
GreenPlum 大数据平台--并行备份(四)
01,并行备份(gp_dump)
1) GP同时备份Master和所有活动的Segment实例
2) 备份消耗的时间与系统中实例的数量没有关系
3) 在Master主机上备份所有DDL文件和GP相关的数据字典表
4) 每个Segment备份各自的数据
5) 所有备份文件组成一个完整的备份集合,通过唯一14位数字的时间戳来识别
gp_dump dumps a database as a text file or to other formats. Usage: gp_dump [OPTION]... [DBNAME] General options: -i, --ignore-version proceed even when server version mismatches gp_dump version -v, --verbose verbose mode. adds verbose information to the per segment status files --help show this help, then exit --version output version information, then exit Options controlling the output content: -a, --data-only dump only the data, not the schema -c, --clean clean (drop) schema prior to create -d, --inserts dump data as INSERT, rather than COPY, commands -D, --column-inserts dump data as INSERT commands with column names -E, --encoding=ENCODING dump the data in encoding ENCODING -n, --schema=SCHEMA dump the named schema only -N, --exclude-schema=SCHEMA do NOT dump the named schema(s) -o, --oids include OIDs in dump -O, --no-owner do not output commands to set object ownership in plain text format -s, --schema-only dump only the schema, no data -S, --superuser=NAME specify the superuser user name to use in plain text format -t, --table=TABLE dump only matching table(s) (or views or sequences) -T, --exclude-table=TABLE do NOT dump matching table(s) (or views or sequences) -x, --no-privileges do not dump privileges (grant/revoke) --disable-triggers disable triggers during data-only restore --incremental dump only modified patitions --use-set-session-authorization use SESSION AUTHORIZATION commands instead of ALTER OWNER commands to set ownership Connection options: -h, --host=HOSTNAME database server host or socket directory -p, --port=PORT database server port number -U, --username=NAME connect as specified database user -W, --password force password prompt (should happen automatically) Greenplum Database specific options: --gp-c use gzip for in-line compression --gp-d=BACKUPFILEDIR directory where backup files are placed --gp-k=TIMESTAMP timestamp key to be used for the dump files --gp-r=REPORTFILEDIR directory where report file is placed --gp-s=BACKUPSET backup set indicator - (p)rimaries only (default) or (i)ndividual segdb (must be followed with a list of dbids of primary segments to dump. For example: --gp-s=i[10,12,14] --rsyncable pass --rsyncable option to gzip --ddboost-storage-unit pass the storage unit name If no database name is supplied, then the PGDATABASE environment variable value is used.
我们来看下具体备份:
创建备份目录(所有节点): mkdir -p /gpbackup chown -R gpadmin. /gpbackup/ 如果报错了: 20190319:02:54:01|gp_dump-[FATAL]:-could not start Greenplum Database backup: ERROR: could not create backup directory "/gpbackup/": Permission denied 那应该就是没创建好,或者没有授权,所有几点重新操作 备份开始: [gpadmin@greenplum01 gpseg-1]$ gp_dump -h 192.168.0.221 -p 5432 -U gpadmin -d postgres --gp-d /gpbackup/ --gp-r /gpbackup/ --inserts is preferred over -d. -d is deprecated. 20190319:03:00:20|gp_dump-[INFO]:-Read params: -d 20190319:03:00:20|gp_dump-[INFO]:-Command line options analyzed. 20190319:03:00:20|gp_dump-[INFO]:-Connecting to master database on host 192.168.0.221 port 5432 database postgres. 20190319:03:00:20|gp_dump-[INFO]:-Reading Greenplum Database configuration info from master database. 20190319:03:00:20|gp_dump-[INFO]:-Preparing to dump the following segments: 20190319:03:00:20|gp_dump-[INFO]:-Segment 7 (dbid 9) 20190319:03:00:20|gp_dump-[INFO]:-Segment 6 (dbid 8) 20190319:03:00:20|gp_dump-[INFO]:-Segment 5 (dbid 7) 20190319:03:00:20|gp_dump-[INFO]:-Segment 4 (dbid 6) 20190319:03:00:20|gp_dump-[INFO]:-Segment 3 (dbid 5) 20190319:03:00:20|gp_dump-[INFO]:-Segment 2 (dbid 4) 20190319:03:00:20|gp_dump-[INFO]:-Segment 1 (dbid 3) 20190319:03:00:20|gp_dump-[INFO]:-Segment 0 (dbid 2) 20190319:03:00:20|gp_dump-[INFO]:-Master (dbid 1) 20190319:03:00:20|gp_dump-[INFO]:-Starting a transaction on master database postgres. 20190319:03:00:20|gp_dump-[INFO]:-Getting a lock on pg_class in database postgres. 20190319:03:00:20|GetTimestampKey-[INFO]:-Timestamp key is generated as it is not provided by the user. 20190319:03:00:20|gp_dump-[INFO]:-About to spin off 9 threads with timestamp key 20190319030020 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 9: host greenplum03 port 6003 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 8: host greenplum03 port 6002 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 7: host greenplum03 port 6001 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 6: host greenplum03 port 6000 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 5: host greenplum02 port 6003 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 4: host greenplum02 port 6002 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 3: host greenplum02 port 6001 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 2: host greenplum02 port 6000 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Creating thread to backup dbid 1: host greenplum01 port 5432 database postgres 20190319:03:00:20|gp_dump-[INFO]:-Waiting for remote gp_dump_agent processes to start transactions in serializable isolation level 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 1 connection 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 7 connection 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 5 connection 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 3 connection 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 7 server 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 5 server 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 3 server 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 9 connection 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 9 server 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 8 connection 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 8 server 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 4 connection 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 2 connection 20190319:03:00:20|gp_dump-[INFO]:-Listening for messages from server on dbid 6 connection 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 4 server 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 6 server 20190319:03:00:20|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 2 server 20190319:03:00:22|gp_dump-[INFO]:-Successfully launched Greenplum Database backup on dbid 1 server 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 1 on host greenplum01 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 9 on host greenplum03 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 7 on host greenplum03 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 6 on host greenplum03 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 8 on host greenplum03 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 2 on host greenplum02 20190319:03:00:22|gp_dump-[INFO]:-All remote gp_dump_agent processes have began transactions in serializable isolation level 20190319:03:00:22|gp_dump-[INFO]:-Waiting for remote gp_dump_agent processes to obtain local locks on dumpable objects 20190319:03:00:22|gp_dump-[INFO]:-All remote gp_dump_agent processes have obtains the necessary locks 20190319:03:00:22|gp_dump-[INFO]:-Committing transaction on the master database, thereby releasing locks. 20190319:03:00:22|gp_dump-[INFO]:-Waiting for all remote gp_dump_agent programs to finish. 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 5 on host greenplum02 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 3 on host greenplum02 20190319:03:00:22|gp_dump-[INFO]:-backup succeeded for dbid 4 on host greenplum02 20190319:03:00:22|gp_dump-[INFO]:-All remote gp_dump_agent programs are finished. 20190319:03:00:22|gp_dump-[INFO]:-Report results also written to /gpbackup/gp_dump_20190319030020.rpt. Greenplum Database Backup Report Timestamp Key: 20190319030020 gp_dump Command Line: -h 192.168.0.221 -p 5432 -U gpadmin -d postgres --gp-d /gpbackup/ --gp-r /gpbackup/ Pass through Command Line Options: -d Compression Program: None Backup Type: Full Individual Results segment 7 (dbid 9) Host greenplum03 Port 6003 Database postgres BackupFile /gpbackup/gp_dump_7_9_20190319030020: Succeeded segment 6 (dbid 8) Host greenplum03 Port 6002 Database postgres BackupFile /gpbackup/gp_dump_6_8_20190319030020: Succeeded segment 5 (dbid 7) Host greenplum03 Port 6001 Database postgres BackupFile /gpbackup/gp_dump_5_7_20190319030020: Succeeded segment 4 (dbid 6) Host greenplum03 Port 6000 Database postgres BackupFile /gpbackup/gp_dump_4_6_20190319030020: Succeeded segment 3 (dbid 5) Host greenplum02 Port 6003 Database postgres BackupFile /gpbackup/gp_dump_3_5_20190319030020: Succeeded segment 2 (dbid 4) Host greenplum02 Port 6002 Database postgres BackupFile /gpbackup/gp_dump_2_4_20190319030020: Succeeded segment 1 (dbid 3) Host greenplum02 Port 6001 Database postgres BackupFile /gpbackup/gp_dump_1_3_20190319030020: Succeeded segment 0 (dbid 2) Host greenplum02 Port 6000 Database postgres BackupFile /gpbackup/gp_dump_0_2_20190319030020: Succeeded Master (dbid 1) Host greenplum01 Port 5432 Database postgres BackupFile /gpbackup/gp_dump_-1_1_20190319030020: Succeeded Master (dbid 1) Host greenplum01 Port 5432 Database postgres BackupFile /gpbackup/gp_dump_-1_1_20190319030020_post_data: Succeeded gp_dump utility finished successfully. [gpadmin@greenplum01 gpseg-1]$
02,并行备份(gpbackup)
将数据库的内容备份到元数据文件和数据文件的集合中,这些文件和数据文件可用于以后使用它来还原数据库 gprestore。默认情况下, gpbackup备份指定数据库中的对象以及全局Greenplum数据库系统对象。您可以选择提供-globals 选项 gprestore恢复全局对象.
gpbackup默认情况下,将对象元数据文件和DDL文件存储在Greenplum数据库主数据目录中。Greenplum数据库细分使用复制..关于部分命令将备份表的数据存储在位于每个段的数据目录中的压缩CSV数据文件中。
你可以添加 -backupdir选项将所有备份文件从Greenplum数据库主节点和段主机复制到绝对路径以供以后使用。提供了其他选项来过滤备份集以包含或排除特定表。
每 gpbackup任务在Greenplum数据库主控主机上使用单个事务。为每个段主机创建实用程序模式连接,以执行关联复制..关于部分并行运作。备份过程获取访问分享 锁定备份的每个表。
gpbackup如果您将名为mail_contacts的文件放在 Greenplum数据库超级用户(gpadmin)的主目录中或与该目录相同的目录中,则会在备份操作完成后发送状态电子邮件通知 gpbackup实用程序($ GPHOME / bin)
参数:
gpbackup is the parallel backup utility for Greenplum Usage: gpbackup [flags] Flags: --backup-dir string The absolute path of the directory to which all backup files will be written --compression-level int Level of compression to use during data backup. Valid values are between 1 and 9. (default 1) --data-only Only back up data, do not back up metadata --dbname string The database to be backed up --debug Print verbose and debug log messages --exclude-schema strings Back up all metadata except objects in the specified schema(s). --exclude-schema can be specifiedmultiple times. --exclude-table strings Back up all metadata except the specified table(s). --exclude-table can be specified multiple times. --exclude-table-file string A file containing a list of fully-qualified tables to be excluded from the backup --from-timestamp string A timestamp to use to base the current incremental backup off --help Help for gpbackup --include-schema strings Back up only the specified schema(s). --include-schema can be specified multiple times. --include-table strings Back up only the specified table(s). --include-table can be specified multiple times. --include-table-file string A file containing a list of fully-qualified tables to be included in the backup --incremental Only back up data for AO tables that have been modified since the last backup --jobs int The number of parallel connections to use when backing up data (default 1) --leaf-partition-data For partition tables, create one data file per leaf partition instead of one data file for the whole table --metadata-only Only back up metadata, do not back up data --no-compression Disable compression of data files --plugin-config string The configuration file to use for a plugin --quiet Suppress non-warning, non-error log messages --single-data-file Back up all data to a single file instead of one per table --verbose Print verbose log messages --version Print version number and exit --with-stats Back up query plan statistics


1 -dbname database_name 2 需要。指定要备份的数据库。 3 -backupdir 目录 4 可选的。将所有必需的备份文件(元数据文件和数据文件)复制到指定的目录。您必须将目录指定为绝对路径(不是相对路径)。如果您不提供此选项,则会在$ MASTER_DATA_DIRECTORY / backups / YYYYMMDD / YYYYMMDDhhmmss / 目录中的Greenplum Database主机上创建元数据文件 。段主机在<seg_dir> / backups / YYYYMMDD / YYYYMMDDhhmmss /目录中创建CSV数据文件 。指定自定义备份目录时,会将文件复制到备份目录的子目录中的这些路径。 5 -data只 6 可选的。仅将表数据备份到CSV文件中,但不备份重新创建表和其他数据库对象所需的元数据文件。 7 -debug 8 可选的。在操作期间显示详细的调试消息。 9 -exclude-schema schema_name 10 可选的。指定要从备份中排除的数据库模式。您可以多次指定此选项以排除多个模式。您无法将此选项与-include-模式选项。有关详细信息,请参阅筛选备份的内容。 11 -exclude-table-file file_name 12 可选的。指定包含要从备份中排除的表列表的文本文件。文本文件中的每一行都必须使用该格式定义一个表 <模式名称> <表名>。该文件不得包含尾随行。如果表或模式名称使用小写字母,数字或下划线字符以外的任何字符,则必须在双引号中包含该名称。 13 您不能结合使用此选项 -leaf分区数据。虽然您可以在指定的文件中指定叶子分区名称 -exclude表文件, gpbackup 忽略分区名称。 14 有关 详细信息,请参阅筛选备份的内容。 15 -include-schema schema_name 16 可选的。指定要包括在备份中的数据库模式。您可以多次指定此选项以包含多个模式。如果指定此选项,则后续未包含的任何模式-include-模式备份集中省略了选项。您无法将此选项与 -exclude-模式选项。有关详细信息,请参阅筛选备份的内容。 17 -include-table-file file_name 18 可选的。指定包含要包括在备份中的表列表的文本文件。文本文件中的每一行都必须使用该格式定义一个表 <模式名称> <表名>。该文件不得包含尾随行。如果表或模式名称使用小写字母,数字或下划线字符以外的任何字符,则必须在双引号中包含该名称。备份集中将省略此文件中未列出的任何表。 19 您可以选择指定表叶子分区名称来代替表名称,以便在备份中仅包含特定叶子分区 -leaf分区数据 选项。 20 有关 详细信息,请参阅筛选备份的内容。 21 --leaf-partition-data 22 可选的。对于分区表,为每个叶子分区创建一个数据文件,而不是为整个表创建一个数据文件(默认值)。使用此选项还可以指定要包含在备份中的单个叶子分区 -include表文件选项。您不能结合使用此选项-exclude表文件。 23 --metadata-only 24 可选的。仅创建重新创建数据库对象所需的元数据文件(DDL),但不备份实际的表数据。 25 --no-compression 26 可选的。不要压缩表数据CSV文件。 27 --quiet 28 可选的。禁止所有非警告,非错误日志消息。 29 -verbose 30 可选的。打印详细日志消息。 31 --version 32 可选的。打印版本号并退出。 33 --with-stats 34 可选的。在备份集中包含查询计划统计信息。
实例说明:
[gpadmin@greenplum01 gpbackup]$ gpbackup -dbname postgres 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Starting backup of database postgres 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Backup Timestamp = 20190319032758 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Backup Database = postgres 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Gathering table state information 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Acquiring ACCESS SHARE locks on tables Locks acquired: 16 / 16 [==============================================================] 100.00% 0s 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Gathering additional table metadata 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Metadata will be written to /greenplum/data/master/gpseg-1/backups/20190319/20190319032758/gpbackup_20190319032758_metadata.sql 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Writing global database metadata 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Global database metadata backup complete 20190319:03:27:58 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Writing pre-data metadata 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Pre-data metadata backup complete 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Writing post-data metadata 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Post-data metadata backup complete 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Writing data to file Tables backed up: 14 / 14 [============================================================] 100.00% 0s 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Skipped data backup of 2 external/foreign table(s). 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-See /home/gpadmin/gpAdminLogs/gpbackup_20190319.log for a complete listof skipped tables. 20190319:03:27:59 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Data backup complete 20190319:03:28:00 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Found neither /usr/local/greenplum-db/./bin/gp_email_contacts.yaml nor /home/gpadmin/gp_email_contacts.yaml 20190319:03:28:00 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Email containing gpbackup report /greenplum/data/master/gpseg-1/backups/20190319/20190319032758/gpbackup_20190319032758_report will not be sent 20190319:03:28:00 gpbackup:gpadmin:greenplum01:018033-[INFO]:-Backup completed successfully
指定目录备份:
[gpadmin@greenplum01 gpbackup]$ gpbackup -dbname demo --backup-dir /gpbackup/back1/ 20190319:03:31:51 gpbackup:gpadmin:greenplum01:018642-[INFO]:-Starting backup of database demo 20190319:03:31:51 gpbackup:gpadmin:greenplum01:018642-[CRITICAL]:-FATAL: database "demo" does not exist (SQLSTATE 3D000) [gpadmin@greenplum01 gpbackup]$ gpbackup -dbname gpdb --backup-dir /gpbackup/back1/ 20190319:03:32:01 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Starting backup of database gpdb 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Backup Timestamp = 20190319033201 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Backup Database = gpdb 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Gathering table state information 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Acquiring ACCESS SHARE locks on tables 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Gathering additional table metadata 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[WARNING]:-No tables in backup set contain data. Performing metadata-only backup instead. 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Metadata will be written to /gpbackup/back1/gpseg-1/backups/20190319/20190319033201/gpbackup_20190319033201_metadata.sql 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Writing global database metadata 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Global database metadata backup complete 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Writing pre-data metadata 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Pre-data metadata backup complete 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Writing post-data metadata 20190319:03:32:02 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Post-data metadata backup complete 20190319:03:32:03 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Found neither /usr/local/greenplum-db/./bin/gp_email_contacts.yaml nor /home/gpadmin/gp_email_contacts.yaml 20190319:03:32:03 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Email containing gpbackup report /gpbackup/back1/gpseg-1/backups/20190319/20190319033201/gpbackup_20190319033201_report will not be sent 20190319:03:32:03 gpbackup:gpadmin:greenplum01:018677-[INFO]:-Backup completed successfully [gpadmin@greenplum01 gpbackup]$
[gpadmin@greenplum01 gpbackup]$ ll /gpbackup/back1/gpseg-1/backups/20190319/20190319033201/ total 16 -r--r--r-- 1 gpadmin gpadmin 550 Mar 19 03:32 gpbackup_20190319033201_config.yaml -r--r--r-- 1 gpadmin gpadmin 2377 Mar 19 03:32 gpbackup_20190319033201_metadata.sql -r--r--r-- 1 gpadmin gpadmin 1452 Mar 19 03:32 gpbackup_20190319033201_report -r--r--r-- 1 gpadmin gpadmin 3164 Mar 19 03:32 gpbackup_20190319033201_toc.yaml [gpadmin@greenplum01 gpbackup]$
03,gpcrondump
gpcrondump 实用程序将数据库的内容转储为SQL脚本文件,然后可以使用它们在以后使用它来还原数据库架构和用户数据 gpdbrestore。在转储操作期间,用户仍将具有对数据库的完全访问权限。
默认情况下,转储文件在其各自的主数据目录和段数据目录中的名称中创建 db_dumps /YYYYMMDD。默认使用压缩数据转储文件gzip的。
该实用程序备份服务器配置参数的数据库级设置 gp_default_storage_options, 优化,和SEARCH_PATH。使用时还原数据库时,将恢复设置gpdbrestore 实用程序并指定 -e 在执行还原操作之前创建空目标数据库的选项。
如果指定备份模式的选项,例如 -s, 要么 -S,即使它们不是特定于模式,也会备份数据库中定义的所有过程语言。备份语言以支持可能备份的任何功能。不备份外语项,例如语言使用的共享库。此外,如果指定仅备份表的选项,则不会备份语言,例如-t, -T。
备份操作完成后,该实用程序将检查 gpcrondump SQL执行错误的状态文件,如果发现错误则显示警告。备份状态文件的默认位置在 db_dumps / date / 目录。
如果指定包含或排除表或模式的选项,例如 -t, -T, -s, 要么 -S,备份表的模式限定名称列在文件中 gp_dump_ timestamp _table。该文件存储在主段的备份目录中。
gpcrondump 允许您使用安排Greenplum数据库的例行备份 cron的(UNIX操作系统的调度实用程序)。叫Cron的工作gpcrondump 应该在主控主机上安排。
注意:
Backing up a database with gpcrondump while simultaneously running ALTER TABLE might cause gpcrondump to fail. Backing up a database with gpcrondump while simultaneously running DDL commands might cause issues with locks. You might see either the DDL command or gpcrondump waiting to acquire locks.
大概就是运行的时候更改表会备份失败,运行DDL会产生锁表问题
回执码:
About Return Codes
- 0 – Dump completed with no problems
- 1 – Dump completed, but one or more warnings were generated
- 2 – Dump failed with a fatal error
参数: ---(英文更好看不翻译了)
[gpadmin@greenplum01 gpbackup]$ gpcrondump --help COMMAND NAME: gpcrondump Writes out a database to SQL script files. The script files can be used to restore the database using the gpdbrestore utility. The gpcrondump utility can be called directly or from a crontab entry. ***************************************************** SYNOPSIS ***************************************************** gpcrondump -x database_name [-s <schema> | -S <schema> | -t <schema>.<table> | -T <schema>.<table>] [--table-file=<filename> | --exclude-table-file=<filename>] [--schema-file=<filename> | --exclude-schema-file=<filename>] [-u backup_directory] [-R post_dump_script] [--incremental] [ -K <timestamp> [--list-backup-files] ] [--prefix <prefix_string> [--list-filter-tables] ] [ -c [ --cleanup-date yyyymmdd | --cleanup-total n ] ] [-z] [-r] [-f <free_space_percent>] [-b] [-h] [-H] [-j | -k] [-g] [-G] [-C] [-d <master_data_directory>] [-B <parallel_processes>] [-a] [-q] [-l <logfile_directory>] [--email-file <path_to_file> ] [-v] { [-E encoding] [--inserts | --column-inserts] [--oids] [--no-owner | --use-set-session-authorization] [--no-privileges] [--rsyncable] { [--ddboost [--replicate --max-streams <max_IO_streams> [--ddboost-skip-ping] ] [--ddboost-storage-unit=<storage_unit_name>] ] } | { [--netbackup-service-host <netbackup_server> --netbackup-policy <netbackup_policy> --netbackup-schedule <netbackup_schedule> [--netbackup-block-size <size> ] [--netbackup-keyword <keyword> ] } } gpcrondump --ddboost-host <ddboost_hostname> [--ddboost-host ddboost_hostname ... ] --ddboost-user <ddboost_user> --ddboost-backupdir <backup_directory> [--ddboost-storage-unit=<storage_unit_name>] [--ddboost-remote] [--ddboost-skip-ping] gpcrondump --ddboost-config-remove gpcrondump --ddboost-show-config [--ddboost-remote] gpcrondump -o [ --cleanup-date yyyymmdd | --cleanup-total n ] gpcrondump -? gpcrondump --version ***************************************************** DESCRIPTION ***************************************************** The gpcrondump utility dumps the contents of a database into SQL script files, which can then be used to restore the database schema and user data at a later time using gpdbrestore. During a dump operation, users will still have full access to the database. By default, dump files are created in their respective master and segment data directories in a directory named db_dumps/YYYYMMDD. The data dump files are compressed by default using gzip. gpcrondump allows you to schedule routine backups of a Greenplum database using cron (a scheduling utility for UNIX operating systems). Cron jobs that call gpcrondump should be scheduled on the master host. WARNING: Backing up a database with gpcrondump while simultaneously running ALTER TABLE might cause gpcrondump to fail. ********************** Data Domain Boost ********************** gpcrondump is used to schedule Data Domain Boost backup and restore operations. gpcrondump is also used to set or remove one-time credentials for Data Domain Boost. ********************** NetBackup ********************** Greenplum Database must be configured to communicate with the Symantec NetBackup master server that is used to backup the database. See the "Greenplum Database Administrator Guide" for information on configuring Greenplum Database and NetBackup and backing up and restoring with NetBackup. ********************** Return Codes ********************** The following is a list of the codes that gpcrondump returns. 0 - Dump completed with no problems 1 - Dump completed, but one or more warnings were generated 2 - Dump failed with a fatal error ********************** EMAIL NOTIFICATIONS ********************** To have gpcrondump send email notifications with the completion status after a back up operation completes, you must place a file named mail_contacts in the home directory of the Greenplum superuser (gpadmin) or in the same directory as the gpcrondump utility ($GPHOME/bin). This file should contain one email address per line. gpcrondump will issue a warning if it cannot locate a mail_contacts file in either location. If both locations have a mail_contacts file, then the one in $HOME takes precedence. You can customize the email Subject and From lines of the email notifications that gpcrondump sends after a back up completes for a database. You specify the option --email-file with the location of a YAML file that contains email Subject and From lines that gpcrondump uses. See the section "File Format for Customized Emails" for information about the format of the YAML file. NOTE: The UNIX mail utility must be running on Greenplum Database host and must be configured to allow the Greenplum superuser (gpadmin) to send email. ********************** Limitations ********************** * NetBackup is not compatible with DDBoost. Both NetBackup and DDBoost cannot be used in a single back up operation. * For incremental back up sets, a full backup and associated incremental backups, the backup set must be on a single device. For example, a backup set must all be on a file system. The backup set cannot have some backups on the local file system and others on a Data Domain system or a NetBackup system. ***************************************************** OPTIONS ***************************************************** -a Do not prompt the user for confirmation.(不要提示) -b Bypass disk space check. The default is to check for available disk space, unless --ddboost is specified. When using Data Domain Boost, this option is always enabled. Note: Bypassing the disk space check generates a warning message. With a warning message, the return code for gpcrondump is 1 if the dump is successful. (If the dump fails, the return code is 2, in all cases.) (绕过磁盘空间检查会生成警告消息。带有警告消息,返回代码为gpcrondump 是 1如果转储成功。
(如果转储失败,则返回代码为2, 在所有情况下。)) -B <parallel_processes> The number of segments to check in parallel for pre/post-dump validation. If not specified, the utility will start up to 60 parallel processes depending on how many segment instances it needs to dump. -c Specify this option to delete old backups before performing a back up. In the db_dumps directory, the directory where the name is the oldest date is deleted. If the directory name is the current date, the directory is not deleted. The default is to not delete old backup files. The deleted directory might contain files from one or more backups. WARNING: Before using this option, ensure that incremental backups required to perform the restore are not deleted. The gpdbrestore utility option --list-backup lists the backup sets required to perform a backup. You can specify the option --cleanup-date or --cleanup-total to specify backup sets to delete. If --ddboost is specified, only the old files on Data Domain Boost are deleted. This option is not supported with the -u option. -C Clean out the catalog schema prior to restoring database objects. gpcrondump adds the DROP command to the SQL script files when creating the backup files. When the script files are used by the gpdbrestore utility to restore database objects, the DROP commands remove existing database objects before restoring them. If --incremental is specified and the files are on NFS storage, the -C option is not supported. The database objects are not dropped if the -C option is specified. --cleanup-date=yyyymmdd Remove backup sets for the date yyyy-mm-dd. The date format is yyyymmdd. If multiple backup sets were created on the date, all the backup sets for that date are deleted. If no backup sets are found, gpcrondump returns a warning message and no backup sets are deleted. If the -c option is specified, the backup process continues. Valid only with the -c or -o option. WARNING: Before using this option, ensure that incremental backups required to perform the restore are not deleted. The gpdbrestore utility option --list-backup lists the backup sets required to perform a backup. --cleanup-total=n Remove the n oldest backup sets based on the backup timestamp. If there are fewer than n backup sets, gpcrondump returns a warning message and no backup sets are deleted. If the -c option is specified, the backup process continues. Valid only with the -c or -o option. WARNING: Before using this option, ensure that incremental backups required to perform the restore are not deleted. The gpdbrestore utility option --list-backup lists the backup sets required to perform a backup. --column-inserts Dump data as INSERT commands with column names. If --incremental is specified, this option is not supported. -d <master_data_directory> The master host data directory. If not specified, the value set for $MASTER_DATA_DIRECTORY will be used. --ddboost [--replicate --max-streams <max_IO_streams> [--ddboost-skip-ping] ] [--ddboost-storage-unit=<storage_unit_name>] Use Data Domain Boost for this backup. Before using Data Domain Boost, set up the Data Domain Boost credential, as described in the next option below. --ddboost-storage-unit is optional. Specify a Data Domain system storage unit name where a back up is stored. The storage unit name is also used to replicate dump files between source and target Data Domain systems if --ddboost-remote is specified. If --ddboost-storage-unit is not specified, it defaults to the value stored in the DD Boost config file for the Greenplum Database cluster. Note: storage unit will be created on DDBoost server only if one does not already exist and following options are not specified: --incremental, --list-backup-file, --list-filter-tables, -o, --ddboost-config-remove The following option is recommended if --ddboost is specified. * -z option (uncompressed) Backup compression (turned on by default) should be turned off with the -z option. Data Domain Boost will deduplicate and compress the backup data before sending it to the Data Domain system. --replicate --max-streams <max_IO_streams> is optional. If you specify this option, gpcrondump replicates the backup on the remote Data Domain server after the backup is complete on the primary Data Domain server. <max_IO_streams> specifies the maximum number of Data Domain I/O streams that can be used when replicating the backup set on the remote Data Domain server from the primary Data Domain server. You can use gpmfr to replicate a backup if replicating a backup with gpcrondump takes a long time and prevents other backups from occurring. Only one instance of gpcrondump can be running at a time. While gpcrondump is being used to replicate a backup, it cannot be used to create a backup. You can run a mixed backup that writes to both a local disk and Data Domain. If you want to use a backup directory on your local disk other than the default, use the -u option. Mixed backups are not supported with incremental backups. For more information about mixed backups and Data Domain Boost, see "Backing Up and Restoring Databases" in the "Greenplum Database Administrator Guide." IMPORTANT: Never use the Greenplum Database default backup options with Data Domain Boost. To maximize Data Domain deduplication benefits, retain at least 30 days of backups. NOTE: The -b, -c, -f, -G, -g, -R, and -u options change if --ddboost is specified. See the options for details. The DDBoost backup options are not supported if the NetBackup options are specified. --ddboost-host ddboost_hostname [--ddboost-host ddboost_hostname ... ] --ddboost-user <ddboost_user> --ddboost-backupdir <backup_directory> [--ddboost-storage-unit=<storage_unit_name>] [--ddboost-remote] [--ddboost-skip-ping] Sets the Data Domain Boost credentials. Do not combine this options with any other gpcrondump options. Do not enter just one part of this option. <ddboost_hostname> is the IP address (or hostname associated to the IP) of the host. There is a 30-character limit. If you use two or more network connections to connect to the Data Domain system, specify each connection with the --ddboost-host option. <ddboost_user> is the Data Domain Boost user name. There is a 30-character limit. <backup_directory> is the location for the backup files, configuration files, and global objects on the Data Domain system. The location on the system is GPDB/<backup_directory>. --ddboost-storage-unit is optional. Create or update the storage unit ID in the DD Boost credentials file. Default storage unit ID is GPDB. --ddboost-remote is optional. Indicates that the configuration parameters are for the remote Data Domain system that is used for backup replication Data Domain Boost managed file replication. If --ddboost-remote is specified, --ddboost-storage-unit is ignored. Example: gpcrondump --ddboost-host 172.28.8.230 --ddboost-user ddboostusername --ddboost-backupdir gp_production After running gpcrondump with these options, the system verifies the limits on the host and user names and prompts for the Data Domain Boost password. Enter the password when prompted; the password is not echoed on the screen. There is a 40-character limit on the password that can include lowercase letters (a-z), uppercase letters (A-Z), numbers (0-9), and special characters ($, %, #, +, etc.). The system verifies the password. After the password is verified, the system creates encrypted DDBOOST_CONFIG files in the user's home directory. In the example, the --ddboost-backupdir option specifies the backup directory gp_production in the Data Domain Storage Unit GPDB. NOTE: If there is more than one operating system user using Data Domain Boost for backup and restore operations, repeat this configuration process for each of those users. IMPORTANT: Set up the Data Domain Boost credential before running any Data Domain Boost backups with the --ddboost option, described above. --ddboost-config-remove Removes all Data Domain Boost credentials from the master and all segments on the system. Do not enter this option with any other gpcrondump option. --ddboost-show-config Show DDBoost and MFR (--ddboost-remote) related configuration information: DDBoost hostname, username, default backup directory, default storage unit. --ddboost-remote is optional, specify it to show the DDBoost and MFR related configuration information for remote DDBoost server. --ddboost-skip-ping Specify this option to skip the ping of a Data Domain system. When working with a Data Domain system, ping is used to ensure that the Data Domain system is reachable. If the Data Domain system is configured to block ICMP ping probes, specify this option. --dump-stats Dump optimizer statistics from pg_statistic. Statistics are dumped in the master data directory to db_dumps/YYYYMMDD/gp_statistics_1_1_<timestamp>. If --ddboost is specified, the backup is located on the storage unit specified by --ddboost-storge-unit, or by default, the storage unit from cluster's config file, under the default directory configured by --ddboost-backupdir when the Data Domain Boost credentials were set. -E <encoding> Character set encoding of dumped data. Defaults to the encoding of the database being dumped. See the Greenplum Database Reference Guide for the list of supported character sets. -email-file <path_to_file> Specify the fully-qualified location of the YAML file that contains the customized Subject and From lines that are used when gpcrondump sends notification emails about a database back up. See the section "File Format for Customized Emails" for information about the format of the YAML file. -f <free_space_percent> When checking that there is enough free disk space to create the dump files, specifies a percentage of free disk space that should remain after the dump completes. The default is 10 percent. NOTE: This is option is not supported if --ddboost or --incremental is specified. -g Secure a copy of the master and segment configuration files postgresql.conf, pg_ident.conf, and pg_hba.conf. These configuration files are dumped in the master or segment data directory to db_dumps/YYYYMMDD/config_files_<timestamp>.tar. If --ddboost is specified, the backup is located on the storage unit specified by --ddboost-storge-unit, or by default, the storage unit from cluster's config file, under the default directory configured by --ddboost-backupdir when the Data Domain Boost credentials were set. -G Use pg_dumpall to dump global objects such as roles and tablespaces. Global objects are dumped in the master data directory to db_dumps/YYYYMMDD/gp_global_1_1_<timestamp>. If --ddboost is specified, the backup is located on the storage unit specified by --ddboost-storge-unit, or by default, the storage unit from cluster's config file, under the default directory configured by --ddboost-backupdir when the Data Domain Boost credentials were set. -h Record details of database dump in database table public.gpcrondump_history in database supplied via -x option. Utility will create table if it does not currently exist. This option will be deprecated in a future release. -H Disable recording details of database dump in database table public.gpcrondump_history in database supplied via -x option. If not specified, the utility will create / update the public.gpcrondump_history table. -H option cannot be selected with -h option. --incremental Adds an incremental backup to a backup set. When performing an incremental backup, the complete backup set created prior to the incremental backup must be available. The complete backup set includes the following backup files: * The last full backup before the current incremental backup * All incremental backups created between the time of the full backup the current incremental backup An incremental backup is similar to a full back up except for append-optimized tables, including column-oriented tables. An append-optimized table is backed up only if at least one of the following operations was performed on the table after the last backup. ALTER TABLE INSERT UPDATE DELETE TRUNCATE DROP and then re-create the table For partitioned append-optimized tables, only the changed table partitions are backed up. The -u option must be used consistently within a backup set that includes a full and incremental backups. If you use the -u option with a full backup, you must use the -u option when you create incremental backups that are part of the backup set that includes the full backup. You can create an incremental backup for a full backup of set of database tables. When you create the full backup, specify the --prefix option to identify the backup. To include a set of tables in the full backup, use either the -t option or --table-file option. To exclude a set of tables, use either the -T option or the --exclude-table-file option. See the description of the option for more information on its use. To create an incremental backup based on the full backup of the set of tables, specify the option --incremental and the --prefix option with the string specified when creating the full backup. The incremental backup is limited to only the tables in the full backup. WARNING: gpcrondump does not check for available disk space prior to performing an incremental backup. IMPORTANT: An incremental back up set, a full backup and associated incremental backups, must be on a single device. For example, a the backups in a backup set must all be on a file system or must all be on a Data Domain system. --inserts Dump data as INSERT, rather than COPY commands. If --incremental is specified, this option is not supported. -j Run VACUUM before the dump starts. -K <timestamp> [--list-backup-files] Specify the <timestamp> that is used when creating a backup. The <timestamp> is 14-digit string that specifies a date and time in the format yyyymmddhhmmss. The date is used for backup directory name. The date and time is used in the backup file names. If -K <timestamp> is not specified, a timestamp is generated based on the system time. When adding a backup to set of backups, gpcrondump returns an error if the <timestamp> does not specify a date and time that is more recent than all other backups in the set. --list-backup-files is optional. When you specify both this option and the -K <timestamp> option, gpcrondump does not perform a backup. gpcrondump creates two text files that contain the names of the files that will be created when gpcrondump backs up a Greenplum database. The text files are created in the same location as the backup files. The file names use the timestamp specified by the -K <timestamp> option and have the suffix _pipes and _regular_files. For example: gp_dump_20130514093000_pipes gp_dump_20130514093000_regular_files The _pipes file contains a list of file names that be can be created as named pipes. When gpcrondump performs a backup, the backup files will generate into the named pipes. The _regular_files file contains a list of backup files that must remain regular files. gpcrondump and gpdbrestore use the information in the regular files during backup and restore operations. To backup a complete set of Greenplum Database backup files, the files listed in the _regular_files file must also be backed up after the completion of the backup job. To use named pipes for a backup, you need to create the named pipes on all the Greenplum Database and make them writeable before running gpcrondump. If --ddboost is specified, -K <timestamp> [--list-backup-files] is not supported. -k Run VACUUM after the dump has completed successfully. -l <logfile_directory> The directory to write the log file. Defaults to ~/gpAdminLogs. --netbackup-block-size <size> Specify the block size of data being transferred to the Symantec NetBackup server. The default is 512 bytes. NetBackup options are not supported if DDBoost backup options are specified. --netbackup-keyword <keyword> Specify a keyword for the backup that is transferred to the Symantec NetBackup server. NetBackup adds the keyword property and the specified <keyword> value to the NetBackup .img files that are created for the backup. The minimum length is 1 character, and the maximum length is 100 characters. NetBackup options are not supported if DDBoost backup options are specified. --netbackup-service-host netbackup_server The NetBackup master server that Greenplum Database connects to when backing up to NetBackup. NetBackup options are not supported if DDBoost backup options are specified. --netbackup-policy <netbackup_policy> The name of the NetBackup policy created for backing up Greenplum Database. NetBackup options are not supported if DDBoost backup options are specified.. --netbackup-schedule <netbackup_schedule> The name of the NetBackup schedule created for backing up Greenplum Database. NetBackup options are not supported if DDBoost backup options are specified. --no-owner Do not output commands to set object ownership. --no-privileges Do not output commands to set object privileges (GRANT/REVOKE commands). -o Clear out old dump files only, but do not run a dump. This will remove the oldest dump directory except the current date's dump directory. All dump sets within that directory will be removed. WARNING: Before using this option, ensure that incremental backups required to perform the restore are not deleted. The gpdbrestore utility option --list-backup lists the backup sets required to perform a restore. You can specify the option --cleanup-date or --cleanup-total to specify backup sets to delete. If --ddboost is specified, only the old files on Data Domain Boost are deleted. If --incremental is specified, this option is not supported. --oids Include object identifiers (oid) in dump data. If --incremental is specified, this option is not supported. --prefix <prefix_string> [--list-filter-tables ] Prepends <prefix_string> followed by an underscore character (_) to the names of all the backup files created during a backup. --list-filter-tables is optional. When you specify both options, gpcrondump does not perform a backup. For the full backup created by gpcrondump that is identified by the <prefix-string>, the tables that were included or excluded for the backup are listed. You must also specify the --incremental option if you specify the --list-filter-tables option. If --ddboost is specified, --prefix <prefix_string> [--list-filter-tables] is not supported. -q Run in quiet mode. Command output is not displayed on the screen, but is still written to the log file. -r Rollback the dump files (delete a partial dump) if a failure is detected. The default is to not rollback. Note: This option is not supported if --ddboost is specified. -R <post_dump_script> The absolute path of a script to run after a successful dump operation. For example, you might want a script that moves completed dump files to a backup host. This script must reside in the same location on the master and all segment hosts. --rsyncable Passes the --rsyncable flag to the gzip utility to synchronize the output occasionally, based on the input during compression. This synchronization increases the file size by less than 1% in most cases. When this flag is passed, the rsync(1) program can synchronize compressed files much more efficiently. The gunzip utility cannot differentiate between a compressed file created with this option, and one created without it. -s <schema_name> Dump all the tables that are qualified by the specified schema in the database. The -s option can be specified multiple times. System catalog schemas are not supported. If you want to specify multiple schemas, you can also use the --schema-file=<filename> option in order not to exceed the maximum token limit. Only a set of tables or set of schemas can be specified. For example, the -s option cannot be specified with the -t option. If --incremental is specified, this option is not supported. -S <schema_name> A schema name to exclude from the database dump. The -S option can be specified multiple times. If you want to specify multiple schemas, you can also use the --exclude-schema-file=<filename> option in order not to exceed the maximum token limit. Only a set of tables or set of schemas can be specified. For example, this option cannot be specified with the -t option. If --incremental is specified, this option is not supported. -t <schema>.<table> Dump only the named table in this database. The -t option can be specified multiple times. If you want to specify multiple tables, you can also use the --table-file=<filename> option in order not to exceed the maximum token limit. Only a set of tables or set of schemas can be specified. For example, this option cannot be specified with the -s option. If --incremental is specified, this option is not supported. -T <schema>.<table> A table name to exclude from the database dump. The -T option can be specified multiple times. If you want to specify multiple tables, you can also use the --exclude-table-file=<filename> option in order not to exceed the maximum token limit. Only a set of tables or set of schemas can be specified. For example, this option cannot be specified with the -s option. If --incremental is specified, this option is not supported. --exclude-schema-file=<filename> Excludes all the tables that are qualified by the specified schemas listed in the <filename> from the database dump. The file <filename> contains any number of schemas, listed one per line. Only a set of tables or set of schemas can be specified. For example, this option cannot be specified with the -t option. If --incremental is specified, this option is not supported. --exclude-table-file=<filename> Excludes all tables listed in the <filename> from the database dump. The file <filename> contains any number of tables, listed one per line. Only a set of tables or set of schemas can be specified. For example, this option cannot be specified with the -s option. If --incremental is specified, this option is not supported. --schema-file=<filename> Dumps only the tables that are qualified by the schemas listed in the <filename>. The file <filename> contains any number of schemas, listed one per line. Only a set of tables or set of schemas can be specified. For example, this option cannot be specified with the -t option. If --incremental is specified, this option is not supported. --table-file=<filename> Dumps only the tables listed in the <filename>. The file <filename> contains any number of tables, listed one per line. If --incremental is specified, this option is not supported. -u <backup_directory> Specifies the absolute path where the backup files will be placed on each host. If the path does not exist, it will be created, if possible. If not specified, defaults to the data directory of each instance to be backed up. Using this option may be desirable if each segment host has multiple segment instances as it will create the dump files in a centralized location rather than the segment data directories. Note: This option is not supported if --ddboost is specified. --use-set-session-authorization Use SET SESSION AUTHORIZATION commands instead of ALTER OWNER commands to set object ownership. -v | --verbose Specifies verbose mode. --version Displays the version of this utility. -x <database_name> Required. The name of the Greenplum database to dump. Specify multiple times for multiple databases. -z Do not use compression. Default is to compress the dump files using gzip. We recommend this option (-z) be used for NFS and Data Domain Boost backups. -? Displays the online help. ***************************************************** File Format for Customized Emails ***************************************************** You can configure gpcrondump to send an email notification after a back up operation completes for a database. To customize the From and Subject lines of the email that are sent for a database, you create a YAML file and specify the location of the file with the option --email-file. In the YAML file, you can specify a different From and Subject line for each database that gpcrondump backs up. This is the format of the YAML file to specify a custom From and Subject line for a database: EMAIL_DETAILS: - DBNAME: <database_name> FROM: <from_user> SUBJECT: <subject_text> When email notification is configured for gpcrondump, the <from_user> and the <subject_text> are the strings that gpcrondump uses in the email notification after completing the back up for <database_name>. This example YAML file specifies different From and Subject lines for the databases testdb100 and testdb200. EMAIL_DETAILS: - DBNAME: testdb100 FROM: RRP_MPE2_DCA_1 SUBJECT: backup completed for Database 'testdb100' - DBNAME: testdb200 FROM: Report_from_DCDDEV_host SUBJECT: Completed backup for database 'testdb200' ***************************************************** EXAMPLES ***************************************************** Call gpcrondump directly and dump mydatabase (and global objects): gpcrondump -x mydatabase -c -g -G A crontab entry that runs a backup of the sales database (and global objects) nightly at one past midnight: 01 0 * * * /home/gpadmin/gpdump.sh >> gpdump.log The content of dump script gpdump.sh is: #!/bin/bash export GPHOME=/usr/local/greenplum-db export MASTER_DATA_DIRECTORY=/data/gpdb_p1/gp-1 . $GPHOME/greenplum_path.sh gpcrondump -x sales -c -g -G -a -q This example creates two text files, one with the suffix _pipes and the other with _regular_files. The _pipes file contain the file names that can be named pipes when you backup the Greenplum database mytestdb. gpcrondump -x mytestdb -K 20131030140000 --list-backup-files To use incremental backup with a set of database tables, you must create a full backup of the set of tables and specify the --prefix option to identify the backup set. The following example uses the --table-file option to create a full backup of the set of files listed in the file user-tables. The prefix user_backup identifies the backup set. gpcrondump -x mydatabase --table-file=user-tables --prefix user_backup To create an incremental backup for the full backup created in the previous example, specify the --incremental option and the option --prefix user_backup to identify backup set. This example creates an incremental backup. gpcrondump -x mydatabase --incremental --prefix user_backup This command lists the tables that were included or excluded for the full backup. gpcrondump -x mydatabase --incremental --prefix user_backup --list-filter-tables This command backs up the database customer and specifies a NetBackup policy and schedule that are defined on the NetBackup master server nbu_server1. A block size of 1024 bytes is used to transfer data to the NetBackup server. gpcrondump -x customer --netbackup-service-host=nbu_server1 --netbackup-policy=gpdb_cust --netbackup-schedule=gpdb_backup --netbackup-block-size=1024 ***************************************************** SEE ALSO ***************************************************** gpdbrestore
---具体操作见下章---
四,三个软件 的认识
备份软件这么多不可能全部都跑一遍把,这种东西不现实:
所以的优缺点就出来了
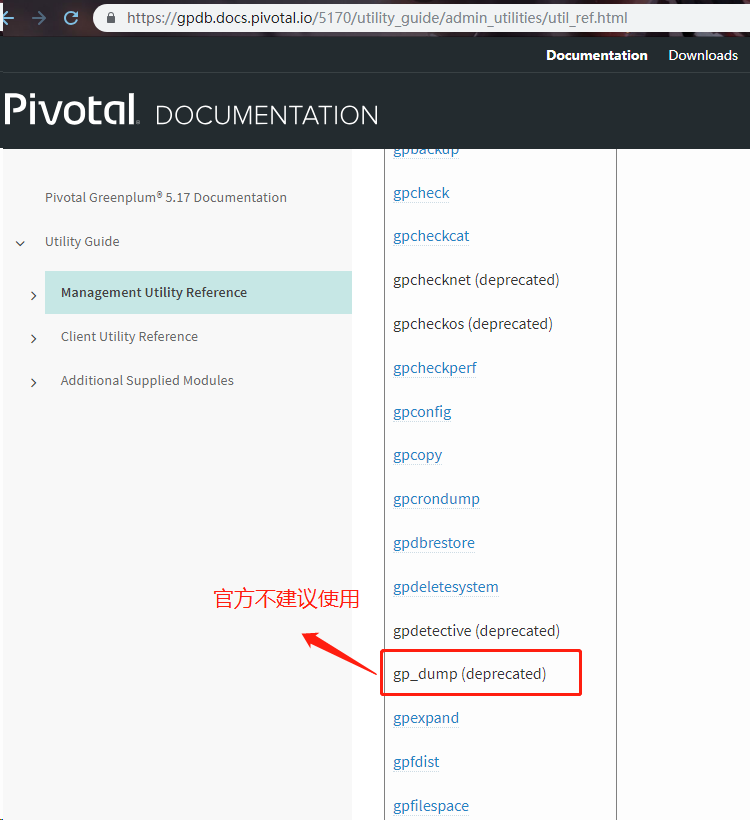
gp_dump --->这个被官方给XXOO了,为啥呢,太慢了,备份慢,连恢复也慢!!
替代他的是gpcrondump 这个底层还是gp_dump 但是更加厉害了,备份可以备份配置文件
后来居上的gpbackup新的东西,就是快!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号