
浅了解c/c++头文件、链接、动态和静态链接库
一个或几个c文件从源文件到可执行文件大致经历步骤如下
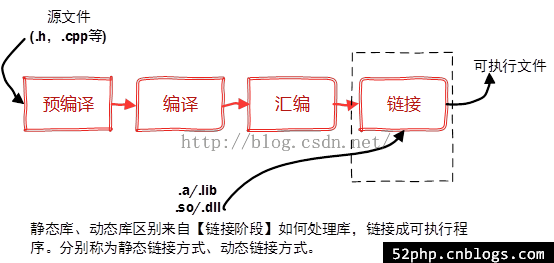
下面以具体例子说明一下各个阶段(本文用c++举例,事实上c/c++是一样的)
源文件
这是我用c++简单写的一个单链的实现(水平有限,算法爹轻喷ww),部分参考单链表的基本操作C++
一共有三个文件
head.h用于声明函数/变量/类。这里不得不说一下声明(declaration)和定义(definition)的区别。
注意这里提到了两个概念,一个是"定义",一个是"声明"。简单地说,"定义"就是把一个符号完完整整地描述出来:它是变量还是函数,返回什么类型,需要什么参数等等。而"声明"则只是声明这个符号的存在,即告诉编译器,这个符号是在其他文件中定义的,我这里先用着,你链接的时候再到别的地方去找找看它到底是什么吧。定义的时候要按 C++ 语法完整地定义一个符号(变量或者函数),而声明的时候就只需要写出这个符号的原型了。需要注意的是,一个符号,在整个程序中可以被声明多次,但却要且仅要被定义一次。试想,如果一个符号出现了两种不同的定义,编译器该听谁的?
也就是说.h文件通常只用于声明用到的函数和变量,在其他地方引用时只需include一下。这里就会有一个小问题,如果我们的头文件在很多地方被引用了,那就可能导致重复声明而编译报错。解决方法是
#ifndef xxx
#define xxx
// 函数/变量的声明
#endif
使用这样一个宏可以在第二次被引用的时候告诉编译器什么也别做。
完整的head.h如下,具体而言定义了Node类和List类
#ifndef LINKEDTABLE_HEAD_H
#define LINKEDTABLE_HEAD_H
class Node{
public:
int value;
Node* next;
Node(int value,Node* next);
};
class List{
private:
int length;
Node* head;
public:
List(Node*); //初始化
void insertHead(Node*); //头插法
void insertTail(Node*); //尾插法
Node* findByIndex(int); //根据索引查找节点,并返回节点的指针,注意0返回头节点
Node* findByValue(int); //根据值查找节点,并返回节点的指针
void deleteByIndex(int); //根据索引删除节点
Node* deleteByNode(Node*); //根据node指针删除节点
void deleteByValueOnce(int); //根据节点值删除第一个节点
void deleteByValueAll(int);//根据节点值删除所有节点
void editByIndex(int,int); //根据索引修改节点的值
void dump();
};
#endif //LINKEDTABLE_HEAD_H
这些函数/变量在声明之后,需要在一个地方实现。比如这里就是head.cpp(文件名不一定要是head)。
head.cpp
#include "head.h"
#include <iostream>
Node::Node(int value,Node* next){
this->value=value;
this->next=next;
}
List::List(Node* p) {
this->head=p;
this->length=1;
}
void List::insertHead(Node * p) {
p->next=this->head;
this->head=p;
this->length++;
}
void List::insertTail(Node* p){
Node* tail=this->findByIndex(this->length-1);
tail->next=p;
this->length++;
}
Node* List::findByIndex(int index) {
if(index>length-1||index<0){
std::cout<<"index error"<<std::endl;
return 0;
}
Node* p=this->head;
for(int cnt=0;cnt<index;cnt++){
p=p->next;
}
return p;
}
Node* List::findByValue(int value){
Node* p=this->head;
for(int i=0;i<this->length;i++){
if(p->value==value){
return p;
}
p=p->next;
}
std::cout<<"not found"<<std::endl;
return 0;
}
Node* List::deleteByNode(Node* p){
if(!p->next){
Node* newTail=this->findByIndex(this->length-2);
free(newTail->next);
newTail->next=0;
this->length--;
return newTail;
}
else if(p==this->head){
Node* tmp=this->head;
this->head=this->head->next;
free(tmp);
this->length--;
return this->head;
}
else{
p->value=p->value^p->next->value;
p->next->value=p->value^p->next->value;
p->value=p->value^p->next->value;
Node* tmp=p->next->next;
free(p->next);
p->next=tmp;
this->length--;
return p;
}
}
void List::deleteByIndex(int index){
if(index>length-1||index<0){
std::cout<<"index error"<<std::endl;
return;
}
if(this->length==1){
std::cout<<"You can't delete all nodes."<<std::endl;
return;
}
deleteByNode(findByIndex(index));
}
void List::deleteByValueOnce(int value){
Node* p=this->head;
for(bool goon;;){
if(p->value==value){
deleteByNode(p);
return;
}
if(!goon)break;
goon=p->next?true:false;
p=p->next;
}
std::cout<<"not found\n";
}
void List::deleteByValueAll(int value) {
int tmpLength=length;
Node* p=this->head;
int deleted=0;
for(bool goon=true;goon;){
bool equal=false;
goon=p->next?true:false;
if(p->value==value){
if(deleted+1==tmpLength){
puts("You can't delete all nodes.");
return;
}
p=deleteByNode(p);
equal=true;
deleted++;
}
p=equal?p:p->next;
}
if(deleted){
std::cout<<"deleted "<<deleted<<" node(s)"<<std::endl;
}
else{
std::cout<<"not found\n"<<std::endl;
}
}
void List::editByIndex(int index,int value){
if(index>length-1||index<0){
std::cout<<"index error"<<std::endl;
}
this->findByIndex(index)->value=value;
}
void List::dump(){
Node *p=this->head;
for(int i=0;i<this->length;i++){
printf("[%d] => [%d]\n",i,p->value);
p=p->next;
}
}
最后再写一个main.cpp,这是主程序的入口。这里用来和用户交互
main.cpp
#include <iostream>
#include "head.h"
using namespace std;
int main(){
puts("input head node's value:\n");
int headValue;
cin>>headValue;
List list(new Node(headValue,0));
while(1){
puts("1: insertHead\n2: insertTail\n3: findByIndex\n4: findByValue\n5: deleteByIndex\n6: deleteByValueOnce\n7. deleteByValueAll\n8. editByIndex\n9. dump\n10. exit");
int choice;
cin>>choice;
switch(choice){
case 1:{
cout<<"input value:\n";
int value;
cin>>value;
list.insertHead(new Node(value,0));
break;
}
case 2:{
cout<<"input value:\n";
int value;
cin>>value;
list.insertTail(new Node(value,0));
break;
}
case 3:{
cout<<"input index:\n";
int index;
cin>>index;
cout<<list.findByIndex(index)<<endl;
break;
}
case 4:{
cout<<"input value:\n";
int value;
cin>>value;
cout<<list.findByValue(value)<<endl;
break;
}
case 5:{
cout<<"input index:\n";
int index;
cin>>index;
list.deleteByIndex(index);
break;
}
case 6:{
cout<<"input value:\n";
int value;
cin>>value;
list.deleteByValueOnce(value);
break;
}
case 7:{
cout<<"input value:\n";
int value;
cin>>value;
list.deleteByValueAll(value);
break;
}
case 8:{
cout<<"input index value:\n";
int index,value;
cin>>index>>value;
list.editByIndex(index,value);
break;
}
case 9:{
list.dump();
break;
}
case 10:{
goto EXIT;
}
default:{
puts("?\n");
break;
}
}
}
EXIT:
return 0;
}
编译
这一阶段是将每一个cpp文件分别编译成Object File(也就是形如xxx.o的文件)
用g++编译如下
g++ -c head.cpp
g++ -c main.cpp
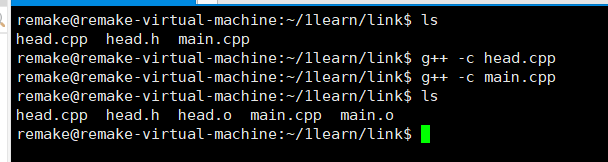
这两个.o文件是独立的。比如main.o里有head.o的函数/变量声明,但没有具体实现的内容。这时候,就需要链接器来把它们联系起来了
链接
此时执行g++ main.o head.o -o main
事实上是调用了GNU LD来完成的链接

链接器将我们的两个.o文件链接了起来,生成一个可执行文件main。由此编译的工作才完成。
动态链接库和静态链接库
注意这里是库而不是开发者自己写的工程。在上述链接阶段,我们可能还会导入一些系统库,如iostream。
静态链接库
静态链接是指把iostream这个库直接链接到可执行文件里(和刚刚的例子一样)
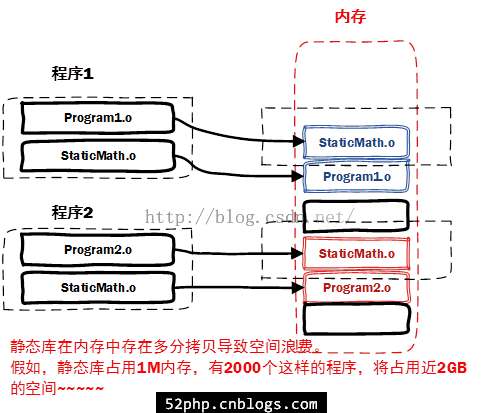
这样显然会造成内存的浪费
动态链接库
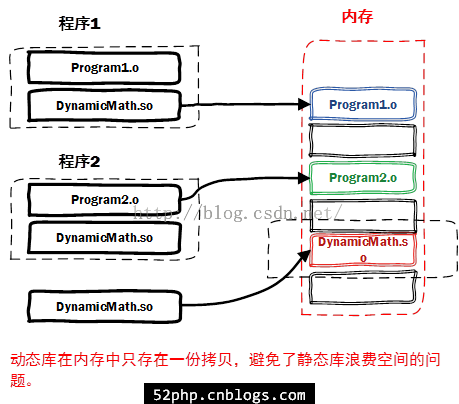
可以通过ldd命令查看可执行文件调用的库和在内存中的位置
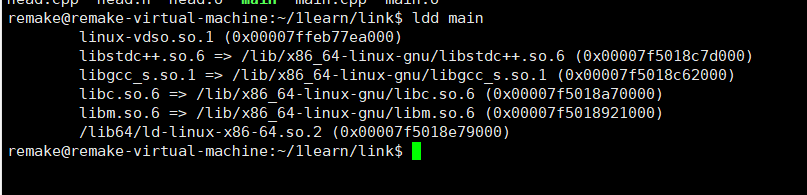
注意到这一行
/lib64/ld-linux-x86-64.so.2 (0x00007f5018e79000)
这是ld链接器的运行时组件。这是被写死在elf文件中的。事实上当程序被加载到内存时,这才是真正的入口。这个ld库会设置程序怎么样加载动态链接库。
在做pwn题的时候,有时候我们需要手动切换libc,这时我们就可以准备需要的ld库和libc库,然后把目标程序elf的ld库改成自己的,然后再把libc也改成自己的。具体过程可以参考
感觉不如IDE
当然上述只是为了学习编译过程,真正写项目的时候用clion就大大方便。只需在CMakeList.txt把
add_executable(LinkedTable main.cpp)
改成
add_executable(LinkedTable main.cpp head.cpp)
然后编译即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号