KingbaseES V8R3 集群运维案例--TEST库被删除导致主备切换失败
案例说明:
在KingbaseES V8R3集群中,kingbasecluster进程连接test库访问,监控后台数据库服务状态;如果删除test数据库,导致后台数据库服务访问失败,在集群主备切换时,无法访问后台数据库服务,导致切换失败。修改集群HAmodule.conf配置文件相关参数后,可以解决集群test库被删除导致主备切换失败问题。
适用版本:
KingbaseES V8R3
一、查看集群访问test库配置
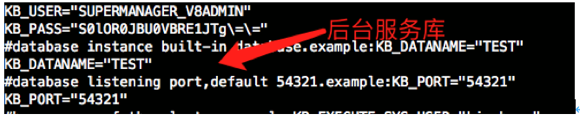
[kingbase@node1 etc]$ cat HAmodule.conf |grep -i test
#database instance built-in database.example:KB_DATANAME="TEST"
KB_DATANAME="TEST"
二、查看kingbase_monitor.sh访问test库信息
=可以从kingbase_monitor.sh start的启动过程,看到对test库的访问=
[kingbase@node1 bin]$ sh -x kingbase_monitor.sh restart > ~/kmon.txt
[kingbase@node1 ~]$ cat kmon.txt |grep -i test
+ param='KB_DATANAME="TEST"'
+ paramValue='"TEST"'
+ '[' -z '"TEST"' ']'
+ eval 'KB_DATANAME="TEST"'
++ KB_DATANAME=TEST
++ /home/kingbase/cluster/kha/db/bin/ksql 'host=192.168.7.248 port=54321 user=SUPERMANAGER_V8ADMIN password=XXXXXX dbname=TEST connect_timeout=10' -Aqtc 'select count(*)=1 from sys_stat_replication;'
++ /home/kingbase/cluster/kha/db/bin/ksql 'host=192.168.7.248 port=54321 user=SUPERMANAGER_V8ADMIN password=XXXXXX dbname=TEST connect_timeout=10' -Aqtc 'select sys_xlog_location_diff(sys_current_xlog_flush_location(), write_location)<=16777216 from sys_stat_replication;'

二、集群删除test库测试(主库)
# 查看database cluster
prod=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+--------+----------+-------------+-------------+--------------------
prod | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SAMPLES | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SECURITY | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
TEMPLATE0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE2 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/system +
| | | | | system=CTcb/system
TEST | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(7 rows)
# 主库判断
prod=# select sys_is_in_recovery();
sys_is_in_recovery
--------------------
f
(1 row)
# 查看流复制状态
prod=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
-------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+--
25795 | 10 | system | node243 | 192.168.7.243 | | 45418 | 2021-03-01 12:49:12.263710+08 | | s
treaming | 0/E0001B0 | 0/E0001B0 | 0/E0001B0 | 0/E000178 | 0 | async
(1 row)
# 主库删除test库:
prod=# drop database test;
DROP DATABASE
prod=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+--------+----------+-------------+-------------+--------------------
prod | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SAMPLES | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SECURITY | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
TEMPLATE0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE2 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/system +
| | | | | system=CTcb/system
(6 rows)
# 备库查看:
[kingbase@node3 bin]$ ./ksql -U system -W 123456 prod
ksql (V008R003C002B0270)
Type "help" for help.
prod=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+--------+----------+-------------+-------------+--------------------
prod | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SAMPLES | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
SECURITY | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
TEMPLATE0 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE1 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/system +
| | | | | system=CTcb/system
TEMPLATE2 | system | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =Tc/system +
| | | | | system=CTcb/system
(6 rows)
三、主备failover切换测试
1)关闭主库数据库服务
[kingbase@node1 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down....... done
server stopped
2)查看日志
备库cluster.log:(从日志可以获知,备库访问主库后台数据库服务失败,已经发起了failover的切换)
......
2021-03-01 12:41:16: pid 14431: LOG: health checking retry count 1
2021-03-01 12:41:16: pid 14431: LOG: failed to connect to kingbase server on "192.168.7.248:54321", getsockopt() detected error "Connection refused"
2021-03-01 12:41:16: pid 14431: ERROR: failed to make persistent db connection
2021-03-01 12:41:16: pid 14431: DETAIL: connection to host:"192.168.7.248:54321" failed
2021-03-01 12:41:18: pid 14644: LOG: watchdog checking if kingbasecluster is alive using heartbeat
2021-03-01 12:41:18: pid 14644: DETAIL: the last heartbeat from "192.168.7.248:9999" received 0 seconds ago
......
2021-03-01 12:41:22: pid 14473: LOG: received the failover command lock request from local kingbasecluster on IPC interface
2021-03-01 12:41:22: pid 14473: LOG: local kingbasecluster node "192.168.7.243:9999 Linux node3" is requesting to become a lock holder for failover ID: 69
2021-03-01 12:41:22: pid 14473: LOG: local kingbasecluster node "192.168.7.243:9999 Linux node3" is the lock holder
2021-03-01 12:41:22: pid 14431: LOG: starting degeneration. shutdown host 192.168.7.248(54321)
2021-03-01 12:41:22: pid 14431: LOG: Restart all children
2021-03-01 12:41:22: pid 14431: LOG: execute command: /home/kingbase/cluster/kha/kingbasecluster/bin/failover_stream.sh 192.168.7.243 1 1 192.168.7.248 192.168.7.248 0 0 /home/kingbase/cluster/kha/db/data
......
3)查看备库数据库服务(切换失败)
=备库数据库服务仍然启动recovery,还是在备库状态=
[kingbase@node3 log]$ ps -ef |grep kingbase
kingbase 13764 1 0 12:31 ? 00:00:01 /home/kingbase/cluster/kha/db/bin/kingbase -D /home/kingbase/cluster/kha/db/data
kingbase 13781 13764 0 12:31 ? 00:00:00 kingbase: logger process
kingbase 13782 13764 0 12:31 ? 00:00:00 kingbase: startup process recovering 00000001000000000000000F
kingbase 13786 13764 0 12:31 ? 00:00:00 kingbase: checkpointer process
kingbase 13787 13764 0 12:31 ? 00:00:00 kingbase: writer process
kingbase 13788 13764 0 12:31 ? 00:00:00 kingbase: stats collector process
.......
查看备库failover.log:
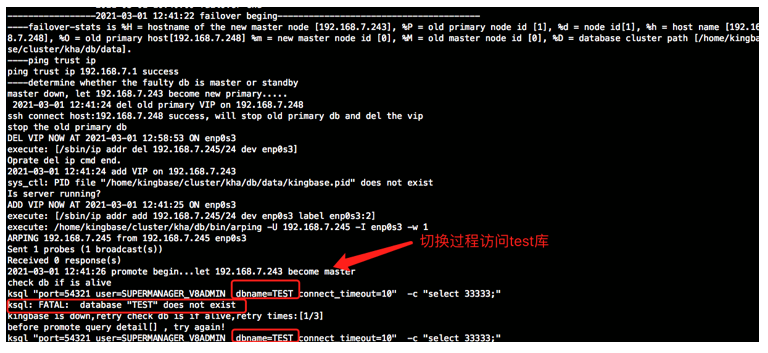
=== 有以下日志信息获知,在切换过程中需要访问test库,而test库被删除,导致访问失败,主备切换不成功===
-----------------2021-03-01 12:41:22 failover beging---------------------------------------
----failover-stats is %H = hostname of the new master node [192.168.7.243], %P = old primary node id [1], %d = node id[1], %h = host name [192.168.7.248], %O = old primary host[192.168.7.248] %m = new master node id [0], %M = old master node id [0], %D = database cluster path [/home/kingbase/cluster/kha/db/data].
----ping trust ip
ping trust ip 192.168.7.1 success
----determine whether the faulty db is master or standby
master down, let 192.168.7.243 become new primary.....
2021-03-01 12:41:24 del old primary VIP on 192.168.7.248
ssh connect host:192.168.7.248 success, will stop old primary db and del the vip
stop the old primary db
DEL VIP NOW AT 2021-03-01 12:58:53 ON enp0s3
execute: [/sbin/ip addr del 192.168.7.245/24 dev enp0s3]
Oprate del ip cmd end.
2021-03-01 12:41:24 add VIP on 192.168.7.243
sys_ctl: PID file "/home/kingbase/cluster/kha/db/data/kingbase.pid" does not exist
Is server running?
ADD VIP NOW AT 2021-03-01 12:41:25 ON enp0s3
execute: [/sbin/ip addr add 192.168.7.245/24 dev enp0s3 label enp0s3:2]
execute: /home/kingbase/cluster/kha/db/bin/arping -U 192.168.7.245 -I enp0s3 -w 1
ARPING 192.168.7.245 from 192.168.7.245 enp0s3
Sent 1 probes (1 broadcast(s))
Received 0 response(s)
2021-03-01 12:41:26 promote begin...let 192.168.7.243 become master
check db if is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
ksql: FATAL: database "TEST" does not exist
kingbase is down,retry check db is if alive,retry times:[1/3]
before promote query detail[] , try again!
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
ksql: FATAL: database "TEST" does not exist
kingbase is down,retry check db is if alive,retry times:[2/3]
before promote query detail[] , try again!
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEST connect_timeout=10" -c "select 33333;"
ksql: FATAL: database "TEST" does not exist
kingbase is down,retry check db is if alive,retry times:[3/3]
before promote query detail[] , try again!
kingbase is down,after retry 3 times ,cannot do promote, will exit
execute kingbase_promote.sh failed ,will exit script with error
"ssh -o StrictHostKeyChecking=no -l kingbase -T 192.168.7.243 "/home/kingbase/cluster/kha/db/bin/kingbase_promote.sh /home/kingbase/cluster/kha/db/bin SUPERMANAGER_V8ADMIN TEST 54321 /home/kingbase/cluster/kha/db/data 3 3 2>&1"" execute failed, error num=[66]
四、修改HAmodule.conf配置文件参数(所有节点)
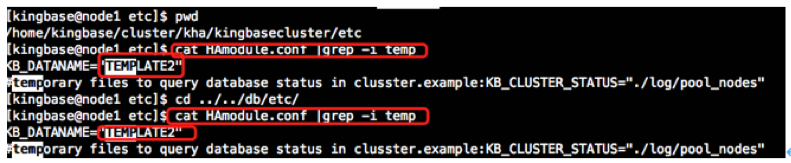
=将访问test库更改为template2库=
[kingbase@node1 etc]$ pwd
/home/kingbase/cluster/kha/kingbasecluster/etc
[kingbase@node1 etc]$ cat HAmodule.conf |grep -i temp
KB_DATANAME="TEMPLATE2"
[kingbase@node1 etc]$ cd ../../db/etc/
[kingbase@node1 etc]$ cat HAmodule.conf |grep -i temp
KB_DATANAME="TEMPLATE2"
五、重新启动集群
1)重启集群
[kingbase@node1 bin]$ ./kingbase_monitor.sh restart
-----------------------------------------------------------------------
2021-03-01 13:18:35 KingbaseES automation beging...
......................
all started..
...
now we check again
=======================================================================
| ip | program| [status]
[ 192.168.7.243]| [kingbasecluster]| [active]
[ 192.168.7.248]| [kingbasecluster]| [active]
[ 192.168.7.243]| [kingbase]| [active]
[ 192.168.7.248]| [kingbase]| [active]
=======================================================================
2)查看集群节点状态
[kingbase@node1 bin]$ ./ksql -U SYSTEM -W 123456 prod -p 9999
ksql (V008R003C002B0270)
Type "help" for help.
prod=# show pool_nodes;
node_id | hostname | port | status | lb_weight | role | select_cnt | load_balance_node | replication_delay
---------+---------------+-------+--------+-----------+---------+------------+-------------------+-------------------
0 | 192.168.7.243 | 54321 | up | 0.500000 | standby | 0 | true | 0
1 | 192.168.7.248 | 54321 | up | 0.500000 | primary | 0 | false | 0
(2 rows)
prod=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+---
--------+---------------+----------------+----------------+-----------------+---------------+------------
5539 | 10 | system | node243 | 192.168.7.243 | | 47872 | 2021-03-01 13:19:09.653137+08 | | st
reaming | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0 | async
(1 row)
[kingbase@node1 bin]$ ./ksql -U SYSTEM -W 123456 prod
ksql (V008R003C002B0270)
Type "help" for help.
prod=# select * from sys_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin |
state | sent_location | write_location | flush_location | replay_location | sync_priority | sync_state
------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+--------------+---
5539 | 10 | system | node243 | 192.168.7.243 | | 47872 | 2021-03-01 13:19:09.653137+08 | | st
reaming | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0/100000D0 | 0 | async
(1 row)
六、再次执行主备切换测试
1)停止主库数据库服务
[kingbase@node1 bin]$ ./sys_ctl stop -D ../data
waiting for server to shut down....... done
server stopped
2、查看备库数据库服务进程(切换成功)
[kingbase@node3 bin]$ ps -ef|grep kingbase
kingbase 22541 1 0 13:01 ? 00:00:00 /home/kingbase/cluster/kha/db/bin/kingbase -D /home/kingbase/cluster/kha/db/data
kingbase 22552 22541 0 13:01 ? 00:00:00 kingbase: logger process
kingbase 22563 22541 0 13:01 ? 00:00:00 kingbase: checkpointer process
kingbase 22564 22541 0 13:01 ? 00:00:00 kingbase: writer process
kingbase 22565 22541 0 13:01 ? 00:00:00 kingbase: stats collector process
root 23208 1 0 13:01 ? 00:00:00 ./kingbasecluster -n
root 23255 23208 0 13:01 ? 00:00:00 kingbasecluster: watchdog
root 23421 23208 0 13:02 ? 00:00:00 kingbasecluster: lifecheck
root 23423 23421 0 13:02 ? 00:00:00 kingbasecluster: heartbeat receiver
root 23424 23421 0 13:02 ? 00:00:00 kingbasecluster: heartbeat sender
kingbase 24571 22541 0 13:05 ? 00:00:00 kingbase: wal writer process
kingbase 24572 22541 0 13:05 ? 00:00:00 kingbase: autovacuum launcher process
kingbase 24573 22541 0 13:05 ? 00:00:00 kingbase: archiver process last was 00000002.history
kingbase 24574 22541 0 13:05 ? 00:00:00 kingbase: bgworker: syslogical supervisor
查看failover.log日志:
[kingbase@node3 log]$ tail -100 failover.log
-----------------2021-03-01 13:05:12 failover beging---------------------------------------
----failover-stats is %H = hostname of the new master node [192.168.7.243], %P = old primary node id [1], %d = node id[1], %h = host name [192.168.7.248], %O = old primary host[192.168.7.248] %m = new master node id [0], %M = old master node id [0], %D = database cluster path [/home/kingbase/cluster/kha/db/data].
----ping trust ip
ping trust ip 192.168.7.1 success
----determine whether the faulty db is master or standby
master down, let 192.168.7.243 become new primary.....
2021-03-01 13:05:14 del old primary VIP on 192.168.7.248
ssh connect host:192.168.7.248 success, will stop old primary db and del the vip
stop the old primary db
sys_ctl: PID file "/home/kingbase/cluster/kha/db/data/kingbase.pid" does not exist
Is server running?
DEL VIP NOW AT 2021-03-01 13:22:43 ON enp0s3
execute: [/sbin/ip addr del 192.168.7.245/24 dev enp0s3]
Oprate del ip cmd end.
2021-03-01 13:05:14 add VIP on 192.168.7.243
ADD VIP NOW AT 2021-03-01 13:05:15 ON enp0s3
execute: [/sbin/ip addr add 192.168.7.245/24 dev enp0s3 label enp0s3:2]
execute: /home/kingbase/cluster/kha/db/bin/arping -U 192.168.7.245 -I enp0s3 -w 1
ARPING 192.168.7.245 from 192.168.7.245 enp0s3
Sent 1 probes (1 broadcast(s))
Received 0 response(s)
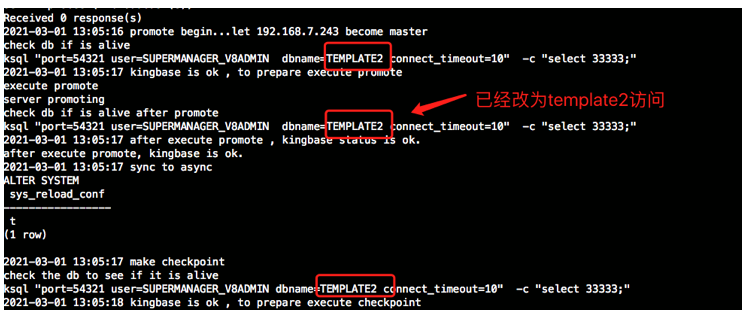
2021-03-01 13:05:16 promote begin...let 192.168.7.243 become master
check db if is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:17 kingbase is ok , to prepare execute promote
execute promote
server promoting
check db if is alive after promote
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:17 after execute promote , kingbase status is ok.
after execute promote, kingbase is ok.
2021-03-01 13:05:17 sync to async
ALTER SYSTEM
sys_reload_conf
-----------------
t
(1 row)
2021-03-01 13:05:17 make checkpoint
check the db to see if it is alive
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:18 kingbase is ok , to prepare execute checkpoint
execute checkpoint
CHECKPOINT
check the db to see if it is alive after execute checkpoint
ksql "port=54321 user=SUPERMANAGER_V8ADMIN dbname=TEMPLATE2 connect_timeout=10" -c "select 33333;"
2021-03-01 13:05:18 after execute checkpoint, kingbase is ok.
after execute checkpoint, kingbase is ok.
七、将原主库恢复为备库
1)在新主库上创建replication slots。
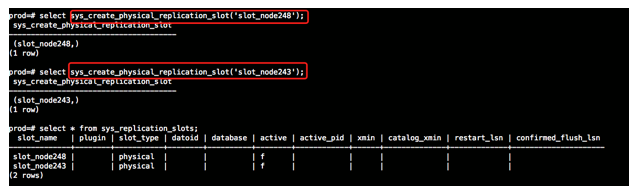
2)在原主库下创建recovery.conf文件后,sys_ctl手工启动数据库服务。

3)检查主备流复制状态。
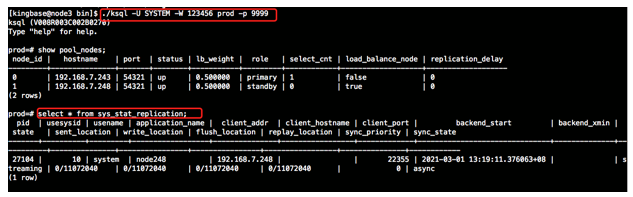
4)重新启动集群测试。
八、总结
对于KingbaseES V8R3集群的test库,多用于kingbasecluster和后台数据库服务的健康检查访问,请不要轻易删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号