MapReduce编程之内连接
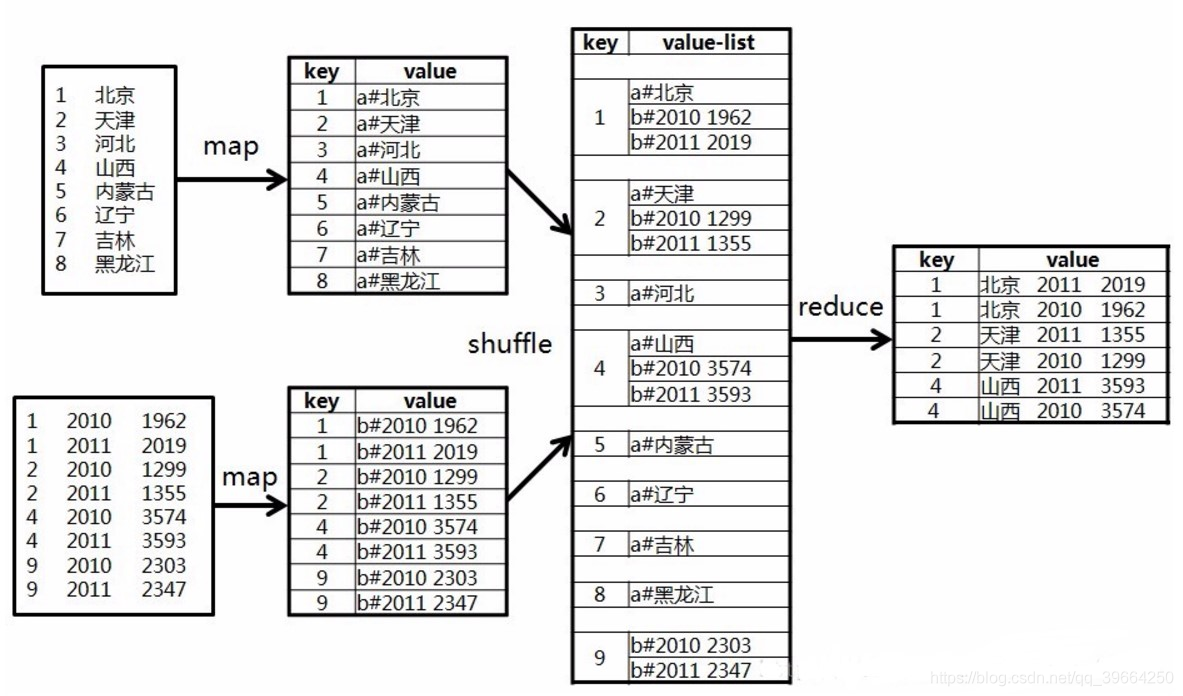
样例数据:
1 北京
2 天津
3 河北
4 山西
5 内蒙古
6 辽宁
7 吉林
8 黑龙江
1 2010 1962
1 2011 2019
2 2010 1299
2 2011 1355
4 2010 3574
4 2011 3593
9 2010 2303
9 2011 2347
现在我们需要做的事情是将这两份数据 进行 内连接查询 ,得到下面的结果集:
1 北京 2011 2019
1 北京 2010 1962
2 天津 2011 1355
2 天津 2010 1299
4 山西 2011 3593
4 山西 2010 3574
设计模型
在设计阶段的设想: 在map端对文件进行分别处理 ,把所有记录修改成 key, value 键值对形式,把 id 作为 key, value 值根据数据的来源进行分类 , 表1 的:“a#” + name ,表2 的:“b#” + score
在reduce阶段,shuffle功能把数据打乱了,我们根据之前的 value 值得前端 ab 来区分数据来源,分别放入两个 LinkedList ,然后做笛卡尔积,一条条存起来
代码实现:
public class MyInnerJoinDemo extends Configured implements Tool {
private static class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text>{
private String[] strs = null;
private LongWritable outkey = new LongWritable();
private Text outval = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context)
throws IOException, InterruptedException {
strs = value.toString().split("\t");
context.getCounter("Line Quality Statistics", "Line Quality Statistics").increment(1);
if (null != strs && (strs.length == 2 || strs.length == 3)) {
context.getCounter("Line Quality Statistics", "Nice Quality Statistics").increment(1);
if (strs.length == 2) {
outkey.set(Long.parseLong(strs[0].trim()));
outval.set("a" + "\001" + strs[1]);
context.write(outkey, outval);
} else {
outkey.set(Long.parseLong(strs[0].trim()));
outval.set("b" + "\001" + strs[1] + "\t" + strs[2]);
context.write(outkey, outval);
}
}
else {
context.getCounter("Line Quality Statistics", "Bad Quality Statistics").increment(1);
}
}
}
private static class MyReducer extends Reducer<LongWritable, Text, AreaWritable, NullWritable>{
private AreaWritable outkey = new AreaWritable();
// 存储单个Area字段值
private Integer aid;
private String aname;
private Integer year;
private Long count;
private String year_count;
// 存储values字符串
private String value = "";
// 存储year_count字符串
private List<String> list = null;
// 存储values字符串
private List<String> list2 = null;
// 存储分割过的value
private String[] strs = null;
@Override
protected void reduce(LongWritable key, Iterable<Text> values,
Reducer<LongWritable, Text, AreaWritable, NullWritable>.Context context) throws IOException, InterruptedException {
/*
* 由于迭代器共用一个对象,因此value输出的时候都会变成最后调用的那个对象
* value = IteratorUtils.toList(values.iterator()).toString();
* System.out.println(key + "\t" + value);
* 下面每行输出都是同一个元素
* [b2010 1962, b2010 1962, b2010 1962]
* [a天津, a天津, a天津]
* ……
* 因此需要在遍历迭代器的时候把每个元素存储到一个新的list集合中
*/
// 初始化变量
aid = (int)(key.get());
aname = "";
year = 0;
count = 0L;
list = new ArrayList<String>();
list2 = new ArrayList<String>();
for (Text text : values) {
list2.add(text.toString());
}
value = list2.toString().replace("[", "").replace("]", "");
// indexOf返回字符串在value中的位置,返回值>-1说明字符串中有指定字符
if (value.indexOf("a") > -1 && value.indexOf("b") > -1) {
strs = value.split(",");
for (String s : strs) {
if (s.trim().startsWith("a")) {
aname = s.split("\001")[1];
}
if (s.trim().startsWith("b")) {
year_count = s.split("\001")[1];
list.add(year_count);
}
}
}
// 循环list 最终输出
for (String s1 : list) {
year = Integer.parseInt(s1.split("\t")[0].trim());
count = Long.parseLong(s1.split("\t")[1].trim());
outkey.setAid(aid);
outkey.setAname(aname);
outkey.setYear(year);
outkey.setCount(count);
// 输出
context.write(outkey, NullWritable.get());
}
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = this.getConf();
Job job = Job.getInstance(conf, "MyJob_1");
job.setJarByClass(MyInnerJoinDemo.class);
job.setInputFormatClass(TextInputFormat.class);
// 配置Map和Reduce
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
// 设置Mapper输出
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
// 设置最终输出
job.setOutputKeyClass(AreaWritable.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 输入输出目录
Path in = new Path(args[0]);
Path out = new Path(args[1]);
// 设置目录
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
FileSystem fs = FileSystem.get(conf);
// 输出目录必须不存在 若存在 删除!
if (fs.exists(out)) {
fs.delete(out,true);
System.out.println(job.getJobName()+"的输出目录已删除!");
}
Long start = System.currentTimeMillis();
// 等待job执行结束
boolean con = job.waitForCompletion(true);
Long end = System.currentTimeMillis();
if (con) {
System.out.println("success!");
System.out.println("任务耗时:" + ((end - start)/1000) + "秒");
}else {
System.out.println("error!");
}
return 0;
}
public static void main(String[] args) {
try {
System.exit(ToolRunner.run(new MyInnerJoinDemo(), args));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号