OOM故障处理流程
一、OOM机制概述
Linux 内核有个机制叫OOM killer(Out Of Memory killer),该机制会监控那些占用内存过大,尤其是瞬间占用内存很快的进程,为防止内存耗尽而自动把该进程杀掉。
进程被Linux杀掉几个可能的原因:
- 内存泄露;
- 你的进程所需要的内存资源太大,系统无法满足;
- 也不一定全是你的问题,也有可能是同一主机的其他进程占用资源过多。
数据库OOM可能的故障现象:
- 数据库切换、服务中断 ……
- 通过数据库的log确认有进程被kill 9,然后通过同时间的系统日志确认
二、操作系统参与OOM
vm.overcommit_memory 接受三种值:
- 0 – 这是缺省值,它允许overcommit,但过于明目张胆的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存。
- 1 – 允许overcommit,对内存申请来者不拒。
- 2 – 禁止overcommit。
OOM参数影响系统的可分配内存。举例如下:操作系统内存 4G、swap 2G。以 kingbase 为例,shared_buffers 最大值:
- vm.overcommit_memory = 0 , shared_buffers 最大值为 6G
- vm.overcommit_memory = 1 , shared_buffers 最大值可以超过 6G,没有限制
- vm.overcommit_memory = 2 , 根据 (物理内存 + swap)* overcommit_ratio 确定可分配的内存,相当于可用内存不超过3G(所有进程可用的总内存,包括操作系统占用)。 默认 overcommit_ratio 50%。
如果vm.overcommit_memory = 2,正常不会发生OOM,只是在执行时报错。类似如下:
ERROR: out of memory DETAIL: Failed on request of size 16384 in memory context "ExecutorState".
三、OOM问题原因排查
1、查看操作系统日志
grep "Out of memory" /var/log/messages* Out of memory: Kill process <pid>(checkpoint) score 9 or sacrifice child checkpoint invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0
有的系统Log里会输出kill时的全部进程和每个进程的内存使用情况,用于确认当时的情况。
dmesg -T [Wed May 15 14:03:08 2019] Out of memory: Kill process 83446 (machine) score 250 or sacrifice child [Wed May 15 14:03:08 2019] Killed process 83446 (machine) total-vm:1920560kB, anon-rss:1177488kB, file-rss:1600kB
2、确认问题时间点的内存使用情况
Linux 系统默认每10分钟会收集系统状态,数据保存在/var/log/sa 目录。用户可以找到对应时间点的文件,运行sar命令,如:sar -r -f sa04 ,取得当时的系统状态信息。类似结果显示如下:
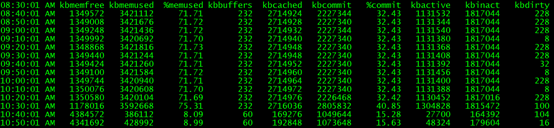
从上图可以看出,10:40 左右,系统可用内存不足,接着引发oom,之后可用内存恢复。
3、操作系统内存排查
查看系统内存使用情况:查看系统内存,关注可用内存情况:
free –g
cat /proc/meminfo
查看进程占用内存情况:
ps aux | sort -nrk5 | more 查看TOP VSZ ,表示请求的共享内存段的大小。这个并不表示实际分配的内存段,如shared_buffer = 1024M,但实际启动时并没有真正分配1024M内存(除非使用大页)。
ps aux | sort –nrk6 | more 查看每个进程实际占用的物理内存大小
注:当前时间点内存占用并不能反应OOM时间点实际内存占用情况,只能查看哪些进程是可能的影响因素。
清除linux系统的cache
# echo 3 > /proc/sys/vm/drop_caches
4、排查OOM时间点的运行业务
- 如有可能,逐个停止、排查业务,确认最占用系统内存的业务。
- 如果所有业务都停止后,还未释放内存,那可能是操作系统占用,需要排查操作系统问题。如以上例子,停止所有业务应用后,操作系统还占用大量内存,需要排查操作系统问题。
- 查看问题时间点,是否有crontab , job 等定时任务,确认是否有长时间运行的任务。
- 查看数据库sys_log,确认是否有耗时的SQL、大量量临时IO的SQL。
- 如果是 R6 版本,可以分析问题时间点kwr , ksh 报告。
5、查看数据库内存配置参数
查看数据库内存配置参数,计算主机可承受的负荷。样例数据如下:
|
主机内存: 256G SWAP: 22G shared_buffers: 100G max_connections: 4000 work_mem: 100M temp_buffers: 32M wal_buffers: 64M autovacuum_max_workers: 3 autovacuum_work_mem: -1 maintenance_work_mem: 10G current connections: 150 |
数据库占用内存计算公式:max_connections*work_mem + max_connections*temp_buffers +shared_buffers+wal_buffers+(autovacuum_max_workers * autovacuum_work_mem)+ maintenance_work_mem
数据库理论峰值 =4000 * 100M + 4000 * 32M + 100G + 64M + 10G = 620G
数据库当前值 = 150 * 100M + 150 * 32M + 100G + 64M + 10G = 130G
主机可承受连接数极值 = ( 250G - 100G - 10G ) / ( 100M + 32M ) = 1080
注意:这里的极限值其实是以每个连接占用132M 进行估算的,实际会话可能并不会占用这么多内存,且并不会有同时这么多并发排序操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号