(转载)ECCV 2018:IBN-Net:打开域适应的新方式
(本文转自极视角)
本文由香港中文大学发表于ECCV2018,论文探索了IN和BN的优劣,据此提出的IBN-Net在语义分割的域适应任务上取得了十分显著的性能提升。

论文地址:https://arxiv.org/pdf/1807.09441
代码地址:https://github.com/XingangPan/IBN-Net
背景介绍
近年来,尽管CNN模型在诸如图像分类、目标检测和语义分割等任务上取得了惊艳的性能,但一个广泛存在的问题是:训练好的CNN模型只适用于特定的task甚至只适用于某一个domain。具体而言,该问题主要有两个表现:1、如果不进行finetune,则将在其他task或者domain上表现非常差;2、经过finetune后,在新的task或者domain上表现优异,但在原来的的task或者domain上性能却会出现显著的下降。这背后的原因是什么?又该以什么方式加以解决,是一个非常值得探索的问题。
针对不同domain之间的shift问题,近年来有学者通过Domain Adaptation (DA)的方式加以解决,其核心思想是:如何使得源域(Source Domain)上训练好的模型能够很好地迁移到没有标签数据的目标域上(Target Domain)上,DA尽管可以使得模型能够很好地适应目标域,但依然无法适应到其他目标域以外的Domain上,因此Domain Generalization(DG)应运而生,其核心思想是如何学习到不同Domain之间的共性特征,使得模型在不同Domain上都具有良好的适应性。然而现实场景中的Domain是难以穷尽的,以上两种方式依然需要不同Domain的数据参与到训练中,这种数据收集的代价显然是巨大的。有没有一种方式能够使得一个Domain上训练好的模型,在不需要任何新的Domain数据参与训练的情况下,也能具有很好的泛化能力?本文从特征Normalization的角度做了一次有益的探索。
基本问题
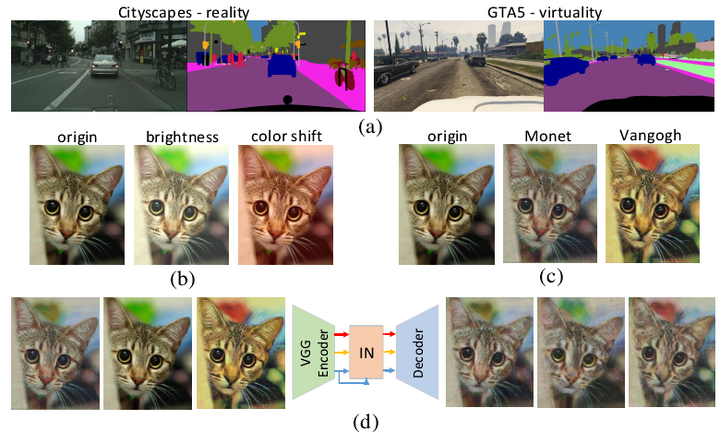
跑过实验的同学深知:在一个训练集上训练好的模型,如果测试数据和训练集风格不一样,模型的性能就会大打折扣,这时finetune就派上用场了,用新场景的数据对模型进行微调就是一种通用的做法。如下图所示,(a)展示的是两个不同的domain:真实数据和合成数据,显然二者的风格是各异的;(b)展示的是对同一张图片调整下色调和亮度,这是一种简单的风格变换;(c)展示的是通过风格转换网络对同一张图片调整为指定的风格,这是一种复杂的风格变换。显然解决以上差异的最佳方式在于让网络学习到关于目标的不变性特征,提高其泛化能力,而不是针对特定的风格重新训练网络。(d)展示了Instance Normalization(IN)的作用,只要将IN嵌入到一个编解码网络中,就可以将不同风格的图片中的风格信息过滤掉,而只保留内容信息,充分证明了IN在保留外观不变性方面的有效性。
从这一观察出发,一个自然的想法是:只要在网络中利用好IN,就能提高网络学习外观不变性的能力?为此作者进一步探索,将IN放置于何处才能更好地发挥其优势?作者通过下图的实验直观展示了特征在网络不同深度中的分布,实验中采用KL散度衡量特征之间的差异性(Y轴),X轴代表ResNet50中不同block的ID,从左到右网络深度不断加深,蓝色代表不同数据集中风格各异的图片,黄色代表同一个数据集中不同类别的图片。

可以发现:随着网络深度的增加,不同数据集图片的特征差异越来越小,而不同类别的图片的特征差异越来越大,这一差异表明低层的特征表示更多反映的是外观信息,而高层的特征表示更多反映的是语义信息。因此为了过滤掉这些反映外观变化的信息并同时保留语义信息,理应将IN放置于低层中。相比于IN,Batch Normalization(BN)把一个batch的数据进行归一化,恰恰是增强了语义特征之间的差异性。
解决之路
通过上图的分析,为了充分发挥IN和BN的各自优势,作者提出了IBN-Net的两条基本构建原则:1、为了防止网络在高层的语义判别性被破坏,IN只加在网络低层中;2、为了保留低层中的语义信息,网络低层中也保留BN。根据这两条原则,作者提出了如下两个IBN block:
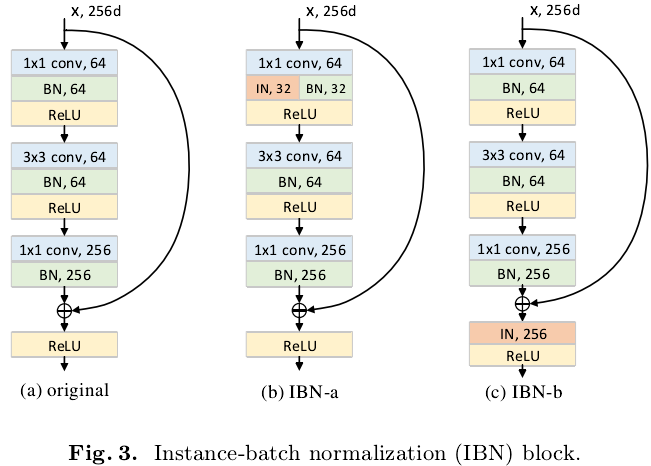
为何如此设计,作者给出了三点解释:(1)在ResNet的原论文中已经证明,identity path不加任何东西更有利于优化ResNet,所以IN不应该加在identity path中;(2)IN置于第一个normalization层,是为了保证与identity path的结果的一致性;(3)在第一个normalization层,IN和BN各占一半的通道数,一方面保证了不增加网络参数和计算量,另一方面也是为了在IN过滤掉反映外观变化的信息的同时用BN保留语义信息。此外,作者还展示了在实验中用到的其它几个IBN block,其核心思想依然符合上述两个设计原则,在此不再赘述。
实验分析
1、实验设定
通过将上文提到的IBN-block添加到不同的基础网络中验证IBN-block的普适性。实验分别在图像分类和语义分割两个任务上进行,首先研究在一个数据集上的性能提升,其次验证在跨数据集时网络的泛化能力。
2、ImageNet图像分类
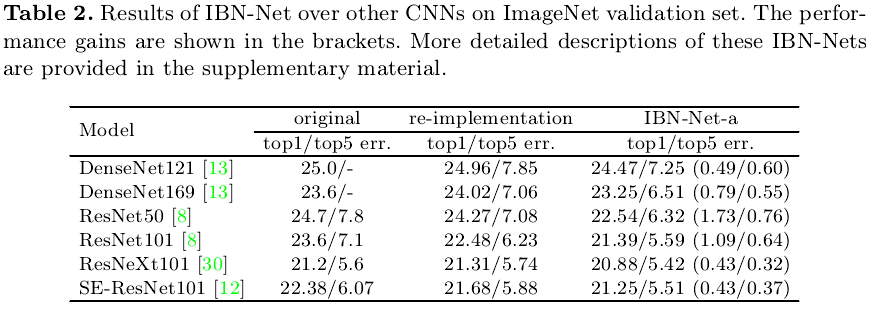
表2展示了在不同的基础网络中添加IBN-block所带来的性能提升,可以发现:在同样的参数设定下(这里选用的是图3(b)中的IBN-block),IBN可以使得基础网络的错误率降低0.5-1.5个百分点左右,说明IBN增强了模型的capacity。表3展示了跨数据集之间的性能提升,其中Monet代表对原始ImageNet数据进行了风格转换,不同的IBN-block均可以使得基础网络的错误率降低30个百分点左右,充分说明IBN可以提升模型的泛化能力。
3、跨域语义分割
作者在Cityscapes(真实数据)和GTA5(虚拟数据)上进行了Domain Generation的实验,从表6可以发现,不论是从Cityscapes到GTA5还是从GTA5到Cityscapes,只要有IBN加持,性能均有5-6个百分点左右的提升,而这种提升是不需要测试集中的图片进行重新训练的,验证了即使是在语义分割这样一个复杂的任务上,IBN也可以有非常出色的性能表现。
总结展望
本文贡献:
(1)结合IN和BN的优势,提出了IBN-block,可以无缝嵌入到各种已有的网络架构中,提升了基础网络的容量和泛化能力。
(2)在不增加网络参数和计算量的情况下,在图像分类和语义分割两个任务上,IBN均展现了非常优异的性能提升。
个人见解:
(1)不管是IN还是BN,本质上都是一种特征归一化的方式,二者唯一的区别在于对特征均值和方差不同的统计方式,因此normalization的核心就是这里的均值和方差。对于BN的均值和方差的研究,已有相关工作[1][2]发表,其研究表明:BN的均值和方差反映了不同数据集或者不同domain的独特信息,而本文综合考虑了IN和BN,在normalization层面上提升网络的泛化能力又迈出了坚实一步。
(2)Domain Generalization还有很长的路要走,当前的CNN模型在cross domain上的表现依然差强人意。尽管本文从normalization的角度部分解决了该问题,但从表6反映的结果来看,即使采用了本文的IBN-block,cross domain的结果依然远远落后于在同一个domain上训练和测试的结果,相比于IBN带来的微弱提升,这种差距是显著的。因此除了normalization之外,还有更为核心的问题有待挖掘。期待你的精彩发现。
参考文献
[1] Revisiting Batch Normalization For Practical Domain Adaptation. ICLR workshop(2017)
[2] AutoDIAL: Automatic DomaIn Alignment Layers. ICCV (2017)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号