学习笔记-Python开发-010_python从网络中保存文件和图片的基础
因为学习案例需要从网络中爬取一段文字信息和一个图片保存到本地,所以需要模拟浏览器进行发包,虽然python自己可以完成,但是太麻烦了,这里使用的是requests模块
1 从网络中下载requests模块
-
mac配置文件中没有pip
既然要使用requests模块,肯定要事先使用pip进行下载,可很遗憾的是zsh告诉我,它找不到pip,pip是安装python的时候肯定同时安装了的,只是没有被加载到环境变量中。
# mac电脑加pip进入环境变量(原本命令意思是get-pip.py是安装脚本) sudo python get-pip.py -
安装requests模块
直接使用命令安装
pip3 install requests
2 基础使用
模块的基本使用是requests.get(url="资源地址")就可以获取网页的内容句柄,直接打印的是状态码,需要使用.content来获取其中的文本信息
import requests
res = requests.get(url="https://www.kinghtxg.com/atom.xml")
print(res) # 得到了返回值 <Response [200]>
print(res.content) # 得到网址返回的文本信息
但是某些网站直接发包,由于没有来源header信息(浏览器、操作系统等),会被识别出来是爬虫,所以不会进行返回
# 以豆瓣为例
import requests
res = requests.get(url="https://movie.douban.com/")
print(res) # <Response [418]>
print(res.content) # b'' 返回数据空,被检查到是爬虫
不过,这个简单,只需要伪造header头即可
import requests
# 伪造header头
res = requests.get(
url="https://movie.douban.com/",
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36"
}
)
header头的信息可以通过浏览器进行获取,打开浏览器->开发者工具->找到Network->刷新网页->找到弹出的内容,查看里面的信息->找到User-Agent,然后里面的内容复制下来即可
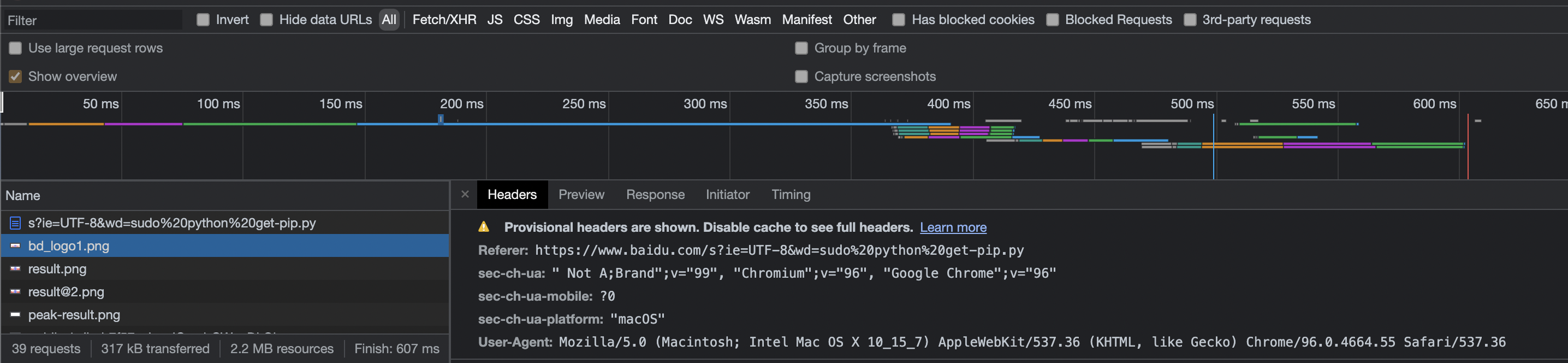
于是豆瓣就可以成功爬取了!
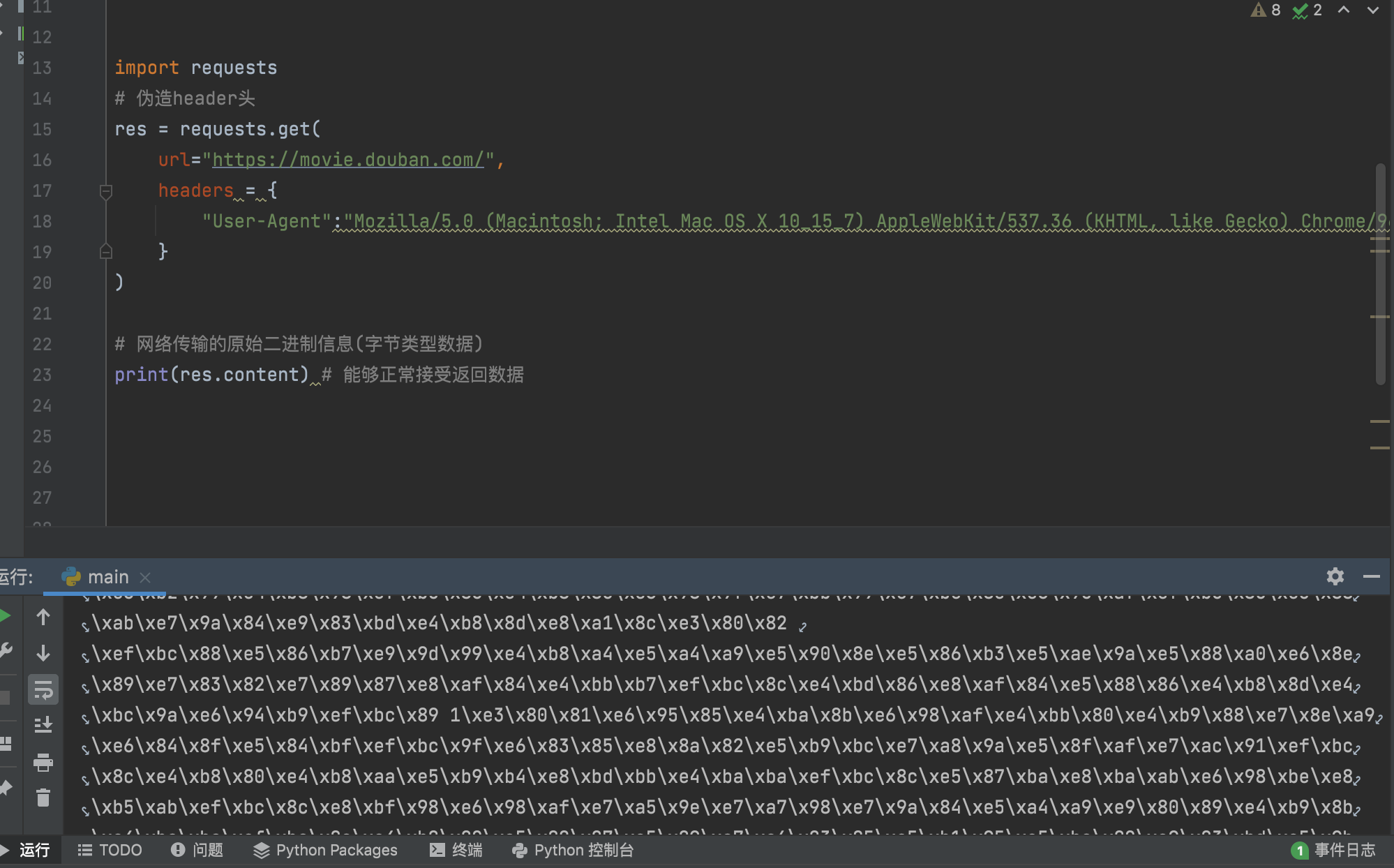
总所周知,通过网络传输的数据为了节省带宽使用的是字节码,我们可以直接保存,但不能直接显示成字符
3 文件操作
3.1 读取res.content
读取的时候需要将字节码转换成unicode的字符串
import requests
# 伪造header头
res = requests.get(
url="https://movie.douban.com/",
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36"
}
)
print(res.content.decode("utf-8"))
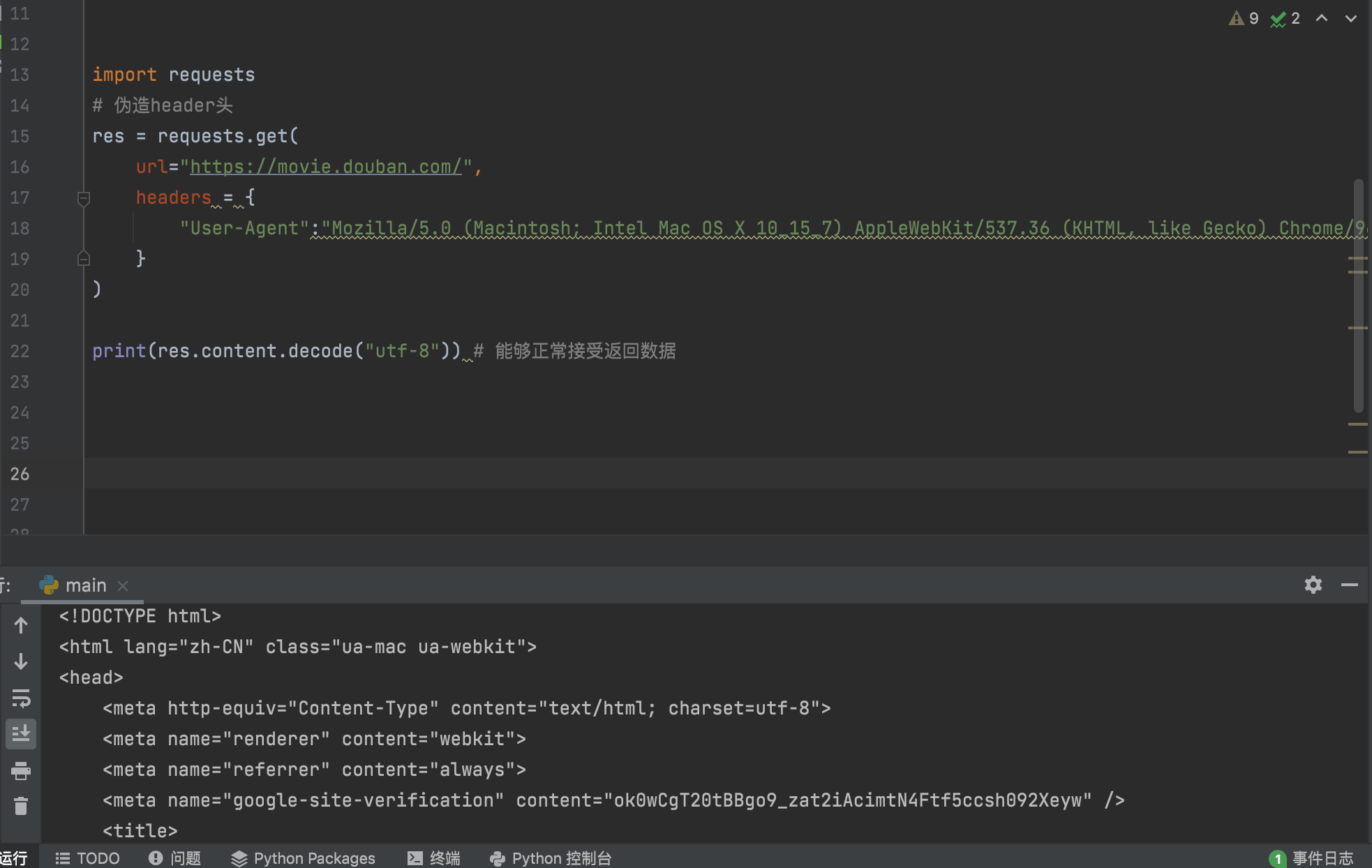
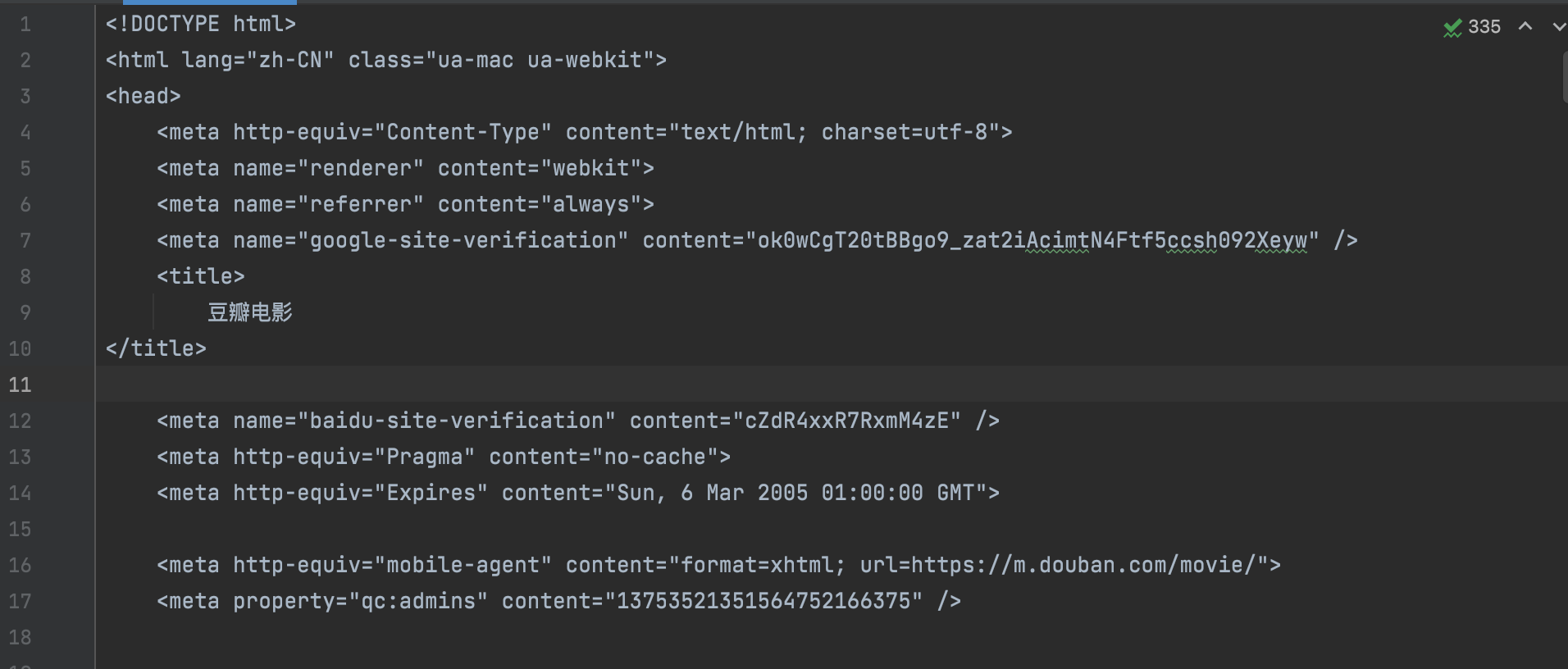
3.2 保存res.content到文件
在上文中,已经将豆瓣的网页数据字节码接收到了res句柄中,只需要file_object打开一个待保存的txt文件,然后将res.content写入到file_object打开的文件中即可
file_object = open("douban.txt",mode='wb')
file_object.write(res.content)
file_object.close()
4 爬取其他类型文件(视频)
爬取其他类型文件其实也是相同的,这里以视频文件为例
# 我们这里首先使用一些网页工具将视频转化为.mp4的格式
# https://xbeibeix.com/api/bilibili/#
# 例如小翔哥的视频
import requests
res = requests.get(
url = "https://cn-gdfs-dx-bcache-24.bilivideo.com/upgcxcode/48/10/429511048/429511048-1-208.mp4?e=ig8euxZM2rNcNbhjnWdVhwdlhzTHhwdVhoNvNC8BqJIzNbfq9rVEuxTEnE8L5F6VnEsSTx0vkX8fqJeYTj_lta53NCM=&uipk=5&nbs=1&deadline=1638972330&gen=playurlv2&os=bcache&oi=242540163&trid=0000120a50459f6b47cf9badf704f8b54b44T&platform=html5&upsig=e72b57331d55a3178f0e77aa3a9e4a41&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&cdnid=60924&mid=0&bvc=vod&nettype=0&bw=369151&orderid=0,1&logo=80000000",
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
)
with open("小翔哥.mp4",mode='wb') as f:
f.write(res.content)
本文来自博客园,作者:kinghtxg,转载请注明原文链接:https://www.cnblogs.com/kinghtxg/articles/17158035.html

