

Kafka - 07Broker管理
一、LEO/HW/ISR
1.1 概念
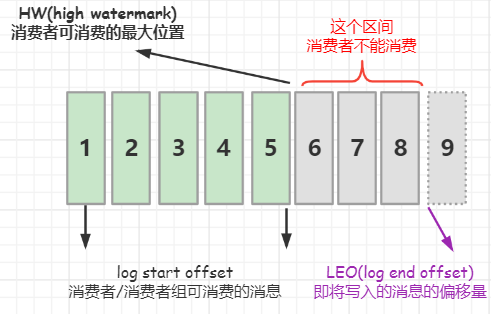
- LEO(log end offset): 即将写入的消息的偏移量
- Kafka里,leader partition 和 follower partition 都称作副本(replica)。
- 每次partition收到一条消息,都会更新自己的LEO, LEO是最新的offset + 1。
- HW(high watermark): 消费者可以消费的最大位置。
- follower和leader的LEO同步了,HW就会更新。
- HW之前的数据对消费者是可见的,消息属于commit状态。
- HW之后的消息消费者不可见。
- ISR: 与Leader 保持同步的follower集合,包括leader
- AR: 分区的所有副本
1.2 LEO及HW更新

二、Controller管理集群
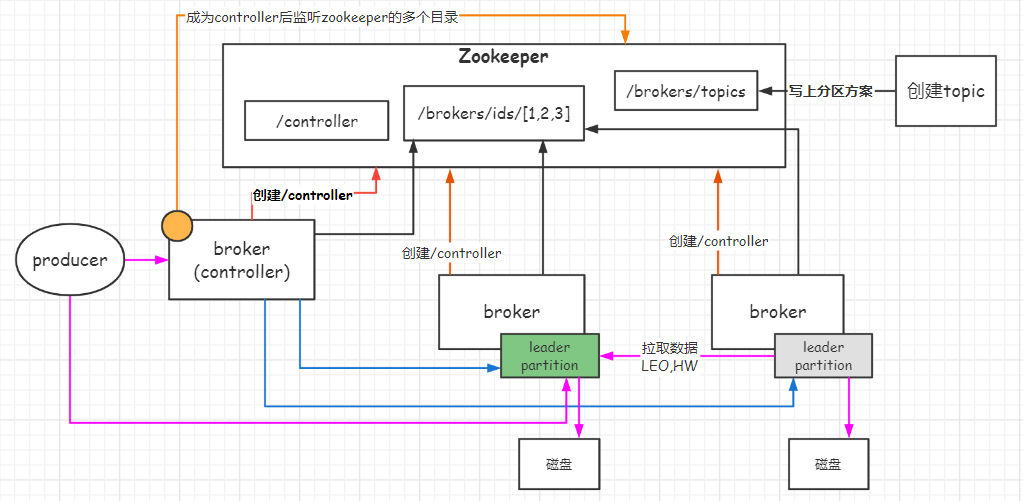
2.1 Controller选举
- Controller主要作用是在Zookeeper帮助下管理和协调整个Kafka集群。
- Controller与Zookeeper进行交互,获取与更新集群中的元数据信息。
- 其他broker不与zookeeper进行通信,而是与Controller交互并同步Controller中的元数据。
- Controller:Kafka节点里面的一个主节点。借助zookeeper进行选举。
- 竞争 controller, 在zookeeper中 创建 /controller,第一个成功的broker被指定为Controller。
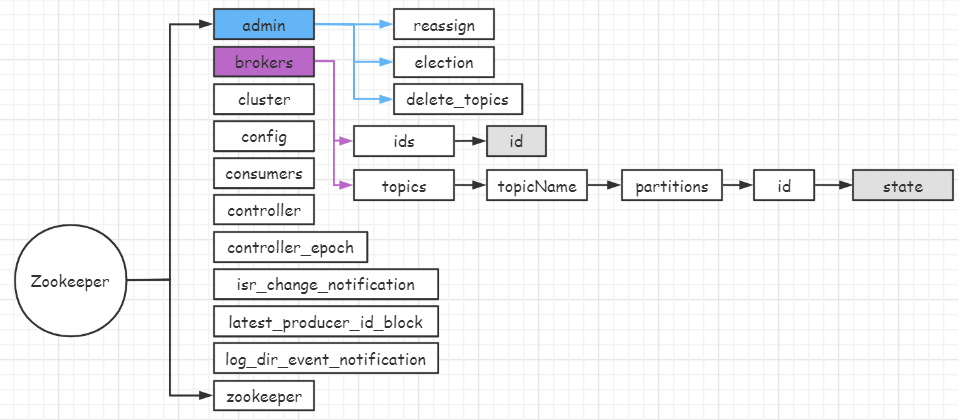
2.2 controller作用及元数据内容
- /broker/ids/ 用来感知broker上下线
- /broker/topics/ 创建主题,创建主题的命令,提供的参数,ZK地址。
- /admin: 保存管理脚本输出结果, /reassign_partitions: 分区重分配
- /cluster: 保存集群信息,如ID, 版本号
- /controller_epoch: 区分无效请求
- /config: 保存各种资源定制化配置信息
- /isr_change_notification: 发生变化的ISR, 控制器监听该节点下子节点变更
Controller主要作用:
- 主题管理: 创建、删除topic,增加topic分区等操作都是由控制器执行。
- 分区重分配: 执行reassign脚本对topic分区重分配。
- 一个broker异常退出,控制器检查此broker是否有分区的leader副本,有则控制器遍历其他副本,选出新leader,更新ISR集合。
- 一个broker加入集群,通过broker id去判断此节点是否有现有分区的副本,有则从分区副本中去同步数据。
- Preferred leader选举: broker进出集群导致leader副本不均衡。需要Preferred leader选举。
- 集群成员管理: 监控broker的新增、主动关闭、宕机,进行执行操作。基于Zookeeper的ZNode模型和Watch机制,监听/brokers/id下临时节点。
- broker加入,在/brokers/id/下创建znode节点,zookeeper通过watch机制推送消息给控制器。控制器进行后续操作。
- broker宕机或退出,/brokers/id的临时节点被自动删除,控制器收到推送的消息。
- 元数据服务
- 控制器保存最全的集群元数据信息,其他broker定期接收控制器发来的元数据更新请求,更新自己内存中的缓存数据。
2.3 controller重新选举
- 单点失效,故障转移,Failover。
- 控制器宕机后,Zookeeper通过watch机制感知并删除/controller临时节点。其他存活broker重新竞争。
- 新的控制器从Zookeeper中读取集群元数据信息,并初始化到自己的缓存中。
[zk: localhost:2181(CONNECTED) 14] get /controller
{"version":1,"brokerid":1,"timestamp":"1657337825455"}
[zk: localhost:2181(CONNECTED) 15] ls /controller
[]
.....
[zk: localhost:2181(CONNECTED) 25] get /controller
{"version":1,"brokerid":1,"timestamp":"1657337825455"}
### 节点1 宕机后,重新选择,节点4成为新Crontroller
[zk: localhost:2181(CONNECTED) 26] get /controller
{"version":1,"brokerid":4,"timestamp":"1657367237188"}
脑裂问题
- 原Controller节点短暂性故障(如FGC), 并不知道自己已经被取代了,此时集群会出现两台Controller。
- 原Controller进入长时间GC暂停,Zookeeper会话超时,注册的/controller被删除,重新选举。
- 剩余的broker组成新的集群,与新Controller进行交互元数据。
- 新老Controller可能发出具有冲突的命令,需要一种方法区分谁是当前最新的Controller。
- 使用epoch number(纪元编号,隔离令牌)来完成。单调递增的数字,发生一次选举加1。
- broker如果收到由controller发出的包含较小epoch number的消息,就忽略。
2.4 broker 上 leader partition 过多
- 创建topic时, 分区是自动分配和后续动态调整的。
- Kafka会自动把leader partition 均匀分散在各个机器上,保证每台机器的读写吞吐量是均匀的。
- 如果某台broker宕机,会导致 leader partition集中在少数几台broker上, 读写请求压力过高。
- 宕机的broker重启后都是 follower partition,读写请求较少。
- auto.leader.rebalance.enable: 开启leader partition动态平衡, 默认为 true。
- leader.imbalance.check.interval.seconds: 每隔300秒检查leader负载是否平衡。
- leader.imbalance.per.broker.precentage: 每台broker允许的不平衡的leader的比率。超过这个值,控制器触发leader的平衡。
2.5 创建或删除topic 底层流程
- 在zookeeper的/brokers/topics节点下创建一个新的节点,如/brokers/topics/ttopic
- 然后会触发Controller的监听程序
- Kafka Controller负责topic的创建,并更新metadata cache。
三、 延时任务
3.1 延时调度任务
第一类延时任务:
- producer的 acks=-1, 必须等待 ISR 列表中副本都写入完成才返回响应。
- 有一个超时时间 request.timeout.ms,默认是30秒。
- 在写入一条数据到leader磁盘后,开启一个延时任务,放到DelayedOperationPurgatory(延时管理器)中。
- 假如在30秒之前所有follower副本都写入数据到磁盘中,延时任务被自动触发苏醒,返回响应给客户端。
- 到达30秒后,没有完成写入,直接超时返回异常。
第二类延时任务:
- follower 向leader拉取消息时, 发现是空的,则会创建一个延时拉取任务。
- 延时时间到期后,就给follower返回一个空数据,然后follower再次发送请求读取消息。
- 如果延时过程中(延时时间未到期),leader写入了消息,任务会自动苏醒,自动执行拉取任务。
海量的延时任务,需要调度。
3.2 时间轮机制
- Kafka 内部有很多延时任务,没有基于JDK Timer来实现, Timer 插入和删除任务的时间复杂度是O(nlogn)。
- 基于自己实现的时间轮,延时任务 插入和删除的时间复杂度是O(1)。
时间轮: 数组
- tickMs: 时间轮间隔 1ms
- wheelSize: 时间轮大小 20
- interval: tickMs * wheelSize, 一个时间轮的总时间跨度。20ms。
- currentTime: 当前时间指针。
- 因为时间轮是数组,获取数据 靠index,时间复杂度是O(1)。
- 数组某个位置上对应的任务, 用的是双向链表存储的,往双向链表插入和删除任务,时间复杂度是O(1)
多层级时间轮
- 第一层的时间轮: 1ms * 20
- 第二层的时间轮: 20ms * 20
- 第三层的时间轮: 400ms * 20


