HardNet解读
论文:Working hard to know your neighbor’s margins: Local descriptor learning loss
为什么介绍此文:这篇2018cvpr文章主要是从困难样本入手,提出的一个loss,简单却很有效,在图像匹配、检索、Wide baseline stereo等都做了大量详细实验,在真实任务中真正取得了state-of-the-art的结果。代码:https://github.com/DagnyT/hardnet 。上一篇博客中的论文可以和这个相结合,一起阅读更佳。此外这些通过learn得到的descriptor虽然在某些数据集结果好,但在实际中并不popular,甚至不如传统SIFT及其变体!有结论认为是数据集不够大、不够有区分度!
摘要:
受到到Lowe的SIFT的匹配标准启发,引入一种度量学习所用的loss。最大化一个batch中的最近正样本与最近负样本的距离。这种方法比复杂的优化方法更有效,它对于浅层或深层网络都很work。将这个loss结合与L2Net的结构可以达到一个更加全面的描述子,称之为HardNet。它有着和SIFT一样的特征维度128,并且state-of-art performance in wide baseline stereo, patch verification and instance retrieval benchmarks.
1. 介绍
许多计算机视觉任务依赖寻找local correspondences,例如image retrieval、panorama stitching、wide baseline stereo、3D-reconstruction。尽管越来越多端到端的方法试图取代复杂的经典方法,但是对于local patches的经典的检测子和描述子仍然被用,主要就是鲁棒性和高效性以及紧密的集成。
LIFT、MatchNet和DeepCompare是最先尝试的端到端学习,然而这些方法在实际应用中并不受欢迎,尽管它们在patch verification任务中有好的表现。近来的研究证实SIFT以及其变体(RootSIFT-PCA [16], DSP-SIFT [17)远超于learned descriptors在匹配、检索以及SD重建等领域。【19】给出结论是local patches datasets不够大和有区分度来学习这么一种高质量、可以广泛应用的descriptor。
本文关注于descriptor的学习,并提出一个新奇的网络HardNet。并通过大量实验展示了该方法学习到的descriptor同时在真实世界的任务中远超于hand-crafted和learned descriptors。达到了真正的state-of-the-art。
2. 相关工作
经典的SIFT local feature matching包括两部分:寻找最近邻和比较第一、第二近邻的距离比值来过滤假阳性matches。据作者所知还没人这么做。
【20】提出一个简单的filter plus pooling策略和convex optimization 来取代 hand-crafted filters and poolings in SIFT。MatchNet采用Siamese网络结构,首先是feature net,然后是metric net,后者提高了匹配表现,但是却无法使用快速最近邻算法例如kd-tree。【15】同样方法探索了不同结构,【22】利用hard negative mining和相对较浅的结构来探索pair-basesd similarity。
下面的几篇论文中与经典的SIFT匹配策略结合紧密。【23】利用triplet margin loss和triplet distance loss,随机采样patch。它显示了triplet-based结构比pair based的优越性。它们随机采用负样本。【7】计算挖掘的正负类样本的距离矩阵,然后是pairwise contrastive loss。
L2-Net利用一个batch中的n个匹配对来生成n方-n个负样本对并且要求每行每列中到真实匹配的距离最小。没有其他距离或者距离比值的限制。相反,它们提出一个对描述子维数的相关性的惩罚,并且通过intermediate 特征图采取deep supervision。本文采用L2-Net的结构作为base结构,我们展现了利用更简单的目标函数不需要两个辅助损失项,学习更有力描述子的可能性。

图1 ,根据图示可以看到这种采样策略比较简单,但是却很有效!
下面分析这个采样过程。
3. The proposed descriptor
3.1 Sampling and loss
学习目标模仿SIFT的匹配标准,过程如图1.首先一个batch中的匹配块生成![]() ,A代表anchor,P代表positive。那么每一对就是源于相同的一个SD point。
,A代表anchor,P代表positive。那么每一对就是源于相同的一个SD point。
第二,这2n个patch进入图2中的网络。 计算L2 pairwise距离矩阵n*n:

那么![]()
然后要分别寻找和该匹配对最相近的不匹配patch以及次相近的不匹配patch的特征向量。(这体现了sift的操作)

那目标就是最小化匹配描述子和与之最相近的非匹配描述子。这n个triplet 距离然后被送到triplet margin loss:

距离在triplet重组的过程中已经预计算好了,和随机triplet采样相比开销是距离矩阵的计算、计算行列的最值。此外,相比usual的triplets学习,我们的方案只需两路two-stream CNN,并不是三路。减少了30%的计算和存储。和L2-net不同的是neither deep supervision for intermediate layers is used, nor a constraint on the correlation of descriptor dimensions.并没有产生过拟合。
3.2 Model architecture
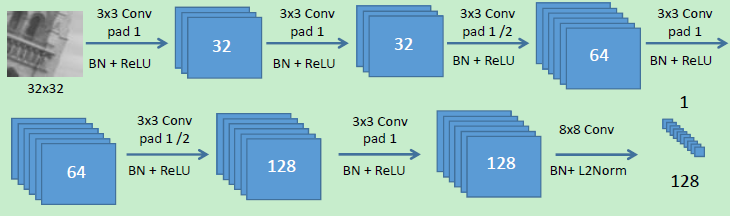
结构来源于L2Net,具体参数及设置见论文。
有趣的一点是Pytorch更新后,作者无法复现,通过超参数搜索后,设置lr=10,dropout rate=0.3得到了更好的结果。
3.3 Model training
在UBC数据集上,除了给出fpr95:false positive rate (FPR) at point of 0.95 true positive recall.,还给出了MatchNet和Tfeat中的FDR:(false discovery rate) 指标。另外作者没有做CS(center-surrounding)结构的实验,因为许多论文都证明了这个结构可以提升结果,所以这里不比再做,其实我认为可以看看还能提升多少。。

可以看到hardnet不论有无数据增强,都更强于L2Net!
作者又探索了batchsize的影响:发现128比较合适,256之提升了一点点。
后面的工作还有很多,关于real-world实际应用的实验,有空再补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号