结对项目-最长单词链
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/buaa/BUAA_SE_2019_LJ |
| 这个作业的要求在哪里 | https://edu.cnblogs.com/campus/buaa/BUAA_SE_2019_LJ/homework/2638 |
| 我在这个课程的目标是 | 学会软件工程,为以后工作打好基础。 |
| 这个作业在哪个具体方面帮助我实现目标 | 实践了结对编程,体会了软件工程的做法 |
1.Github项目地址:
2.在开始实现程序之前,在下述PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 840 | 760 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 50 | 40 |
| · Coding | · 具体编码 | 500 | 480 |
| · Code Review | · 代码复审 | 40 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 150 | 60 |
| Reporting | 报告 | 60 | 105 |
| · Test Report | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| 合计 | 920 | 1905 |
3.看教科书和其它资料中关于Information Hiding, Interface Design, Loose Coupling的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的
- Information Hiding信息隐藏
这是指模块内不需要暴露的信息要隐藏起来,也就是做好模块的封装工作。作为计算模块的主要负责人,一个很重要的工作就是模块的封装、信息的隐藏,可能避免重要信息外泄引发不可预测的异常等,保证程序安全性。 - Interface Design接口设计
接口是用于交互的,所以在设计接口时,主要需要考虑的是,“我们会接受哪些信息”和“我们需要反馈哪些信息”,类似于函数里面接受什么参数、返回什么信息。接口设计对软件工程团队合作十分重要,同时应该遵循OO课讲过的接口设计六大原则。 - Loose Coupling松耦合
IT界有一句很著名的口号——强内聚、松耦合:
我们的程序要模块化,模块要完成明确的一组关联的服务功能,要求它的各部分是相关的、有机组合起来是完整体(外部程序来看黑盒子),模块的内部各成分之间相关联程度要尽可能高(强内聚);而模块与模块之间又要求是可分拆的、少依赖的(松耦合)。
本次结对项目中,在构造类时,比较注意类的变量和函数的封装,从而保证程序的安全性。其次,在分工前约定好了接口,以便于后续的代码整合。在松耦合方面,我们在设计借口而的时候就考虑到这一点,设计模块功能和接口的时候尽量让模块之间的耦合更松,同时在进行GUI部分的时候,也用到了Model View Controller这个软件设计典范,将计算模型、视图界面、控制器分离进行代码,这三个大模块也实现了“松耦合”。
4.计算模块接口的设计与实现过程。 设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处
在计算模块中,一共有4个类,包括Input类:处理命令行输入的类,Readin类,从文件中读入单词的类,Genlist类:搜索并生成单词列表的类, Core类:封装好的接口类。
Input类有两个函数
| 函数名 | 函数作用 | 调用关系 |
|---|---|---|
| CompareStr | 用来比较读入的字符串最后是不是”.txt“ | 无 |
| InputHandle | 用来处理命令行的输入,修改Input类变量 | CompareStr |
Readin类中有四个函数
| 函数名 | 函数作用 | 调用关系 |
|---|---|---|
| compare | 重定向sort的比较函数,变成降序 | 无 |
| compare_str | 重定向sort的比较函数,改成字符串比较 | 无 |
| GetWords | 从文件中读取单词,到Words里,修改类成员变量 | 无 |
| ClassifyWords | 将已经读入的单词分类,建立26*26个vector,存放以某个字母开头以某个字母结尾的所有单词,并将他们排序 | compare、compare_str |
GenList类中有十个函数
| 函数名 | 函数作用 | 调用关系 |
|---|---|---|
| PrintRoad | 输出搜到的路径,路径是有环的时候搜到的 | 无 |
| ClassifyWords | 单词分类,将已经读入的单词分类,建立26*26个vector,存放以某个字母开头以某个字母结尾的所有单词,并将他们排序 | 无 |
| SerchList | 在已经排过序的单词中查找单词链,适用于无环模式,运用深度优先搜索的方式,并且采用剪枝 | 无 |
| SerchCircle | 查找单词列表中有没有环,如果不是-r模式,有环需要报错 | 无 |
| SerchListCircle | 有环的模式下查找单词链,运用深度优先搜索的方式 | 无 |
| 输出查找到的单词链,单词链是无环模式下找到的 | 无 | |
| SerchListLastMode | 规定结束字母并且是无环模式下找到单词链 | 无 |
| gen_chain_word | 模式是-w的时候,按照传入的各个参数查找单词链,存到result里,返回单词链长度 | PrintRoad、ClassifyWords、SerchList、SerchCircle、SerchListCircle、Print、SerchListLastMode、GetOutDeg |
| gen_chain_char | 模式是-c的时候,按照传入的各个参数查找单词链,存到result里,返回单词链长度 | PrintRoad、ClassifyWords、SerchList、SerchCircle、SerchListCircle、Print、SerchListLastMode、GetOutDeg |
| GetOutDeg | 得到所有字母的出度 | 无 |
Core类中有两个函数:
| 函数名 | 函数作用 | 调用关系 |
|---|---|---|
| gen_chain_word | 实例化GenList类,调用GenList类中gen_chain_word,实现封装 | GenList->gen_chain_word |
| gen_chain_char | 实例化GenList类,调用GenList类中gen_chain_char,实现封装 | GenList->gen_chain_char |
使用的时候,首先调用Input类中的InputHandle来处理命令行参数,处理完后,这个类中的变量已经被修改,之后拿到修改后的变量来调用Readin类中的GetWords函数,得到单词数组,之后实例化Core类,根据Input类中的类变量来确定调用Core中的哪一个函数,如果是-w模式就调用gen_chain_word函数,如果是-c模式就调用gen_chain_char函数。
算法有两部分,一部分是不可以存在环的,另一部分是可以存在环的。
不可以存在环的部分,主要算法是深度优先搜索,算法把每个字母作为图的一个节点,因为不存在环,所以从一个字母到一个字母只能走一遍,所以可以忽略相同开始和结束字母的所有单词。之后进行深度优先搜索,在搜索的过程中,进行剪枝的操作,当一个点已经走完之后,这个点到结尾的最大深度已经可以知道,这个时候我们记录下来这个最大深度,如果这个点出度为0,那么这个点的最大深度为0,在进入递归前,判断这个点有没有被走过,如果被走过了,就不进入这个点的递归,这样就减少了很多进入递归的次数,从而使速度变快。
这个算法的独到之处在于这个算法减少了递归的次数,做到了一个剪枝的操作,并且之后记录下来了最大的长度,相当于每个边最多只走一遍,也就是算法的最大复杂度为26*26,类似于动态规划的速度,并且代码从深度优先搜索上的基础而来,代码也比较好写易懂。
对于存在环的部分,使用深度优先搜索,因为可以存在环,所以以单词作为节点,进行了部分剪枝,当一个当前最大路径中存在一个字母,从这个字母开始的所有边都走过,那么这个时候,就不需要以这个点为起点开始搜路,因为以这个点开始的所有点都被走过,路径的最长长度也小于这个现在的最长长度,经过这个剪枝操作,可以使得速度快很多。
在查找与当前节点相连的边的时候,记录下了那些字母可能与这个点相连,这样遍历的时候就不需要遍历26个字母,加快了查找的速度。进行了剪枝操作,使得速度变快,整体代码思路也是从深度优先搜索开始设计,所以代码比较好写易懂。
查找环的部分采用拓扑排序的办法。首先查找收尾字母一样的单词序列,如果长度大于两个,那么就成环,之后,按照单词的收尾字母来初始化每个字母的入度,从入度为0的点开始删掉,并且与它相连的点的入度减一,重复这个操作直到没有点可以被删掉,最后遍历每个点的入度,如果有大于0的点,那么说明成环。
采用拓扑排序的方式,避免了深度优先搜索的速度慢,并且代码简洁效率高。
5.阅读有关UML的内容:https://en.wikipedia.org/wiki/Unified_Modeling_Language。画出UML图显示计算模块部分各个实体之间的关系(画一个图即可)。
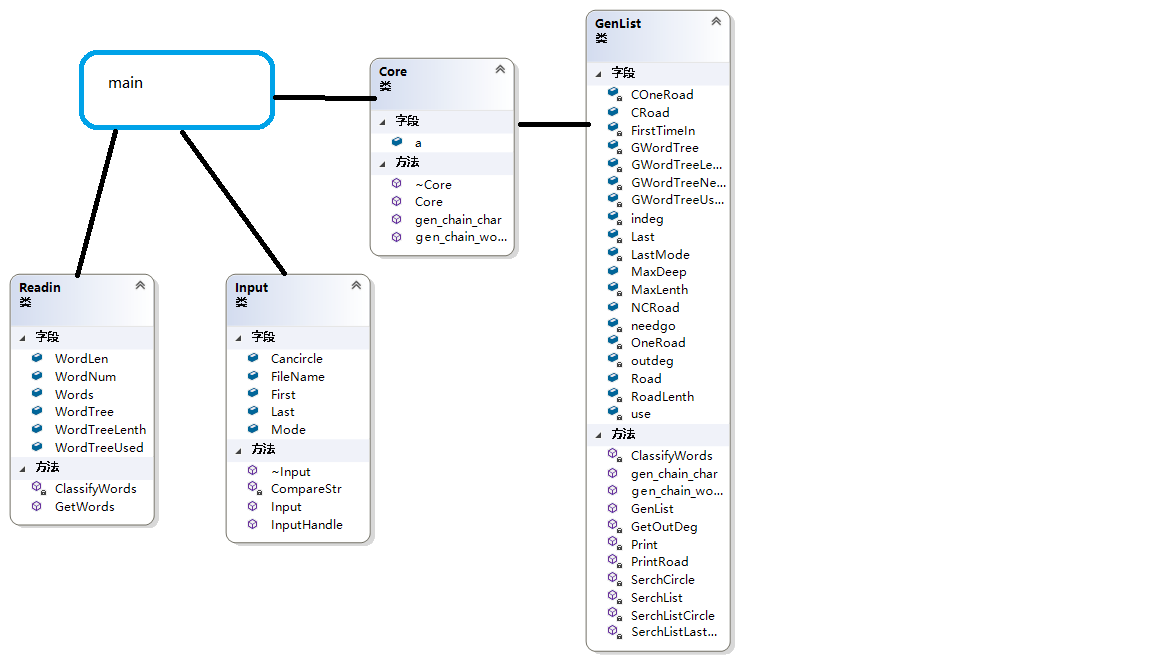
类图画法:使用VS2017,右键点击项目,找到查看,右边会有类图,之后点击图,就看到各个类的属性关系,保存类图,自己补充调用关系即可。
6.计算模块接口部分的性能改进。 记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2015/2017的性能分析工具自动生成),并展示你程序中消耗最大的函数
在改进计算模块上,一共花费了大约12小时,主要改进了算法在无环的时候的搜索速度,程序最开始的时候,计算无环的算法是无任何剪枝的深度优先搜索,这样,最慢的情况是26!,显然,这样搜索的速度太慢,所以要进行优化,这部分,我们主要进行了剪枝的优化,首先我记录了每一个节点到最终节点的距离,如果这个点本身就是最终节点,那么就记录它的距离为0,并且,如果这个点已经有到结尾的最大距离,那么就不进入这个点的递归,也就是不进入下一层,这样就少了很多重复递归的操作,走过的边不会再次被走到,所以就使得代码运行速度显著提高。并且,有些计算vector的size的函数在for中被重复使用,在把这些提出来以后,代码运行速度变高。开始,成环部分进行深度优先搜索的时候,每次进入递归都要把建好的单词图复制一份传入下一层,这个复制操作很慢,所以改进的过程中,把这个图放到类变量中,就不需要每次都传进去,这样速度快了十倍以上,之后,思考了剪枝的方式,在当前最长路径中如果有一个字母,它的所有后继都被用到,这个时候,最长的单词链不可能以这个字母为开头,所以可以减少遍历的次数,速度快了五倍左右。
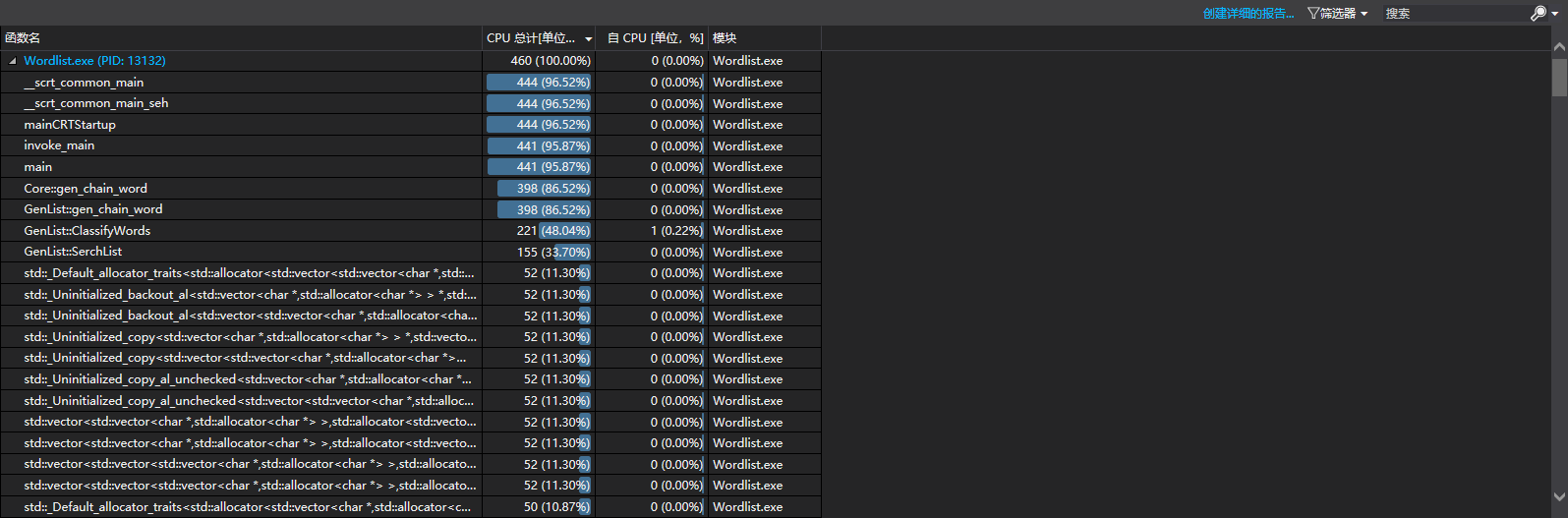
消耗最大的函数:
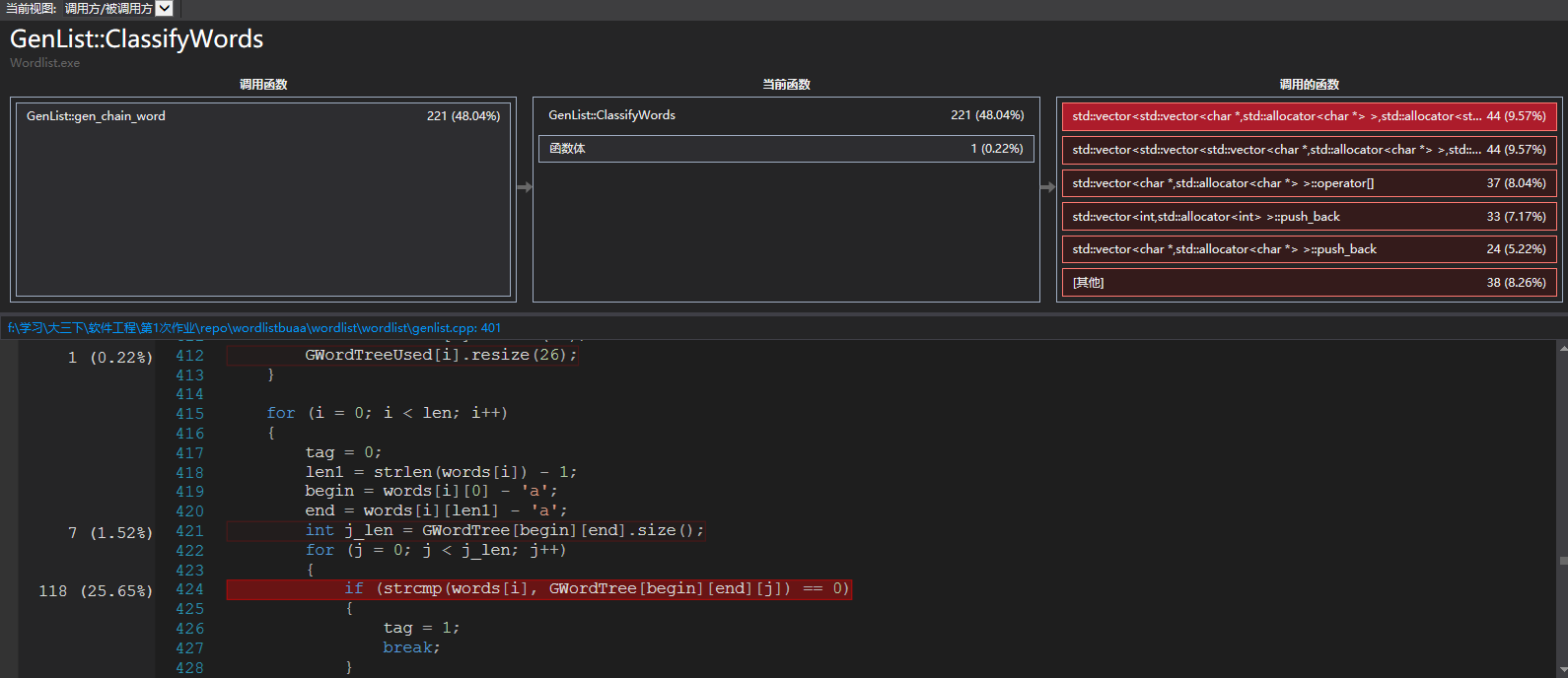
因为算法在寻找路这一方面做的比较优秀,所以慢在单词的分类,分类中有单词的查重功能,在找到当前的单词就查找一下有没有和他重复的,这个时候,strcmp就会慢很多。
在成环的时候,性能分析和不成环就不一样。
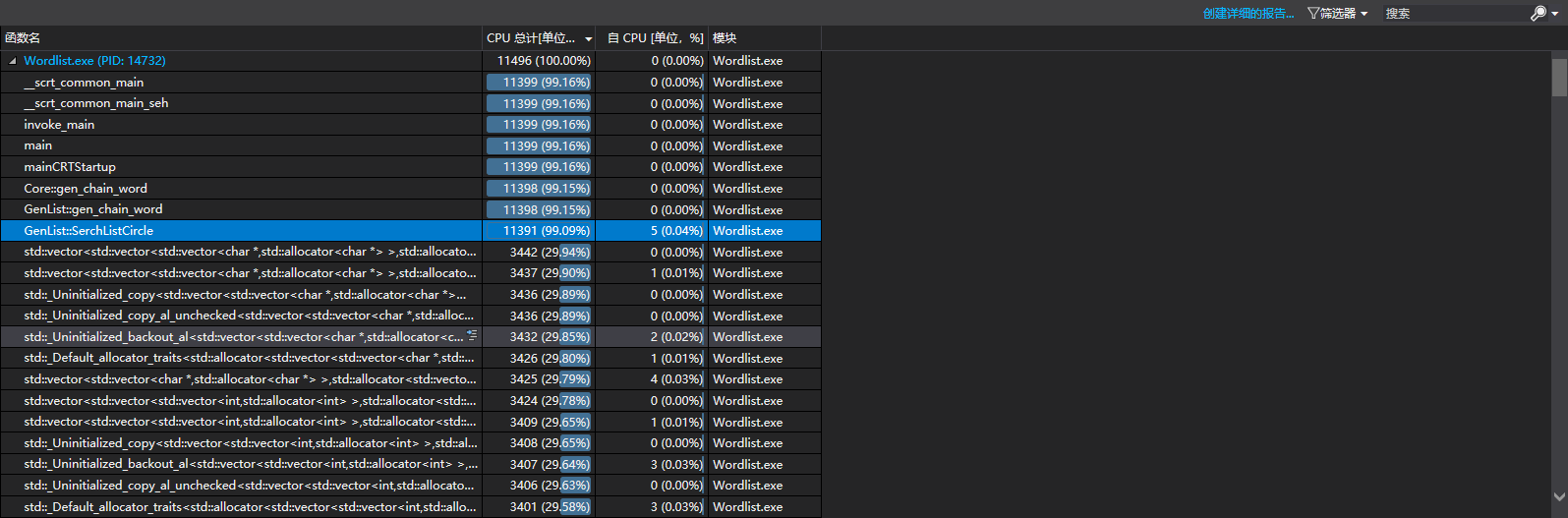
消耗最大的函数:
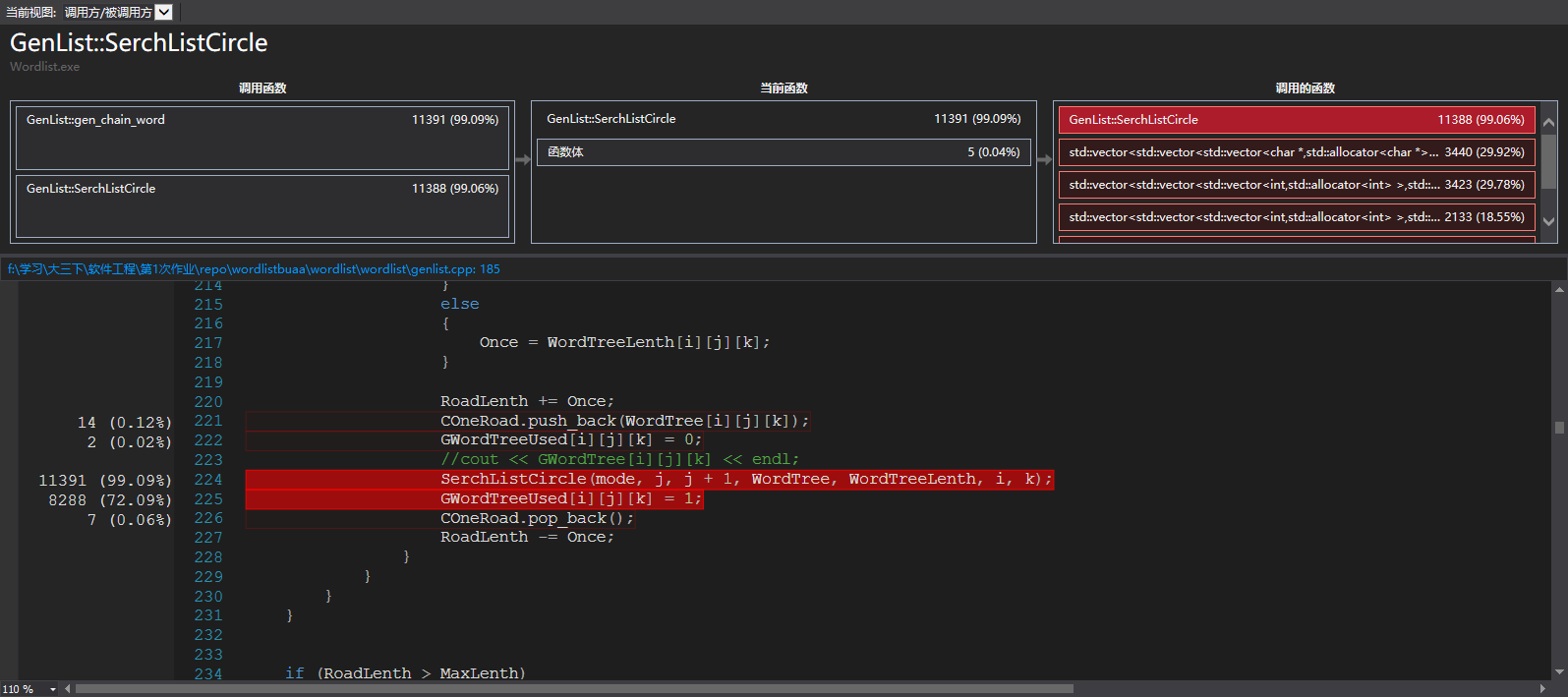
这个时候,算法主要在递归中,所以所有的消耗基本在进入递归的函数中,函数出来也消耗了大量写入的操作。
7.看Design by Contract, Code Contract的内容:
http://en.wikipedia.org/wiki/Design_by_contract
http://msdn.microsoft.com/en-us/devlabs/dd491992.aspx
描述这些做法的优缺点, 说明你是如何把它们融入结对作业中的
参考这篇博客:
契约式编程(Design by Contract)指的是调用者和被调用者地位平等,制定代码契约(Code Contract),双方必须彼此履行义务,才可以行驶权利。简单来说,就是调用者必须提供正确的参数(调用者的义务、被调用者的权利),被调用者必须保证正确的结果(调用者的权利、被调用者的义务)。
在契约式编程提出之前,软件工程的主要理论是C/S模式。对于C/S模式,我们看待两个模块的地位是不平等的,我们往往要求server非常强大,可以处理一切可能的异常,而对client不闻不问,造成了client代码的低劣。这里的client可以理解为调用者,server理解为被调用者。
由此我们可以得出契约式编程的优点:调用双方都有必须履行的义务,也有使用的权利,这样就保证了双方代码的质量,提高了软件工程的效率和质量。
契约式编程的缺点在于,契约式编程需要一种机制来验证契约的成立与否。而断言显然是最好的选择,但是并不是所有的程序语言都有断言机制。那么强行使用语言进行模仿就势必造成代码的冗余和不可读性的提高。
为了实现上述契约式编程,我们的做法是,在一些函数的功能性的代码前加入了断言assert,来验证调用者是否遵循了一些最基本的契约,比如 在处理文件内容的函数Readin(filename)中,
在本项目中,我们在代码中设置了一些断言机制,表明某个函数对于传入的参数的一些最基本的要求,比如 处理文件内容的函数void GetWords(char * filename)内部会首先断言传入的filename非NULL。
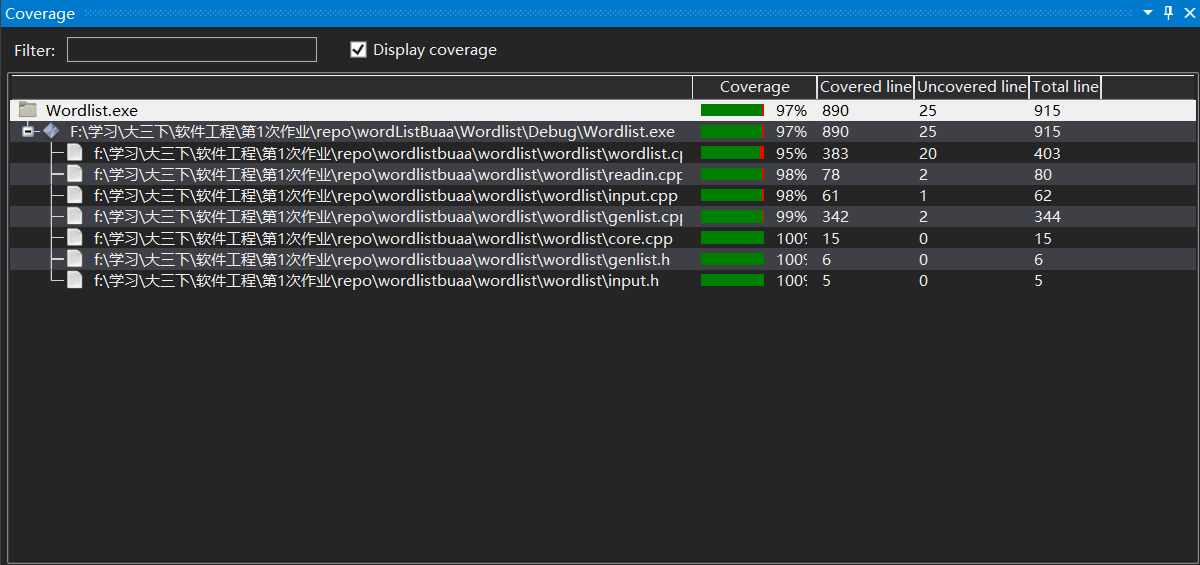
8.计算模块部分单元测试展示。 展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。要求总体覆盖率到90%以上,否则单元测试部分视作无效。
计算模块部分的单元测试代码 部分展示如下:
TEST_METHOD(TestMethod1)
{
// TODO: 在此输入测试代码
Input *input = new Input();
int n = 3;
char * instr[] = { " ", "-w","..\\Wordlist\\a.txt" };
char ** result = new char *[11000];
int len = 0;
input->InputHandle(n, instr);
Readin *readin = new Readin();
readin->GetWords(input->FileName);
int i = 0;
for (i = 0; i < 8; i++)
{
Core *core = new Core();
switch (i)
{
case(0):
len = core->gen_chain_word(readin->Words, readin->WordNum, result, '0', '0', false);
Assert::AreEqual(len, 29);
break;
case(1):
len = core->gen_chain_word(readin->Words, readin->WordNum, result, 'd', '0', false);
Assert::AreEqual(len, 27);
break;
case(2):
len = core->gen_chain_word(readin->Words, readin->WordNum, result, '0', 'e', false);
Assert::AreEqual(len, 27);
break;
case(3):
len = core->gen_chain_word(readin->Words, readin->WordNum, result, 'd', 'e', false);
Assert::AreEqual(len, 25);
break;
case(4):
len = core->gen_chain_char(readin->Words, readin->WordNum, result, '0', '0', false);
Assert::AreEqual(len, 29);
break;
case(5):
len = core->gen_chain_char(readin->Words, readin->WordNum, result, 'd', '0', false);
Assert::AreEqual(len, 27);
break;
case(6):
len = core->gen_chain_char(readin->Words, readin->WordNum, result, '0', 'e', false);
Assert::AreEqual(len, 27);
break;
case(7):
len = core->gen_chain_char(readin->Words, readin->WordNum, result, 'd', 'e', false);
Assert::AreEqual(len, 25);
break;
}
delete core;
}
}
计算模块的单元测试的函数是TestCore,被测试的函数是gen_chain_char和get_chain_word。构造测试数据主要是两个思路:
- 通过代码随机地生成一些测试输入,然后与另外一组同学一起跑这个样例,对比输出是否相同。
- 手动构造一些测试数据并计算结果,构造-w和-r测试样例时,首先构造一个有向无环图,然后手动求解其拓扑排序,可以参见这里。
单元测试得到的测试覆盖率截图如下,可见覆盖率达到了90%以上:
9.计算模块部分异常处理说明。 在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
-
计算模块部分的异常处理有两种:
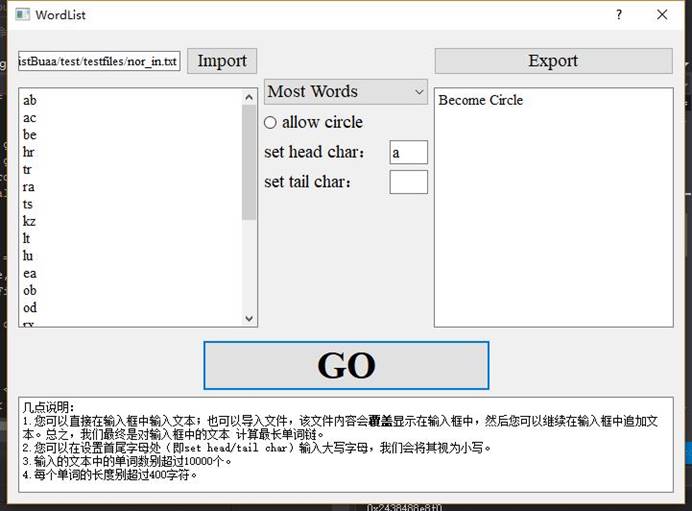
(1)按照文本内容和命令要求,不存在可行解。这包括:
- 无论命令为何,文本内容都无法成链。这样一个单元测试的输入可以是:ab cd lmn opq uvw xyz ef rst g hi jk。
- 文本内容本可以成链,但由于首尾字母的限制而没有可行解。这样一个单元测试的输入可以是:ab bc cd de,命令参数可以是WordList.exe -w -h d test.txt。
(2)命令中没有-r,但是文本内容可以成环。一个单元测试样例的输入是:abc cfs ehshoda sefe sewqq
这里列出整个项目的所有异常种类的设计:
| 抛出异常的模块 | 抛出异常的场景 | 错误提示语 |
|---|---|---|
| Input(命令行参数处理模块) | -h 后紧跟着的参数不是单字符 | Too Long Begin! |
| -t 后紧跟着的参数不是单字符 | Too Long End! | |
| -t 或-h后紧跟着的参数是单字符,但不是小写字母 | Need a alapa | |
| 文件名后还有参数 | Too many parameters | |
| 没有-w或-c | need one -c or -w | |
| 不是-w -c -r -h -t,也不是以.txt结尾的文件名 | illegal parameter | |
| 命令行参数中没有文件名 | No a legal file | |
| Readin(文件内容处理模块) | 无法打开命令行中指定的文件(比如文件不存在) | Fail to open the file |
| 文本中单词个数过多 | Too many words | |
| 单词的长度过长 | Too long word! | |
| Core(计算核心模块) | 按照文本内容和用户命令的要求,没有找到解 | No solution |
| 命令中没有-r,但是文件中出现了单词环 | Become Circle | |
| Main(主函数) | 其它异常情况 | Error |
10.界面模块的详细设计过程。 在博客中详细介绍界面模块是如何设计的,并写一些必要的代码说明解释实现过程。
界面模块使用VS+Qt,这里分享两个安装教程:教程1,教程2。
整个界面是一个QDialog(由于是一个小软件所以没有选择QMainWindow)界面模块主要包括“视图view”和“控制controller”两部分:
(一)通过所见既所得的Qt Designer设计UI视图,对布局做了一些考虑,放一张布局设计图:
//插入图片
整体采用纵向布局,其中最上面的部分采用水平布局,各个部分的功能如下:
- 最左边是输入,可以通过文件导入或手动输入,导入文件的内容会覆盖输入框并允许用户手动追加文本。
- 中间部分的4个用来设定参数:下拉选择框提供-w和-c两种选择,单选按钮提供是否选择-r,下面非必填的两个输入框用来设定首尾字母(仅能输入一个字符,可以选择不输入)。
- 最右边是输出,将计算结果显示在输出框中,可以导出为文件。
(二)通过信号与槽机制设置“哪个组件的什么事件会触发哪个类的什么方法”。按照上述每个组件的功能设置槽函数,并在go按钮点击事件对应的槽函数中调用文本处理模块readin和计算模块core,完成视图、控制器、模型的对接。
比较难写的槽函数在于文件的导入和导出,我们参考了这篇博客使用了QFileDialog,下面给出我们这部分的代码。
void Dialog::on_btn_import_clicked()
{
QString filepath = QFileDialog::getOpenFileName(this,tr("choose file"));
if(filepath!=NULL){
QByteArray ba = filepath.toLatin1();
char *filepath_c;
filepath_c = ba.data();
ui->le_path->setText(filepath);
FILE *fp;
fopen_s(&fp,filepath_c,"r");
fseek(fp,0,SEEK_END);
int filesize = ftell(fp);
fseek(fp,0,SEEK_SET);
char *buf = new char[filesize+1];
int n = fread(buf,1,filesize,fp);
if(n>0){
buf[n] = 0;
ui->te_in->setText(buf);
}
delete[] buf;
fclose(fp);
}
}
void Dialog::on_btn_export_clicked()
{
QString filename = QFileDialog::getSaveFileName(this,tr("save as"));
QByteArray ba = filename.toLatin1();
char *filepath_c;
filepath_c = ba.data();
QString text = ui->tb_out->toPlainText();
QByteArray ba2 = text.toLatin1();
char *text_c;
text_c = ba2.data();
if(filename.length()>0){
FILE *fp;
fopen_s(&fp, filepath_c, "w");
fwrite(text_c,1,text.length(),fp);
}
}
11.界面模块与计算模块的对接。 详细地描述UI模块的设计与两个模块的对接,并在博客中截图实现的功能
前面提到,我们在GO按钮点击事件对应的槽函数中 调用文本处理模块Readin和计算模块Core,从而完成视图、控制器、模型的对接。
具体来说,我们把槽函数都放到了Dialog类中,当用户点击GO按钮后,会触发Dialog类中的on_btn_go_clicked()槽函数,这个函数将视图中文本输入框的内容传递给核心控制器Calculator类,设置其成员变量textIn,然后调用Calculator类的核心函数core()进行计算,计算结果再通过setText()函数设置到视图上的文本输出框中。
上面这个过程是视图与控制器的对接,而控制器和计算模型的对接主要体现在Calculator类的核心函数core()中:将textIn内容传递给Readin实例化对象并调用其getWords方法,从而将文本内容处理为单词数组。随后,根据用户的参数设置,分-w和-c两类,分别调用Core.dll的gen_chain_word和gen_chain_char函数(通过dll),从而 或得出计算结果(长度和单词链)、或接收抛出的异常(无解或无-r却成环)。最后,将计算结果或异常提示信息设置到控制器Calculator类的textOut变量中,再由控制器传递到视图层在输出文本框中
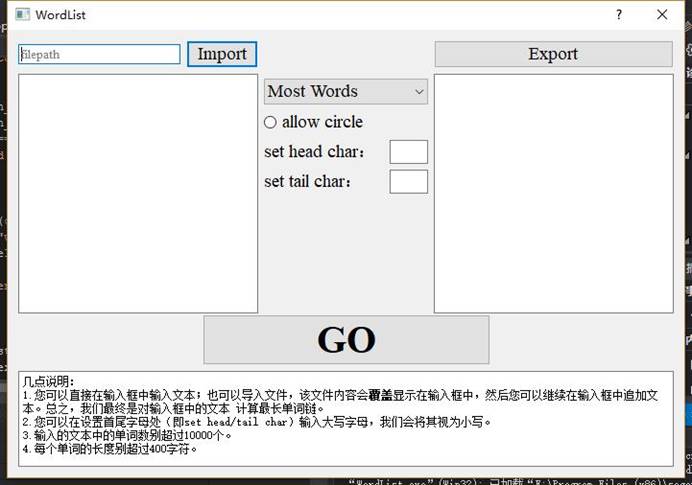
实现的功能截图如下:
(1)初始界面:
(2)一个正确的样例:

(3)一个测试异常的样例:
12.描述结对的过程,提供非摆拍的两人在讨论的结对照片。
整个项目的实现过程中,由于时间上不好安排、不大熟悉、性格比较内向等原因,我们大多数时候还是并行工作,保持线上交流讨论、互报进度,每隔1-3天线下开个小会,进行需求分析、工作分配、问题讨论、模块对接等工作。具体如下:
| 时间/事件 | 16061155王冰 | 16061093谢静芬 |
| 第一次开会前 | 粗读项目核心要求,开始编写第一版代码 | 研读和分析项目要求,记录问题,考虑如何分工 |
| 第一次开会 | 讨论需求中不明确的地方;然后一致认为,由于时间紧任务重、二人时空上不大方便进行结对编程(无法像其他组那样串宿舍结对编程...)等原因,决定二人还是并行工作;建仓库,进行分工 | |
| 第一次开会后 | 编写完成第一版核心代码,包括命令行参数处理、文本单词提取、最长链计算 | 设计异常种类、构造测试用例、安装和学习qt、代码复审 |
| 第二次开会前 | 进行测试,修复一些bug,测试性能,尝试优化性能 | 设计和编写GUI,代码复审,开始书写博客的共同部分 |
| 第二次开会 | 将GUI和计算核心进行对接(暂未转成dll),修复了一些bug。各自查阅并尝试进行dll的生成和调用(失败了) | |
| 第二次开会后 | 继续尝试进行dll的生成和调用、书写博客的共同部分中关于计算核心和优化等内容 | 书写完成博客的共同部分中的其它部分、找到一些不错的链接便于队友学习博客中提到的一些概念 |
| 第三次开会 | 将GUI和计算核心dll进行对接,成功!与另一组同学的模块进行交换对接,成功! | |
| 第三次开会后 | 各自完成博客中的非共同部分 | |
| 总结 | 真是太优秀了! | 打杂也很认真! |

13.看教科书和其它参考书,网站中关于结对编程的章节,例如:
http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html
说明结对编程的优点和缺点。
结对的每一个人的优点和缺点在哪里 (要列出至少三个优点和一个缺点)。
结对编程的优点:
- 每人在各自独立设计、实现软件的过程中不免要犯这样那样的错误。在结对编程中,因为有随时的复审和交流,程序各方面的质量取决于一对程序员中各方面水平较高的那一位。程序中的错误就会少得多,程序的初始质量会高很多。
- 程序的初始质量高了,就会省下很多以后修改、测试的时间。
- 在企业管理层次上,结对能更有效地交流,相互学习和传递经验,能更好地处理人员流动。因为一个人的知识已经被其他人共享。
- 轮流工作:让程序员轮流工作,从而避免出现过度思考而导致观察力和判断力下降。
缺点:
- 结对的双方如果脾气对味,技术观点相近,结对会很愉快,而且碰撞出很多火花,效率有明显提高。反之,就可能陷入很多的争吵,而导致进度停滞不前。甚至影响团队协作。
- 结对编程所花费的时间较多,虽然后期修改和测试的时间可能会减少。
- 需要有一个领航员,且该领航员恰当地发挥作用,只有两个副驾驶员是不能开飞机的。
- 有些人的性格上喜欢单兵作战,不喜欢、不习惯,适应结对编程需要一定的时间
自己优点:
1.写代码刻苦
2.准备的比较多
3.尝试的比较多
自己缺点:
有时候写代码思考的比较少,有很多没考虑到的bug
队友优点:
1.阅读需求详细
2.思考覆盖完全
3.代码bug少
对优缺点:
找不到缺点
14.在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 840 | 760 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 120 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 50 | 40 |
| · Coding | · 具体编码 | 500 | 480 |
| · Code Review | · 代码复审 | 40 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 150 | 60 |
| Reporting | 报告 | 60 | 105 |
| · Test Report | · 测试报告 | 30 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 60 |
| 合计 | 920 | 1905 |
15.与其他队进行松耦合。
我们队把我们队的Core.dll与其他队的Core.dll进行了交换,并使用我们的GUI与他们的dll进行耦合,结果比较符合要求,成功运行。
最终,我们与16061173鲍屹伟和16061135张沛泽一组、16061167白世豪和16061170宋卓洋一组以及16061144余宸狄和16061137张朝阳一组交换了程序,进行了松耦合。
在我们的GUI上调用其他组的dll:
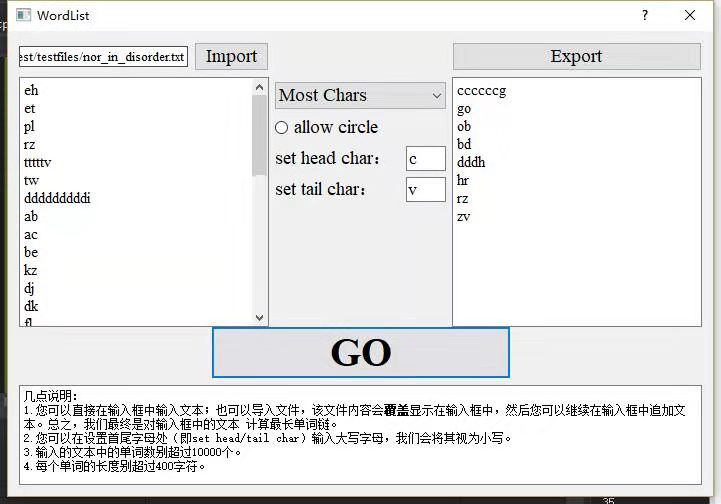
16061173鲍屹伟和16061135张沛泽调用我们的dll:
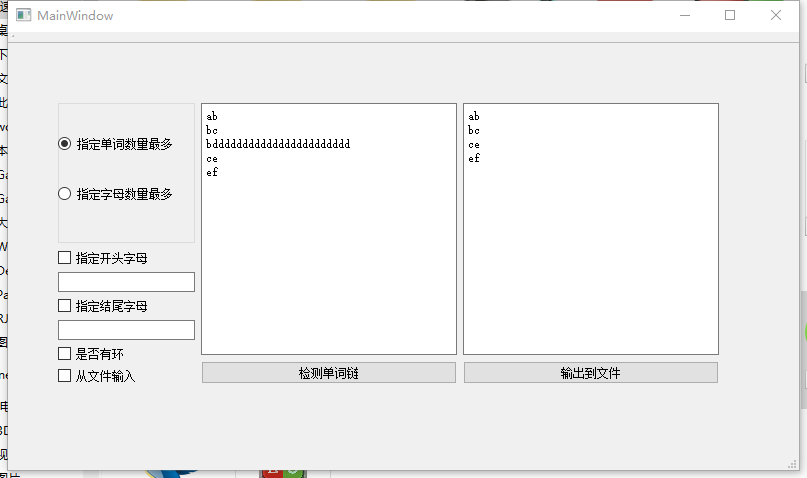
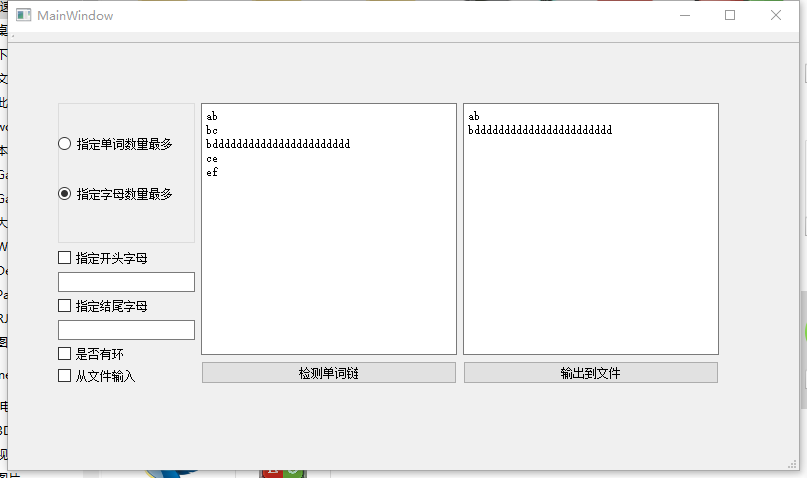
16061167白世豪和16061170宋卓洋调用我们的dll:
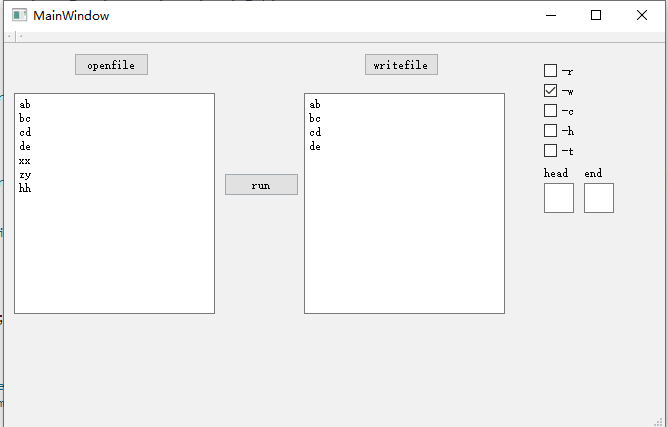
16061144余宸狄和16061137张朝阳调用我们的dll:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号