
mysql 数据存储引擎区别
一,存储类型
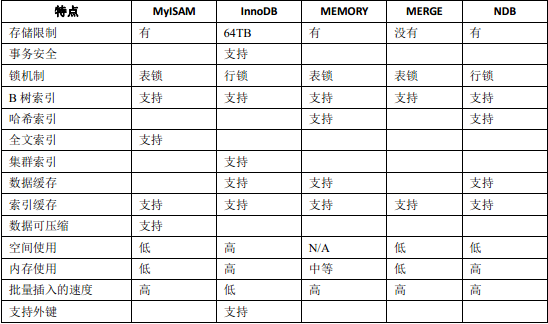
二 , MyISAM默认存储引擎
特性:
应用场景:
调优精要:
存储:
三 , innodb存储引擎
什么是InnoDB引擎?
InnoDB引擎是MySQL数据库的另一个重要的存储引擎,正成为目前MySQL AB所发行的新版的标准,被包含在所有二进制安装包里,和其他存储引擎相比,InnoDB引擎的优点是支持兼容ACID的事务(类似于PostgreSQL),以及参数完整性(有外键)等.现在Innobase实行双认证授权.MySQL5.5.5以后默认的存储引擎都是InnoDB引擎.
InnoDB的引擎特点.
1).支持事务(事务是指逻辑上的一组操作,组成这组操作的各个单元,要么全成功,要么全失败)
2).行级锁定(更新时一般是锁定当前行):通过索引实现,全表扫描仍然会是锁定整个表,注意间隙锁的影响.
3).读写阻塞与事务隔离级别相关.
4).具有非常高效的缓存特性,能缓存索引,也能缓存数据.
5).整个表和主键以Cluster方式存储,组成一颗平衡树.
6).所有Secondary Index 都会保存主键信息.
7).支持分区,表空间.类似于Oracle数据库.
8).支持外键约束,不支持全文索引,5.5之前支持,后面不再支持.
9).和MyISAM相比,InnoDB对于硬件资源要求比较高.
InnoDB引擎的适用的生产场景
1).需要支持事务的业务(例如转账,付款)
2).行级锁定对于高并发有很好的适应能力,但是需要保证查询是通过索引完成.
3).数据读写及更新都比较频繁的场景,如:BBS,SNS,微博,微信等.
4).数据一致性要求很高的业务.如:转账,充值等.
5).硬件设备内存较大,可以很好利用InnoDB较好的缓存能力来提高内存利用率,尽可能减少磁盘IO的开销.
InnoDB引擎调优精要:
1).主键尽可能小,避免给Secondary index带来过大的空间负担.
2).避免全表扫描,因为会使用表锁.
3).尽可能缓存所有的索引和数据,提高响应速度,减少磁盘IO消耗.
4).在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交,有开关参数可以控制提交.
5).合理设置Innodb_flush_log_at_trx_commit 参数值,不要过度追求安全性.
如果Innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件进入磁盘,提交事务的时候不做任何操作.
6).避免主键更新,因为这会带来大量的数据移动.
存储方式
1) 使用共享空间存储,这种方式创建的表的表结保存在.frm文件中, 数据和索引保存在innodb_data_home_dir和innodb_data_file_path定义的表的空间, 可以是多个文件
2) 使用多表空间存储, 这种方式创建的表的表结构任然保存在.frm文件中,但是每一个表的数据和缩影单独保存在.idb中,如果是个分区表,则每个分区对应单独的.idb文件,文件名是表明+分区名,可以创建分区的时间指定每个分区的数据文件的位置每一次将表的IO均匀分布在多个磁盘
四 , memory存储引擎
memoery存储引擎是在内存中来创建表,每个memory表只实际对应一个磁盘文件格式是.frm. 该引擎的表访问非常得快,因为数据是放在内存中,且默认是hash索引,但服务关闭,表中的数据就会丢失掉。
下面创建一个memory表,并从city表获得记录:
CREATE TABLE tab_memory ENGINE=MEMORY SELECT city_id,country_id FROM city GROUP BY city_id
给momory 表创建索引时,可以指定是hash索引还是btree索引
CREATE INDEX mem_hash USING HASH ON tab_memory(city_id); SHOW INDEX FROM tab_memory
DROP INDEX mem_hash ON tab_memory; CREATE INDEX mem_hash USING BTREE ON tab_memory(city_id) SHOW INDEX FROM tab_memory
服务器需要足够的内存来维护所有在同一时间使用的memory表,当不再需要时,要释放,应执行 delete from 或 truncate table 或删除表drop table。
每个memory表放置的数据量大小,受到max_heap_table_size系统变量的约束,初始值是16MB. 通过max_rows 子句指定表的最大行数。
memory类型 一般应用于临时表,如统计操作的中间结果表。
五,merge存储引擎
merge 引擎是一组MyISAM表的组合,这些MYISAM表必须结构完全相同,merge表本身并没有数据,对表的增删改查 实际是对内部的myisam表进行操作。
对于merge类型表的插入操作有三种类型:first是插入在第一个表,last是插入到最后一个表,不定义或为NO表示不能对merge表执行插入操作,对于merge表的drop操作,内部的表没有任何影响。merge 在磁盘上保留两个文件,一个是.frm文件存储表定义,另一个是.mrg文件包含组合表的信息。
下面来测试下,创建三个结构相同的表 payment_2006,payment_2007,payment_all(merge类型)。
CREATE TABLE payment_2006( country_id SMALLINT, payment_date DATETIME, amount DECIMAL(15,2), KEY inx_fx_country_id (country_id) )ENGINE =MYISAM CREATE TABLE payment_2007( country_id SMALLINT, payment_date DATETIME, amount DECIMAL(15,2), KEY inx_fx_country_id (country_id) )ENGINE =MYISAM CREATE TABLE payment_all( country_id SMALLINT, payment_date DATETIME, amount DECIMAL(15,2), INDEX (country_id) )ENGINE =MERGE UNION=(payment_2006,payment_2007) INSERT_METHOD=LAST;
分别向payment_2006和payment_2007表插入数据
INSERT INTO payment_2006 VALUES(1,'2006-05-01',100000),(2,'2006-08-01',150000); INSERT INTO payment_2007 VALUES(1,'2007-05-01',200000),(2,'2007-08-01',350000);
查询payment_all
SELECT * FROM payment_all;
六,四个的区别与选择
myisam: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性,并发性要求不是很高,例如数据仓储。
innodb: 用于事务处理应用程序,支持外键,对事务的完整性较高,并发条件下数据一致性,包括很多的更新和删除操作,它能避免删除和更新导致的锁定,还提供了提交和回滚,例如计算费用对数据准确性要求高的。
memory: 数据保存在ram(内存)中,访问速度快,但对表的大小有限制,要确保数据是可以恢复的,常用于更新不太频繁的小表,用以快速访问。
merge: 它是myisam表以逻辑方式组合的引擎,将myisam表分布在多个磁盘上,可以有效改善merge表的访问效率。例如数据仓储等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号