop-2.7.2\share\hadoop\common\lib
◎mapreduce组件包
○hadoop-2.7.2\share\hadoop\mapreduce
○hadoop-2.7.2\share\hadoop\mapreduce\lib
然后将程序打包成jar文件,名称为yootk.jar
不要忘记设置一个程序执行的主类
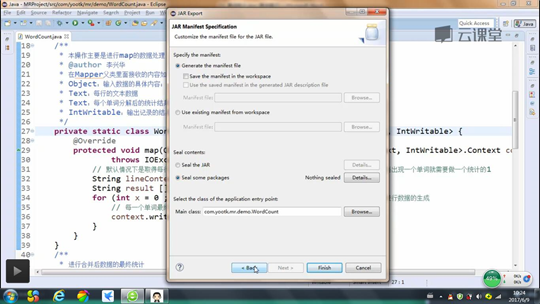
随后利用ftp将yootk.jar文件上传到Linux服务器中
在HDFS上建立一个input文件夹,同时将保存一个文件到此文件夹中
范例:在hdfs上创建一个input的文件目录
|
hadoop fs -mkdir /input |
|
(查看)hadoop fs -ls / |
范例:建立一个文件,直接利用vi处理
|
vi mldn.txt |

范例:将此文件保存在HDFS中的“/input”目录之中
|
hadoop fs -put mldn.txt /input |
范例:查看文件内容确定是否成功
|
hadoop fs -cat /input/mldn.txt |
随后进入到yootk.jar文件所在的路径,执行jar文件
|
cd /srv/ftp |
|
hadoop jar yootk,jar /input/mldn.txt /output |
注:执行的时候需要保证output目录在HDFS上不存在
执行完成之后可以查看HDFS中/output目录下的内容
|
hadoop fs -ls /output |
范例:查看输出的文件内容
|
hadoop fs -cat /output/part-r-00000 |

