消息中间件Notify和MetaQ-阿里中间件
3.1、Notify
Notify是淘宝自主研发的一套消息服务引擎,是支撑双11最为核心的系统之一,在淘宝和支付宝的核心交易场景中都有大量使用。消息系统的核心作用就是三点:解耦,异步和并行。下面让我以一个实际的例子来说明一下解耦异步和并行分别所代表的具体意义吧:
假设我们有这么一个应用场景,为了完成一个用户注册淘宝的操作,可能需要将用户信息写入到用户库中,然后通知给红包中心给用户发新手红包,然后还需要通知支付宝给用户准备对应的支付宝账号,进行合法性验证,告知sns系统给用户导入新的用户等10步操作。
那么针对这个场景,一个最简单的设计方法就是串行的执行整个流程,如图3-1所示:

图3-1-用户注册流程
这种方式的最大问题是,随着后端流程越来越多,每步流程都需要额外的耗费很多时间,从而会导致用户更长的等待延迟。自然的,我们可以采用并行的方式来完成业务,能够极大的减少延迟,如图3-2所示。

图3-2-用户注册流程-并行方式
但并行以后又会有一个新的问题出现了,在用户注册这一步,系统并行的发起了4个请求,那么这四个请求中,如果通知SNS这一步需要的时间很长,比如需要10秒钟的话,那么就算是发新手包,准备支付宝账号,进行合法性验证这几个步骤的速度再快,用户也仍然需要等待10秒以后才能完成用户注册过程。因为只有当所有的后续操作全部完成的时候,用户的注册过程才算真正的“完成”了。用户的信息状态才是完整的。而如果这时候发生了更严重的事故,比如发新手红包的所有服务器因为业务逻辑bug导致down机,那么因为用户的注册过程还没有完全完成,业务流程也就是失败的了。这样明显是不符合实际的需要的,随着下游步骤的逐渐增多,那么用户等待的时间就会越来越长,并且更加严重的是,随着下游系统越来越多,整个系统出错的概率也就越来越大。
通过业务分析我们能够得知,用户的实际的核心流程其实只有一个,就是用户注册。而后续的准备支付宝,通知sns等操作虽然必须要完成,但却是不需要让用户等待的。 这种模式有个专业的名词,就叫最终一致。为了达到最终一致,我们引入了MQ系统。业务流程如下:
主流程如图3-3所示:

图3-3-用户注册流程-引入MQ系统-主流程
异步流程如图3-4所示:
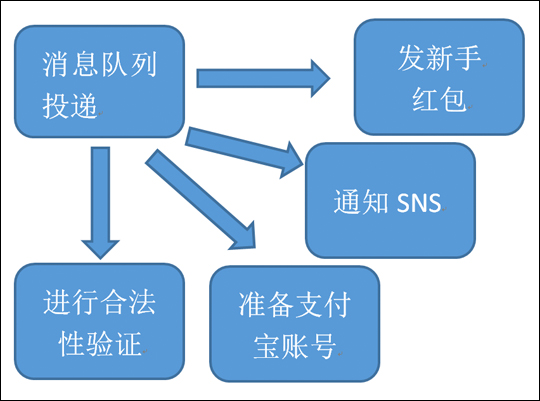
图3-4-用户注册流程-引入MQ系统-异步流程
核心原理
Notify在设计思路上与传统的MQ有一定的不同,他的核心设计理念是
1. 为了消息堆积而设计系统
2. 无单点,可自由扩展的设计
下面就请随我一起,进入到我们的消息系统内部来看看他设计的核心原理
- 为了消息堆积而设计系统在市面上的大部分MQ产品,大部分的核心场景就是点对点的消息传输通道,然后非常激进的使用内存来提升整体的系统性能,这样做虽然标称的tps都能达到很高,但这种设计的思路是很难符合大规模分布式场景的实际需要的。
在实际的分布式场景中,这样的系统会存在着较大的应用场景瓶颈,在后端有大量消费者的前提下,消费者出现问题是个非常常见的情况,而消息系统则必须能够在后端消费不稳定的情况下,仍然能够保证用户写入的正常并且TPS不降,是个非常考验消息系统能力的实际场景。
也因为如此,在Notify的整体设计中,我们最优先考虑的就是消息堆积问题,在目前的设计中我们使用了持久化磁盘的方式,在每次用户发消息到Notify的时候都将消息先落盘,然后再异步的进行消息投递,而没有采用激进的使用内存的方案来加快投递速度。
这种方式,虽然系统性能在峰值时比目前市面的MQ效率要差一些,但是作为整个业务逻辑的核心单元,稳定,安全可靠是系统的核心诉求。 - 无单点,可自由扩展的设计

图3-5-Notify系统组成结构
图3-5展示了组成Notify整个生态体系的有五个核心的部分。
- 发送消息的集群这主要是业务方的机器,这些APP的机器上是没有任何状态信息的,可以随着用户请求量的增加而随时增加或减少业务发送方的机器数量,从而扩大或缩小集群能力。
- 配置服务器集群(Config server)这个集群的主要目的是动态的感知应用集群,消息集群机器上线与下线的过程,并及时广播给其他集群。如当业务接受消息的机器下线时,config server会感知到机器下线,从而将该机器从目标用户组内踢出,并通知给notify server,notify server 在获取通知后,就可以将已经下线的机器从自己的投递目标列表中删除,这样就可以实现机器的自动上下线扩容了。
- 消息服务器(Notify Server)消息服务器,也就是真正承载消息发送与消息接收的服务器,也是一个集群,应用发送消息时可以随机选择一台机器进行消息发送,任意一台server 挂掉,系统都可以正常运行。当需要增加处理能力时,只需要简单地增加notify Server就可以了
- 存储(Storage)Notify的存储集群有多种不同的实现方式,以满足不同应用的实际存储需求。针对消息安全性要求高的应用,我们会选择使用多份落盘的方式存储消息数据,而对于要求吞吐量而不要求消息安全的场景,我们则可以使用内存存储模型的存储。自然的,所有存储也被设计成了随机无状态写入存储模型以保障可以自由扩展。
- 消息接收集群业务方用于处理消息的服务器组,上下线机器时候也能够动态的由config server 感知机器上下线的时机,从而可以实现机器自动扩展。
3.3、MetaQ
METAQ是一款完全的队列模型消息中间件,服务器使用Java语言编写,可在多种软硬件平台上部署。客户端支持Java、C++编程语言,已于2012年3月对外开源,开源地址是: http://metaq.taobao.org/ 。MetaQ大约经历了下面3个阶段
- 在2011年1月份发布了MetaQ 1.0版本,从Apache Kafka衍生而来,在内部主要用于日志传输。
- 在2012年9月份发布了MetaQ 2.0版本,解决了分区数受限问题,在数据库binlog同步方面得到了广泛的应用。
- 在2013年7月份发布了MetaQ 3.0版本,MetaQ开始广泛应用于订单处理,cache同步、流计算、IM实时消息、binlog同步等领域。MetaQ3.0版本已经开源, 参见这里
综上,MetaQ借鉴了Kafka的思想,并结合互联网应用场景对性能的要求,对数据的存储结构进行了全新设计。在功能层面,增加了更适合大型互联网特色的功能点。

图3-6-MetaQ整体结构
如图3-6所示,MetaQ对外提供的是一个队列服务,内部实现也是完全的队列模型,这里的队列是持久化的磁盘队列,具有非常高的可靠性,并且充分利用了操作系统cache来提高性能。
- 是一个队列模型的消息中间件,具有高性能、高可靠、高实时、分布式特点。
- Producer、Consumer、队列都可以分布式。
- Producer向一些队列轮流发送消息,队列集合称为Topic,Consumer如果做广播消费,则一个consumer实例消费这个Topic对应的所有队列,如果做集群消费,则多个Consumer实例平均消费这个topic对应的队列集合。
- 能够保证严格的消息顺序
- 提供丰富的消息拉取模式
- 高效的订阅者水平扩展能力
- 实时的消息订阅机制
- 亿级消息堆积能力
MetaQ存储结构
MetaQ的存储结构是根据阿里大规模互联网应用需求,完全重新设计的一套存储结构,使用这套存储结构可以支持上万的队列模型,并且可以支持消息查询、分布式事务、定时队列等功能,如图3-7所示。

图3-7-MetaQ存储体系
MetaQ单机上万队列
MetaQ内部大部分功能都靠队列来驱动,那么必须支持足够多的队列,才能更好的满足业务需求,如图所示,MetaQ可以在单机支持上万队列,这里的队列全部为持久化磁盘方式,从而对IO性能提出了挑战。MetaQ是这样解决的
- Message全部写入到一个独立的队列,完全的顺序写
- Message在文件的位置信息写入到另外的文件,串行方式写。
通过以上方式,既做到数据可靠,又可以支持更多的队列,如图3-8所示。

图3-8-MetaQ单机上万队列
MetaQ与Notify区别
- Notify侧重于交易消息,分布式事务消息方面。
- MetaQ侧重于顺序消息场景,例如binlog同步。以及主动拉消息场景,例如流计算等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号