
keepalived heartbeat lvs haproxy
一, keeplived @
01,keeplived 是什么?
Keepalived起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。后来Keepalived又加入了VRRP的功能,VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,因此Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有HA cluster功能.
02,keeplived 工作原理
Keepalived工作在TCP/IP 参考模型的 三层、四层、五层,也就是分别为:网络层,传输层和应用层,根据TCP、IP参数模型隔层所能实现的功能,Keepalived运行机制如下:
在网络层:我们知道运行这4个重要的协议,互联网络IP协议,互联网络可控制报文协议ICMP、地址转换协议ARP、反向地址转换协议RARP,在网络层Keepalived在网络层采用最常见的工作方式是通过ICMP协议向服务器集群中的每一个节点发送一个ICMP数据包(有点类似与Ping的功能),如果某个节点没有返回响应数据包,那么认为该节点发生了故障,Keepalived将报告这个节点失效,并从服务器集群中剔除故障节点。
在传输层:提供了两个主要的协议:传输控制协议TCP和用户数据协议UDP,传输控制协议TCP可以提供可靠的数据输出服务、IP地址和端口,代表TCP的一个连接端,要获得TCP服务,需要在发送机的一个端口和接收机的一个端口上建立连接,而Keepalived在传输层里利用了TCP协议的端口连接和扫描技术来判断集群节点的端口是否正常,比如对于常见的WEB服务器80端口。或者SSH服务22端口,Keepalived一旦在传输层探测到这些端口号没有数据响应和数据返回,就认为这些端口发生异常,然后强制将这些端口所对应的节点从服务器集群中剔除掉。
在应用层:可以运行FTP,TELNET,SMTP,DNS等各种不同类型的高层协议,Keepalived的运行方式也更加全面化和复杂化,用户可以通过自定义Keepalived工作方式,例如:可以通过编写程序或者脚本来运行Keepalived,而Keepalived将根据用户的设定参数检测各种程序或者服务是否允许正常,如果Keepalived的检测结果和用户设定的不一致时,Keepalived将把对应的服务器从服务器集群中剔除
03,keeplived主配置文件详解
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。keepalived只有一个配置文件keepalived.conf,里面主要包括以下几个配置区域,
分别是global_defs、static_ipaddress、static_routes、vrrp_script、vrrp_instance和virtual_server。
配置文件实例介绍:


1 global_defs { 2 notification_email { #故障发生时给谁发邮件通知。 3 a@abc.com 4 b@abc.com 5 ... 6 } 7 notification_email_from alert@abc.com #通知邮件从哪个地址发出。 8 smtp_server smtp.abc.com #通知邮件的smtp地址。 9 smtp_connect_timeout 30 # 连接smtp服务器的超时时间。 10 enable_traps #连接smtp服务器的超时时间。 11 router_id host163 #标识本节点的字条串,通常为hostname,但不一定非得是hostname。故障发生时,邮件通知会用到。 12 } 13 14 15 static_ipaddress { 16 10.210.214.163/24 brd 10.210.214.255 dev eth0 配置的是是本节点的IP和路由信息 17 ... 18 } 19 20 21 static_routes { 22 10.0.0.0/8 via 10.210.214.1 dev eth0 配置的是是本节点的IP和路由信息 23 ... 24 } 25 26 vrrp_script chk_http_port { #用来做健康检查的,当时检查失败时会将vrrp_instance的priority减少相应的值。 27 28 script "</dev/tcp/127.0.0.1/80" 29 interval 1 30 weight -10 31 } 32 33 34 vrrp_sync_group VG_1 { 35 group { 36 inside_network # name of vrrp_instance (below) 37 outside_network # One for each moveable IP. 38 ... 39 } 40 notify_master /path/to_master.sh #分别表示切换为主/备/出错时所执行的脚本 41 notify_backup /path/to_backup.sh 42 notify_fault "/path/fault.sh VG_1" 43 notify /path/notify.sh 44 smtp_alert 表示是否开启邮件通知 45 } 46 vrrp_instance VI_1 { 47 state MASTER #可以是MASTER或BACKUP,不过当其他节点keepalived启动时会将priority比较大的节点选 举为MASTER,因此该项其实没有实质用途。 48 interface eth0 #节点固有IP(非VIP)的网卡,用来发VRRP包。 49 use_vmac <VMAC_INTERFACE> #是否使用VRRP的虚拟MAC地址。 50 dont_track_primary $#忽略VRRP网卡错误 51 track_interface { #监控以下网卡,如果任何一个不通就会切换到FALT状态 52 eth0 53 eth1 54 } 55 mcast_src_ip <IPADDR> #修改vrrp组播包的源地址,默认源地址为master的IP。(由于是组播,因此即使修改了源地址,该master还是能收到回应的) 56 lvs_sync_daemon_interface eth1 #绑定lvs syncd的网卡。 57 garp_master_delay 10 #当切为主状态后多久更新ARP缓存,默认5秒 58 virtual_router_id 1 #取值在0-255之间,用来区分多个instance的VRRP组播。 59 priority 100 #用来选举master的,要成为master,那么这个选项的值最好高于其他机器50个点,该项取值范围是1-255(在此范围之外会被识别成默认值100) 60 advert_int 1 #发VRRP包的时间间隔,即多久进行一次master选举(可以认为是健康查检时间间隔)。 61 authentication { #认证区域,认证类型有PASS和HA(IPSEC),推荐使用PASS(密码只识别前8位)。 62 auth_type PASS 63 auth_pass 12345678 64 } 65 virtual_ipaddress { 66 10.210.214.253/24 brd 10.210.214.255 dev eth0 67 192.168.1.11/24 brd 192.168.1.255 dev eth1 68 } 69 virtual_routes { #虚拟路由,当IP漂过来之后需要添加的路由信息。 70 172.16.0.0/12 via 10.210.214.1 71 192.168.1.0/24 via 192.168.1.1 dev eth1 72 default via 202.102.152.1 73 } 74 track_script { 脚本 75 chk_http_port 76 } 77 nopreempt #允许一个priority比较低的节点作为master,即使有priority更高的节点启动 78 preempt_delay 300 #启动多久之后进行接管资源(VIP/Route信息等),并提是没有nopreempt选项。 79 debug 80 notify_master <STRING>|<QUOTED-STRING> 81 notify_backup <STRING>|<QUOTED-STRING> 82 notify_fault <STRING>|<QUOTED-STRING> 83 notify <STRING>|<QUOTED-STRING> 84 smtp_alert 85 }
二, heartbeat @
01,heartbeat 是什么?
Linux-HA的全称是High-Availability Linux,它是一个开源项目,这个开源项目的目标是:通过社区开发者的共同努力,提供一个增强linux可靠性(reliability)、可用性(availability)和可服务性(serviceability)(RAS)的群集解决方案。其中Heartbeat就是Linux-HA项目中的一个组件,也是目前开源HA项目中最成功的一个例子,它提供了所有 HA 软件所需要的基本功能,比如心跳检测和资源接管、监测群集中的系统服务、在群集中的节点间转移共享 IP 地址的所有者等,通过它可以将资源(IP及程序服务等资源)从一台故障计算机快速转移到另一台运转正常的机器继续提供服务, 版本下载的话可以从Linux-HA的官方网站www.linux-ha.org下载到Heartbeat的最新版本。
02,heartbeat 原理
通过修改配置文件,指定哪一台Heartbeat服务器作为主服务器,则另一台将自动成为备份服务器。然后在指定备份服务器上配置Heartbeat守护进程来监听来自主服务器的心跳。如果备份服务器在指定时间内未监听到来自主服务器的心跳,就会启动故障转移程序,并取得主服务器上的相关资源服务所有权,接替主服务器继续不间断的提供服务,从而达到资源服务高可用性的目的。
以上描述的是Heartbeat主备的模式,Heartbeat还支持主主模式,即两台服务器互为主备,这时它们之间会相互发送报文来告诉对方自己当前的状态,如果在指定的时间内为收到对方发送的心跳报文,那么久认为对方失效或者宕机了,这时就会启动自身的资源接管模块来接管运行在对方主机上的资源或者服务,继续对用户提供服务。正常情况下,可以较好的实现主机故障后,业务仍不间断的持续运行。
keepalived主要控制IP飘移,配置应用简单,而且分层,layer3,4,5,各自配置极为简单。heartbeat不但可以控制IP飘移,更擅长对资源服务的控制,配置,应用比较复杂。lvs的高可用建议用keepavlived;业务的高可用用heartbeat。
03,headbeat 模块详解
😊ha.cg配置文件:
debugfile /var/log/ha-debug #用于记录heartbeat的调试信息 logfile /var/log/ha-log #用于记录heartbeat的日志信息 logfacility local0 #系统日志级别 keepalive 2 #设定心跳(监测)间隔时间,默认单位为秒 warntime 10 ##警告时间,通常为deadtime时间的一半 deadtime 30 # 超出30秒未收到对方节点的心跳,则认为对方已经死亡 initdead 120 #网络启动时间,至少为deadtime的两倍。 hopfudge 1 #可选项:用于环状拓扑结构,在集群中总共跳跃节点的数量 udpport 694 #使用udp端口694 进行心跳监测 ucast eth1 192.168.9.6 #采用单播,进行心跳监测,IP为对方主机IP auto_failback on #on表示当拥有该资源的属主恢复之后,资源迁移到属主上 node srv5.localdomain #设置集群中的节点,节点名须与uname –n相匹配 node srv6.localdomain #节点2 ping 192.168.8.2 192.168.9.7 #ping集群以外的节点,这里是网关和另一台机器,用于检测网络的连接性 respawn root /usr/lib/heartbeat/ipfail apiauth ipfail gid=root uid=root #设置所指定的启动进程的权限
😊认证文件authkeys:
用于配置心跳的加密方式,该文件主要是用于集群中两个节点的认证,采用的算法和密钥在集群 中节点上必须相同,目前提供了3种算法:md5,sha1和crc。其中crc不能够提供认证,它只能 够用于校验数据包是否损坏,而sha1,md5需要一个密钥来进行认证。三种认证方式的安全性依次提高,但是占用的系统资源也依次增加。如果heartbeat集群运行在安全的网络上,可以使用crc方式,如果HA每个节点的硬件配置很高,建议使用sha1,这种认证方式安全级别最高,如果是处于网络安全和系统资源之间,可以使用md5认证方式。
😊 资源文件(/etc/ha.d/haresources):
Haresources文件用于指定双机系统的主节点、集群IP、子网掩码、广播地址以及启动的服务等集群资源,文件每一行可以包含一个或多个资源脚本名,资源之间使用空格隔开,参数之间使用两个冒号隔开,在两个HA节点上该文件必须完全一致,此文件的一般格式为:
node-name network
node-name表示主节点的主机名,必须和ha.cf文件中指定的节点名一致,network用于设定集群的IP地址、子网掩码、网络设备标识等,需要注意的是,这里指定的IP地址就是集群对外服务的IP地址,resource-group用来指定需要heartbeat托管的服务,也就是这些服务可以由heartbeat来启动和关闭,如果要托管这些服务,必须将服务写成可以通过start/stop来启动和关闭的脚步,然后放到/etc/init.d/或者/etc/ha.d/resource.d/目录下,heartbeat会根据脚本的名称自动去/etc/init.d或者/etc/ha.d/resource.d/目录下找到相应脚步进行启动或关闭操作。
三, haproxy
01,什么是haproxy?
haproxy是一款负载均衡软件,它工作在7层模型上,可以分析数据包中的应用层协议,并按规则进行负载。通常这类7层负载工具也称为反向代理软件,nginx是另一款著名的反向代理软件。HAProxy提供了L4(TCP)和L7(HTTP)两种负载均衡能力(反向代理)
02,haproxy的特性?
特性有:
负载均衡:L4(伪四层)和L7两种模式,支持RR/静态RR/LC/IP Hash/URI Hash/URL_PARAM Hash/HTTP_HEADER Hash等丰富的负载均衡算法
健康检查:支持TCP和HTTP两种健康检查模式
会话保持:对于未实现会话共享的应用集群,可通过Insert Cookie/Rewrite Cookie/Prefix Cookie,以及上述的多种Hash方式实现会话保持
SSL:HAProxy可以解析HTTPS协议,并能够将请求解密为HTTP后向后端传输
HTTP请求重写与重定向
监控与统计:HAProxy提供了基于Web的统计信息页面,展现健康状态和流量数据。基于此功能,使用者可以开发监控程序来监控HAProxy的状态
😊会话保持:
任何一个反向代理软件,都必须具备这个基本的功能。这主要针对后端是应用服务器的情况,如果后端是静态服务器或缓存服务器,无需实现会话保持,因为它们是"无状态"的。如果反向代理的后端提供的是"有状态"的服务或协议时,必须保证请求过一次的客户端能被引导到同义服务端上。只有这样,服务端才能知道这个客户端是它曾经处理过的,能查到并获取到和该客户端对应的上下文环境(session上下文),有了这个session环境才能继续为该客户端提供后续的服务。这个可能不太好去理解,那我们就来简单举个例子。
客户端A向服务端B请求将C商品加入它的账户购物车,加入成功后,服务端B会在某个缓存中记录下客户端A和它的商品C,这个缓存的内容就是session上下文环境。而识别客户端的方式一般是设置session ID(如PHPSESSID、JSESSIONID),并将其作为cookie的内容交给客户端。客户端A再次请求的时候(比如将购物车中的商品下订单)只要携带这个cookie,服务端B就可以从中获取到session ID并找到属于客户端A的缓存内容,也就可以继续执行下订单部分的代码。假如这时使用负载均衡软件对客户端的请求进行负载,如果这个负载软件只是简单地进行负载转发,就无法保证将客户端A引导到服务端B,可能会引导到服务端X、服务端Y,但是X、Y上并没有缓存和客户端A对应的session内容,当然也无法为客户端A下订单。因此,反向代理软件必须具备将客户端和服务端"绑定"的功能,也就是所谓的提供会话保持,让客户端A后续的请求一定转发到服务端B上。
03,配置文件详解
主配置文件:
global:参数是进程级的,通常是和操作系统相关。这些参数一般只设置一次,如果配置无误,就不需要再次进行修改;
defaults:配置默认参数,这些参数可以被用到frontend,backend,Listen组件;
frontend:接收请求的前端虚拟节点,Frontend可以更加规则直接指定具体使用后端的backend;
backend:后端服务集群的配置,是真实服务器,一个Backend对应一个或者多个实体服务器;
Listen Fronted和backend的组合体。
global # 全局参数的设置
log 127.0.0.1 local0 info
# log语法:log <address_1>[max_level_1] # 全局的日志配置,使用log关键字,指定使用127.0.0.1上的syslog服务中的local0日志设备,记录日志等级为info的日志
user haproxy
group haproxy
# 设置运行haproxy的用户和组,也可使用uid,gid关键字替代之
daemon
# 以守护进程的方式运行
nbproc 16
# 设置haproxy启动时的进程数,根据官方文档的解释,我将其理解为:该值的设置应该和服务器的CPU核心数一致,即常见的2颗8核心CPU的服务器,即共有16核心,则可以将其值设置为:<=16 ,创建多个进程数,可以减少每个进程的任务队列,但是过多的进程数也可能会导致进程的崩溃。这里我设置为16
maxconn 4096
# 定义每个haproxy进程的最大连接数 ,由于每个连接包括一个客户端和一个服务器端,所以单个进程的TCP会话最大数目将是该值的两倍。
#ulimit -n 65536
# 设置最大打开的文件描述符数,在1.4的官方文档中提示,该值会自动计算,所以不建议进行设置
pidfile /var/run/haproxy.pid
# 定义haproxy的pid
defaults # 默认部分的定义
mode http
# mode语法:mode {http|tcp|health} 。http是七层模式,tcp是四层模式,health是健康检测,返回OK
log 127.0.0.1 local3 err
# 使用127.0.0.1上的syslog服务的local3设备记录错误信息
retries 3
# 定义连接后端服务器的失败重连次数,连接失败次数超过此值后将会将对应后端服务器标记为不可用
option httplog
# 启用日志记录HTTP请求,默认haproxy日志记录是不记录HTTP请求的,只记录“时间[Jan 5 13:23:46] 日志服务器[127.0.0.1] 实例名已经pid[haproxy[25218]] 信息[Proxy http_80_in stopped.]”,日志格式很简单。
option redispatch
# 当使用了cookie时,haproxy将会将其请求的后端服务器的serverID插入到cookie中,以保证会话的SESSION持久性;而此时,如果后端的服务器宕掉了,但是客户端的cookie是不会刷新的,如果设置此参数,将会将客户的请求强制定向到另外一个后端server上,以保证服务的正常。
option abortonclose
# 当服务器负载很高的时候,自动结束掉当前队列处理比较久的链接
option dontlognull
# 启用该项,日志中将不会记录空连接。所谓空连接就是在上游的负载均衡器或者监控系统为了探测该服务是否存活可用时,需要定期的连接或者获取某一固定的组件或页面,或者探测扫描端口是否在监听或开放等动作被称为空连接;官方文档中标注,如果该服务上游没有其他的负载均衡器的话,建议不要使用该参数,因为互联网上的恶意扫描或其他动作就不会被记录下来
option httpclose # 这个参数我是这样理解的:使用该参数,每处理完一个request时,haproxy都会去检查http头中的Connection的值,如果该值不是close,haproxy将会将其删除,如果该值为空将会添加为:Connection: close。使每个客户端和服务器端在完成一次传输后都会主动关闭TCP连接。与该参数类似的另外一个参数是“option forceclose”,该参数的作用是强制关闭对外的服务通道,因为有的服务器端收到Connection: close时,也不会自动关闭TCP连接,如果客户端也不关闭,连接就会一直处于打开,直到超时。
contimeout 5000
# 设置成功连接到一台服务器的最长等待时间,默认单位是毫秒,新版本的haproxy使用timeout connect替代,该参数向后兼容
clitimeout 3000
# 设置连接客户端发送数据时的成功连接最长等待时间,默认单位是毫秒,新版本haproxy使用timeout client替代。该参数向后兼容
srvtimeout 3000
# 设置服务器端回应客户度数据发送的最长等待时间,默认单位是毫秒,新版本haproxy使用timeout server替代。该参数向后兼容
listen status # 定义一个名为status的部分
bind 0.0.0.0:1080
# 定义监听的套接字
mode http
# 定义为HTTP模式
log global
# 继承global中log的定义
stats refresh 30s
# stats是haproxy的一个统计页面的套接字,该参数设置统计页面的刷新间隔为30s
stats uri /admin?stats
# 设置统计页面的uri为/admin?stats
stats realm Private lands
# 设置统计页面认证时的提示内容
stats auth admin:password
# 设置统计页面认证的用户和密码,如果要设置多个,另起一行写入即可
stats hide-version
# 隐藏统计页面上的haproxy版本信息
frontend http_80_in # 定义一个名为http_80_in的前端部分
bind 0.0.0.0:80
# http_80_in定义前端部分监听的套接字
mode http
# 定义为HTTP模式
log global
# 继承global中log的定义
option forwardfor
# 启用X-Forwarded-For,在requests头部插入客户端IP发送给后端的server,使后端server获取到客户端的真实IP
acl static_down nbsrv(static_server) lt 1
# 定义一个名叫static_down的acl,当backend static_sever中存活机器数小于1时会被匹配到
acl php_web url_reg /*.php$
#acl php_web path_end .php
# 定义一个名叫php_web的acl,当请求的url末尾是以.php结尾的,将会被匹配到,上面两种写法任选其一
acl static_web url_reg /*.(css|jpg|png|jpeg|js|gif)$
#acl static_web path_end .gif .png .jpg .css .js .jpeg
# 定义一个名叫static_web的acl,当请求的url末尾是以.css、.jpg、.png、.jpeg、.js、.gif结尾的,将会被匹配到,上面两种写法任选其一
use_backend php_server if static_down
# 如果满足策略static_down时,就将请求交予backend php_server
use_backend php_server if php_web
# 如果满足策略php_web时,就将请求交予backend php_server
use_backend static_server if static_web
# 如果满足策略static_web时,就将请求交予backend static_server
backend php_server #定义一个名为php_server的后端部分
mode http
# 设置为http模式
balance source
# 设置haproxy的调度算法为源地址hash
cookie SERVERID
# 允许向cookie插入SERVERID,每台服务器的SERVERID可在下面使用cookie关键字定义
option httpchk GET /test/index.php
# 开启对后端服务器的健康检测,通过GET /test/index.php来判断后端服务器的健康情况
server php_server_1 10.12.25.68:80 cookie 1 check inter 2000 rise 3 fall 3 weight 2
server php_server_2 10.12.25.72:80 cookie 2 check inter 2000 rise 3 fall 3 weight 1
server php_server_bak 10.12.25.79:80 cookie 3 check inter 1500 rise 3 fall 3 backup
# server语法:server [:port] [param*] # 使用server关键字来设置后端服务器;为后端服务器所设置的内部名称[php_server_1],该名称将会呈现在日志或警报中、后端服务器的IP地址,支持端口映射[10.12.25.68:80]、指定该服务器的SERVERID为1[cookie 1]、接受健康监测[check]、监测的间隔时长,单位毫秒[inter 2000]、监测正常多少次后被认为后端服务器是可用的[rise 3]、监测失败多少次后被认为后端服务器是不可用的[fall 3]、分发的权重[weight 2]、最后为备份用的后端服务器,当正常的服务器全部都宕机后,才会启用备份服务器[backup]
backend static_server
mode http
option httpchk GET /test/index.html
server static_server_1 10.12.25.83:80 cookie 3 check inter 2000 rise 3 fall 3
04,算法
1 1.balance roundrobin # 轮询,软负载均衡基本都具备这种算法 2 3 2.balance static-rr # 根据权重,建议使用 4 5 3.balance leastconn # 最少连接者先处理,建议使用 6 7 4.balance source # 根据请求源IP,建议使用 8 9 5.balance uri # 根据请求的URI 10 11 6.balance url_param,# 根据请求的URl参数'balance url_param' requires an URL parameter name 12 13 7.balance hdr(name) # 根据HTTP请求头来锁定每一次HTTP请求 14 15 8.balance rdp-cookie(name) # 根据据cookie(name)来锁定并哈希每一次TCP请求
四,LVS @
01,LVS是什么?
LVS的英文全称是Linux Virtual Server,即Linux虚拟服务器。它是我们国家的章文嵩博士的一个开源项目。在linux内存2.6中,它已经成为内核的一部分,在此之前的内核版本则需要重新编译内核。主要用于多服务器的负载均衡。它工作在网络层,可以实现高性能,高可用的服务器集群技术。它廉价,可把许多低性能的服务器组合在一起形成一个超级服务器。它易用,配置非常简单,且有多种负载均衡的方法。它稳定可靠,即使在集群的服务器中某台服务器无法正常工作,也不影响整体效果。另外可扩展性也非常好。
02,LVS的工作原理?
LVS 有两核心组成, ipvs与ipvsadm
ipvs: LVS核心实现,更具定义好的集群规则进行工作
ipvsadm:LVS管理工具,管理员通过ipvsadm定义或管理集群规则
LVS可以分为三大部分:
1.Load Balancer:这是LVS的核心部分,它好比我们网站MVC模型的Controller。它负责将客户的请求按照一定的算法分发到下一层不同的服务器进行处理,自己本身不做具体业务的处理。另外该层还可用监控下一层的状态,如果下一层的某台服务器不能正常工作了,它会自动把其剔除,恢复后又可用加上。该层由一台或者几台Director Server组成。
2.Server Array:该层负责具体业务。可有WEB Server、mail Server、FTP Server、DNS Server等组成。注意,其实上层的Director Server也可以当Real server用的。
3.Shared Storage:主要是提高上一层数据和为上一层保持数据一致
03,三种类型
😀LVS-DR:
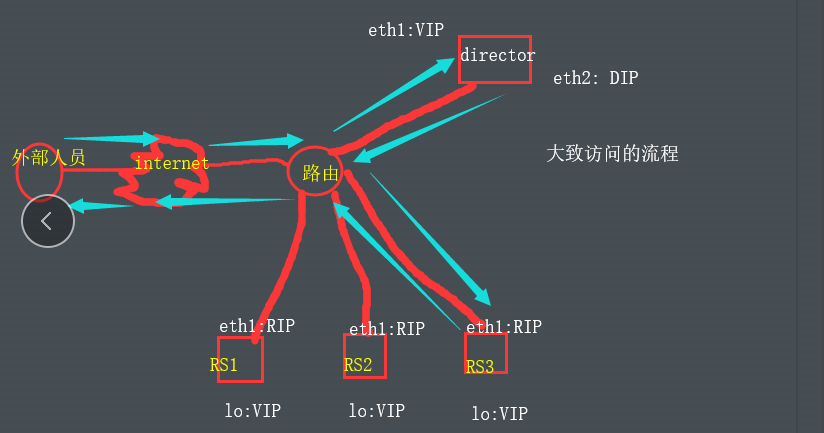
原理简述 当客户端向VIP发起请求时,[源CIP;目的VIP]数据包通过路由器发送到Director。然后Director不修改其源IP目 的iP。经过调度后将目的MAC改为RS的MAC,RS收到数据之后发现目的IP为本机的L0接口就将其收下,然后找 到数据再将源IP改为L0目的IP为CIP直接通过公网返回给客户端 架构特性 1.必须保证前端路由通过ARP地址解析将数据转发至Director,数据不能被RS接收 2.RS可以使用私网地址,也可以使用公网IP 3.Director只负责调度。 4.Director与RS必须在同一物理段中 5.不支持端口映射 6.RS的网关为前端路由,不能为Director 7.RS支持大多出OS(可以拒绝ARP响应的系统)
😀LVS-NAT:
原理简述
客户端向VIP发起请求连接,Director在经过调度之后选取RS,将本地端口与RS的端口做映射,然后RS
返还数据Director将数据返还客户端
LVS-NAT特性
1.RIP的网关必须与网关指向DIP
2.可以使用端口映射;即Director将客户端请求的IP端口转换为真是服务器的iP与端口
3.Director会成为系统的瓶颈所在,
4.RS可以为任意的操作系统
5.每台后端服务器的网关必须为调度器的内网地址
😀LSV-TUN:
原理简述 客户端向VIP发送请求时,[源CIP;目的VIP],Director经过调度轮询后选择一个RS后使用隧道技术再次封装后 向RS发送【源DIP;目的RIP [源CIP;目的VIP]】,RS通过隧道收到请求后拆开数据后得到[源CIP;目的VIP], 发现目的IP为自己L0接口的IP得,后就把数据收下,找到数据后将数据直接通过公网返还给客户端[源VIP;目的 CIP] 特性 1.RIP、DIP、VIP必须为公网IP 2.RS网关不指向Director 3.请求报文由Director转发至RS,回复报文由RS直接发送至客户端 4.不支持端口映射 5.RS的OS必须支持隧道技术 6.Director与RS、RS与RS可以跨网段、跨机房。
04,LVS十种算法:
1.轮询调度
轮询调度(Round Robin 简称'RR')算法就是按依次循环的方式将请求调度到不同的服务器上,该算法最大的特点就是实现简单。轮询算法假设所有的服务器处理请求的能力都一样的,调度器会将所有的请求平均分配给每个真实服务器。
2.加权轮询调度
加权轮询(Weight Round Robin 简称'WRR')算法主要是对轮询算法的一种优化与补充,LVS会考虑每台服务器的性能,并给每台服务器添加一个权值,如果服务器A的权值为1,服务器B的权值为2,则调度器调度到服务器B的请求会是服务器A的两倍。权值越高的服务器,处理的请求越多。
3.最小连接调度
最小连接调度(Least Connections 简称'LC')算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态的调度算法,它通过服务器当前活跃的连接数来估计服务器的情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中断或者超时,其连接数减1。
(集群系统的真实服务器具有相近的系统性能,采用最小连接调度算法可以比较好地均衡负载。)
4.加权最小连接调度
加权最少连接(Weight Least Connections 简称'WLC')算法是最小连接调度的超集,各个服务器相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。调度器可以自动问询真实服务器的负载情况,并动态地调整其权值。
5.基于局部的最少连接
基于局部的最少连接调度(Locality-Based Least Connections 简称'LBLC')算法是针对请求报文的目标IP地址的 负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同一台服务器,来提高各台服务器的访问局部性和Cache命中率,从而提升整个集群系统的处理能力。LBLC调度算法先根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则使用'最少连接'的原则选出一个可用的服务器,将请求发送到服务器。
6.带复制的基于局部性的最少连接
带复制的基于局部性的最少连接(Locality-Based Least Connections with Replication 简称'LBLCR')算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统,它与LBLC算法不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。按'最小连接'原则从该服务器组中选出一一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载,则按'最小连接'原则从整个集群中选出一台服务器,将该服务器加入到这个服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。
7.目标地址散列调度
目标地址散列调度(Destination Hashing 简称'DH')算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。
8.源地址散列调度U
源地址散列调度(Source Hashing 简称'SH')算法先根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且并未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法的相同,它的算法流程与目标地址散列调度算法的基本相似。
9.最短的期望的延迟
最短的期望的延迟调度(Shortest Expected Delay 简称'SED')算法基于WLC算法。举个例子吧,ABC三台服务器的权重分别为1、2、3 。那么如果使用WLC算法的话一个新请求进入时它可能会分给ABC中的任意一个。使用SED算法后会进行一个运算A:(1+1)/1=2 B:(1+2)/2=3/2 C:(1+3)/3=4/3 就把请求交给得出运算结果最小的服务器。
1 0.最少队列调度
最少队列调度(Never Queue 简称'NQ')算法,无需队列。如果有realserver的连接数等于0就直接分配过去,不需要在进行SED运算。
五,联系
01,keepalived+haproxy+web
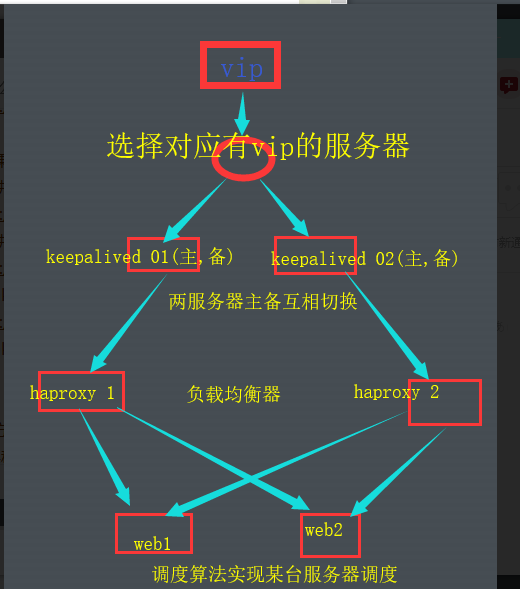
02,keepalived+lvs+web

03, heartbeat+haproxy+web
后续其实相差无几
主要是haproxy与lvs区别
lvs的是通过vrrp协议进行数据包转发的,提供的是4层的负载均衡。特点是效率高,机器网卡比较吃的紧张。
haproxy可以提供4层或7层的数据转发服务,能做到7层的好处是可以根据服务所处的状态等进行负载。
1、 抗负载能力强,因为lvs工作方式的逻辑是非常之简单,而且工作在网络4层仅做请求分发之用,没有流量,所以在效率上基本不需要太过考虑。在我手里的 lvs,仅仅出过一次问题:在并发最高的一小段时间内均衡器出现丢包现象,据分析为网络问题,即网卡或linux2.4内核的承载能力已到上限,内存和 cpu方面基本无消耗。
2、配置性低,这通常是一大劣势,但同时也是一大优势,因为没有太多可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率
3、工作稳定,因为其本身抗负载能力很强,所以稳定性高也是顺理成章,另外各种lvs都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,lvs会自动判别,所以系统整体是非常稳定的。
4、无流量,上面已经有所提及了。lvs仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的IO性能不会受到大流量的影响。
5、基本上能支持所有应用,因为lvs工作在4层,所以它可以对几乎所有应用做负载均衡,包括http、数据库、聊天室等等。
1,HAProxy支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡。
2,支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态
3,HAProxy负载均衡策略非常多,HAProxy的负载均衡算法现在具体有如下8种:
② static-rr,表示根据权重,建议关注;
③ leastconn,表示最少连接者先处理,建议关注;
④ source,表示根据请求源IP,这个跟Nginx的IP_hash机制类似,我们用其作为解决session问题的一种方法,建议关注;
⑤ ri,表示根据请求的URI;
⑥ rl_param,表示根据请求的URl参数’balance url_param’ requires an URL parameter name;
⑦ hdr(name),表示根据HTTP请求头来锁定每一次HTTP请求;
⑧ rdp-cookie(name),表示根据据cookie(name)来锁定并哈希每一次TCP请求。
六, 三大负载均衡器特点:
LVS的特点是:
1、抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生;
2、配置性比较低,这是一个缺点也是一个优点,因为没有可太多配置的东西,所以并不需要太多接触,大大减少了人为出错的几率;
3、工作稳定,自身有完整的双机热备方案;
4、无流量,保证了均衡器IO的性能不会收到大流量的影响;
5、应用范围比较广,可以对所有应用做负载均衡;
6、LVS需要向IDC多申请一个IP来做Visual IP,因此需要一定的网络知识,所以对操作人的要求比较高。
Nginx的特点是:
1、工作在网络的7层之上,可以针对http应用做一些分流的策略,比如针对域名、目录结构;
2、Nginx对网络的依赖比较小;
3、Nginx安装和配置比较简单,测试起来比较方便;
4、也可以承担高的负载压力且稳定,一般能支撑超过1万次的并发;
5、Nginx可以通过端口检测到服务器内部的故障,比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点,不过其中缺点就是不支持url来检测;
6、Nginx对请求的异步处理可以帮助节点服务器减轻负载;
7、Nginx能支持http和Email,这样就在适用范围上面小很多;
8、不支持Session的保持、对Big request header的支持不是很好,另外默认的只有Round-robin和IP-hash两种负载均衡算法。
HAProxy的特点是:
1、HAProxy是工作在网络7层之上。
2、能够补充Nginx的一些缺点比如Session的保持,Cookie的引导等工作
3、支持url检测后端的服务器出问题的检测会有很好的帮助。
4、更多的负载均衡策略比如:动态加权轮循(Dynamic Round Robin),加权源地址哈希(Weighted Source Hash),加权URL哈希和加权参数哈希(Weighted Parameter Hash)已经实现
5、单纯从效率上来讲HAProxy更会比Nginx有更出色的负载均衡速度。
6、HAProxy可以对Mysql进行负载均衡,对后端的DB节点进行检测和负载均衡

 浙公网安备 33010602011771号
浙公网安备 33010602011771号