从微信朋友圈的评论可见性,谈因果一致性在分布式系统中的应用
概述
最近在读Designing Data-Intensive Application(简称DDIA)设计数据密集型应用,中文翻译, 整体感觉翻译得还是不错的。读到第九章《一致性与共识》的时候,里面有对因果一致性的阐述,结合之前微信朋友圈技术负责人在2015年ArchSummit全球架构师峰会(相关的分享资料可从如下地方获取)上关于朋友圈某一条状态的评论以及评论的回复,在跨数据中心(IDC)多副本间复制数据时,对因果一致性理论的应用,巧妙地解决了写冲突的问题。我们来看看因果一致性在实际业务开发中是如何应用的。
因果一致性的理解
下面我们先就DDIA的内容来看一个简单的问-答例子,并由此给因果关系下一个定义:
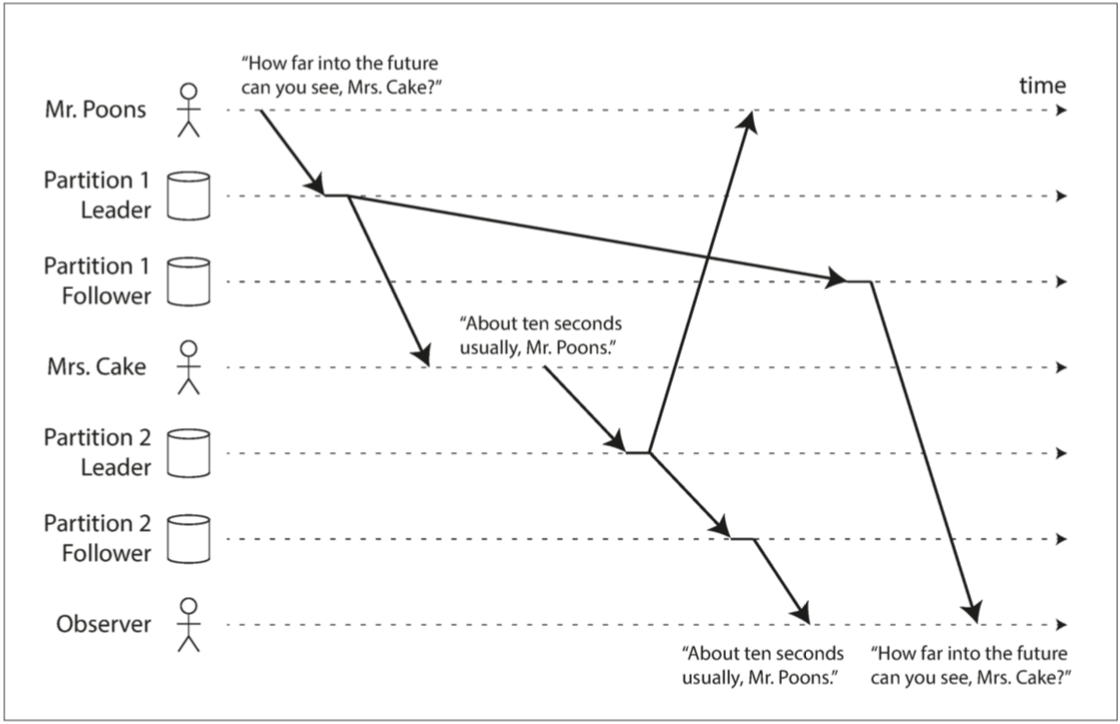
图1、问-答的因果关系
从上图1可知,一个对话的观察者(Observer)首先看到问题的答案“About ten seconds...”,然后才看到被回答的问题“How far into the ...”。这是令人困惑的,因为它违背了我们对因与果的直觉:如果一个问题被回答,显然问题本身得先在那里,因为给出答案的人必须已经看到这个问题,我们认为在问题和答案之间存在因果依赖。
考虑我们设计这样一个问答平台,当有一个用户去访问数据,例如刷新最新的所有问-答列表,就像刷新知乎推荐页面一样,他一定要先看到问题,然后再看到答案,否则就会给用户带来很大的困扰。因为只看到答案,而没有相应的问题是没有实际的意义的。
正如DDIA所提到的,因果关系对事件施加了一种顺序:因在果之前,消息发送在消息收取之前。而且就像现实生活中一样,一件事会顺序地导致另一件事发生:某个节点读取了一些数据然后写入一些结果,另一个节点读取其写入的内容,并依次写入一些其他内容等等。这些因果依赖的操作链定义了系统中的因果顺序,即什么在什么之前发生。从而我们也引出了分布式系统的因果一致性,如果一个系统服从因果关系所规定的顺序,我们说它是因果一致性的。
微信朋友圈的因果一致性
下面我们来看微信朋友圈某条状态的评论以及对评论的答复(也是评论)所构成的因果关系,以及微信是怎样通过保证不同数据中心间的因果一致性来保证一个用户在刷朋友圈的时候不会出现看到评论所对应的答复,却看不到答复对应的评论。要理解下文的前提是一定要实事前去学习前文提到的:微信朋友圈技术负责人陈明在2015年ArchSummit全球架构师峰会上的分享资料。
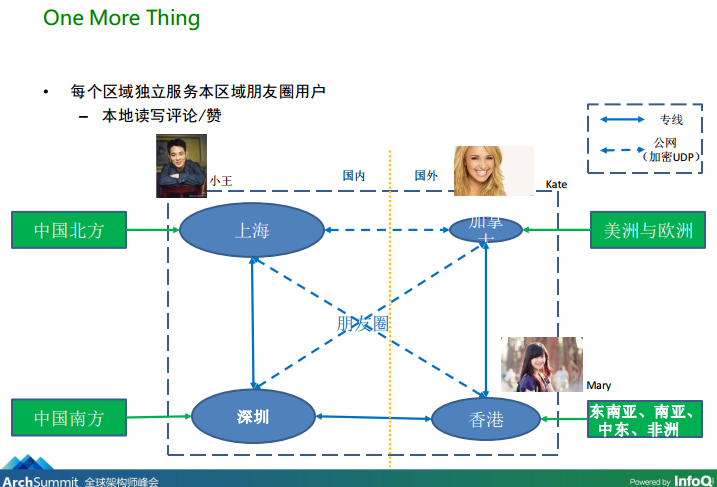
图2、微信分布在全球四地的数据中心
从图2微信分布在全球四地的数据中心,可知用户小王有两个朋友:Mary、Kate,分别在不同的区域下(数据中心),所以他们要看到彼此朋友圈的内容时,必须等到相关的数据在不同数据中心间的副本同步到用户所在的IDC完成之后才能看到。
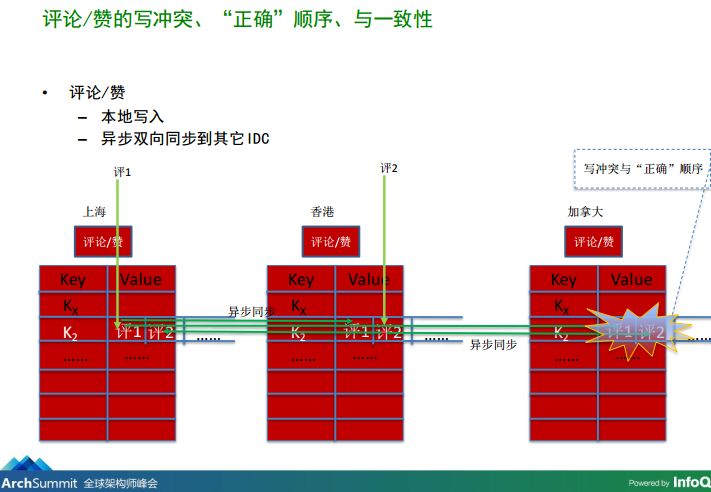
图3-1、数据在副本间同步时乱序

图3-2、数据在副本间同步时乱序
从上图3-1、3-2可知,由于网络在不同副本间复制数据时的延迟、中断等分布式系统中常见的场景,导致两条消息在同步到用户Kate(加拿大)所在数据中心上的副本时已经乱序了。即原先顺序是这样的:“Mary:这是哪里?”->“小王:Mary,这是梅里雪山”,然而Kate去数据库中查到的消息却是这样的顺序:“小王:Mary,这是梅里雪山”->“Mary:这是哪里?”,或者中间的某个时刻只能查询到“小王:Mary,这是梅里雪山”这一条消息,你说Kate会不会懵逼。
为了解决这个问题,微信是怎样来处理的呢,且看下面分析。
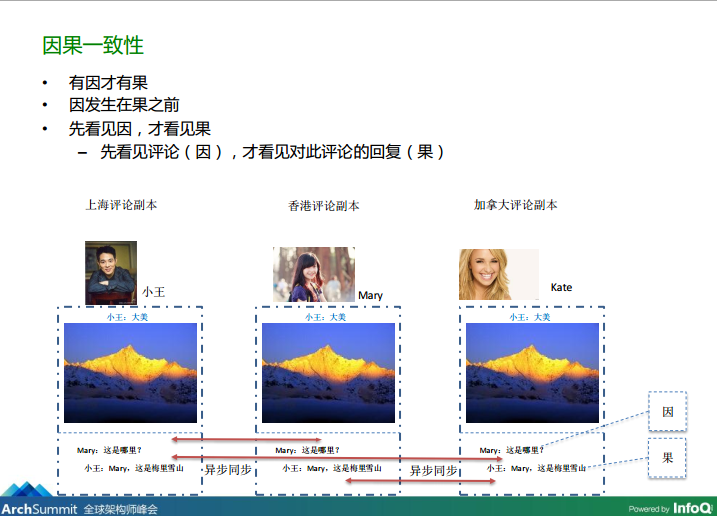
图4-1、因果关系的梳理
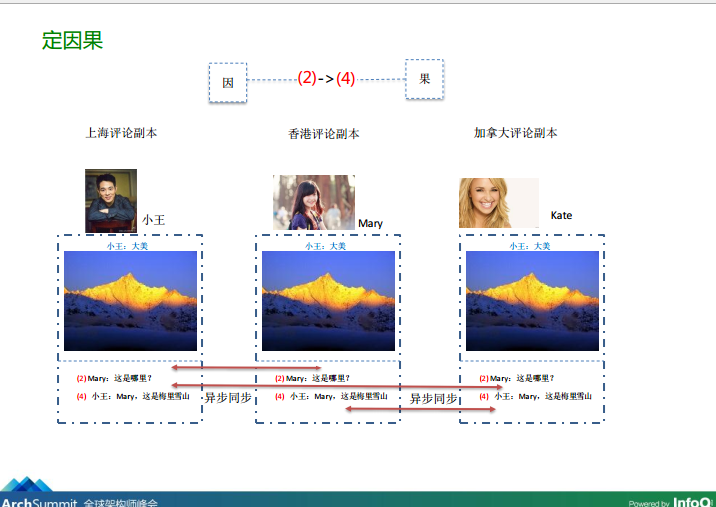
图4-2、因果关系的梳理
从上图4-1、4-2可知,我们可以将Mary对小王所发布的朋友圈状态的评论“Mary:这是哪里?”当成因,而把小王对Mary评论的答复“小王:Mary,这是梅里雪山”当成果。按照这样的约定,当这两条数据同步到Kate所在的数据中心副本时即使发生乱序,Kate根据在刷朋友圈时,根据因果关系也可以将这个评论、答复的顺序调整到正确的、可阅读的方式。那微信到底是采用什么方法来让各个地区的用户理解这个约定呢?具体来看:
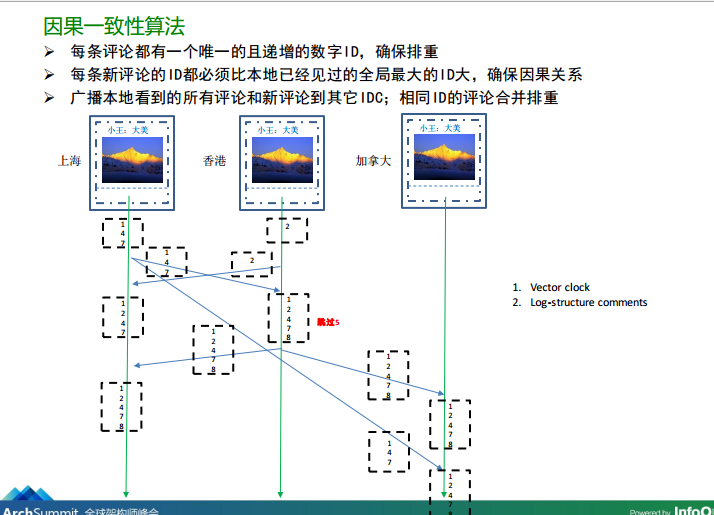
图5、朋友圈事件因果一致性的算法
从图5我们可知,微信采用如下的方案:
- 每条评论都有一个唯一的且递增的数字ID,确保排重
- 每条新评论的ID都必须比本地已经见过的全局最大的ID大,确保因果关系
- 广播本地看到的所有评论和新评论到其它IDC;相同ID的评论合并排重
我们可以针对上面的三点背后的技术作出合理性的解读跟假设:
1、每条评论都有一个唯一的且递增的数字ID:那么背后肯定是一个ID生成器,各个数据中心都有一个这样的入口来获取本IDC内唯一、递增的ID。具体怎么做的可参考。
2、每条新评论的ID都必须比本地已经见过的全局最大的ID大,确保因果关系:如上图在香港的数据中心,当发表完2的评论,并且已经同步上海数据中心过来的1 4 7等ID的评论之后,如果再有香港地域下的用户发表新评论时,那么一定要大于当前香港数据中心能看到的全局最大ID,此时是7,所以香港地域此时用户最新发表的评论的ID必须大于7(上图有一个“跳过5”的备注),所以上图中的ID(8)就是从这里得出的。
3、广播本地看到的所有评论和新评论到其它IDC;相同ID的评论合并排重:那么什么时候广播呢?其实就是本地域下的用户针对同一条朋友圈状态有评论时,该地域就负责申请一个全局ID,然后将这个评论的事件广播给其他的数据中心。注意这个过程需要合并所有看到的序列,例如香港数据中心就合并1 2 4 7 8等针对同一条朋友圈状态的一系列评论事件IDs,然后再整体广播出去,这样才能保证针对同一条状态的所有当前最新的事件整体被广播出去,否则此时香港IDC只广播8的话,如果前面的事件序列在广播的中途丢失了,那么其他节点比如加拿大IDC就会漏掉部分评论事件,这也是数据多重补位的措施。当然这个方法有一个前提就是:因为同一个朋友圈的发布状态,一般的评论不会很多,所以造成的数据冗余交互不会很大,否则是不行的。至于相同ID的评论合并排重,上图5可以看出,加拿大IDC会收到来自上海IDC的1 4 7事件系列,也会收到来自香港IDC同步过来的1 4 7 8 事件系列,这两个广播的事件系列有重复,所以需要去重。
总结
以上就是因果一致性在实际分布式系统业务中的应用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号