
Kafka - 01简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区(partition)、多副本(replica),基于zookeeper协调的分布式消息系统;
最大的特性是可以实时处理大量数据以满足各种需求场景,如基于hadoop的批处理系统、低延迟的实时系统、Storm/Spark流式处理引擎、web/nginx日志、访问日志、消息服务等等;
用scala语言编写; Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
一、消息系统
1.1 应用解耦
- 多应用间 通过消息队列对同一消息进行处理,避免调用接口失败导致整个过程失败。
- 不需要等待后面应用消费数据后的返回结果。
- 用户注册: 填写注册信息 -> 提交 -> 发送激活邮件|同步CRM|发优惠券。
1.2 异步处理
- 上下游没有强依赖的业务关系或针对单次请求不需要立刻处理的业务。
- 电商平台的秒杀活动流程,通过消息系统将不需要紧急处理的业务放在后面慢慢处理。相比串行处理,减少处理时间。
- 风险控制 -> 库存锁定 -> 生成订单 -> 短信通知 -> 更新数据
- 风险控制 -> 库存锁定 -> 消息系统 -> 生成订单 -> 短信通知 -> 更新数据
1.3 流量控制
- 网关接收到请求后,将请求放入到消息队列;后端服务从消息队列获取请求,完成后续处理流程。
- 广泛应用于秒杀或抢购活动中,避免流量过大导致应用系统挂掉。
二、Kafka使用场景
- Messaging
- Website Activity Tracking
- Metrics
- Log Aggregation
- Stream Processing
- Event Sourcing
- Commit Log
三、 Kafka 核心概念和组件
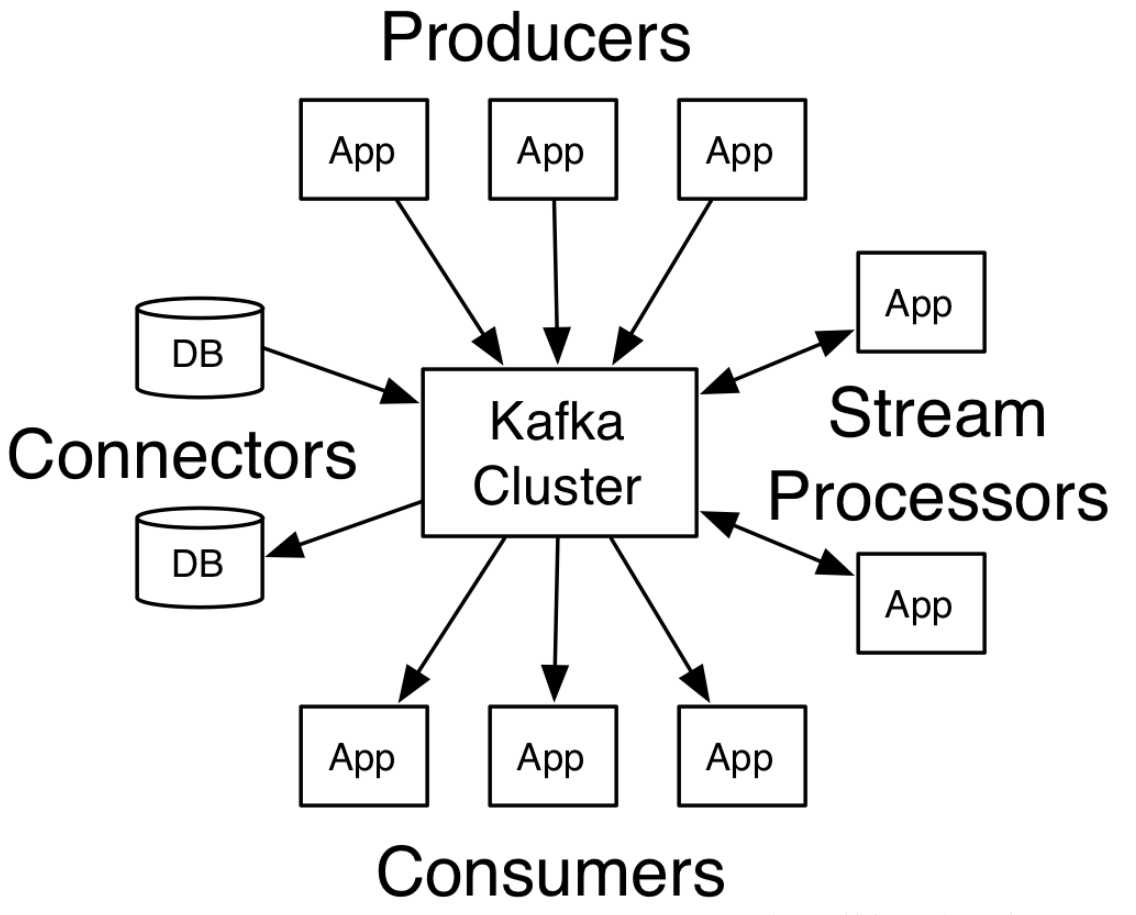
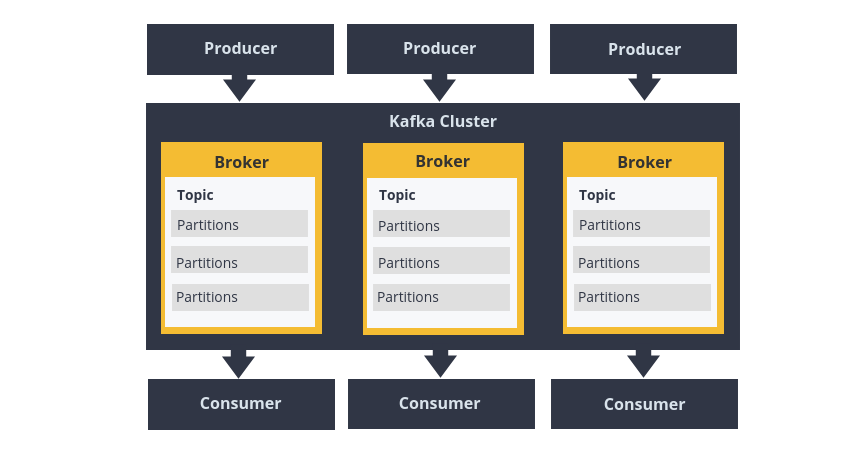
3.1 组件
- 生产者: 生产者 Producer 向 Kafka 发送消息(Push动作); Producer 往Kafka集群生成数据
- 消费者: 消费者 Consumer 监听 Kafka 接收消息(Pull动作); Consumer 从Kafka集群获取数据,处理数据、消费数据, 主动拉取数据
- Broker(Kafka集群): Kafka服务器, 负责消息存储和转发; 一个broker代表一个kafka节点,一个broker可以包含多个topic。
- Zookeeper: 管理kafka集群, 负责存储集群broker、topic、partition等meta数据存储,负责broker故障发现、partition leader选举、负载均衡等功能。
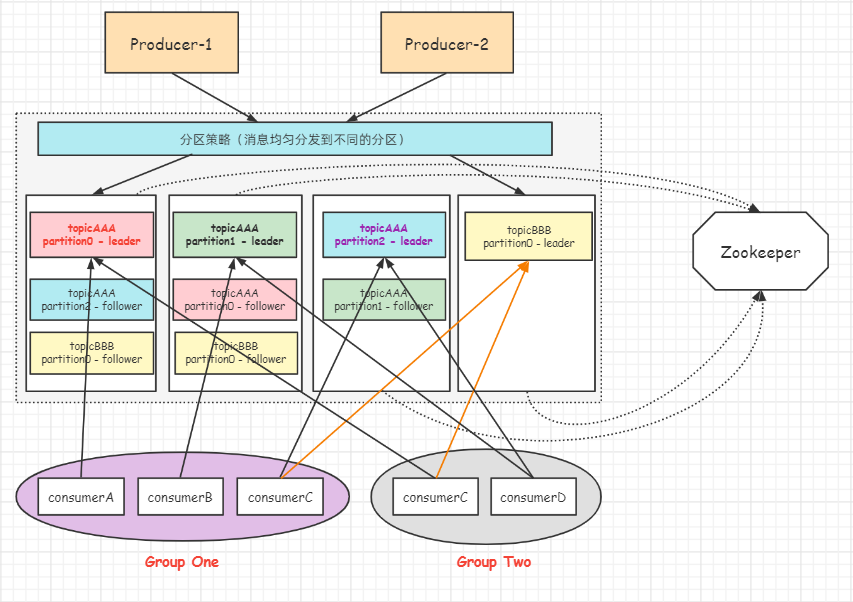
3.2 核心概念
- topic(主题): 消息类别,Kafka按照topic对消息进行分类。
- topic 是生产者发送消息的目标地址,是消费者的监听目标。一个Topic可以认为是一类消息。
- partition(分区): topic的分区,一个topic可以包含多个partition, topic消息保存在各个partition上。
- topic只是逻辑上的概念,partition在磁盘上体现为一个目录。
- 每个partition在存储层面是append log文件。每个分区都是一个有序、不可变的记录序列,不断附加到结构化的提交日志中。
- 生产者发送消息的时候,这条消息会被路由到此 topic 中的某一个 Partition。
- 分区中的每个记录都被分配了一个称为偏移的顺序ID号,它唯一地标识分区中的每个记录。
- 生产者发送消息时,默认是面向 topic 的,由 topic 决定放在哪个 Partition,默认使用轮询策略。
- Consumer Group(消费者组): 使用group id 区分消费者组。 每个Consumer必须属于一个group。
- 消费者消费topic数据,一个分区只能由组内的一个消费者消费,消费者组之间互不影响。
四、消息功能演化:MQ -> Kafka
- 通用MQ:
- 1对1传输 producer --push--> MQ(FIFO) --push--> consumer
- 如果有多个消费者需要消费消息,使用 广播方式。
- 如果消费者只需要消费部分数据, 可以将消息细分, 使用 topic routing 放到不同的topic。
- 新问题:
- 同一个队列,当出现新的消费者,就需要 使用广播 或 拷贝一个新的队列出来。 带来带宽或存储压力。
- 解决思路:
- 将因消费者导致复杂化问题交给消费者处理。
- 消息自取,消息永远在MQ中, 消费者随时获取。通过传递消息的offset参数。
- 无状态设计,将状态维护机制交给了消费者。
- Kafka设计
- 一个topic划分为多个partition, key hash 细分消息,提高并发处理性能。
- 消费者扩展问题: 一个消费者组消费一个或多个topic, 每个分区由其中一个消费者消费。
- 负载均衡,提供访问的并发性; 高可用性,做热备份。
- 海量数据访问
- 消费者通过offset来获取消息, 如果每个partition是一个完整的文件。存储困难,访问困难。
- 将partition分成 等大小 的一系列小文件(分段), 建立索引放在内存(稀疏索引)。
- 如果每条消费都建立索引,太占空间。
- 索引整个内存空间,稀疏化做法是分页,将内存划分为等大小的块(内存页)。索引内存页即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号