
oracle 基础知识(四) 构成
一, oracle服务
一个oracle 服务由一个oracle 实例和一个oracle数据库组成.
oracle = instance + database
总体概念:

二, oracle 实例
01,实例?
实例是一种访问oracle数据库的方式,始终打开一个方式,并且只打开一个数据库.它包括内存结构(SGA)和一系列后台进程(background process),两者合起来称为一个oracle实例。
Oracle instance = sga+ background Process
02,内存结构?
包含系统全局区(SGA)和程序全局区(PGA
oracle memory Structures = SGA +PGA
SGA(系统全局表):再历程启动时分配,是oracle实例的基本组件
PGA(程序全局表): 在服务器进程启动时分配
SGA由服务器和后台进程共享,PGA包含单个服务器进程或单个后台进程的数据和控制信息,与几个进程共享的SGA相反,PGA是只被一个进程使用的区域,PGA在创建进程时分配在终止进程时回收。由服务器进程产生。
03,SGA?
SGA 是一块巨大的共享内存区域,被看做是oracle数据库的一个大缓冲池,这里的数据可以被oracle的各个进程共用。
SGA = 数据缓冲区 +重做日志缓冲区 +共享池 + 大池 + java 池 +池流
查看SGA大小: 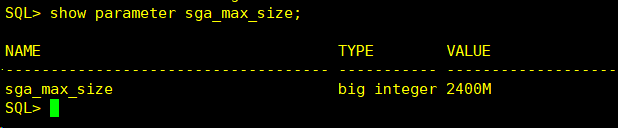
04,块缓冲区高速缓存(database buffer cache)
4.1概念
读取磁盘的速度相对来说是非常慢的,而内存相对速度则要快的多。因此为了能够加快处理数据的速度,oracle 必须将读取过的数据缓存在内存里。而这些缓存在内存里的数据就是数据库缓冲区高速缓存区,通常就叫做 Buffer Cache。按照 oracle 官方的说法,Buffer Cache 就是 SGA 中一块含有许多数据块的内存结构,而这些数据块主要都是数据文件里的数据块内容的拷贝
4.2缓冲区状态
没用过(Unused)
表示缓冲区可供使用,因为它从未被使用或当前未被使用。这种类型的缓冲区是数据库最快使用的;
清洁(Clean)
表示缓冲区较早已被使用,现在包含一个时间点的块的读一致版本。该块包含数据,但是“干净”,所以它不需要检查点。数据库可以固定块并重新使用它;
脏(Dirty)
表示缓冲区包含尚未写入磁盘的已修改数据。数据库必须在重新使用该块之前执行检查点。
每个缓冲区都有一个访问模式:pinned or free - 固定或空闲(未固定)。缓存被“固定”在缓存中,以便在用户会话访问内存时不会耗尽内存。多个会话不能同时修改固定的缓冲区。
4.3缓冲模式
当前模式(Current mode)
如果未提交的事务已更新块中的两行,则当前模式将检索具有这些未提交行的块。修改语句只能更新块的当前版本。
一致模式(Consistent mode)
如果未提交的事务更新了块中的两行,并且如果单独会话中的查询请求该块,则数据库使用撤销数据来创建此块的读一致版本不包括未提交的更新。通常查询以一致模式检索块。
4.4 缓冲池
数据库缓冲区缓存分为一个或多个缓冲池。可以手动配置将数据保存在缓冲区缓存中的独立缓冲池,或者在使用数据块后立即使缓冲区可用于新数据。

4.4.1 默认池(Default Pool)
除非手动配置单独的池,否则默认池是唯一的缓冲池


1 show parameter db_cache_size

4.4.2 保留池(Keep Pool)
保留缓冲池的目标是将常用对象保留在内存中,从而避免大量物理 I / O 操作。
show parameter db_keep_cache_size
4.4.3 回收池(Recycle pool)
这个池适用于大范围数据的单次操作缓冲,在使用后可快速释放缓冲池,避免消耗不必要的内存空间。
show parameter db_recycle_cache_size

4.4.5 非标准块大小表空间的独立池
05 , 重做日志缓冲区(redo log buffer)
重做日志文件的缓冲区,对数据库的任何修改都按顺序被记录在该缓冲,然后由LGWR进程将它写入磁盘。这些修改信息可能是DML语句,如(insert,update,delete)或DDL语句,如(create,alter,drop等)。重做日志缓存区的存在,是因为内存到内存的操作比内存到硬盘的速度快很多。重做日志缓冲区可以加速数据库的操作速度。但是考虑数据库的一致性与可恢复性,数据在重做日志缓冲区的滞留时间不会很长,所以重做日志缓冲区一般都很小。【操作速度和安全性之间需要权衡考虑】
日志中记录数据块的地址,更改的时间以及对数据块做了哪些改变。Oracle在执行任何DML和DDL操作改变数据之前,都会将恢复所需要的信息,先写入redo log buffer,然后再写入database buffer cache。
① 如果数据和回滚数据不在database buffer cache中,server process会将它们从dbf文件中读取到database buffer cache中。
② server process会在要修改的数据行上添加行级锁。
③ server process将数据的变化信息和回滚所需的信息都写入redo log buffer。
④ server process将对数据所做的修改后的数据信息写入database buffer cache,然后将database buffer cache中的这些数据标记为脏数据(此时内存中的数据和磁盘上的数据是不一致的)。
⑤ LGWR将重做日志缓冲区中的数据写入重做日志文件中。
⑥ DBWn将database buffer cache的脏数据写入数据文件中。
06,Java程序缓冲区(java pool)
07,大池(large pool)
08,共享池(shared pool)
Oracle共享池(Share Pool)属于SGA,由库高速缓存(library cache)和数据字典高速缓存(data dictionary cache)组成
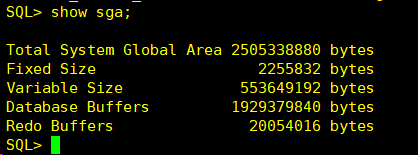
8.1 库高速缓存(Library cache)
Oracle引入库高速缓存的目的是共享SQL和PL/SQL代码。服务器进程执行SQL和PL/SQL时,首先会进入库高速缓存查找是否有相同的SQL,如果有,就不再进行后续的编译处理,直接使用已经编译的SQL和执行计划。Oracle通过比较两条SQL语句的正文来确定两条SQL是否相同,所以如果想共享SQL语句,必须使用绑定变量的方式。如:
8.2 数据字典高速缓存 (Library cache)
当Oracle执行SQL时,会将相关的数据文件、表、索引、列、用户、其他的数据对象的定义和权限信息存放到数据字典高速缓存中。在此之后,如果需要相同的相关数据,Oracle会从数据字典高速缓存中提取。Oracle没有提供直接修改 数据字典高速缓存大小的方法,只能通过修改共享池的大小来间接修改 数据字典高速缓存的大小。
8.3 修改 大小
alter system set shared_pool_size= xxx m
共享池的大小受限制于SGA_MAX_SIZE参数的大小。
来自: >>
|
SGA |
SHARE POOL (共享池) 用如下命令可以调整 ALTER SYSTEM SET SHARED_POOL_SIZE=64M |
LIBRARY CACHE (库高速缓存) 1存储最近使用的SQL和PL/SQL语句信息 2包括SHARED SQL和SHARED PL/SQL 3用LRU算法管理 4大小由SHARE POOL大小决定 |
|
DATA DICTIONARY CACHE (数据字典高速缓存) 1数据库中最近使用的定义的集合 2包含数据库文件,表,索引,列,用户,权限和其他的数据库对象相关信息 3在语法分析阶段,服务器进程会在数据字典中查找用于对象解析和验证访问的信息 4将数据字典信息高速缓存到内存中,可缩短查询和DML的响应时间 5大小由共享池的大小决定 |
||
|
DATABASE BUFFER CACHE (数据缓冲区高速缓存) |
1存储已从数据文件检索到的数据的复本 2大幅提高读取和更新数据的性能 3使用LRU算法管理 4主块的大小由DB_BLOCK_SIZE确定 |
|
|
REDO LOG BUFFER (重做日志缓冲区) |
1记录对数据库数据块作的全部更改 2主要用来恢复 3其中记录的更改被称作重做条目 4重做条目包含用于重新构建或重做更改的信息 5大小由LOG_BUFFER定义 |
|
|
LARGE POOL (大型池) |
1 SGA可选的内存区 2分担了共享池的一部分工作 3用于共享服务器的UGA 4用于I/O服务器进程 5备份和恢复操作或RMAN 6并行执行消息缓冲区(前提PARALLEL_POOL_SIZE=TRUE) 7不使用LRU列表 8大小由LARGE_POOL_SIZE确定 |
|
|
JAVA POOL (JAVA池) |
1存储JAVA命令服务分析要求 2安装和使用JAVA时必须的 3大小有JAVA_POOL_SIZE确定 |
|
|
PGA |
PRIVATE SQL AREA (专用SQL区) 专用SQL区的位置取决于为会话建立的连接类型。在专用服务器环境中,专用SQL区位于各自服务器进程的PGA中。在共享服务器环境中,专用SQL区位于SGA中。 管理专用SQL区是用户进程的职责。用户进程可以分配的专用SQL区的数目始终由 初始化参数OPEN_CURSORS来限制。该参数的缺省值是50。 |
PERSISTEN AREA (永久区) 包含绑定信息,并且只在关闭游标时释放 |
|
RUNTIME AREA (运行时区) 在执行请求时的第一步创建。对于INSERT、UPDATE和DELETE命令,该区在执行语句后释放,对于查询操作,该区只在提取所有行或取消查询后释放。 |
||
|
SESSION MEMORY (会话内存) |
包含为保留会话变量以及与该会话相关的其它信息而分配的内存。对于共享服务器环境,该会话是共享的而不是专用的。 |
|
|
SQL WORK AREAS (SQL工作区) |
用于大量占用内存的操作,如排序、散列联接、位图合并和位图创建。 工作区的大小可进行控制和调整 |
三,后台进程
|
DBWn |
DBWn延迟写入数据文件,直到发生下列事件之一: •增量或正常检查点 •灰数据缓冲区的数量达到阈值 •进程扫描指定数量的块而无法找到任何空闲缓冲区时 •出现超时 •实时应用集群(Real Application Clusters, RAC)环境中出现ping请求 •使一般表空间或临时表空间处于脱机状态 •使表空间处于只读模式 •删除或截断表 •执行ALTER TABLESPACE表空间名BEGIN BACKUP操作 |
|
LGWR |
LGWR在下列情况下执行从重做日志缓冲区到重做日志文件的连续写入: •当提交事务时 •当重做日志缓冲区的三分之一填满时 •当重做日志缓冲区中记录了超过1 MB的更改时 •在DBWn将数据库缓冲区高速缓存中修改的块写入数据文件以前 •每隔三秒 |
|
SMON |
例程恢复 –前滚重做日志中的更改 –打开数据库供用户访问 –回退未提交的事务处理 •合并空闲空间 •回收临时段 |
|
PMON |
进程失败后,后台进程PMON通过下面的方法进行清理: •回退用户的当前事务处理 •释放当前保留的所有表锁或行锁 •释放用户当前保留的其它资源 •重新启动已失效的调度程序 |
|
CKPT |
•在检查点发信号给DBWn •使用检查点信息更新数据文件的标头 •使用检查点信息更新控制 启动检查点的原因如下: •确保定期向磁盘写入内存中发生修改的数据块,以便在系统或数据库失败时不会丢失数据 •缩短例程恢复所需的时间。只需处理最后一个检查点后面的重做日志条目以启动恢复操作 •确保提交的所有数据在关闭期间均已写入数据文件 由CKPT写入的检查点信息包括检查点位置、系统更改号、重做日志中恢复操作的起始位置以及有关日志的信息等等。 注:CKPT并不将数据块写入磁盘,或将重做块写入联机重做日志。 |
|
ARCn |
•可选的后台进程 •设置ARCHIVELOG模式时自动归档联机重做日志 •保留数据库的全部更改记录 |
其他文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号