
linux运维基础之跟我一起学正则表达式(一)
正则表达式
一,
1) 什么是正则表达式
正则表达式又称为规则表达式
正则表达式是一个计算机的一个概念
正则表达式为了处理大量的文本|字符串而定义的一套规则和方法,通常被用来检索,替换那些符合摸个模式规则的文本
2)为何使用正则表达式
linux运维工作,大量操作命令,化繁为简。
正则表达式高级工具:支持三剑客 ---慢慢来后面讲
二,
正则表达式从入门到入狱,从删库到跑路
********************************************************************************************************
dos 通配符:
*:任意的字符串
(你要寻找摸个目录下的txt文件,泥就可以输入*.txt,表示目录下所有带.txt的文件)
?: 代替任意单个字符
(你可能输入单词会突然有一个字母记不住或者多个,你就可以he??o,这样就能搜索到很多hello,heqwo,heoko等等只要那两个字母不同就能匹配)
正则表达式-->
\b 代表着单词的开头和结尾-->搜索单词的时候在单词的开头结尾输入\b
eg:你要精确搜索hello --> \bhello\b
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
***********************************************************************************************************
(1)连续次数的匹配
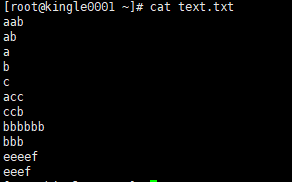
模拟环境内容
什么叫连续匹配次数呢?就是匹配单个次数内容多个
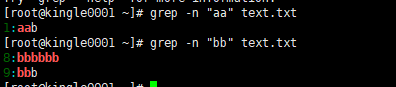
要匹配两个字符的时候用grep搜索,但是如果要匹配10个呢??100个??你会一直输入100个字符吗??那肯定行不通的。所以我们就引进一个{n}需要匹配的次数。
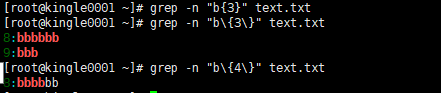
斜杆是转义字符:你想匹配多少个b就写多大就行啦。
这个匹配会吧含有更多的内容输出如果你只想匹配当前个数的话可以用<>

但是突然你想要匹配3到5个b的内容呢??哎呀真会出题。
不知道聪明的人有没有想到{n,m}意思就是至少n,至多m。

所以引申出来了{,m}表示至多m,至少0
我们再来认识下*
表示匹配前一个字符任意次数

任意次的话也包括零次,只要是a或者ab就会被匹配

天天匹配这么多肯定没意思啊
我们来认识下\? \+
\? 表示匹配其前面字符0次或者一次,就是要么没有要么一次
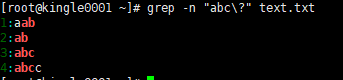
\+ 表示匹配前面的字符至少一次,也就是必须有一个字符

但是必须有一个呢,他也可以有多个。上不封顶呢。
. 表示匹配任意的单个字符
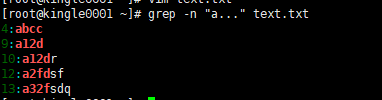
图中已显示了a后面匹配了三个字符及以上的内容,不明白的话滴滴我
这里可以看出匹配的字符里面还有数字,你可能用到的是子需要匹配字母在正则表达式上字母表达为[[:alpha:]]

所以这样就会帮你匹配到纯字母的内容
如果你还觉得这个不苛刻的话不妨还要来个匹配的是小写字母:[[:lower:]]
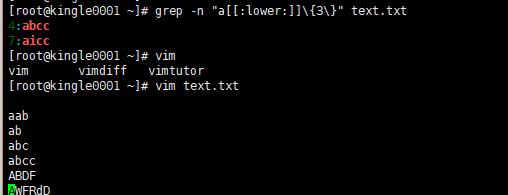
为了编译环境零时添加的,你可以尝试上一个命令,看匹配的内容
然后加入需要匹配大写字母的话: [[:upper:]]

好了剩余内容就大家自己测试啦:
[[:alpha:]] 表示任意大小的字母
[[:lower:]] 表示小写字母
[[:upper:]] 表示任意大写字母
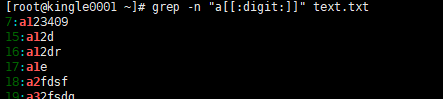
[[:digit:]] 表示0到9之间的任意数字
[[:alnum:]] 表示任意数字和字母
[[:space:]] 表示任意空白字符包括空格 tab键
[[:punct:]] 表示任意标点符号
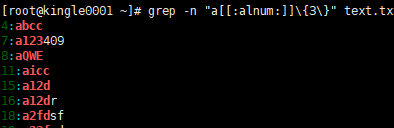



最后一个仅匹配A-Z以内的大写字母
所以引申出 [ ] 里面 匹配指定范围内的任意字符 ,但一般都是匹配一个字符

[^ ] 大家来看下这个呢??你是不是会觉得什么锚钉头部??
不是的啦,,这个表示指定范围外的单个字符,,与 [ ] 相反

这个东西与上面所得[^[:lower:]] 这样也可以用 都能用

\d 也是表示数字的哦,,单个数字不行测试下唉
这个字符总结在最上面啦,,,,,,不愿意翻??我给你cp了啊
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ |
匹配字符串的结 |
| \D | 表示任意单个非数字字符 |
| \t | 表示匹配单个横向字符就是相当于tab键 |
| \S | 表示匹配非空白字符 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号