hive 桶表的使用
对于每一个表或者分区来说,可以进一步组织成 桶 ,其实就是更细粒度的数据范围。
Bucket是对指定列进行 hash,然后根据hash值除以桶的个数进行求余,决定该条记录存放在哪个桶中。
公式:whichBucket = hash(columnValue) % numberOfBuckets
公式:要往哪个桶存 = hash(列值) % 桶的数量
hive桶表最大限度的保证了每个桶中的文件中的数据量大致相同,不会造成数据倾斜。
但说是不会造成数据倾斜,但这是在业务无关的情况下,只要有真实业务在,肯定会发生数据倾斜。
总结:桶表就是对一次进入表的数据进行文件级别的划分。
案例:多个国家的用户日志
--创建桶表的语法格式
CREATE EXTERNAL TABLE buckets_table(
col ....)
COMMENT 'This is the buckets_table table'
PARTITIONED BY (`dt` string)
CLUSTERED BY(col1) [SORTED BY(col2 [asc|desc])] INTO 2 BUCKETS
LOCATION '.....'
示例:
-- 创建外部表桶表
CREATE EXTERNAL TABLE user_install_status_buckets(
`aid` string,
`pkgname` string,
`uptime` bigint,
`type` int,
`country` string,
`gpcategory` string)
COMMENT 'This is the buckets_table table'
PARTITIONED BY (`dt` string)
CLUSTERED BY (country)
SORTED BY(uptime desc)
INTO 42 BUCKETS
LOCATION 'hdfs://ns1/user/mydir/hive/user_install_status_buckets';
--建partition 分区
alter table user_install_status_buckets add if not exists partition (dt='20141228') location '20141228' partition (dt='20141117') location '20141117';
在给分区插入数据的时候肯定有某些国家数据量大,某些少的情况
--给分区插入数据
insert overwrite table user_install_status_buckets partition(dt='20141228')
select
aid,pkgname,uptime,type,country,gpcategory
from user_install_status_orc
where dt='20141228';
insert overwrite table user_install_status_buckets partition(dt='20141117')
select
aid,pkgname,uptime,type,country,gpcategory
from user_install_status_orc
where dt='20141117';
桶中的数据文件:文件大小参差不齐,明显有数据倾斜现象
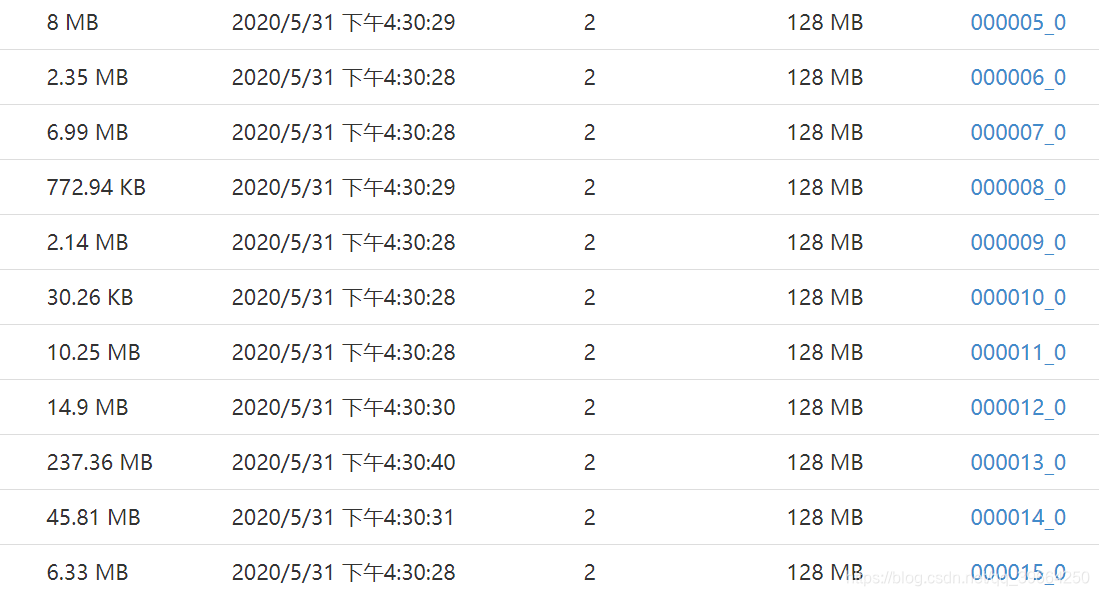
桶表抽样:
当数据量特别大时,对全体数据进行处理存在困难时,抽样就显得尤其重要了。
抽样可以从被抽取的数据中估计和推断出整体的特性,是科学实验、质量检验、社会调查普遍采用的一种经济有效的工作和研究方法。
桶表抽样的语法如下:table_sample: TABLESAMPLE (BUCKET x OUT OF y [ON colname])
当创建桶表的字段和抽样字段一致的时候,抽样时不扫描全表,直接输入指定的桶文件。
select * from user_install_status_buckets tablesample(bucket 11 out of 84 on country);
上面的语句指定抽取第11个桶的一半,但是如果第11个桶中没有第二个country,就会把所有记录全部抽取出来。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号