Faster_RCNN 4.训练模型
总结自论文:Faster_RCNN,与Pytorch代码:
本文主要介绍代码最后部分:trainer.py 、train.py , 首先分析一些主要理论操作,然后在代码分析里详细介绍其具体实现。首先是训练与测试的过程图:


还是要再次强调:
AnchorTargetCreator和ProposalTargetCreator是为了生成训练的目标(或称ground truth),只在训练阶段用到,ProposalCreator是RPN为Fast R-CNN生成RoIs,在训练和测试阶段都会用到。所以测试阶段直接输进来300个RoIs,而训练阶段会有AnchorTargetCreator的再次干预。
在ROI Pooling过程中,首先sample_rois中的坐标将feature(512,w/16,h/16)划分为不同的roi_feature_map(_,512,w/16,w/16),再经过ROI Pooling操作,类似SPP那样将特征图下采样到同样的大小(_,512,7,7)。
一. 代码分析
1.trainer.py


from collections import namedtuple import time from torch.nn import functional as F from model.utils.creator_tool import AnchorTargetCreator, ProposalTargetCreator from torch import nn import torch as t from torch.autograd import Variable from utils import array_tool as at from utils.vis_tool import Visualizer from utils.config import opt from torchnet.meter import ConfusionMeter, AverageValueMeter LossTuple = namedtuple('LossTuple', ['rpn_loc_loss', 'rpn_cls_loss', 'roi_loc_loss', 'roi_cls_loss', 'total_loss' ]) class FasterRCNNTrainer(nn.Module): """wrapper for conveniently training. return losses The losses include: * :obj:`rpn_loc_loss`: The localization loss for \ Region Proposal Network (RPN). * :obj:`rpn_cls_loss`: The classification loss for RPN. * :obj:`roi_loc_loss`: The localization loss for the head module. * :obj:`roi_cls_loss`: The classification loss for the head module. * :obj:`total_loss`: The sum of 4 loss above. Args: faster_rcnn (model.FasterRCNN): A Faster R-CNN model that is going to be trained. """ def __init__(self, faster_rcnn): super(FasterRCNNTrainer, self).__init__() self.faster_rcnn = faster_rcnn self.rpn_sigma = opt.rpn_sigma self.roi_sigma = opt.roi_sigma # target creator create gt_bbox gt_label etc as training targets. self.anchor_target_creator = AnchorTargetCreator() self.proposal_target_creator = ProposalTargetCreator() self.loc_normalize_mean = faster_rcnn.loc_normalize_mean self.loc_normalize_std = faster_rcnn.loc_normalize_std self.optimizer = self.faster_rcnn.get_optimizer() # visdom wrapper self.vis = Visualizer(env=opt.env) # indicators for training status self.rpn_cm = ConfusionMeter(2) self.roi_cm = ConfusionMeter(21) self.meters = {k: AverageValueMeter() for k in LossTuple._fields} # average loss def forward(self, imgs, bboxes, labels, scale): """Forward Faster R-CNN and calculate losses. Here are notations used. * :math:`N` is the batch size. * :math:`R` is the number of bounding boxes per image. Currently, only :math:`N=1` is supported. Args: imgs (~torch.autograd.Variable): A variable with a batch of images. bboxes (~torch.autograd.Variable): A batch of bounding boxes. Its shape is :math:`(N, R, 4)`. labels (~torch.autograd..Variable): A batch of labels. Its shape is :math:`(N, R)`. The background is excluded from the definition, which means that the range of the value is :math:`[0, L - 1]`. :math:`L` is the number of foreground classes. scale (float): Amount of scaling applied to the raw image during preprocessing. Returns: namedtuple of 5 losses """ n = bboxes.shape[0] if n != 1: raise ValueError('Currently only batch size 1 is supported.') _, _, H, W = imgs.shape img_size = (H, W) features = self.faster_rcnn.extractor(imgs) rpn_locs, rpn_scores, rois, roi_indices, anchor = \ self.faster_rcnn.rpn(features, img_size, scale) # Since batch size is one, convert variables to singular form bbox = bboxes[0] label = labels[0] rpn_score = rpn_scores[0] rpn_loc = rpn_locs[0] roi = rois # Sample RoIs and forward # it's fine to break the computation graph of rois, # consider them as constant input sample_roi, gt_roi_loc, gt_roi_label = self.proposal_target_creator( roi, at.tonumpy(bbox), at.tonumpy(label), self.loc_normalize_mean, self.loc_normalize_std) # NOTE it's all zero because now it only support for batch=1 now sample_roi_index = t.zeros(len(sample_roi)) roi_cls_loc, roi_score = self.faster_rcnn.head( features, sample_roi, sample_roi_index) # ------------------ RPN losses -------------------# gt_rpn_loc, gt_rpn_label = self.anchor_target_creator( at.tonumpy(bbox), anchor, img_size) gt_rpn_label = at.tovariable(gt_rpn_label).long() gt_rpn_loc = at.tovariable(gt_rpn_loc) rpn_loc_loss = _fast_rcnn_loc_loss( rpn_loc, gt_rpn_loc, gt_rpn_label.data, self.rpn_sigma) # NOTE: default value of ignore_index is -100 ... rpn_cls_loss = F.cross_entropy(rpn_score, gt_rpn_label.cuda(), ignore_index=-1) _gt_rpn_label = gt_rpn_label[gt_rpn_label > -1] _rpn_score = at.tonumpy(rpn_score)[at.tonumpy(gt_rpn_label) > -1] self.rpn_cm.add(at.totensor(_rpn_score, False), _gt_rpn_label.data.long()) # ------------------ ROI losses (fast rcnn loss) -------------------# n_sample = roi_cls_loc.shape[0] roi_cls_loc = roi_cls_loc.view(n_sample, -1, 4) roi_loc = roi_cls_loc[t.arange(0, n_sample).long().cuda(), \ at.totensor(gt_roi_label).long()] gt_roi_label = at.tovariable(gt_roi_label).long() gt_roi_loc = at.tovariable(gt_roi_loc) roi_loc_loss = _fast_rcnn_loc_loss( roi_loc.contiguous(), gt_roi_loc, gt_roi_label.data, self.roi_sigma) roi_cls_loss = nn.CrossEntropyLoss()(roi_score, gt_roi_label.cuda()) self.roi_cm.add(at.totensor(roi_score, False), gt_roi_label.data.long()) losses = [rpn_loc_loss, rpn_cls_loss, roi_loc_loss, roi_cls_loss] losses = losses + [sum(losses)] return LossTuple(*losses) def train_step(self, imgs, bboxes, labels, scale): self.optimizer.zero_grad() losses = self.forward(imgs, bboxes, labels, scale) losses.total_loss.backward() self.optimizer.step() self.update_meters(losses) return losses def save(self, save_optimizer=False, save_path=None, **kwargs): """serialize models include optimizer and other info return path where the model-file is stored. Args: save_optimizer (bool): whether save optimizer.state_dict(). save_path (string): where to save model, if it's None, save_path is generate using time str and info from kwargs. Returns: save_path(str): the path to save models. """ save_dict = dict() save_dict['model'] = self.faster_rcnn.state_dict() save_dict['config'] = opt._state_dict() save_dict['other_info'] = kwargs save_dict['vis_info'] = self.vis.state_dict() if save_optimizer: save_dict['optimizer'] = self.optimizer.state_dict() if save_path is None: timestr = time.strftime('%m%d%H%M') save_path = 'checkpoints/fasterrcnn_%s' % timestr for k_, v_ in kwargs.items(): save_path += '_%s' % v_ t.save(save_dict, save_path) self.vis.save([self.vis.env]) return save_path def load(self, path, load_optimizer=True, parse_opt=False, ): state_dict = t.load(path) if 'model' in state_dict: self.faster_rcnn.load_state_dict(state_dict['model']) else: # legacy way, for backward compatibility self.faster_rcnn.load_state_dict(state_dict) return self if parse_opt: opt._parse(state_dict['config']) if 'optimizer' in state_dict and load_optimizer: self.optimizer.load_state_dict(state_dict['optimizer']) return self def update_meters(self, losses): loss_d = {k: at.scalar(v) for k, v in losses._asdict().items()} for key, meter in self.meters.items(): meter.add(loss_d[key]) def reset_meters(self): for key, meter in self.meters.items(): meter.reset() self.roi_cm.reset() self.rpn_cm.reset() def get_meter_data(self): return {k: v.value()[0] for k, v in self.meters.items()} def _smooth_l1_loss(x, t, in_weight, sigma): sigma2 = sigma ** 2 diff = in_weight * (x - t) abs_diff = diff.abs() flag = (abs_diff.data < (1. / sigma2)).float() flag = Variable(flag) y = (flag * (sigma2 / 2.) * (diff ** 2) + (1 - flag) * (abs_diff - 0.5 / sigma2)) return y.sum() def _fast_rcnn_loc_loss(pred_loc, gt_loc, gt_label, sigma): in_weight = t.zeros(gt_loc.shape).cuda() # Localization loss is calculated only for positive rois. # NOTE: unlike origin implementation, # we don't need inside_weight and outside_weight, they can calculate by gt_label in_weight[(gt_label > 0).view(-1, 1).expand_as(in_weight).cuda()] = 1 loc_loss = _smooth_l1_loss(pred_loc, gt_loc, Variable(in_weight), sigma) # Normalize by total number of negtive and positive rois. loc_loss /= (gt_label >= 0).sum() # ignore gt_label==-1 for rpn_loss return loc_loss
此脚本定义了类FasterRCNNTrainer,在初始化中用到了之前定义的类FasterRCNNVGG16为faster_rcnn。 此外在初始化中有引入了其他creator、vis、optimizer等。
定义了四个损失函数和一个总损失函数:rpn_loc_loss、rpn_cls_loss、roi_loc_loss、roi_cls_loss以及total_loss。
前向传播:
因为只支持batch_size=1的训练,所以n=1。 每个batch输入一张图片、一张图片上的所有bbox及label,以及图像经过预处理后的尺度scale。
对于两个分类损失调用cross_entropy即可。回归损失调用smooth_l1_loss。这里要注意的一点是例如roi回归输出的是128*84,然而真实位置参数是128*4和真实标签128*1,利用这个真实标签将回归输出索引成为128*4即可。然后在计算过程中只计算非背景类的回归损失。具体实现与Fast-RCNN略有不同(sigma设置不同)。
此外定义了保存模型、可视化信息、具体配置、导入权重、配置信息等函数。
此外还从torchnet.meter 引入了 ConfusionMeter, AverageValueMeter。
2. trainer.py
import os import ipdb import matplotlib from tqdm import tqdm from utils.config import opt from data.dataset import Dataset, TestDataset, inverse_normalize from model import FasterRCNNVGG16 from torch.autograd import Variable from torch.utils import data as data_ from trainer import FasterRCNNTrainer from utils import array_tool as at from utils.vis_tool import visdom_bbox from utils.eval_tool import eval_detection_voc # fix for ulimit # https://github.com/pytorch/pytorch/issues/973#issuecomment-346405667 import resource rlimit = resource.getrlimit(resource.RLIMIT_NOFILE) resource.setrlimit(resource.RLIMIT_NOFILE, (20480, rlimit[1])) matplotlib.use('agg') def eval(dataloader, faster_rcnn, test_num=10000): pred_bboxes, pred_labels, pred_scores = list(), list(), list() gt_bboxes, gt_labels, gt_difficults = list(), list(), list() for ii, (imgs, sizes, gt_bboxes_, gt_labels_, gt_difficults_) in tqdm(enumerate(dataloader)): sizes = [sizes[0][0], sizes[1][0]] pred_bboxes_, pred_labels_, pred_scores_ = faster_rcnn.predict(imgs, [sizes]) gt_bboxes += list(gt_bboxes_.numpy()) gt_labels += list(gt_labels_.numpy()) gt_difficults += list(gt_difficults_.numpy()) pred_bboxes += pred_bboxes_ pred_labels += pred_labels_ pred_scores += pred_scores_ if ii == test_num: break result = eval_detection_voc( pred_bboxes, pred_labels, pred_scores, gt_bboxes, gt_labels, gt_difficults, use_07_metric=True) return result def train(**kwargs): opt._parse(kwargs) dataset = Dataset(opt) print('load data') dataloader = data_.DataLoader(dataset, \ batch_size=1, \ shuffle=True, \ # pin_memory=True, num_workers=opt.num_workers) testset = TestDataset(opt) test_dataloader = data_.DataLoader(testset, batch_size=1, num_workers=opt.test_num_workers, shuffle=False, \ pin_memory=True ) faster_rcnn = FasterRCNNVGG16() print('model construct completed') trainer = FasterRCNNTrainer(faster_rcnn).cuda() if opt.load_path: trainer.load(opt.load_path) print('load pretrained model from %s' % opt.load_path) trainer.vis.text(dataset.db.label_names, win='labels') best_map = 0 lr_ = opt.lr for epoch in range(opt.epoch): trainer.reset_meters() for ii, (img, bbox_, label_, scale) in tqdm(enumerate(dataloader)): scale = at.scalar(scale) img, bbox, label = img.cuda().float(), bbox_.cuda(), label_.cuda() img, bbox, label = Variable(img), Variable(bbox), Variable(label) trainer.train_step(img, bbox, label, scale) if (ii + 1) % opt.plot_every == 0: if os.path.exists(opt.debug_file): ipdb.set_trace() # plot loss trainer.vis.plot_many(trainer.get_meter_data()) # plot groud truth bboxes ori_img_ = inverse_normalize(at.tonumpy(img[0])) gt_img = visdom_bbox(ori_img_, at.tonumpy(bbox_[0]), at.tonumpy(label_[0])) trainer.vis.img('gt_img', gt_img) # plot predicti bboxes _bboxes, _labels, _scores = trainer.faster_rcnn.predict([ori_img_], visualize=True) pred_img = visdom_bbox(ori_img_, at.tonumpy(_bboxes[0]), at.tonumpy(_labels[0]).reshape(-1), at.tonumpy(_scores[0])) trainer.vis.img('pred_img', pred_img) # rpn confusion matrix(meter) trainer.vis.text(str(trainer.rpn_cm.value().tolist()), win='rpn_cm') # roi confusion matrix trainer.vis.img('roi_cm', at.totensor(trainer.roi_cm.conf, False).float()) eval_result = eval(test_dataloader, faster_rcnn, test_num=opt.test_num) if eval_result['map'] > best_map: best_map = eval_result['map'] best_path = trainer.save(best_map=best_map) if epoch == 9: trainer.load(best_path) trainer.faster_rcnn.scale_lr(opt.lr_decay) lr_ = lr_ * opt.lr_decay trainer.vis.plot('test_map', eval_result['map']) log_info = 'lr:{}, map:{},loss:{}'.format(str(lr_), str(eval_result['map']), str(trainer.get_meter_data())) trainer.vis.log(log_info) if epoch == 13: break if __name__ == '__main__': import fire fire.Fire()
训练Faster-RCNN。
总共迭代14个epoch,第9个epoch时学习率衰减0.1倍。每100个batch在visdom中更新损失变化曲线及显示训练与测试图像。
二. 补充内容
1. RPN网络
RPN作用是通过网络训练的方式从feature map中获取目标的大致位置。RPN做两件事:1、把feature map分割成多个小区域,识别出哪些小区域是前景,哪些是背景,简称RPN Classification;2、获取前景区域的大致坐标,简称RPN bounding box regression。RPN可以独立使用,而不需要第二阶段的模型。在只有一类对象的问题中,目标性概率可以用作最终的类别概率。这是因为在这种情况下,「前景」=「目标类别」以及「背景」=「不是目标类别」。一些从独立使用 RPN 中受益的机器学习问题的例子包括流行的(但仍然是具有挑战性的)人脸检测和文本检测。仅使用 RPN 的优点之一是训练和预测的速度都有所提高。由于 RPN 是一个非常简单的仅使用卷积层的网络,所以预测时间比使用分类基础网络更快。
2. 回归
两次位置参数回归中的h,w都采用的是取对数操作,用对数来表示长宽的差别,是为了在差别大时能快速收敛,差别小时能较慢收敛来保证精度。
3 . chainer框架与pytorch等其他框架的比较:
chainer利用python重造了所有轮子(所有layer、正反向传播等),而pytorch借用现有C语言的轮子(TH、THNN)。
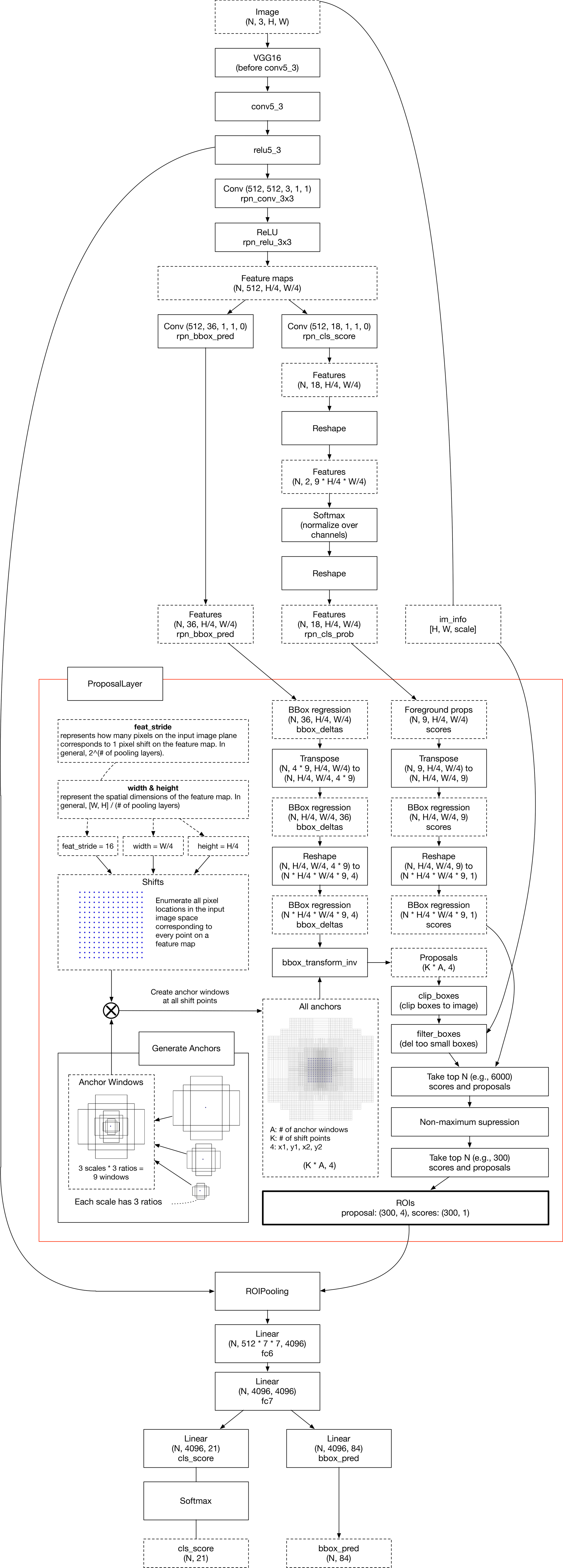
下图是chainer实现Faster-RCNN的流程图:
Reference:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号