学习笔记-Python开发-019_函数进阶知识
1 参数的内存地址
为了详细的剖析传参的实现原理,我们就得知晓在运行过程中内存具体发生了什么样的变化?
在python中为我们提供了一个函数id()来查看值的内存地址(以十进制展示)
username = 'kinght'
print(id(username)) # 140270948209840
v1 = [11,22,33]
v2 = [11,22,33]
print(id(v1)) # 140479656404096
print(id(v2)) # 140479656262784
v3 = v1
print(id(v3)) # 140696552252608
s1 = (11,22,33)
s2 = s1
print(id(s1)) # 140208134368960
print(id(s2)) # 140208134368960
1.1 函数传参的本质其实是传递内存地址
def demo(b):
print(id(b))
a = 123
print(id(a))
demo(a)
'''输出结果
140530256566448
140530256566448
'''
Python参数的这一特性有两个好处:
- 节省内存
- 对于可变类型且函数中修改元素的内容,所有的地方都会修改。可变类型:列表、字典、集合
# 参数是可变类型list/dict/set & 修改内部修改
def func(data):
data.append('666')
return data # 注意:返回值同样返回的是内存地址
data_list = ['111','222','333']
print(id(data_list),data_list) # 140613337261312 ['111', '222', '333']
fun_data = func(data_list)
print(id(fun_data),fun_data) # 140613337261312 ['111', '222', '333', '666']
# 特殊情况:不可变类型,无法修改内部元素,只能重新赋值。
def func(data):
data = "kinght"
v1 = "aym"
func(v1)
其他很多编程语言执行函数时,默认传参时会将数据重新拷贝一份,会浪费内存
提示注意:其他语言也可以通过 ref 等关键字来实现传递内存地址
当然,如果你不想让外部的变量和函数内部参数的变量一致,也可以选择将外部值拷贝一份,再传给函数
# 拷贝传参
import copy
# 可变类型 & 修改内部修改
def func(data):
data.append(999)
v1 = [11, 22, 33]
new_v1 = copy.deepcopy(v1) # 拷贝一份数据,把拷贝的数据传入参数
func(new_v1)
print(v1) # [11,22,33]
TIPS:python的内存驻留机制
def demo1():
demo = [1,2,3]
return demo
# 函数的每次调用结束,都会销毁内部所有的值
# 所以
res1 = demo1()
res2 = demo1()
# 由于demo1被调用了两次,所以生成了两次demo并将其进行返回赋值
## 两次都各不相同
print(id(res1)) # 140651455784000
print(id(res2)) # 140651455642752
# 但是也有例外
def demo2():
demo = '123'
return demo
res3 = demo2()
res4 = demo2()
# 由于python有着变量驻留机制优化内存,对于所有都不可变数据类型可能会存在指向同一内存地址
print(id(res3)) # 140518848596080
print(id(res4)) # 140518848596080
# 变量驻留机制演示
a = '123456'
b = '123456'
print(id(a)) # 140375102654896
print(id(b)) # 140375102654896
1.2 函数参数的默认值
def func(a,b=1):
print(a,b)
Python在创建函数(未执行)时,如果发现函数的参数中有默认值,则在函数内部会创建一块区域并赋值这个默认值
当执行函数但是并未向默认值区域传值的时候,则让b指向函数维护的那个值的地址
func(1) # 1 1
当执行函数向默认值区域传值的时候,则让b指向新传入的值的地址
func(1,2) # 1 2
1.2.1 注意:默认参数如果可变会踩坑
【默认参数的值是可变类型 list/dict/set】 & 【函数内部会修改这个值】
案例1:
def func(a1,a2=[1,2]):
a2.append(666)
print(id(a2))
print(a1,a2)
'''函数讲解
func函数在定义的时候即会生成a2=[1,2]的内存空间,此函数空间在整个程序运行阶段都存活
假设传入没有传入a2的值,即指向默认值,a2.append即加载默认的空间中
假设有传入值,则将a2指向传入值的空间
'''
func(100) # 140315508122624 100 [1, 2, 666]
'''
func(100)没有传入a2值,则a2.append则添加默认生成的140315508122624空间a2=[1,2]中
a2使用的内存空间id是140315508122624
'''
func(200) # 140315508122624 200 [1, 2, 666, 666]
'''
func(200)没有传入a2值,则a2.append则添加默认生成的140315508122624空间a2=[1,2,666]中
a2使用的内存空间id是140315508122624
'''
func(99,[77,88]) # 140315508124864 99 [77, 88, 666]
'''
func(99,[77,88])传入了a2值,则原本的140315508122624空间被[77,88]的140315508124864空间覆盖,则a2.append则添加到a2=[77,88]中
a2使用的内存空间id是140315508124864
'''
func(300) # 140315508122624 300 [1, 2, 666, 666, 666]
'''
func(300)没有传入a2值,则a2.append则添加默认生成的140315508122624空间a2=[1,2,666,666]中
a2使用的内存空间id是140315508122624
'''
案例2:
def func(a1,a2=[1,2]):
a2.append(a1)
return a2
v1 = func(10)
v2 = func(20)
v3 = func(30, [11, 22])
v4 = func(40)
print(v1)
print(v2)
print(v3)
print(v4)
'''
输出结果:
[1, 2, 10, 20, 40]
[1, 2, 10, 20, 40]
[11, 22, 30]
[1, 2, 10, 20, 40]
函数讲解:
1.在函数func定义的时候会生成一块内存空间存放默认参数a2=[1,2]
2.v1 = func(10)执行,由于a2没有传入值,a2即使用默认空间a2=[1,2],append结果默认空间a2=[1,2,10],返回值为return a2即v1指向a2默认空间内存地址
3.v2 = func(20)执行,由于a2没有传入值,a2即使用默认空间a2=[1,2,10],append结果默认空间a2=[1,2,10,20],返回值为return a2即v2指向a2默认空间内存地址
4.v3 = func(30, [11, 22])指向,a2没有使用默认空间,创建了新空间a2=[11, 22],append结果新空间a2=[11, 22, 30],返回值return a2即v3指向a2新空间内存地址
5.v4 = func(40)执行,由于a2没有传入值,a2即使用默认空间a2=[1,2,10,20],append结果默认空间a2=[1,2,10,20,40],返回值为return a2即v4指向a2默认空间内存地址
6.此刻 v1.v2.v4都指向最初生成都默认空间,而默认空间都值是[1, 2, 10, 20, 40],v3指向新空间,新空间对应都值是[11, 22, 30]
'''
2 动态参数的补充
在前文:10函数入门提到过,动态参数,定义函数时在形参位置用 *或** 可以接任意个参数
def func(*args,**kwargs):
print(args,kwargs)
func("宝强","杰伦",n1="alex",n2="eric")
在定义函数时可以用 *和**,其实在执行函数时,也可以用
- 形参固定,实参用
*和**
def func(a1,a2):
print(a1,a2)
func( 11, 22 )
func( a1=1, a2=2 )
func( *[11,22] ) # 相当于打散,按顺序赋值,把11交给a1,22交给a2
func( **{"a1":11,"a2":22} ) # 相当于打散,按关键字赋值,把11交给a1,22交给a2
- 形参用
*和**,实参也用*和**
def func(*args,**kwargs):
print(args,kwargs)
# 注意,这里会把他们都当作顺序传参
## args = ([11,22,33],{"k1":1,"k2":2}) kwargs = {}
func( [11,22,33], {"k1":1,"k2":2} )
# 这里在实参中使用*和**
## args=(11,22,33),kwargs={"k1":1,"k2":2}
func( *[11,22,33], **{"k1":1,"k2":2} )
# 值得注意:按照这个方式将数据传递给args和kwargs时,数据是会重新拷贝一份的(可理解为内部循环每个元素并设置到args和kwargs中)
在format字符串格式化也支持这样的用法
v1 = "我是{},年龄:{}".format("kinght",18)
v2 = "我是{name},年龄:{age}".format(name="kinght",age=18)
v3 = "我是{},年龄:{}".format(*["kinght",18])
v4 = "我是{name},年龄:{age}".format(**{"name":"kinght","age":18})
案例:下载抖音视频
抖音视频下载,首先需要找到视频解析源,这里使用的
https://www.dy114.com/douyin
获取解析源后,在目录下创建了一个file的文件夹,创建了一个7_url.csv的文件
鱼香肉丝,http://v11-x.douyinvod.com/4fdc29fe92aabe5280e599568adaae8b/6219cdd2/video/tos/cn/tos-cn-ve-15-alinc2/852932a75a8443af97f51825476c723a/?a=1128&br=1633&bt=1633&cd=0%7C0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=YbbdSWWFBNFqd.4YagD1233CCd3w&l=20220226134809010212170090122648AC&lr=&mime_type=video_mp4&net=0&pl=0&qs=0&rc=ajV4NTU6Zmo3OzMzNGkzM0ApOGRmODZnZTtmNzdlZWk4OWcpaGRqbGRoaGRmNWlpLXI0MGRgYC0tZC0vc3MzYDIyNTMwLTMvNjI0MGFeOmNwb2wrbStqdDo%3D&vl=&vr=
游戏指挥官,http://v5-f.douyinvod.com/e14bc1c0ab2ccf947956b5a16893b4cf/6219cdfb/video/tos/cn/tos-cn-ve-15-alinc2/ccb04fdcc55546d29ac4fe6737eda997/?a=1128&br=905&bt=905&cd=0%7C0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=YbbdSWWFBNFqd.4YagD12EqCCd3w&l=2022022613491001019405122531268848&lr=&mime_type=video_mp4&net=0&pl=0&qs=0&rc=M2QzM2U6ZjM3OzMzNGkzM0ApMzo6NTo2PGU2N2g0M2c0aWcpaGRqbGRoaGRmY2BoMXI0MGI1YC0tZC1hc3NhMl9hLV4wYmMuMmM1XjZjOmNwb2wrbStqdDo%3D&vl=&vr=
打工人模拟器,http://v1-cold1.douyinvod.com/a3de8062cf93de87082c77dd24a20976/6219ce00/video/tos/cn/tos-cn-ve-15-alinc2/230204e5b7c043b297ec5bf0b7f9e8b4/?a=1128&br=1078&bt=1078&cd=0%7C0%7C0%7C0&ch=0&cr=0&cs=0&cv=1&dr=0&ds=3&er=&ft=ElUQrWWFBNFqd.4YagD12SGCCd3w&l=202202261350220102091561561025F834&lr=&mime_type=video_mp4&net=0&pl=0&qs=0&rc=M211ajQ6ZnFnOzMzNGkzM0ApOTs8ZDdoZGVlN2g8aWg1PGcpaGRqbGRoaGRmYi1lLXI0MDBfYC0tZC0vc3NeMy5jLTYwLTFhMi9eYC0uOmNwb2wrbStqdDo%3D&vl=&vr=
然后进行文件读取下载
import requests,os
def path():
abs_path = os.path.abspath(__file__)
dir_path = os.path.dirname(abs_path)
return dir_path
def csv_file():
csv_file_path = os.path.join(path(),'file','7_url.csv')
with open(csv_file_path,mode='rt',encoding='utf-8') as csv:
for file in csv:
file = file.strip().split(',') # 把字符串进行分割成列表
download(*file) # 传入download进行下载
def download(title,url):
res = requests.get(
url=url,
headers={
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
)
movie_file_path = os.path.join(path(),'file','{}.mp4'.format(title))
with open(movie_file_path,mode='wb') as file:
file.write(res.content)
csv_file()
3 函数与函数名
函数其实就是一大堆代码的集合,可以把他看作一个变量,函数名就相当于变量名代指这个函数
def add(n1,n2):
return n1 + n2
注意:由于解释型语言从上而下边解释边执行的特点,函数必须在使用之前定义,否则无法识别函数位置
# 正确
def add(n1,n2):
return n1 + n2
ret = add(1,2)
print(ret)
# 错误
ret = add(1,2)
print(ret)
def add(n1,n2):
return n1 + n2
3.1 函数做元素
既然函数就相当于是一个变量,那么在列表等元素中是否可以把行数当做元素呢?
def func():
return 123
list = ['kinght','22',func,func()]
print(list[0]) # kinght
print(list[1]) # 22
print(list[2]) # <function func at 0x7fb3b80e7040>
print(list[3]) # 123
# 加括号执行函数,获得的值应该是返回值
print(list[2]()) # 123
注意:函数同时也可被哈希,所以函数名也可以当做集合的元素、字典的键。
使用情景:功能选择
def send_msg():
"""发送短信"""
pass
def send_email():
"""发送邮件"""
pass
def send_wechat():
"""发送微信"""
pass
def send_file():
"""发送文件"""
pass
function_dict = {
"1": send_msg,
"2": send_email,
"3": send_wechat,
"4": send_file
}
print("欢迎使用系统")
print("请选择:1.发送短信;2.发送邮件;3.发送微信;4.发送文件")
choice = input("输入选择的序号") # "1"
# 获取字典value值(函数名),如果超出范围的输入,根据字典特性返回Null
func = function_dict.get(choice)
if not func:
print("输入错误")
else:
# 执行函数
func()
注意:上诉案例需要在参数相同时才可用,如果参数不一致,会出错。所以,在项目设计时就要让程序满足这一点,如果无法满足,也可以通过其他手段实现
def send_msg(phone,content):
"""发送短信"""
pass
def send_email(to_email,content,title):
"""发送邮件"""
pass
def send_wechat(wechat_id,content):
"""发送微信"""
pass
def send_file(file_path):
"""发送文件"""
pass
function_dict = {
"1": [send_msg,['手机号','短信内容']],
"2": [send_email,['收件邮箱','邮箱内容','邮件抬头']],
"3": [send_wechat,['微信id','消息内容']],
"4": [send_file,['文件名']]
}
print("欢迎使用系统")
print("请选择:1.发送短信;2.发送邮件;3.发送微信;4.发送文件")
choice = input("输入选择的序号") # "1"
# 获取字典value值(函数名),如果超出范围的输入,根据字典特性返回Null
func = function_dict.get(choice)
if not func:
print("输入错误")
else:
# 执行函数 -> 将参数打包成列表存放,使用动态元素进行解压,规避元素个数不统一
func[0](*func[1])
3.2 函数名赋值
函数名其实就是一个指向存放函数空间的变量名,如果将函数名赋值给另外一个变量,则此变量也会代指该函数
def func(a1,a2):
print(a1,a2)
abc = func
# 此时,abc和func都代指上面的那个函数,所以都可以被执行。
func(1,1)
abc(2,2)
#其实上诉案例已经使用过函数名赋值啦
def func():
return 123
list = [func,'1']
list[0]() # 列表第一个元素 == func ,加括号就可以直接执行
对函数名重新赋值,如果将函数名修改为其他值,函数名便不再代指函数
def func(a1,a2):
print(a1,a2)
# 执行func函数
func(11,22)
# func重新赋值成一个字符串
func = "kinght"
print(func) # kinght
# func 又重新指向另一个函数
def func():
print(666)
func() # 666
注意:由于函数名被重新定义之后,就会变量新被定义的值,所以大家在自定义函数时,不要与python内置的函数同名,否则会覆盖内置函数的功能
# len内置函数用于计算值得长度
v1 = len("kinght")
print(v1) # 6
# len重新定义成另外一个函数
def len(a1,a2):
return a1 + a2
# 以后执行len函数,只能按照重新定义的来使用
v3 = len(1,2)
print(v3)
3.3 函数名做参数和返回值
函数名其实就一个变量,代指某个函数,所以,他和其他的数据类型一样,也可以当做函数的参数和返回值
'''函数名作参数
调用handler函数,参数为plus,未加括号不执行,传入后在res = func(10) -=> plus(10)
'''
def plus(num):
return num + 100
def handler(func):
res = func(10)
print(res)
handler(plus)
'''函数名作返回值
运行handler()函数,函数内将plus函数返回到了result变量,后执行result变量
'''
def plus(num):
return num + 100
def handler():
print("执行handler函数")
return plus
result = handler()
data = result(20) # 120
print(data)
4 作用域
作用域可以看做围墙,在围墙内部的数据可以共享,而围墙外无法访问围墙内部的数据
4.1 函数为作用域
Python以函数为作用域,所以在函数内创建的所有数据,可以此函数中被使用,无法在函数之外的其他位置被使用
重点是Python以函数为作用域,这其实是和其他的编程语言有差别的地方,其他的很多编程语言很多是以花括号为作用域
def func():
for num in range(10):
print(num) # 0,1,2,3,4,5,6,7,8,9
print(num) # 9
if 1 == 1:
value = "admin"
print(value) # admin
print(value) # admin
if 1 > 2: # 因为这里条件不成立,所以下方max_num并没有赋值
max_num = 10
print(max_num)
# print(max_num) # 报错
func()
我们来分析一下代码,调用func()进入了函数,执行了一个for循环,num取出了0~9的数据,num的最后赋值是9,但由于它是同一个函数,所以在循环之外的print(num)同样会输出9,下方if是一样的,在循环、判断中赋的值,只要在同一个作用域中都能够被获取
4.2 全局和局部
python是以函数作为作用域,但函数的作用域,通常称为局部作用域,在函数之外,称之为全局作用域,前文把作用域比喻为围墙
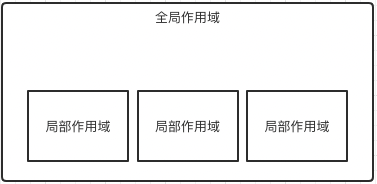
围墙里能够访问围墙外的数据,而围墙外不能访问围墙里的数据,即局部作用域能够方位全局作用域的数据
# 全局变量(变量名大写)
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
# 局部变量
url = "http://www.xxx.com"
...
def upload():
file_name = "rose.zip"
...
COUNTRY和CITY_LIST是在全局作用域中,全局作用域中创建的变量称之为【全局变量】,可以在全局作用域中被使用,也可以在其局部作用域中被使用。
download和upload函数内部维护的就是一个局部作用域,在各自函数内部创建变量称之为【局部变量】,且局部变量只能在此作用域中被使用。
局部作用域中想使用某个变量时,寻找的顺序为:优先在局部作用域中寻找,如果没有则去上级作用域中寻找。
注意:全局变量一般都是大写。
# 约定编码规范,全局变量应该大些 -> 这里为了演示全局变量与局部变量冲突所以全部小写
data_list = [1,2,3,4,5]
def func():
data_list = [6,7,8,9]
print(data_list)
print(data_list) # [1, 2, 3, 4, 5]
func() # [6, 7, 8, 9]
4.3 global关键字
默认情况下,在局部作用域对全局变量只能进行:读取和修改内部元素(可变类型),无法对全局变量进行重新赋值
案例:在局部作用域中修改全局变量 -> 可变类型
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
print(CITY_LIST)
CITY_LIST.append("广州") # 指针指向的空间不能变,但可变类型空间内部的值可以变
CITY_LIST[0] = "南京"
print(CITY_LIST)
download()
print(CITY_LIST)
虽然在可变类型的情况下,局部作用域可以修改可变类型的值,但是由于无法修改指针指向的内存地址,所以无法重新赋值
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
# 不是对全部变量赋值,而是在局部作用域中又创建了一个局部变量 CITY_LIST 。
CITY_LIST = ["河北","河南","山西"]
print(CITY_LIST)
download()
print(CITY_LIST) # ["北京","上海","深圳"]
想要在局部作用域中对全局变量重新赋值,则可以基于 global关键字实现
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
global CITY_LIST # 指示CITY_LIST使用的是全局变量
CITY_LIST = ["河北","河南","山西"]
print(CITY_LIST)
global CHINA # 定义全局变量
CHINA = "中华人民共和国"
download()
print(CITY_LIST) # ['河北', '河南', '山西']
print(CHINA) # 中华人民共和国
5 综合案例
- 启动后,让用户选择专区,每个专区用单独的函数实现,提供的专区如下:
- 下载 花瓣网图片专区
- 下载 抖音短视频专区
- 下载 NBA锦集 专区
- 在用户选择了某个功能之后,表示进入某下载专区,在里面循环提示用户可以下载的内容选项(已下载过的则不再提示下载)
提醒:可基于全部变量保存已下载过得资源。- 在某个专区中,如果用户输入(Q/q)表示 退出上一级,即:选择专区。
- 在选择专区如果输入Q/q则退出整个程序。
5.1 简单直观学习版本
import requests,os
SELECTED_IMAGE_SET = set()
SELECTED_MOVIE_SET = set()
SELECTED_NBA_SET = set()
def path():
'''路径'''
abs_path = os.path.abspath(__file__)
dir_path = os.path.dirname(abs_path)
down_path = os.path.join(dir_path,'file')
return down_path
def down_load(path,url):
'''下载文件'''
res = requests.get(
url=url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 保存
with open(path, mode='wb') as file_object:
file_object.write(res.content)
def down_image():
'''
花瓣网专区
'''
image_dict = {
"1": ("吉他男神", "https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V"),
"2": ("漫画美女", "https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO"),
"3": ("游戏地图", "https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd"),
"4": ("alex媳妇", "https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz"),
}
while True:
# 构造输出
text_list = []
for key,value in image_dict.items():
if key in SELECTED_IMAGE_SET:
continue
text_list.append("{}.{}".format(key,value[0]))
if text_list:
text = ";".join(text_list)
else:
print("无可用下载项,自动退出")
return
user_input = input("{};Q.退出:".format(text)).strip()
# 返回上一步
if user_input.upper() == "Q":
return
# 资源不存在
if user_input in SELECTED_IMAGE_SET:
print("此资源已被下载,无法继续下载")
continue
if not image_dict.get(user_input):
print("此序号不存在资源,请重新选择")
continue
# 保存路径
png_path = os.path.join(path(), "{}.png".format(image_dict[user_input][0]))
url = image_dict[user_input][1]
# 资源下载
down_load(png_path,url)
# 加入已下载序号
SELECTED_IMAGE_SET.add(user_input)
def down_movie():
'''
抖音短视频专区
'''
# 可供用户下载的短视频如下
video_dict = {
"1": {"title": "东北F4模仿秀",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"},
"2": {"title": "卡特扣篮",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"},
"3": {"title": "罗斯mvp",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg"},
}
while True:
# 构造输出
text_list = []
for key,value in video_dict.items():
if key in SELECTED_MOVIE_SET:
continue
res = "{}.{}".format(key,value['title'])
text_list.append(res)
if text_list:
text = ";".join(text_list)
else:
print("无可用下载项,自动退出")
return
# 用户输入
user_input = input("{};Q.退出:".format(text)).strip()
# 检查用户输入
if user_input.upper() == "Q":
return
if user_input in SELECTED_MOVIE_SET:
print("此资源已被下载,无法继续下载")
continue
if not video_dict.get(user_input):
print("此序号不存在资源,请重新选择")
continue
# 获取保存路径
movie_path = os.path.join(path(),'{}.mp4'.format(video_dict[user_input]['title']))
# 获取url
movie_url = video_dict[user_input]['url']
down_load(movie_path,movie_url)
SELECTED_MOVIE_SET.add(user_input)
def down_NBA():
'''
NBA专区
'''
nba_dict = {
"1": {"title": "威少奇才首秀三双",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300fc20000bvi413nedtlt5abaa8tg&ratio=720p&line=0"},
"2": {"title": "塔图姆三分准绝杀",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag&ratio=720p&line=0"}
}
while True:
# 输出构造列表
text_list = []
for key,value in nba_dict.items():
if key in SELECTED_NBA_SET:
continue
res = "{}.{}".format(key,value['title'])
text_list.append(res)
# 如果text_list不为空就转换为字符串
if text_list:
text = ";".join(text_list)
else:
print("无可用下载项,自动退出")
return
user_input = input('{};Q.退出:'.format(text)).strip()
if user_input.upper() == "Q":
return
if user_input in SELECTED_NBA_SET:
print("此资源已被下载,无法继续下载")
continue
if not nba_dict.get(user_input):
print("此序号不存在资源,请重新选择")
continue
# 获取路径
nba_path = os.path.join(path(),"{}.mp4".format(nba_dict[user_input]['title']))
# 获取url
nba_url = nba_dict[user_input]['url']
# 下载
down_load(nba_path,nba_url)
SELECTED_NBA_SET.add(user_input)
print("欢迎使用资源下载器")
func_dict = {
'1':down_image,
'2':down_movie,
'3':down_NBA
}
# 选择系统
while True:
user_input = input("进入专区选择:1.花瓣网图片专区 2.抖音短视频专区 3.NBA锦集专区 Q:退出 :").strip()
if user_input.upper() == "Q":
break
func = func_dict.get(user_input)
if not func:
print("输入有误,请检查输入")
# 进入专区
func()
5.2 进阶版本
import requests,os
DB = {
"1": {
"area": "花瓣网图片专区",
"total_dict": {
"1": ("吉他男神", "https://hbimg.huabanimg.com/51d46dc32abe7ac7f83b94c67bb88cacc46869954f478-aP4Q3V"),
"2": ("漫画美女", "https://hbimg.huabanimg.com/703fdb063bdc37b11033ef794f9b3a7adfa01fd21a6d1-wTFbnO"),
"3": ("游戏地图", "https://hbimg.huabanimg.com/b438d8c61ed2abf50ca94e00f257ca7a223e3b364b471-xrzoQd"),
"4": ("alex媳妇", "https://hbimg.huabanimg.com/4edba1ed6a71797f52355aa1de5af961b85bf824cb71-px1nZz"),
},
"ext": "png",
"selected": set()
},
"2": {
"area": "抖音短视频专区",
"total_dict": {
"1": {"title": "东北F4模仿秀",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"},
"2": {"title": "卡特扣篮",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"},
"3": {"title": "罗斯mvp",
'url': "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg"},
},
"ext": "mp4",
"selected": set()
},
"3": {
"area": "NBA锦集专区",
"total_dict": {
"1": {"title": "威少奇才首秀三双",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300fc20000bvi413nedtlt5abaa8tg&ratio=720p&line=0"},
"2": {"title": "塔图姆三分准绝杀",
"url": "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0d00fb60000bvi0ba63vni5gqts0uag&ratio=720p&line=0"}
},
"ext": "mp4",
"selected": set()
},
}
def path():
'''路径'''
abs_path = os.path.abspath(__file__)
dir_path = os.path.dirname(abs_path)
down_path = os.path.join(dir_path,'file')
return down_path
def down_load(path,url):
'''下载文件'''
res = requests.get(
url=url,
headers={
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
# 保存
with open(path, mode='wb') as file_object:
file_object.write(res.content)
def handler(area_info):
summary = "欢迎进入{}专区".format(area_info["area"])
print(summary)
while True:
text_list = []
for key,value in area_info["total_dict"].items():
# 判断key是否在selected中
if key in area_info['selected']:
continue
# value 分为 dict和tuple两种处理
if type(value) == tuple:
data = "{}.{}".format(key,value[0])
elif type(value) == dict:
data = "{}.{}".format(key,value["title"])
text_list.append(data)
# 转换为字符串输出
if text_list:
text = ";".join(text_list)
else:
print("无可用下载项,自动退出")
return
text = "{};Q.退出:".format(text)
# 输出格式
user_input = input(text).strip()
if user_input.upper() == "Q":
return
if user_input in area_info['selected']:
print("此资源已被下载,无法继续下载")
continue
if not area_info['total_dict'].get(user_input):
print("此序号不存在资源,请重新选择")
continue
# 获取路径和url
lie = area_info['total_dict'].get(user_input)
if type(lie) == tuple:
file_path = os.path.join(path(),"{}.mp4".format(lie[0]))
file_url = lie[1]
elif type(lie) == dict:
file_path = os.path.join(path(),"{}.mp4".format(lie["title"]))
file_url = lie['url']
down_load(file_path,file_url)
area_info["selected"].add(user_input)
print("欢迎使用资源下载器")
while True:
user_input = input("进入专区选择:1.花瓣网图片专区 2.抖音短视频专区 3.NBA锦集专区 Q:退出 :").strip()
if user_input.upper() == "Q":
break
# 寻找字典
area_dict = DB.get(user_input)
if not area_dict:
print("输入错误,请重新输入")
continue
handler(area_dict)
本文来自博客园,作者:kinghtxg,转载请注明原文链接:https://www.cnblogs.com/kinghtxg/articles/17158044.html

