
Oracle之xml的增删改查操作
工作之余,总结一下xml操作的一些方法和心得!
tip: xmltype函数是将clob字段转成xmltype类型的函数,若字段本身为xmltype类型则不需要引用xmltype()函数
同名标签用数组取值的方式获取,但起始值从1开始
一.查询(Query)
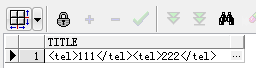
1. extract函数,查询节点值,带节点名
1 -- 获取带节点的值,例如:<tel>222</tel> 2 select extract(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel').getStringVal() as title from project e where e.zh_title='白夜追逐繁星'; 3 -- 备注如果节点表达式查询一个节点的父节点,则会将该父节点下的所有节点包含该父节点查出
Query Result:
tip: extract函数中路径引用text(),查询的节点若重复则自动拼接
select extractvalue(xmltype('<a><b>1</b><b>2</b></a>'),'/a/b') from dual; -- 报错,报只返回一个节点值,因为在a标签下存在两个同名标签b select extract(xmltype('<a><b>1</b><b>2</b></a>'),'/a/b/text()') from dual; -- extract+text() 解决同名节点问题,若存在重复节点会自动拼接在一起,但不使用任何拼接符号
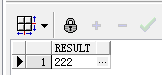
2. extractvalue函数,查询节点值,不带节点名
-- 获取不带节点的值,例如:222 1 select extractvalue(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel') as result from project e where e.zh_title='白夜追逐繁星';
Query Result:
Tip: 节点不存在时,查询结果均为空
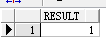
3. existsnode函数,判断节点是否存在,表示存在,0表示不存在
1 select existsnode(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel') as result from project e where e.zh_title='白夜追逐繁星';
Query Result:
4. sys_dburigen,将指定列通过函数生成一个该列的URI值,例如:/PUBLIC/PROJECT/ROW[ZH_TITLE='邹成咁180117']/ZH_TITLE
1 select sys_dburigen(e.zh_title) as result from project e where e.zh_title='白夜追逐繁星';
Query Result:

5. sys_xmlAgg,合并查询,将多个xml合并,类似于set集合
-- sys_xmlGen 将xml转成xmltype实例,方便xml合并,sys_xmlAgg用于xml合并
1 select sys_xmlAgg(sys_xmlgen(e.prj_xml)) as result from project e where e.zh_title='白夜追逐繁星' or e.zh_title='白夜追逐繁星2' ;
Query Result:
6. xmlforest,将指定列以xml格式查询出来,可指定生成的xml节点名称
1 select xmlforest(e.zh_title as zhTitle,e.prj_no as prjNo,e.psn_code as psnCode).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星';
Query Result:

7. xmlelement,为查询出来的xml添加挂载的父节点,并将xml字符串格式化成xml ,与xmlforest函数配套使用
1 select xmlelement(data,xmlforest(e.zh_title,e.prj_no,e.psn_code)).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星';
Query Result:

延伸:为data节点添加属性,使用xmlattributes函数
1 select xmlelement(data,xmlattributes(e.prj_code as code),xmlforest(e.zh_title,e.prj_no,e.psn_code)).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星';
Query Result:

延伸: XMLCOLATTVAL效果等同于xmlforest函数,但默认会为每个标签添加一个属性name,属性值为列明,若未指定列别名,默认该列列明
1 select XMLCOLATTVAL(e.zh_title as zhTitle,e.prj_no as prjNo,e.psn_code as psnCode).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星'
Query Result:

8. xmlConcat,xmlType实例之间联结
1 select xmlelement(data,xmlConcat(xmltype('<a>1</a>'),xmltype('<b>1</b>'))).getStringVal() as result from dual;
Query Result:
9. xmlsequence将一个xml以标签为单位,转换成数组,也就是一行行记录
1 select e.getStringVal() as result 2 from table(xmlsequence(extract(xmltype('<a><b>233</b><c>666</c><d>88</d></a>'),'/a/*'))) e;
Query Result:

二.添加(Insert)
-- 添加xml节点,insertchildxml添加xml节点,参数3默认指定插在该节点后,若该节点不存在,则追加到子节点集合的末尾
-- 添加xml节点,insertchildxmlbefore,和insertchildxmlafter添加xml节点,参数3指定插在该节点前或者后,若该节点不存在,则追加到子节点集合的末尾
1 update project e set e.prj_xml=insertchildxml(xmltype(e.prj_xml),'/data/project/persons/person[1]','tel',xmltype('<tel>222</tel>')).getClobVal() where e.zh_title='白夜追逐繁星'; 2 update project e set e.prj_xml=insertchildxmlbefore(xmltype(e.prj_xml),'/data/project/persons/person[1]','psn_code',xmltype('<tel>111</tel>')).getClobVal() where e.zh_title='白夜追逐繁星';
三.修改(Update)
-- updatexml用于更新节点值
1 -- updatexml用于更新节点值,参数1:需要修改节点的xml字段;参数2:节点路径;参数3:值 2 update project e set e.prj_xml=updatexml(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel','<tel>111</tel>').getClobVal() where e.zh_title='白夜追逐繁星'; 3 update project e set e.prj_xml=updatexml(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel/text()','222').getClobVal() where e.zh_title='白夜追逐繁星';
tip: getClobVal()是将xmltype类型转成clob类型方法
四.删除(Delete)
1 -- 删除xml节点,参数1:需要删除节点的xml字段;参数2:节点路径; 2 update project e set e.prj_xml=deletexml(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel').getClobVal() where e.zh_title='白夜追逐繁星';

