Windows平台下安装Hadoop
1、安装JDK1.6或更高版本
官网下载JDK,安装时注意,最好不要安装到带有空格的路径名下,例如:Programe Files,否则在配置Hadoop的配置文件时会找不到JDK(按相关说法,配置文件中的路径加引号即可解决,但我没测试成功)。
2、安装Cygwin
Cygwin是Windows平台下模拟Unix环境的工具,需要在安装Cygwin的基础上安装Hadoop,下载地址:http://www.cygwin.com/
根据操作系统的需要下载32位或64的安装文件。
1)、双击下载好的安装文件,点击下一步,选择install from internet
2)、选择安装路径
3)、选择local Package Directory
4)、选择您的Internet连接方式
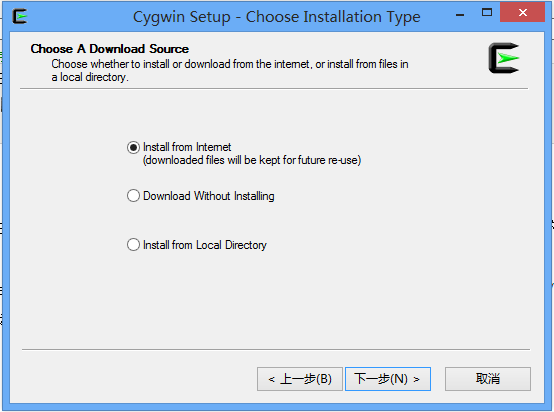
5)、选择合适的安装源,点击下一步
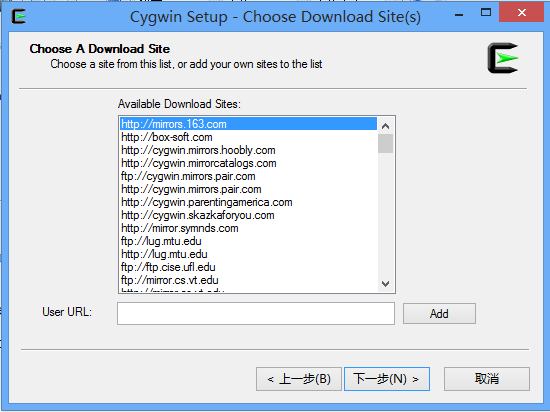
6)、在Select Packages界面里,Category展开net,选择如下openssh和openssl两项

如果要在Eclipe上编译Hadoop,需要安装Category为Base下的sed

如果想在Cygwin上直接修改hadoop的配置文件,可以安装Editors下的vim
7)、点击“下一步”,等待安装完成。
3、配置环境变量
在“我的电脑”上点击右键,选择菜单中的“属性",点击属性对话框上的高级页签,点击”环境变量"按钮,在系统变量列表里双击“Path”变量,在变量值后输入安装的Cygwin的bin目录,例如:D:\hadoop\cygwin64\bin
4、安装sshd服务
双击桌面上的Cygwin图标,启动Cygwin,执行ssh-host-config -y命令
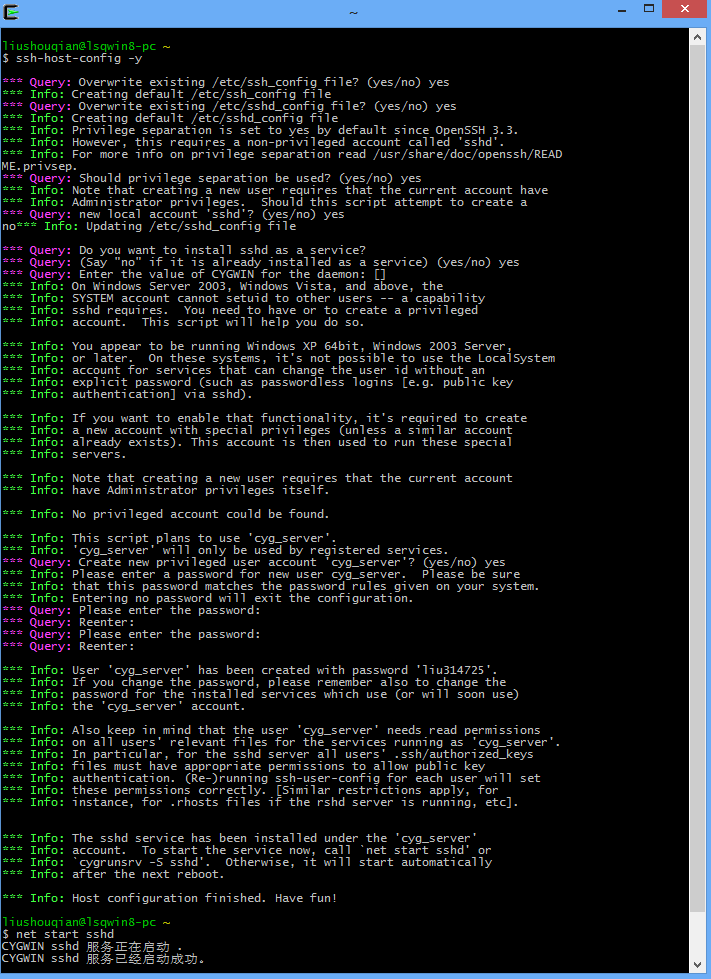
执行后,会提示输入密码,否则会退出该配置,此时输入密码和确认密码,回车。最后出现Host configuration finished.Have fun!表示安装成功。
输入net start sshd,启动服务。或者在系统的服务里找到并启动Cygwin sshd服务。
可能会遇到无法安装和启动sshd服务的问题,可参考此连接http://www.cnblogs.com/kinglau/p/3261886.html。
另外如果是Win8操作系统,启动Cygwin时,需要以管理员身份运行(右键图标,选择以管理员身份运行),否则会因为权限问题,提示“发生系统错误5”。
5、配置SSH免密码登录
执行ssh-keygen命令生成密钥文件
如下图所示,输入:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa,注意-t -P -f参数区分大小写。
ssh-keygen是生成密钥命令
-t 表示指定生成的密钥类型(dsa,rsa)
-P表示提供的密语
-f指定生成的密钥文件。
注意:~代表当前用户的文件夹,/home/用户名
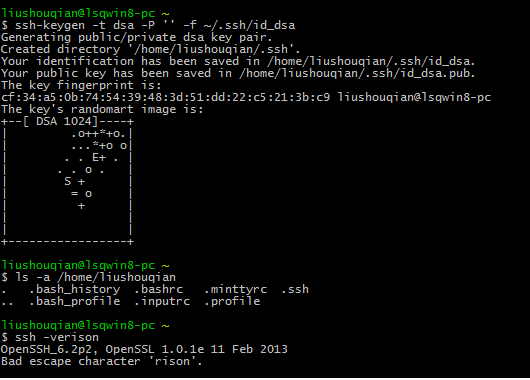
执行此命令后,在你的Cygwin\home\用户名 路径下面会生成.ssh文件夹,可以通过命令ls -a /home/用户名 查看,ssh -version命令查看版本。
执行完ssh-keygen命令后,再执行下面命令,就可以生成authorized_keys文件了。
cd ~/.ssh/
cp id_dsa.pub authorized_keys
如下图所示:

然后执行exit命令,退出Cygwin窗口
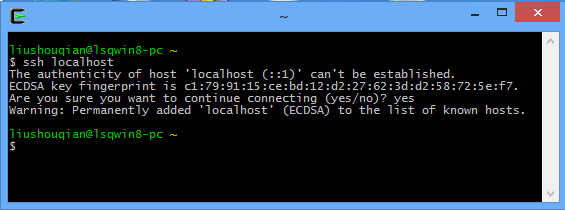
6、再次在桌面上双击Cygwin图标,打开Cygwin窗口,执行ssh localhost命令,第一次执行该命令会有提示,输入yes后,回车即可。如下图所示
7、安装Hadoop
hadoop官网下载http://hadoop.apache.org/releases.html。
把hadoop压缩包解压到/home/用户名 目录下,文件夹名称更改为hadoop,可以不修改,但后边在执行命令时稍显麻烦。
(1)单机模式配置方式
单机模式不需要配置,这种方式下,Hadoop被认为是一个单独的Java进程,这种方式经常用来调试。
(2)伪分布模式
可以把伪分布模式看作是只有一个节点的集群,在这个集群中,这个节点既是Master,也是Slave,既是NameNode,也是DataNode,既是JobTracker,也是TaskTracker。
这种模式下修改几个配置文件即可。
配置hadoop-env.sh,记事本打开改文件,设置JAVA_HOME的值为你的JDK安装路径,例如:
JAVA_HOME="D:\hadoop\Java\jdk1.7.0_25"
配置core-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> <property> <name>mapred.child.tmp</name> <value>/home/u/hadoop/tmp</value> </property> </configuration>
配置hdfs-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
配置mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> <property> <name>mapred.child.tmp</name> <value>/home/u/hadoop/tmp</value> </property> </configuration>
8、启动Hadoop
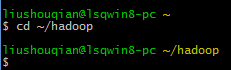
打开Cgywin窗口,执行cd ~/hadoop命令,进入hadoop文件夹,如下图:
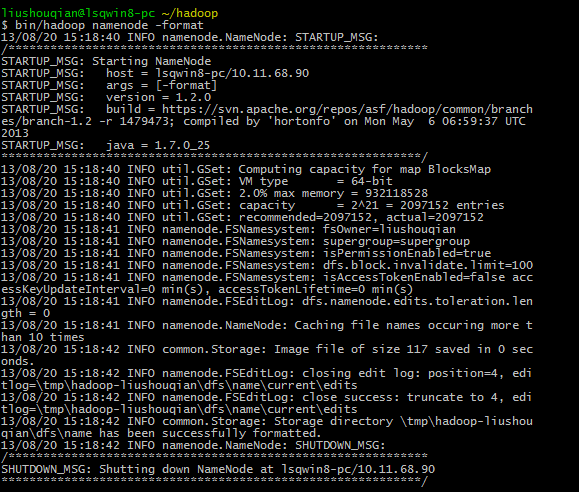
启动Hadoop前,需要先格式化Hadoop的文件系统HDFS,执行命令:bin/hadoop namenode -format
注意namenode要小些,否则如果输入NameNode,会提示错误,找不到或无法加载主类NameNode。执行正确命令后如下图所示:
输入命令 bin/start-all.sh,启动所有进程,如下图:

接下来,验证是否安装成功
打开浏览器,分别输入下列网址,如果能够正常浏览,说明安装成功。
http://localhost:50030,回车打开MapReduce的web页面,如下图(页面部分截图):

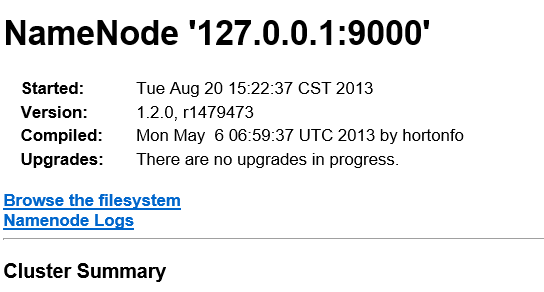
http://localhost:50070,回车打开HDFS的web页面,如下图(页面部分截图):
第一次启动后,如果都不能浏览,或不能浏览某一个,退出Cygwin,重新打开Cygwin,执行bin/start-all.sh命令。
如果只想启动MapReduce,可执行bin/start-mapred.sh命令。
如果只想启动HDFS,可执行bin/start-dfs.sh命令。
参考文献:
本文参考和引用了《Hadoop实战》(作者:陆嘉恒)中的章节“2.3在Windows上安装与配置Hadoop”。
特此声明,如果涉及到版权问题,请告知。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号