


Kafka - 06消费者消费消息解析
一、Kafka消费者读取数据流程
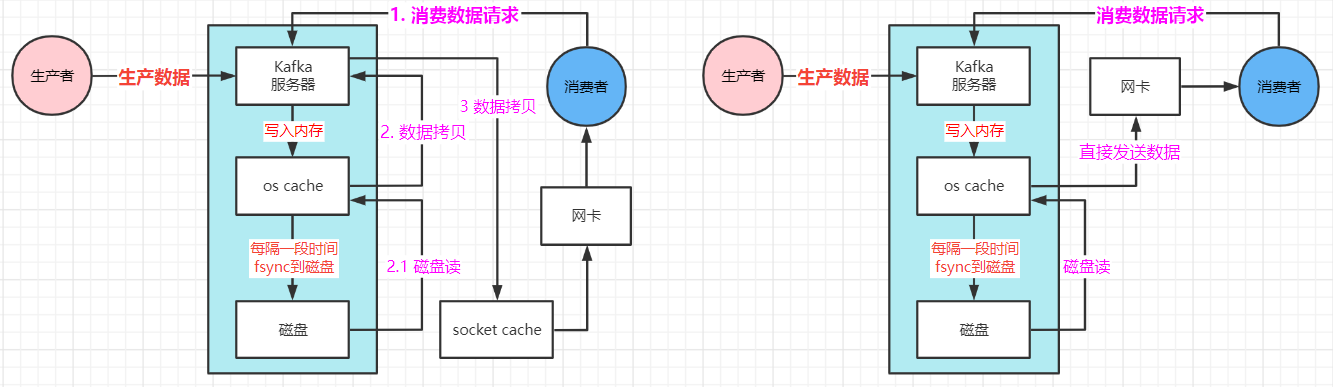
1.1 传统流程
- 消费者发送请求给Kafka服务器
- Kafka服务器在os cache缓存读取数据(缓存没有再去磁盘读取数据)
- 从磁盘读取数据到os cache缓存中
- os cache复制数据到Kafka应用程序中
- Kafka将数据(复制)发送到socket cache中
- socket cache通过网卡传输给消费者
1.2 Kafka零拷贝机制 -- linux sendfile技术
- 消费者发送请求给kafka服务
- Kafka服务去os cache缓存读取数据(缓存没有就去磁盘读取数据)
- 从磁盘读取了数据到os cache缓存中
- os cache直接将数据发送给网卡
- 通过网卡将数据传输给消费者
二、消费者组
2.1 消费者组
- topic 的一个分区只能被消费者组下的一个consumer消费。分区可以被不同的消费者组消费。
- 一个consumer可以消费多个分区,也可以不消费分区。
- 实现广播效果,使用不同的group id 去消费即可。
- 消费者组内的消费者down掉,会自动把分区交给其他消费者。重启后,会再把一些分区重新交给消费者处理。
2.2 消费者代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | public class ConsumerTest { public static void main(String[] args) { String topicName = "ttopic2"; String groupId = "consumerTest"; Properties props = new Properties(); props.put("bootstrap.servers","my-node51:9092,my-node52:9092,my-node53:9092"); props.put("group.id", groupId); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topicName)); try { while (true) { ConsumerRecords<String, String> records = consumer.poll(1000); for(ConsumerRecord<String, String> record: records) { System.out.println(record.offset() + "," + record.key() + "," + record.value()); } } } catch (Exception e) { e.printStackTrace(); } }} |
1 2 3 4 5 6 | [root@my-node52 kafka-2.6.0]# kafka-console-producer.sh --bootstrap-server 192.168.6.51:9092 --topic ttopic2>123>1234--- 输出结果0,null,1230,null,1234 |
2.3 偏移量管理
- 每个 consumer内存里保存对每个topic的每个分区的消费offset,定期提交offset。
- 老版本是写入zookeeper, zookeeper是做分布式协调的,轻量级的元数据存储,不适合高并发读写及存储。
- 新版本提交offset发送给Kafka内部topic: __consumer_offsets。
- 提交 key是group.id + topic + 分区号, value是 当前消费offset的值 + 1。
- 每隔一段时间, Kafka对topic进行合并(compact),每个group.id + topic + 分区号只保留最新数据。
- __consumer_offsets 可能接收高并发的请求,默认分区是50。
偏移量监控工具
- KafkaManager: 修改kafka-run-class.sh 增加 JMX_PORT=9988; 重启Kafka进程
2.4 消费异常感知
- hearbeat.interval.ms
- consumer 心跳时间间隔, 与coordinator 保持心跳,感知consumer是否故障.
- 如果某个consumer故障,通过心跳下发rebalance指令给其他consumer,进行rebalance操作。
- session.timeout.ms
- Kafka 多长时间感知不到一个consumer,就认为故障了。默认是10秒。
- max.poll.interval.ms
- 如果两次poll操作之间超过最大间隔时间,认为consumer处理能力太弱,剔除消费者组。
三、消费者核心参数详解
- fetch.max.bytes
- 获取一条消息最大的字节数。默认是1M。
- Producer 发送一条消息的最大值,默认是10M。
- Broker 存储一条消息接受的最大值,默认是10M。
- max.poll.records
- 一次poll返回消息的最大条数,默认是500。
- connection.max.idle.ms
- consumer 跟 broker 的socket连接, 超过空闲时间,自动回收连接;下次消费重新建立socket。
- 建议设置为-1, 不进行回收。
- enable.auto.commit
- 开启自动提交偏移量
- auto.commit.interval.ms
- 每隔多久提交一次偏移量,默认值是5000。
- auto.offset.reset
- earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交时从头开始消费
- latest: 当各分区下有已提交的offset时,从提交的offset开始消费;无提交时从最新开始消费
- none: 当各分区下有已提交的offset时,从提交的offset开始消费;只要有一个分区无提交则抛出异常
四、Group Coordinator
4.1 消费者rebalance机制
- 消费者如何实现rebalance的? 根据coordinator实现。
- 每个 consumer group 都会选择一个broker作为自己的coordinator,
- 负责监控这个消费者组的各个消费者的心跳,以及判断是否宕机,然后开启rebalance等。
4.2 如何选择coordinator
- 首先对 group id 进行hash, 对 __consumer_offsets 的分区数量取模,默认是50。
- __consumer_offsets的分区数可以通过offsets.topic.num.partitions来设置。
- 找到分区后,分区所在的broker机器就是 coordinator机器。
- consumer group下的所有消费者都往这个分区去提交offset。
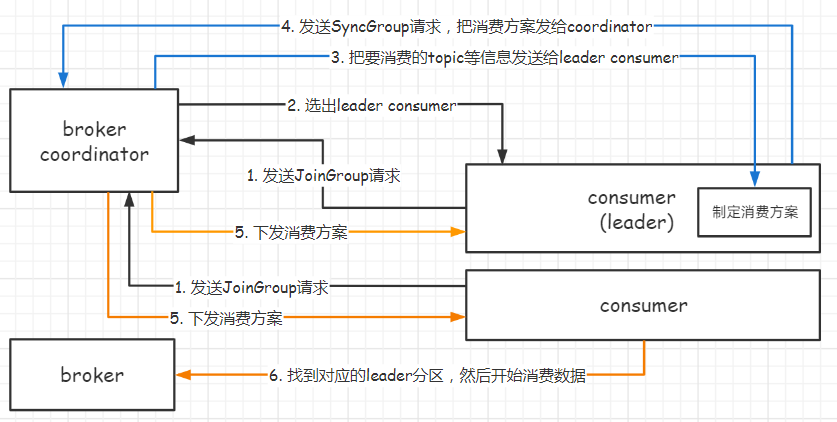
4.3 消费方案下发
- 每个 consumer 发送 JoinGroup 请求到 coordinator。
- 然后Coordinator从consumer group中选择一个consumer作为leader,
- 把consumer group信息发送给leader,
- leader负责制定消费方案,通过SyncGroup发给Coordinator
- Coordinator把消费方案下发给各个consumer,
- consumer 从指定的分区的leader broker开始进行socket连接及消费消息
4.4 rebalance 策略
- consumer group 靠 coordinator 实现 rebalance
- 三种rebalance策略: range、 round-robin、sticky
- 假设topic有12个分区,消费者组有三个消费者
- range策略: 按照partition的序号范围,默认策略
- 将同一个topic的分区按照序号排序,然后把消费者按照字母顺序排序。
- 用topic的partition分区数量除以消费者线程的数量决定每个消费者线程消费几个分区。
- 如果除不尽, 前面几个消费者线程会多消费一个分区。
- p0-3 consumer1
- p4-7 consumer2
- p8-11 consumer3
- 如果 consumer1宕机, p0-5 分配给consumer2, p6-11分配给consumer3;原本在consumer2的6和7分区被分配到了consumer3上。
- round-robin策略: 轮询策略
- consumer1: 0,3,6,9
- consumer2: 1,4,7,10
- consumer3: 2,5,8,11
- sticky 策略: 尽可能保证在rebalance时,让原本属于consumer的分区不变动,把多余的分区均匀分配。
- consumer1: 0-3; consumer2: 4-7; consumer3: 8-11。
- consumer1 宕机, consumer2: 4-7, 0,1 consumer3: 8-11, 2,3


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!