学习笔记-Python开发-024_Python的模块
1 自定义模块
在开发简单的程序时,使用一个py文件就可以搞定,如果程序比较庞大,需要些10w行代码,此时为了,代码结构清晰,将功能按照某种规则拆分到不同的py文件中,使用时再去导入即可。另外,当其他项目也需要此项目的某些模块时,也可以直接把模块拿过去使用,增加重用性
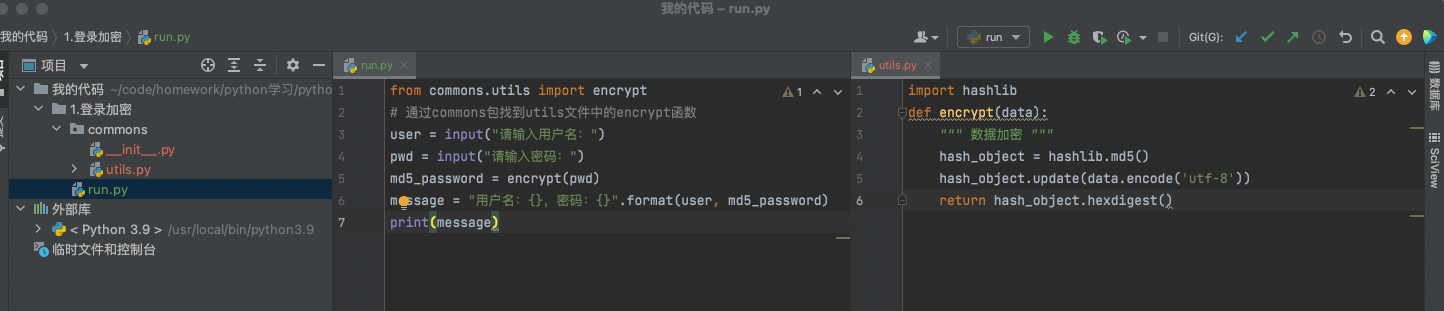
import hashlib
def encrypt(data):
""" 数据加密 """
hash_object = hashlib.md5()
hash_object.update(data.encode('utf-8'))
return hash_object.hexdigest()
user = input("请输入用户名:")
pwd = input("请输入密码:")
md5_password = encrypt(pwd)
message = "用户名:{},密码:{}".format(user, md5_password)
print(message)
我们可以按照某个规则进行拆分py文件,如果拆分到太多,还可以创建一个文件夹再次进行拆分
在Python中一般对文件和文件的称呼(很多开发者的平时开发中也有人都称为模块)
- 一个py文件,模块(module)
- 含多个py文件的文件夹,包(package)
tips:
对于模块的注释则是直接写在文件最上方即可
包的注释则是写在__init__.py文件中
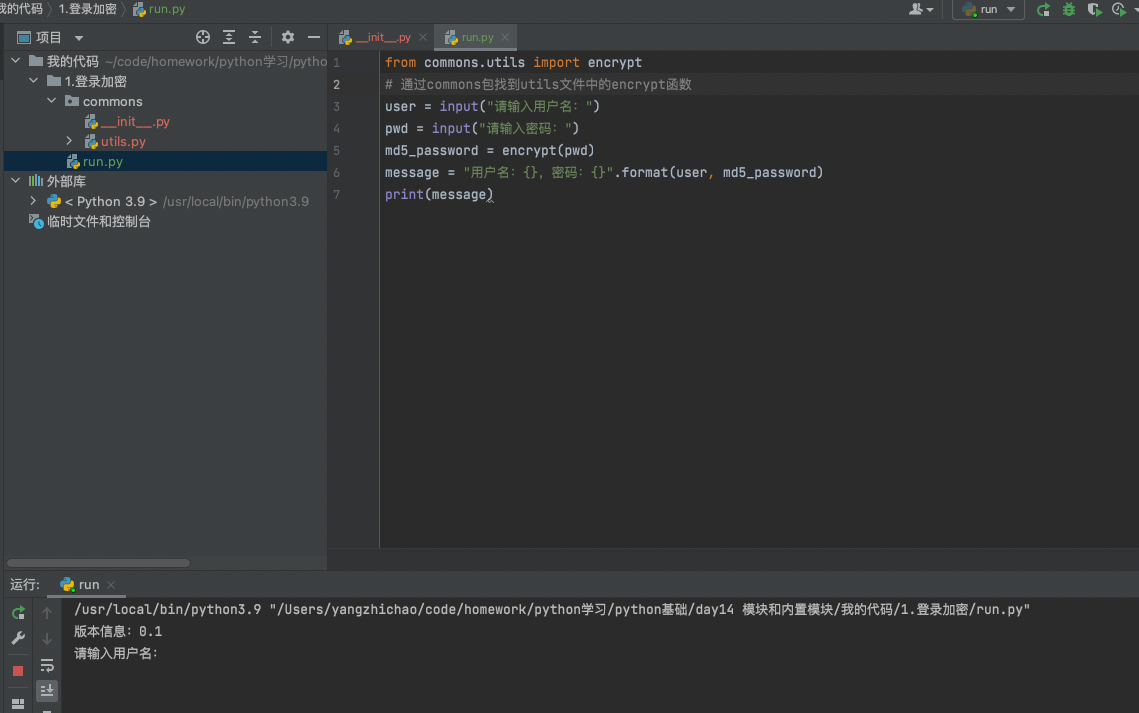
1.1 __init__.py
注意:在包(文件夹)中有一个默认内容为空的__init__.py的文件,一般用于描述当前包的信息(在导入他下面的模块时,也会自动加载)
-
py2必须有,如果没有导入包就会失败。
-
py3可有可无。
这个文件可以是空的,但是通常情况下,会在这个文件中写入包的注视以及版本信息
'''
这个包是干嘛的?
'''
version = 0.1
print('版本信息:{}'.format(version))
并且在加载这个包的时候,里面的代码会自动执行一次
1.2 模块导入路径
当定义好一个模块或包之后,如果想要使用其中定义的功能,必须要先导入,然后再能使用
导入,其实就是将模块或包加载的内存中,以后再去内存中去拿就行
1.2.1 python模块的查找
对于python而言,他并不支持from D:/xx.py import xx这样直接直接以路径形式的方式导入模块,它将模块分为了四个通用类别
1、使用纯Python代码编写的py文件
2、包含一系列模块的包
3、使用C编写并链接到Python解释器中的内置模块
4、使用C或C++编译的扩展模块
在导入一个模块时,如果该模块已加载到内存中,则直接引用,内存没有就回去硬盘找,会优先查找内置模块,然后按照列表的顺序依次检索sys.path中定义的路径,直到找模块对应的文件为止,否则抛出异常。sys.path也被称为模块的搜索路径,它是一个列表类型
如果在不同的sys.path路径中有同名的模块,就需要看查找顺序优先级
import sys
print(sys.path)
‘’‘
其中第一条当前执行脚本的目录
第二条是pycharm中默认会将项目目录加入到sys.path中
其次是系统环境定义的目录,它包含了很多安装的第三方模块和系统内置模块
输出结果
[
'/Users/user/code/homework/python学习/python基础/day14 模块和内置模块/我的代码/2.导入的路径',
'/Users/user/code/homework/python学习/python基础/day14 模块和内置模块/我的代码',
'/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_display',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python39.zip',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/lib-dynload',
'/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages',
'/Applications/PyCharm.app/Contents/plugins/python/helpers/pycharm_matplotlib_backend'
]
'''
如果已经被加载到内存中了,就不会再去硬盘中查找
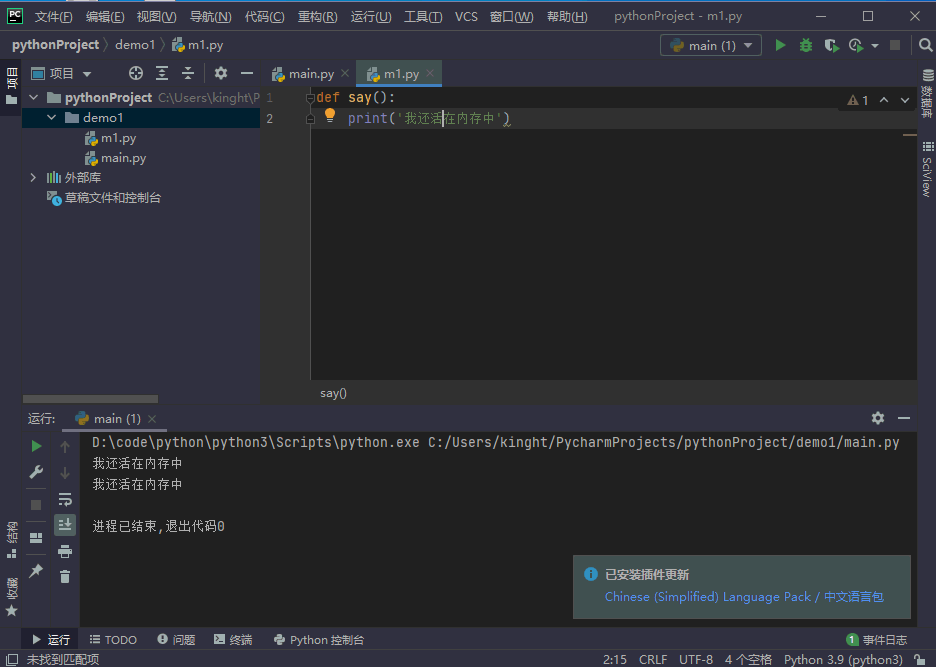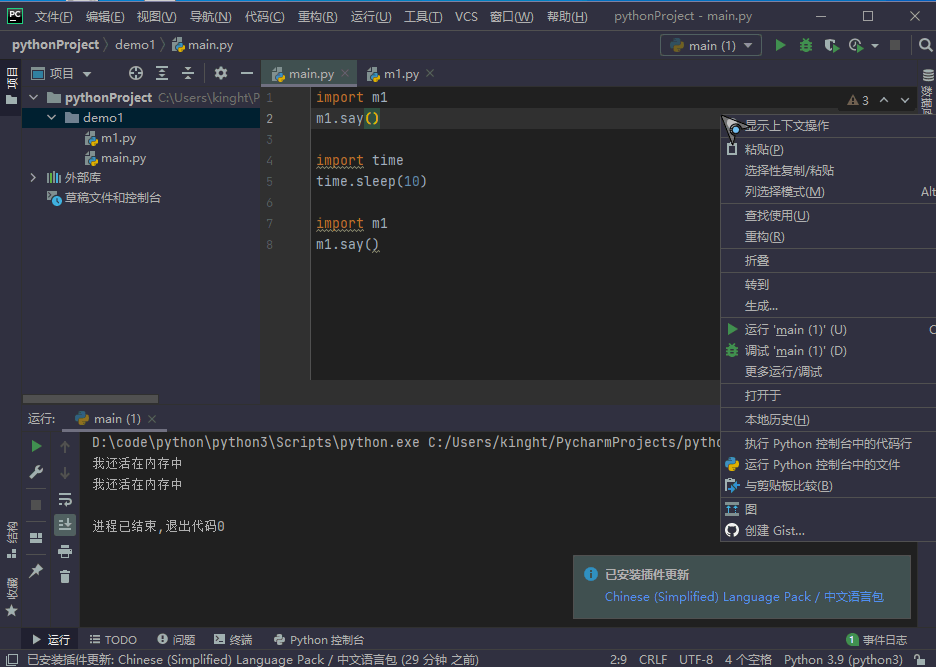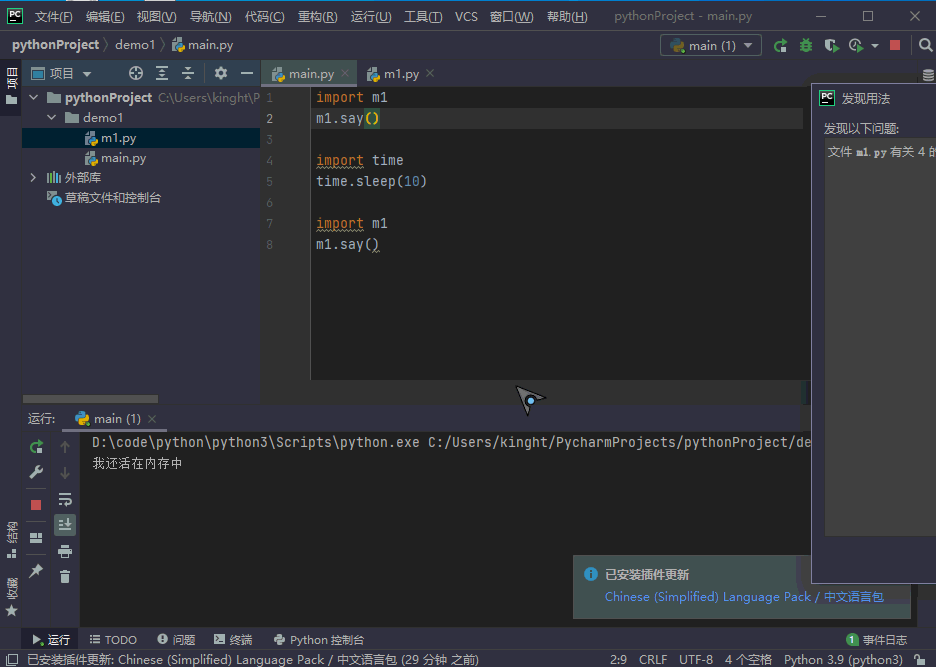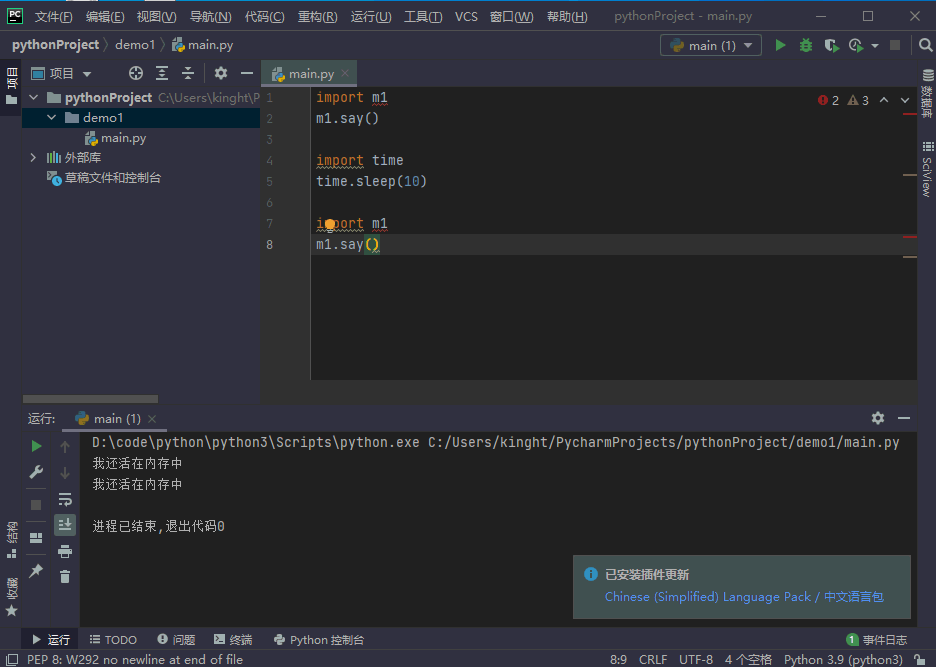
我们进行一个验证,调用了m1,经过第一次调用后,程序暂停,然后把m1给删除,发现第二次还是能够正常调用m1
1.2.2 自定义sys.path
import sys
sys.path.append(r"路径A")
import xxxxx # 导入路径A下的一个xxxxx.py文件
sys.path是一个列表,我们可以通过append将对应模块地址加入到列表中,就可以访问到模块了
1.2.3 导入模块需要注意
-
你以后写模块名称时,千万不能和内置和第三方的同名(新手容易犯错误)。
-
项目执行文件一般都在项目根目录,如果执行文件嵌套的内存目录,就需要自己手动在sys.path中添加路径。
‘’‘ ├── commons │ ├── __init__.py │ └── utils.py └── bin ├── __init__.py └── run.py run.py需要查找到commons模块utils包,所以需要添加上级目录到sys.path ’‘’ import os ,sys sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) -
pycharm中默认会将项目目录加入到sys.path中
-
导入模块时有规范的顺序
# 先内置模块 # 再第三方模块 # 最后自定义模块
1.3 模块导入的方式
导入本质上是将某个文件中的内容先加载到内存中,然后再去内存中拿过来使用。而在Python开发中常用的导入的方式有2类方式,每类方式都也多种情况
import xxxx # 适用于项目根目录下包模块级别的导入
from xxx.xxx import xxx # 适用于导入成员、嵌套的包模块
1.3.1 使用import xxxx导入
开发中,一般多用于导入sys.path目录下的一个py文件
1.3.1.1 模块级别 -> 找到模块中的函数
目录结构:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ ├── tencent
│ │ ├── __init__.py
│ │ ├── sms.py
│ │ └── wechat.py
│ └── utils.py
├── many.py
└── run.py
导入方式 run.py文件:
# 导入到 模块级别
import many
import commons.page
import commons.tencent.sms as CT # 取别名
# 调用方式 包名.模块名.函数名()
v1 = many.show()
v2 = commons.page.pagination()
v3 = CT.send_sms()
1.3.1.2 包级别 -> 找到包下属模块中的所有函数
默认加载包里面__init__文件
目录结构:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ └── utils.py
├── third
│ ├── __init__.py
│ ├── ali
│ │ └── oss.py
│ └── tencent
│ ├── __init__.py
│ ├── __pycache__
│ ├── sms.py
│ └── wechat.py
└── run.py
导入方式 run.py文件:
import commons
import third.tencent as tt # 取别名
# 直接在包里调用模块的函数
# 调用方式 包名.函数名()
v1 = commons.xx()
v2 = third.tencent.uuuuu()
v3 = tt.uuuuu()
1.3.2 使用from...import...导入
最常用的导入模式,一般适用于多层嵌套和导入模块中某个成员的情况
1.3.2.1 成员级别
目录结构:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ └── utils.py
├── many.py
└── run.py
导入方式 run.py文件:
from commons.page import pagination
from commons.utils import encrypt,NAME
from many import show
# 调用方式 可直接使用函数名
v1 = pagination()
v2 = encrypt()
v3 = NAME()
v4 = show()
提示:基于from模式也可以支持 from many import *,即:导入一个模块中所有的成员(可能会重名,所以用的少)
1.3.2.2 模块级别
目录结构:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ └── utils.py
├── many.py
└── run.py
导入方式 run.py文件:
from commons import page
from commons import utils
import many() # 由于many()在根目录下,所以不适用于from
# 调用方式 模块名.函数名()
v1 = utils.encrypt()
v2 = tils.NAME()
v3 = page.pagination()
v4 = many.show()
1.3.2.3 包级别
目录结构:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ ├── tencent
│ │ ├── __init__.py
│ │ ├── sms.py
│ │ └── wechat.py
│ └── utils.py
├── many.py
└── run.py
导入方式 run.py文件:
from commons import tencent # 要求包不能再根目录
# 调用方式 包名.函数名()
v1 = tencent.uuuuu()
1.3.3 导入到级别并不节约内存
无论是导入到成员、模块,都会将所有模块的函数加载到内存,所以并不节约内存,意义在于不会让函数名之间冲突
1.4 相对导入(开发规范不建议)
在开发程序的过程中,肯定不止有主文件需要倒入模块,在包当中的功能文件实现某些功能也需要倒入模块,而由于主文件是运行文件,所以哪怕是sms.py和wechat.py在同一路径下,也需要from commons.tencent import wechat,而这一块空间在运行之初已经加入了sys.path中,所以他其实可以使用from . import wechat相对路径导入
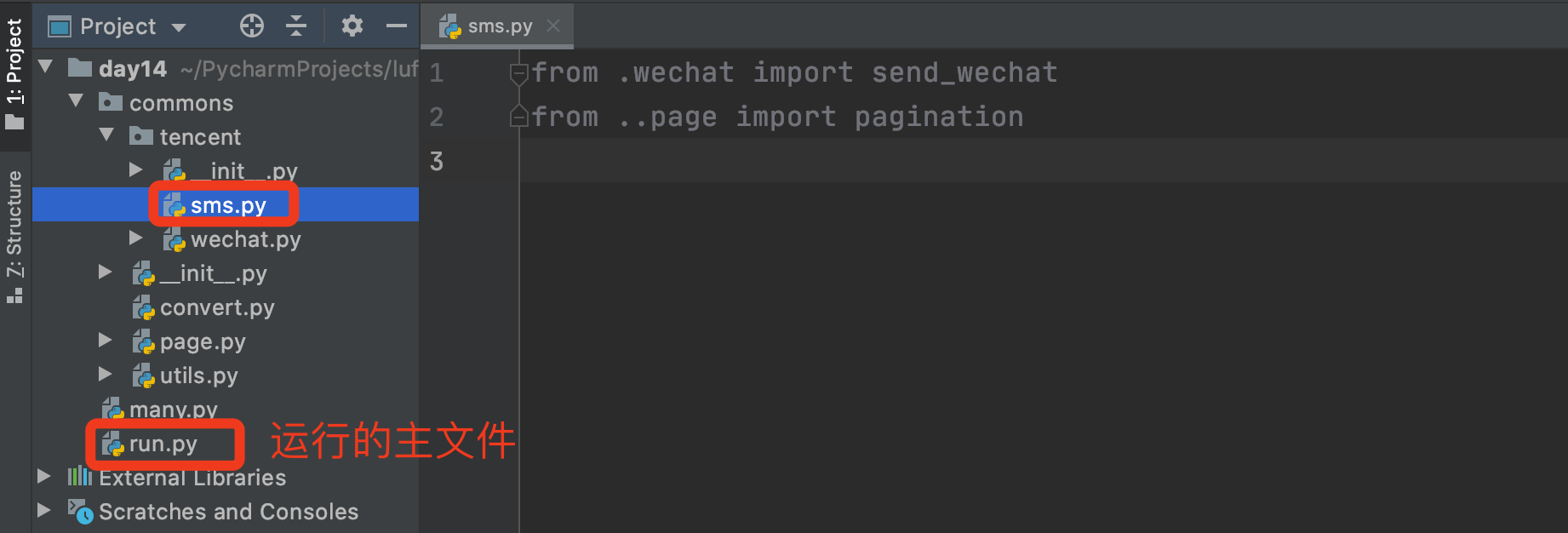
切记,相对导入只能用在包中的py文件中(即:嵌套在文件中的py文件才可以使用,项目根目录下无法使用)
1.5 导入别名
如果项目中导入 成员/模块/包 有重名,那么后导入的会覆盖之前导入,为了避免这种情况的发生,Python支持重命名,即:
from xxx.xxx import xx as xo
import x1.x2 as pg
除此之外,有了as的存在,让import xx.xxx.xxxx.xxx在调用执行时,会更加简单(不常用,了解即可)。
-
原来
import commons.page v1 = commons.page.pagination() -
现在
import commons.page as pg v1 = pg.pagination()
1.6 主文件
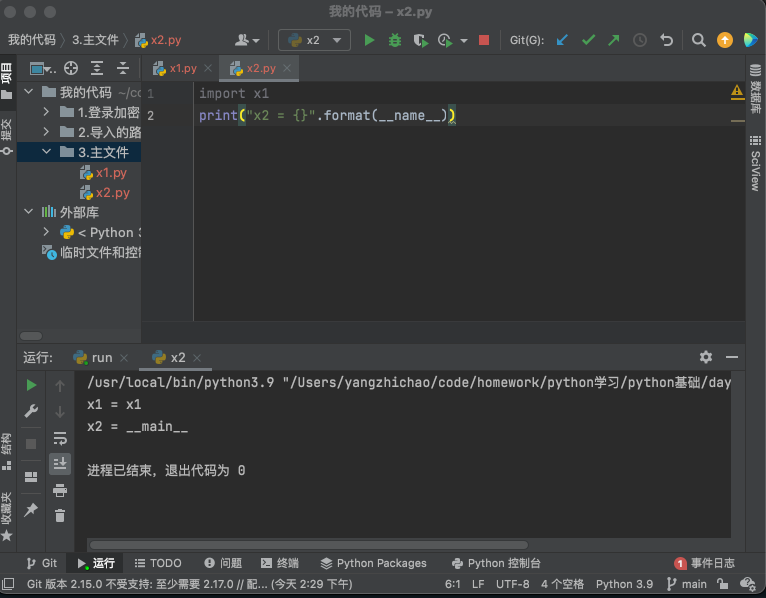
1.6.1 __name__
当一个文件被解释器去运行的时候
__name__ = "__main__"
当一个文件是被其他文件导入的时候
__name__ = "模块名"
1.6.2 入口文件
主文件,其实就是在程序执行的入口文件,例如:
├── commons
│ ├── __init__.py
│ ├── convert.py
│ ├── page.py
│ ├── tencent
│ │ ├── __init__.py
│ │ ├── sms.py
│ │ └── wechat.py
│ └── utils.py
├── many.py
└── run.py
我们通常是执行 run.py 去运行程序,其他的py文件都是一些功能代码。当我们去执行一个文件时,文件内部的 __name__变量的值为 __main__,所以,主文件经常会看到:
import many
from commons import page
from commons import utils
def start():
v1 = many.show()
v2 = page.pagination()
v3 = utils.encrypt()
# 主文件标志
if __name__ == '__main__':
start()
只有是以主文件的形式运行此脚本时start函数才会执行,被导入时则不会被执行
这种模式也可以用于测试某个功能,只有直接执行那个文件,才会让文件__name__ = "__main__",才会让if __name__ == '__main__'中函数执行
2 第三方模块
Python内部提供的模块有限,所以在平时在开发的过程中,经常会使用第三方模块,第三方模块就是别人写好并开源出来的代码,使用第三方模块可以方便快速的构建一些功能,不必重复造轮子。
第三方模块必须要先安装才能可以使用,下面介绍常见的3中安装第三方模块的方式
2.1 pip(最常用)
pip是最常用最方便的第三方模块安装方式,pip其实是一个第三方模块包管理工具,默认安装Python解释器时自动会安装,默认目录:
MAC系统,即:Python安装路径的bin目录下
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3
/Library/Frameworks/Python.framework/Versions/3.9/bin/pip3.9
Windows系统,即:Python安装路径的scripts目录下
C:\Python39\Scripts\pip3.exe
C:\Python39\Scripts\pip3.9.exe
提示:为了方便在终端运行pip管理工具,我们也会把它所在的路径添加到系统环境变量中
2.1.1 下载pip
如果你的电脑上某个写情况没有找到pip,也可以自己手动安装:
-
下载
get-pip.py文件,到任意目录地址:https://bootstrap.pypa.io/get-pip.py -
打开终端进入目录,用Python解释器去运行已下载的
get-pip.py文件即刻安装成功。

2.1.2 pip使用
pip的使用方式非常简单,执行后会到https://pypi.org或者指定的pip源中下载安装包,然后执行安装程序
# pip3 install 模块名称
pip install requests
# 默认安装的是最新的版本,如果想要指定版本
# pip3 install 模块名称==版本
pip3 install django==2.2
2.1.3 pip更新
有时安装软件黄色字体提示:目前我电脑上的pip是20.2.3版本,最新的是 20.3.3 版本,如果想要升级为最新的版本,可以在终端执行他提示的命令:
/Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -m pip install --upgrade pip
注意:根据自己电脑的提示命令去执行,不要用我这里的提示命令哈。
2.1.4 pip换源
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学:https://pypi.mirrors.ustc.edu.cn/simple/
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学:http://pypi.mirrors.ustc.edu.cn/simple/
豆瓣:https://pypi.douban.com/simple/
pip默认是去 https://pypi.org 去下载第三方模块(本质上就是别人写好的py代码),国外的网站速度会比较慢,为了加速可以使用国内的豆瓣源。
-
一次性使用
pip3.9 install 模块名称 -i https://pypi.douban.com/simple/ -
永久使用
-
配置
# 在终端执行如下命令 pip3.9 config set global.index-url https://pypi.douban.com/simple/ # 执行完成后,提示在我的本地文件中写入了豆瓣源,以后再通过pip去安装第三方模块时,就会默认使用豆瓣源了。 # 自己以后也可以打开文件直接修改源地址。 Writing to /Users/wupeiqi/.config/pip/pip.conf -
使用
pip3.9 install 模块名称
-
2.2 源码安装
如果要安装的模块在pypi.org中不存在或因特殊原因无法通过pip install安装时,可以直接下载源码,然后基于源码安装,例如:
-
下载requests源码(压缩包zip、tar、tar.gz)并解压。
下载地址:https://pypi.org/project/requests/#files -
进入目录
-
执行编译和安装命令
# 在下载的源码解压完成后 一定会有一个setup.py 文件 python3 setup.py build # 编译 python3 setup.py install # 安装
2.3 wheel
wheel是Python的第三方模块包的文件格式的一种,我们也可以基于wheel去安装一些第三方模块。
-
安装wheel格式支持,这样pip再安装第三方模块时,就可以处理wheel格式的文件了。
pip3 install wheel -
下载第三方的包(wheel格式),例如:
https://pypi.org/project/requests/#files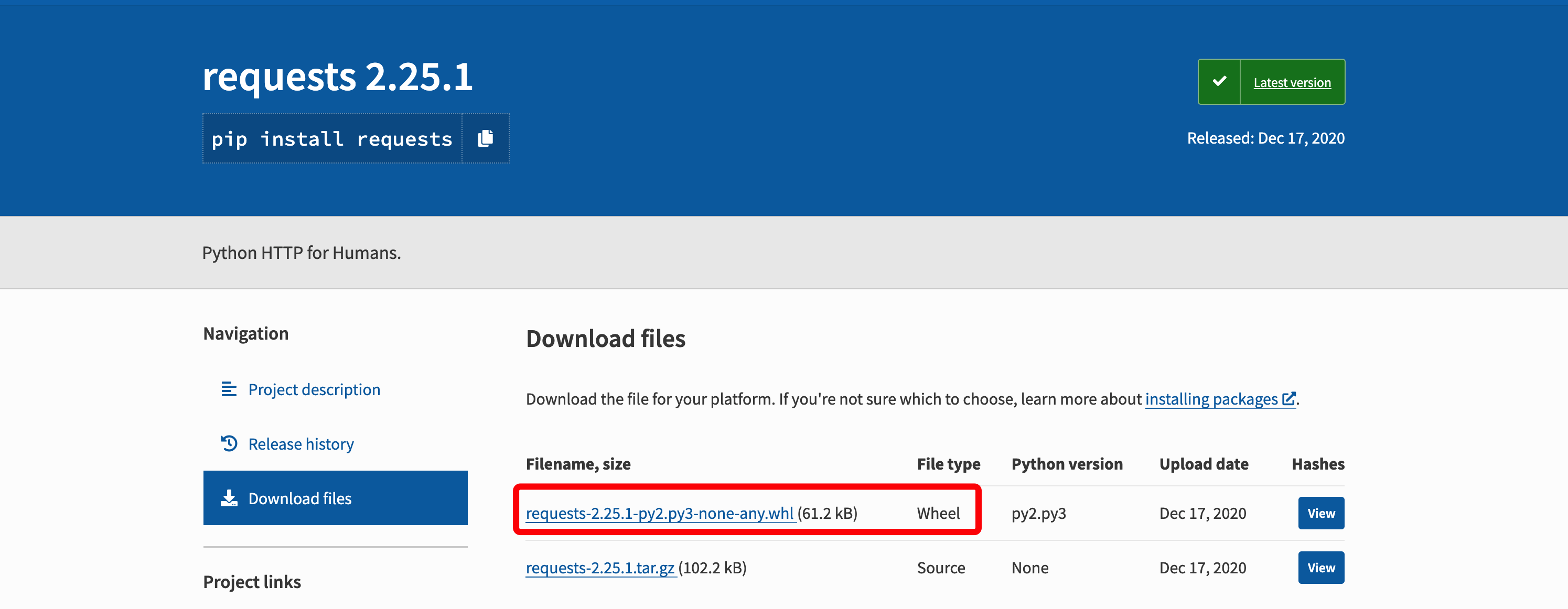
-
进入下载目录,在终端基于pip直接安装
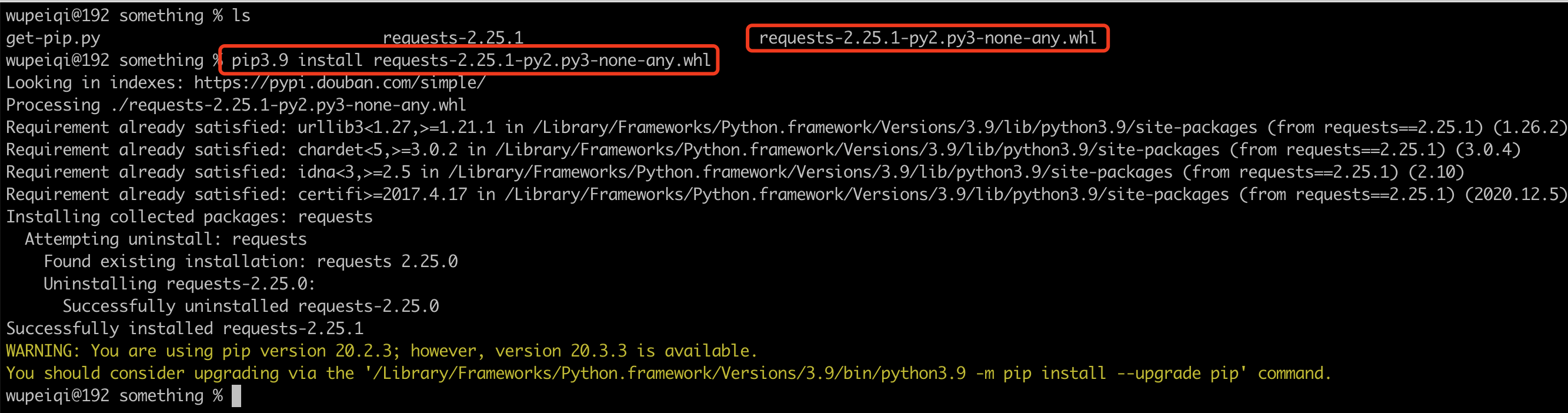
无论通过什么形式去安装第三方模块,默认模块的安装路径在:
Max系统:
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages
Windows系统:
C:\Python39\Lib\site-packages\
提醒:这个目录在sys.path中,所以我们直接在代码中直接导入下载的第三方包是没问题的。
3 内置模块
Python内置的模块有很多,内置模块有很多 & 模块中的功能也非常多,没有办法全局注解,在此会整理出项目开发最常用的来进行讲解。
3.1 os
import os
# 1.获取文件绝对路径
import shutil
abs_path = os.path.abspath(__file__)
print(abs_path)
# 2.获取文件的目录
file_path = os.path.dirname(abs_path)
print(file_path)
## 获取当前文件的上级目录(双重os.path.dirname)
base_path = os.path.dirname(os.path.dirname(abs_path))
print(base_path)
# 3.路径拼接
p1 = os.path.join(file_path,'file','1.txt')
print(p1)
# 4.判断路径是否存在
exists = os.path.exists(p1)
print(exists)
# 5.创建文件夹 os.makedirs(路径)
os.makedirs("{}/demo/test".format(file_path))
# 6.判断是否是文件夹
is_dir = os.path.isdir("{}/demo/test".format(file_path))
print(is_dir)
# 7.删除文件或文件夹
## 删除文件 os.remove(路径)
os.remove(p1)
## 删除文件夹 shutil.rmtree(路径)
shutil.rmtree("{}/demo/test".format(file_path))
# 8.查看目录下所有的文件
## 查看当前目录下的文件 os.listdir(路径)
data = os.listdir(os.path.join(file_path,'file'))
print(data)
## 查看目录下所有的文件(含子孙文件)os.walk(路径) 需要使用for循环输出
data = os.walk(os.path.join(file_path))
print(data) # <generator object _walk at 0x7fc4d8145740> 返回生成器
for item in data:
print(item) # 输出结果[被循环路径,被循环路径中的文件夹,被循环路径中的文件]
### 循环获得每个具体的文件名 只需要循环file_list即可
for path,folder_liet,file_list in data:
for item in file_list:
print(item,end=" ")
### 循环获得每个具体的文件的路径
for path,folder_liet,file_list in data:
for item in file_list:
# 此循环是循环每个目录下的文件名,所以path是相同的
file_path_list = os.path.join(path,item)
print(file_path_list)
#### 找出后缀名为txt的文件路径
ext = file_path_list.rsplit(".",1)[-1]
if ext == "txt":
print(file_path_list)
3.2 shutil
import shutil,os
base_path = os.path.dirname(os.path.abspath(__file__))
# 1. 删除文件夹
path = os.path.join(base_path, 'xx')
shutil.rmtree(path)
# 2. 拷贝文件夹
shutil.copytree("/Users/wupeiqi/Desktop/图/csdn/","/Users/wupeiqi/PycharmProjects/CodeRepository/files")
# 3.拷贝文件
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/")
shutil.copy("/Users/wupeiqi/Desktop/图/csdn/WX20201123-112406@2x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/x.png")
# 4.文件或文件夹重命名
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/x.png","/Users/wupeiqi/PycharmProjects/CodeRepository/xxxx.png")
shutil.move("/Users/wupeiqi/PycharmProjects/CodeRepository/files","/Users/wupeiqi/PycharmProjects/CodeRepository/images")
# 5. 压缩文件
"""
# base_name,压缩后的压缩包文件
# format,压缩的格式,例如:"zip", "tar", "gztar", "bztar", or "xztar".
# root_dir,要压缩的文件夹路径
"""
shutil.make_archive(base_name=r'datafile',format='zip',root_dir=r'files')
# 6. 解压文件
"""
# filename,要解压的压缩包文件
# extract_dir,解压的路径
# format,压缩文件格式
"""
shutil.unpack_archive(filename=r'datafile.zip', extract_dir=r'xxxxxx/xo', format='zip')
3.3 sys
import sys
# 1. 获取解释器版本
print(sys.version)
print(sys.version_info)
print(sys.version_info.major, sys.version_info.minor, sys.version_info.micro)
# 2. 导入模块路径
sys.path.append("xxx/xxxx")
print(sys.path)
# 3.获取外部输入
print(sys.argv) # ['4.内置函数/sys外部接受.py', '123', '456', '789']
'''
外部输入内容会被输出成列表 [py文件名,输入参数1,输入参数2,...]
'''
## 案例 -> 下载图片小公举
import sys
def download_image(url):
print("下载图片",url) # 简化一下
def run():
# 接受用户传入参数
url_list = sys.argv[1:]
# 哪怕只接受一个参数,也需要[1:],否则交给for循环的将会是字符串而不是列表,将会导致字符一个一个被输出
for url in url_list:
download_image(url)
if __name__ == '__main__':
run()
## 案例使用
python3.9 4.内置函数/sys外部接受.py https://www.kinghtxg.com/logo.png http://www.baidu.com
3.4 random
import random
# 1. 获取范围内的随机整数
v = random.randint(10, 20)
print(v)
# 2. 获取范围内的随机小数
v = random.uniform(1, 10)
print(v)
# 3. 随机抽取一个元素
v = random.choice([11, 22, 33, 44, 55])
print(v)
# 4. 随机抽取多个元素 random.sample([列表], 抽取几个)
v = random.sample([11, 22, 33, 44, 55], 3)
print(v)
# 5. 列表打乱顺序
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
random.shuffle(data)
print(data)
3.5 hashlib
hashlib适用于md5加密,所以我们直接通过一个加密案例进行了解它
import hashlib
def md5(origin):
hash_object = hashlib.md5()
hash_object.update(origin.encode('utf-8')) # 需要讲接受参数进行编码
result = hash_object.hexdigest()
print(result) # 21232f297a57a5a743894a0e4a801fc3
def run():
md5('admin')
if __name__ == "__main__":
run()
从技术角度来说,md5属于不可逆加密,但是无奈现在有碰撞行为(加密获取大量密码的md5,存储于数据库中,通过查询获得md5明文)
https://www.cmd5.com/
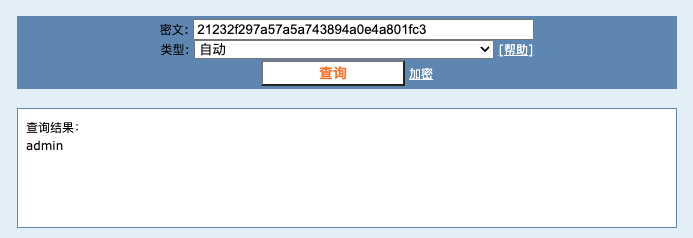
所以需要对其加盐,对代码进行改造,加盐后,碰撞就失效了
import hashlib
def md5(origin,salt="asdasd!@#Sd23edasr31."):
hash_object = hashlib.md5(salt.encode('utf-8')) # salt就是加盐,也是需要编码的
hash_object.update(origin.encode('utf-8'))
result = hash_object.hexdigest()
print(result) # 6051aa1bca6e8dea096476b481410342
def run():
md5('admin')
if __name__ == "__main__":
run()
3.6 Json
json模块,是python内部的一个模块,可以将python的数据格式转换为json格式的数据,也可以将json格式的数据转换为python的数据格式。
json格式,是一个数据格式(本质上就是个字符串,常用语网络数据传输)
# Python中的数据类型的格式
data = [
{"data":1,"name":'张三','age':23},
{"data":2,"name":'aym',"age":24},
('kinght',25)
]
# JSON格式
value = '[{"data": 1, "name": "张三", "age": 23}, {"data": 2, "name": "aym", "age": 24}, ["kinght", 25]]'
## JSON格式主要区别
# 1.没有小括号,data的元祖在JSON中是以列表体现
# 2.JSON格式没有单引号
3.6.1 json格式的作用?
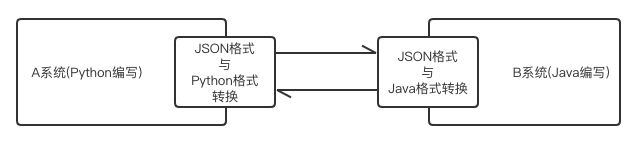
跨语言数据传输,例如:
A系统用Python开发,有列表类型和字典类型等。
B系统用Java开发,有数组、map等的类型。
语言不同,基础数据类型格式都不同。
为了方便数据传输,大家约定一个格式:json格式,每种语言都是将自己数据类型转换为json格式,也可以将json格式的数据转换为自己的数据类型。
3.6.2 数据类型转换为JSON格式(json.dumps) 被称为:序列化
import json
data = [
{"data":1,"name":'张三','age':23},
{"data":2,"name":'aym',"age":24},
('kinght',25)
]
res = json.dumps(data)
print(res) # 默认进行unicode编码 [{"data": 1, "name": "\u5f20\u4e09", "age": 23}, {"data": 2, "name": "aym", "age": 24}]
res = json.dumps(data,ensure_ascii=False)
print(res) # 不进行编码 [{"data": 1, "name": "张三", "age": 23}, {"data": 2, "name": "aym", "age": 24}]
案例:Flask网站传输数据
import json
from flask import Flask
app = Flask(__name__)
def index():
return '首页'
def users():
data = [
{"id": 1, "name": 'kinght', "age": 18},
{"id": 2, "name": 'aym', "age": 17},
]
return json.dumps(data)
app.add_url_rule('/index/',view_func=index,endpoint='index')
app.add_url_rule('/users/', view_func=users, endpoint='users')
if __name__ == '__main__':
app.run()
3.6.3 Json格式转换为数据类型(json.loads) 被称为:反序列化
import json
data_string = '[{"data": 1, "name": "\u5f20\u4e09", "age": 23}, {"data": 2, "name": "aym", "age": 24}, ["kinght", 25]]'
data_list = json.loads(data_string)
print(data_list) # [{'data': 1, 'name': '张三', 'age': 23}, {'data': 2, 'name': 'aym', 'age': 24}, ['kinght', 25]]
案例:爬取豆瓣网数据
网站传输数据,通常是使用json数据传输后,在网页拼接成数据,所以,我们可以抓取传输的数据流
import json,requests
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=5&page_start=20'
res = requests.get(
url=url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 获取到到数据是json格式
print(res.text)
'''
{"subjects":[{"episodes_info":"","rate":"8.0","cover_x":2000,"title":"天鹅挽歌","url":"https:\/\/movie.douban.com\/subject\/35258381\/","playable":false,"cover":"https://img9.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2717809625.jpg","id":"35258381","cover_y":3000,"is_new":false},{"episodes_info":"","rate":"6.3","cover_x":2191,"title":"这个杀手不太冷静","url":"https:\/\/movie.douban.com\/subject\/35505100\/","playable":true,"cover":"https://img3.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2814949620.jpg","id":"35505100","cover_y":3500,"is_new":false},{"episodes_info":"","rate":"6.7","cover_x":2000,"title":"蜘蛛侠:英雄无归","url":"https:\/\/movie.douban.com\/subject\/26933210\/","playable":false,"cover":"https://img9.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2730024046.jpg","id":"26933210","cover_y":2964,"is_new":false},{"episodes_info":"","rate":"8.4","cover_x":720,"title":"芬奇","url":"https:\/\/movie.douban.com\/subject\/26897885\/","playable":true,"cover":"https://img1.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2721066869.jpg","id":"26897885","cover_y":1080,"is_new":false},{"episodes_info":"","rate":"8.7","cover_x":1000,"title":"杰伊·比姆","url":"https:\/\/movie.douban.com\/subject\/35652715\/","playable":false,"cover":"https://img2.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2734251152.jpg","id":"35652715","cover_y":1500,"is_new":false}]}
'''
# 将json格式转换为python的数据格式
data_dict = json.loads(res.text)
# 为了更方便看,使用列表输出
for item in data_dict['subjects']:
print(item)
3.6.4 Json类型要求
并不是所有的python数据类型都能够被json,对数据类型是有要求的,默认只支持:
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
例如集合,他就无法被支持,如果要传输集合类型,就需要将其转换,或者自定义JSONEncoder
其他类型如果想要支持,需要自定义JSONEncoder 才能实现【目前只需要了解大概意思即可,以后项目开发中用到了还会讲解。】,例如:
import json
from decimal import Decimal
from datetime import datetime
data = [
{"id": 1, "name": "武沛齐", "age": 18, 'size': Decimal("18.99"), 'ctime': datetime.now()},
{"id": 2, "name": "alex", "age": 18, 'size': Decimal("9.99"), 'ctime': datetime.now()},
]
class MyJSONEncoder(json.JSONEncoder):
def default(self, o):
if type(o) == Decimal:
return str(o)
elif type(o) == datetime:
return o.strftime("%Y-%M-%d")
return super().default(o)
res = json.dumps(data, cls=MyJSONEncoder)
print(res)
3.6.5 将数据序列化并写入文件(json.dump)
import json
data = [
{"id": 1, "name": "武沛齐", "age": 18},
{"id": 2, "name": "alex", "age": 18},
]
file_object = open('xxx.json', mode='w', encoding='utf-8') # 文件句柄
json.dump(data, file_object) # 写入文件需要加入文件句柄
file_object.close()
3.6.6 读取文件中的数据并反序列化为python的数据类型(json.load)
import json
file_object = open('xxx.json', mode='r', encoding='utf-8')
data = json.load(file_object) # 读取文件需要加入文件句柄
print(data)
file_object.close()
3.7 时间模块
世界把时间分为两个类型,以英国皇家格林尼治天文台公布的时间为标准时间叫做世界统一时间,又被称为utc时间,我国比世界统一时间早八个小时,所以我国的本地时间是UTC+8
- UTC/GMT:世界时间
- 本地时间:本地时区的时间
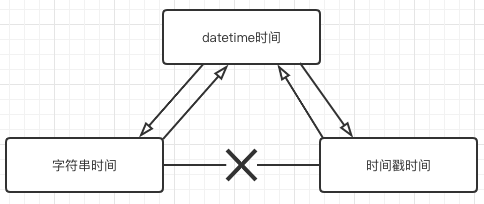
Python中关于时间处理的模块有两个,分别是time和datetime
3.7.1 time
import time
# 获取当前时间戳(自1970-1-1 00:00到现在的时间)
v1 = time.time()
print(v1) # 1650519189.819707
# 时区
v2 = time.timezone # 获取当前时区
print(v2 / 3600) # 一个小时等于3600秒 所以结果是-8.0 就是我们的时间比世界时间早8个小时
# 停止n秒,再执行后续的代码。
time.sleep(5)
3.7.2 datetime
3.7.2.1 datetime的时间计算
from datetime import datetime,timezone,timedelta
# 获取当地时间
v1 = datetime.now()
print(v1) # 2022-04-21 14:15:14.312667 这不是字符串而是一种特殊的数据类型叫做datetime类型
# 获取UTC时间
v2 = datetime.utcnow()
print(v2) # 2022-04-21 06:16:20.179755
# 获取指定时区的时间
## 定义时区
tz = timezone(timedelta(hours=7)) # 获取东7区时间
v3 = datetime.now(tz)
print(v3) # 2022-04-21 13:18:06.860596+07:00
# 时间的相加
v4 = datetime.now() + timedelta(days=140,minutes=5) # 当地时间加上140天5分钟
print(v4) # 2022-09-08 14:26:32.886264
# 时间的相减 计算时间差 (不支持datetime+datetime)
data = datetime.now() - datetime.utcnow()
print(data.days) # 获取相差天数
print(data.seconds) # 获取相差秒数 通过秒数乘除得到分钟和小时数
print(data.microseconds) # 得到相差毫秒数 999999 数字太大直接999999了
3.7.2.2 datetime与字符串转换
from datetime import datetime
# 字符串格式时间转换为datetime时间
text = "2022-04-21"
v5 = datetime.strptime(text,'%Y-%m-%d') # %Y年 %m月 %d天
print(v5) # 2022-04-21 00:00:00
# datetime转自字符串格式时间
v6 = datetime.now()
val = v6.strftime('%Y-%m-%d %H:%M:%S') # %Y年 %m月 %d天 %H小时 %M分钟 %S秒
print(val) # 2022-04-21 14:31:40
3.7.2.3 datetime与时间戳转换
import time
from datetime import datetime
# 时间戳格式转换为datetime格式
ctime = time.time()
v1 = datetime.fromtimestamp(ctime)
print(ctime) # 1650523027.863102
print(v1) # 2022-04-21 14:37:07.863102
# datetime格式转换为时间戳格式
v1 = datetime.now()
val = v1.timestamp()
print(v1) # 2022-04-21 14:38:18.167312
print(val) # 1650523098.167312
3.7.2.4 时间戳与字符串的转换需要通过datetime实现
3.7.3 案例
3.7.3.1 日志记录,将用户输入的信息写入到文件,文件名格式为年-月-日-时-分.txt。
'''
日志记录,将用户输入的信息写入到文件,文件名格式为`年-月-日-时-分.txt`
'''
import os
from datetime import datetime
def user_inp():
'''用户写入'''
user = ""
while True:
user_input = input("请输入内容(Q退出):")
if user_input.upper() == "Q":
break
user = user + user_input + '\n'
return user
def com_time():
'''获取时间'''
now_time = datetime.now()
now_time_str = now_time.strftime("%Y-%m-%d-%H-%M")
now_time_str = "{}.txt".format(now_time_str)
return now_time_str
def file(time_str,user_input):
'''文件路径'''
abs_path = os.path.abspath(__file__)
dir_path = os.path.dirname(abs_path)
file_path = os.path.join(dir_path,'file',time_str)
with open(file_path,mode='wt',encoding='utf-8') as file_object:
file_object.write(user_input)
file_object.flush()
def run():
input = user_inp()
time = com_time()
file(time,input)
if __name__ == '__main__':
run()
3.7.3.2 用户注册,将用户信息写入Excel,其中包含:用户名、密码、注册时间 三列
'''
用户注册,将用户信息写入Excel,其中包含:用户名、密码、注册时间 三列
'''
import os,hashlib
from datetime import datetime
from openpyxl import load_workbook,workbook
def md5(origin):
hashlib_object = hashlib.md5("asdasd!@#Sd23edasr31.".encode('utf-8'))
hashlib_object.update(origin.encode('utf-8'))
result = hashlib_object.hexdigest()
return result
def excel_path():
'''创建表格/获得表格路径'''
abs_path = os.path.abspath(__file__)
dir_path = os.path.dirname(abs_path)
excel_path = os.path.join(dir_path,'file','user.xlsx')
if not os.path.exists(excel_path):
wb = workbook.Workbook()
sheet = wb.worksheets[0]
# 表头设置
list = ['账号','密码','注册时间']
for num,value in enumerate(list,1):
cell = sheet.cell(1,num)
cell.value = value
wb.save(excel_path)
return excel_path
def user_inp():
# 账号密码
username = input("请输入用户名:").strip()
passwd = input("请输入密码:").strip()
passwd = md5(passwd)
# 获取时间
time = datetime.now()
time = time.strftime("%Y-%m-%d %H:%M:%S")
user_list = [username,passwd,time]
return user_list
def excel(user,file_path):
'''向excel写入数据'''
wb = load_workbook(file_path)
sheet = wb.worksheets[0]
next_row_position = sheet.max_row + 1 # 获得写入了第几行
for num,value in enumerate(user,1):
cell = sheet.cell(next_row_position,num)
cell.value = value
wb.save(file_path)
def run():
# 1.获取表格路径/创建表格 完成
file_path = excel_path()
# 2.获取用户输入用户名、密码、获取当前时间,形成列表
user = user_inp()
# 3.获取表格句柄、用户输入,找到最下方那一行写入用户名、密码、水岸
excel(user,file_path)
if __name__ == "__main__":
run()
3.8 re模块
python中提供了re模块,可以处理正则表达式并对文本进行处理。
3.8.1 findall,获取匹配到的所有数据
import re
text = "dsf130429191912015219k13042919591219521Xkk"
data_list = re.findall("(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)", text)
print(data_list) # [('130429', '1919', '12', '01', '521', '9'), ('130429', '1959', '12', '19', '521', 'X')]
3.8.2 match,从起始位置开始匹配,匹配成功返回一个对象,未匹配成功返回None
一般用于匹配格式,而不是采集数据
import re
text = "大小逗2B最逗3B欢乐"
data = re.match("逗\dB", text)
print(data) # None
import re
text = "逗2B最逗3B欢乐"
data = re.match("逗\dB", text)
if data:
# 执行data.group()获取文本
content = data.group() # "逗2B"
print(content)
3.8.3 search,浏览整个字符串去匹配第一个,未匹配成功返回None
import re
text = "大小逗2B最逗3B欢乐"
data = re.search("逗\dB", text)
if data:
print(data.group()) # "逗2B"
3.8.4 sub,替换匹配成功的位置
import re
text = "逗2B最逗3B欢乐"
data = re.sub("\dB", "沙雕", text)
print(data) # 逗沙雕最逗沙雕欢乐
import re
text = "逗2B最逗3B欢乐"
data = re.sub("\dB", "沙雕", text, 1) # 支持替换几个,这里就是从左至右替换1个
print(data) # 逗沙雕最逗3B欢乐
3.8.5 split,根据匹配成功的位置进行字符串分割
import re
text = "逗2B最逗3B欢乐"
data = re.split("\dB", text)
print(data) # ['逗', '最逗', '欢乐']
import re
text = "逗2B最逗3B欢乐"
data = re.split("\dB", text, 1)
print(data) # ['逗', '最逗3B欢乐']
3.8.6 finditer
和findall差不多,不同的是,finditer不会立即生成列表,会返回一个迭代器,迭代一次,获取一次
import re
text = "逗2B最逗3B欢乐"
data = re.finditer("\dB", text)
for item in data:
print(item.group())
import re
text = "逗2B最逗3B欢乐"
data = re.finditer("(?P<xx>\dB)", text) # 命名分组
for item in data:
print(item.groupdict())
import re
text = "dsf130429191912015219k13042919591219521Xkk"
data_list = re.findall("\d{6}(\d{4})(\d{2})(\d{2})\d{3}[\d|X]",text)
print(data_list) # [('1919', '12', '01'), ('1959', '12', '19')]
# 输出字典只能使用finditer
data_list = re.finditer("\d{6}(?P<year>\d{4})(?P<month>\d{2})(?P<day>\d{2})\d{3}[\d|X]",text)
for item in data_list:
print(item.groupdict())
'''输出结果
{'year': '1919', 'month': '12', 'day': '01'}
{'year': '1959', 'month': '12', 'day': '19'}
'''
本文来自博客园,作者:kinghtxg,转载请注明原文链接:https://www.cnblogs.com/kinghtxg/articles/17158078.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号