
一、Simhash简介
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大。所以传统的Hash是无法在签名的维度上来衡量原内容的相似度,而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
SimHash算法是Google公司进行海量网页去重的高效算法,它通过将原始的文本映射为64位的二进制数字串,然后通过比较二进制数字串的差异进而来表示原始文本内容的差异。简单描述:simhash是一种快速判断两个文本是否相同(相似)的方法
二、SimHash流程描述
simhash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
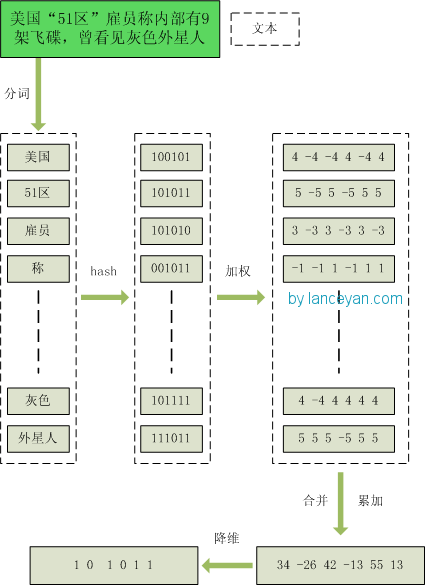
- 分词。把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
- hash。通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
- 加权。通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
- 合并。把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
- 降维。把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
三、SimHash文本相似比较
海明距离: 两个码字的对应比特取值不同的比特数称为这两个码字的海明距离。一个有效编码集中, 任意两个码字的海明距离的最小值称为该编码集的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为 3.
异或: 只有在两个比较的位不同时其结果是1 ,否则结果为 0
对每篇文档根据SimHash 算出签名后,再计算两个签名的海明距离(两个二进制异或后 1 的个数)即可。根据经验值,对 64 位的 SimHash ,海明距离在 3 以内的可以认为相似度比较高。
四. SimHash查询、存储和索引
如何在海量的样本库中查询与其海明距离在3以内的记录呢?
eg:数据库有2^34(差不多10亿)的simhash签名文档,现在给你一个新的文档,判断这个文档在不在现有数据库中,怎么判断?
最简单办法就是比较10亿次,算法复杂度o(n)这显然是不能接受的
解决方案:
将simhash串(64位)拆成4个相等长度的子串A1 A2 A3 A4,每个串长16位
A文档:A1 A2 A3 A4
B文档:B1 B2 B3 B3
根据抽屉原理
如果A文档和B文档的海明距离在3以内,那么A1-B1,A2-B2,A3-B3,A4-B4之间必然有一组完全相同
这个可以用反证法,如果每组都不同,那么A文档和B文档的海明距离一定>=4(每个分组的海明距离都>=1,4个分组加一起的海明距离>=4)
所以我们可以将数据库10亿+的simhash签名,按照每个simhash拆分成4个子组(eg:1111111100000000,0000000011111111,1010101000000000,0101010100000000)
A:seg 0-15:(1111111100000000)
B:seg 16-31:(0000000011111111)
C:seg 32-47:(1010101000000000)
D:seg 48-63:(0101010100000000)
这样我们就能得到40亿+的simhash seg组,每个seg组的记录数为2^16
如果数据是分布均匀的 那么每个seg组的每个seg(例如00000000 00000000)就会有2^32 / 2^16 = 262144条记录
对于新目标文档 查询流程为:
首先进行初筛:对于新目标文档 拆分成4个seg组后 和数据库做hash匹配 理论上就能找到 4×262144 = 100W+条单个seg相同的记录
但是只是单个seg相同 并不能保证这两个文档的海明距离就是3了 (可能一个seg相同 其他3个seg加一起的海明距离>>3)
然后进行准确筛选,将这100W个文档分别和目标文档比较海明距离,就可以准确判断该文档是否在数据库中存在了
这样10亿+的判断被优化成了100W+的判断

五. SimHash原理解析
从上面的流程我们可以看到,影响simHash值的主要因素就是文档的关键字段(权重高),如果两个文档的关键字段大致相同,那么这两个文档的simhash值大致也会相同
如果每个字段的权重都一样 会发生什么结果?
eg1:白娘子传奇 和 传奇白娘子 这两个文本的simhash就会一模一样,因为拆分出的词语 白娘子和传奇 计算后加一起的simhash都一样 跟顺序无关了 早加晚加最终的值都一致
eg2:simhash只能做相似判断 不能做包含判断,例如白娘子,白娘子传奇,白娘子传奇之法海你不懂爱 ,白娘子和白娘子传奇之法海你不懂爱的汉明距离就很长
白娘子-分词:[白娘子] 白娘子传奇-分词:[白娘子, 传奇]] 白娘子传奇之法海你不懂爱-分词:[白娘子, 传奇, 之, 法海, 你, 不, 懂, 爱] 白娘子-simhash:0110011000001110111110001111111111100001110000000000000000000000 白娘子传奇-simhash:1110011000011110111111101111111111111011110000000000000000000000 白娘子传奇之法海你不懂爱-simhash:0110011111111000110101101110111111111010010000000000000000000000 白娘子 和 白娘子传奇:hanming distance is 7 白娘子传奇 和 白娘子传奇之法海你不懂爱:hanming distance is 12 白娘子 和 白娘子传奇之法海你不懂爱:hanming distance is 17
其他算法:
- 百度的去重算法(直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。)
- shingle算法
- Minhash and LSH
本文参考
https://www.cnblogs.com/sddai/p/10088007.html
https://cloud.tencent.com/developer/article/1189493
https://cloud.tencent.com/developer/article/1043655
https://www.biaodianfu.com/simhash.html
simhash

