f-GAN
学习总结于国立台湾大学 :李宏毅老师
f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization
本文Outline
一句话介绍f-GAN: you can use any f-divergence
一. 回顾GAN的basic idea:
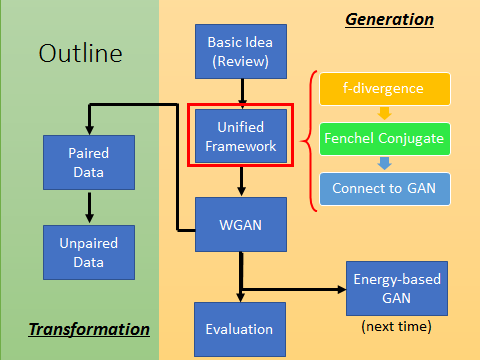
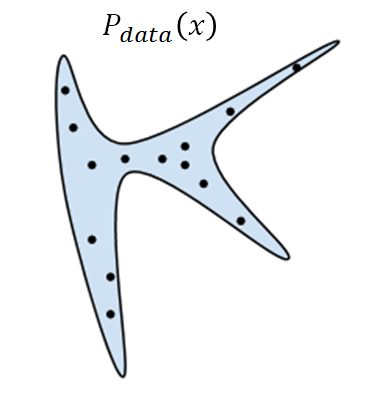
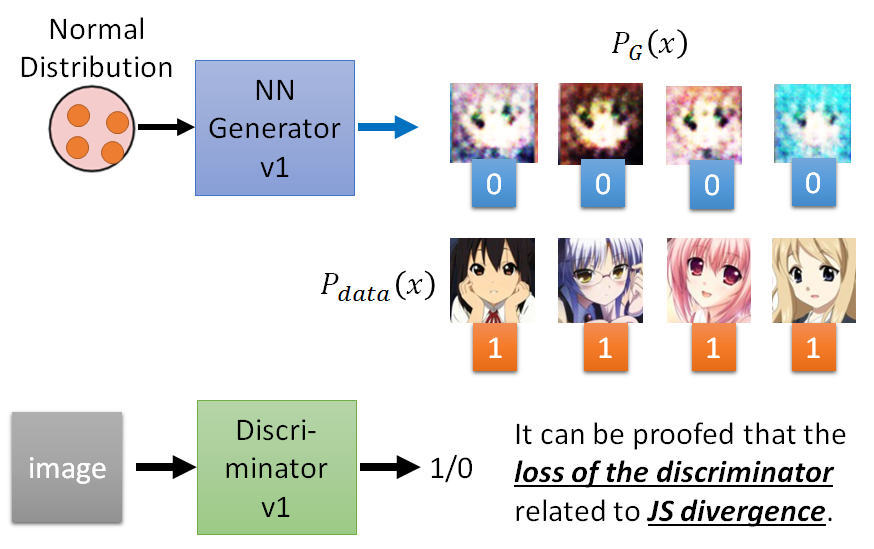
我们想要machine生成的target distribution: Pdata(x) ,如下图蓝色区域的分布。图中的蓝色区域里面为Pdata(x)值为高的部分,即sample出的图片看起来很好,蓝色区域外sample出来的看起来很模糊。
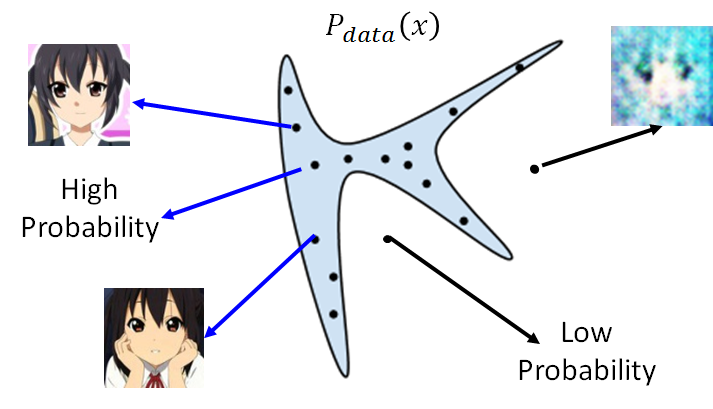
那怎么做?要找到一个generator,即为NN, 这个网络就定义了一个probability distribution。此时generator的输入为一个分布:normal distribution, 输出就是另外一个distribution。而这个输出一般是很复杂的分布,可能是叫不上名字的分布(例如高斯混合分布等),毕竟是经过了NN。那我们的任务就是调整generator的参数使得生成的分布PG(x)尽可能接近真实的分布 Pdata(x) 。
上图操作的难点在于难以计算出PG(x), 就说给定x,无法算出PG(x)是多少,如果可以算出PG(x)是多少,就可以maxmize likelihood。所以给你已有的data,无法算出data的likelihood是多少,唯一能做的是从原始data中sample。
Basic Idea of GAN:
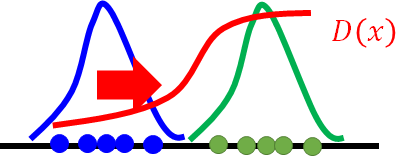
直观解释generator和discriminator在迭代过程中做了什么?
蓝色的点代表此时的generator画出的图,绿色的点为真实的数据分布,蓝线和绿线分别表示generator和data的distribution。红线为discriminator。那discriminator就是让绿点进入discriminator的输出为1, 蓝色输出为0,所以如果你训练了一个discriminator它应该长这个样子:
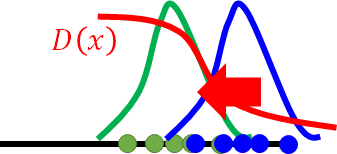
生成器又希望蓝线可以移向绿线 但调参G可能又使得移动过多, D又有新的判断
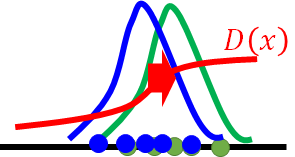
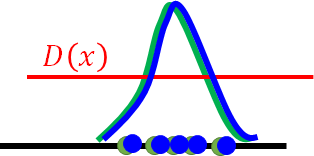
G,D反复更新 完全重合时,D无法判别只能都是输出一样的值
实际为高维问题,远比二维复杂。
GAN的基本算法:

二. GAN的Unified Framework
什么是f-divergence、Fenchel Conjugate,然后 Connect to GAN
1. f-divergence
f-divergence论文讲到之前的discriminator和JS-divergence有关,但是可以设计你的discriminator让它跟任何的f-divergence有关。
什么是f-divergence? f可以为很多不同的function,但必须满足(f is convex, f(1) = 0):
假设P, Q为两个分布,p(x)和q(x)为sample x的概率(the probability of sampling x)。

f-divergence为大于等于0的数,当P和Q完全一样的分布时,Df(P||Q)取到最小值0.否则为正数。 证明如下:
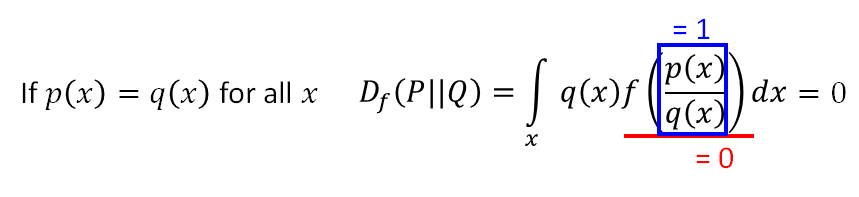
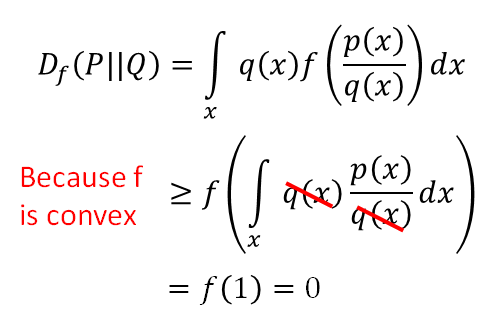
f-divergence栗子:
- f = xlogx 为 KL-divergence:
![]()
- f = -logx 为Reverse KL-divergence:
![]()
- f = (x-1)2 为Chi Squzre:
![]()
2. Fenchel Conjugate
每个凸函数f有一个conjugate function f*:![]()
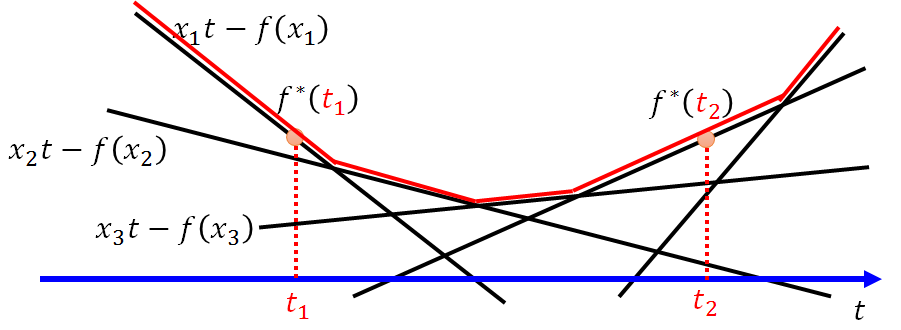
x不同的取值得到不同的直线,横坐标对应不同的t值取所有与直线中取值最大的值,这个操作就得到了红色的线,是个凸函数f*(t)。
Fenchel Conjugate 栗子: 取x为0.1、1、10....
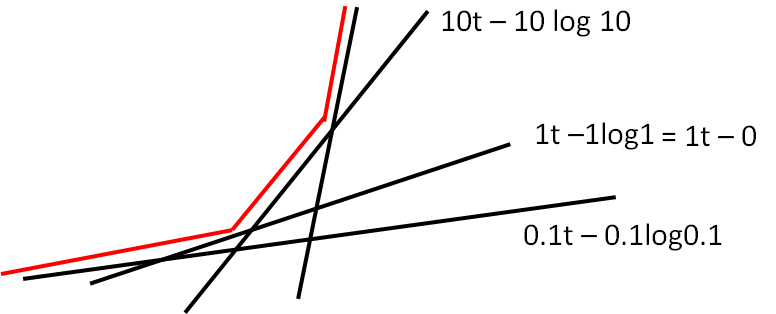
上图看起来像exp指数函数吧,事实上当f(x) = xlogx时, f*(t)就是指数函数exp(t-1) !!! 这个过程怎么算的呢?
很简单,令g(x) = xt- xlogx, 就是给定t,找一个x使得g(x)最大。所以对g(x)微分: t - logx -1 = 0 得到:x = exp(t-1) 带回原式得到f得共轭f*:
![]()
3. Connection with GAN
前提了解了 f 与它的共轭好朋友的互推关系:![]()
现在将Df(P||Q)中的 f 带入上式:
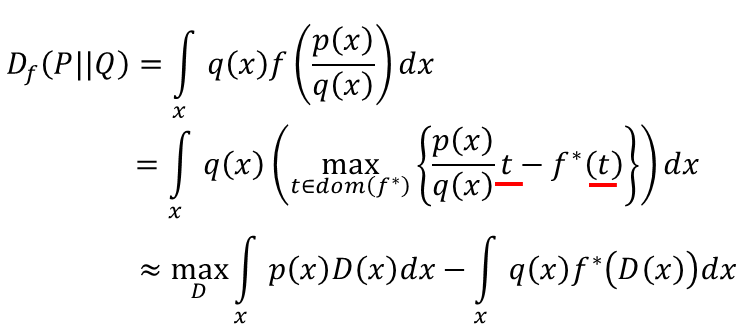
上式怎么得出的?假设有个函数叫D, 为一个function,它的输入为x,输出为t。 注意原式中的max{ }一项中为给定一个x找到一个t使得式子最大值,那么这个D为任意一个函数,所以它的输出应是个下界lower bound,所以可以用D来代替t,从而得到了下界:
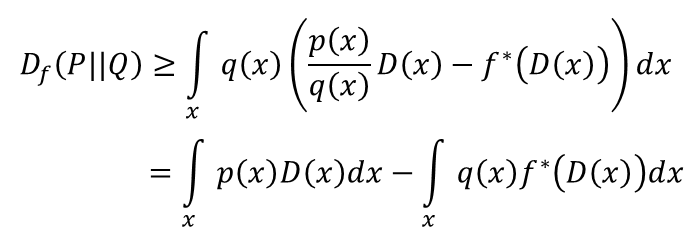
所以这里的f-divergence有个近似,即找一个D使得式子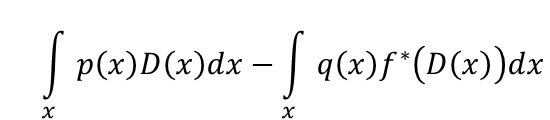 最大:
最大:
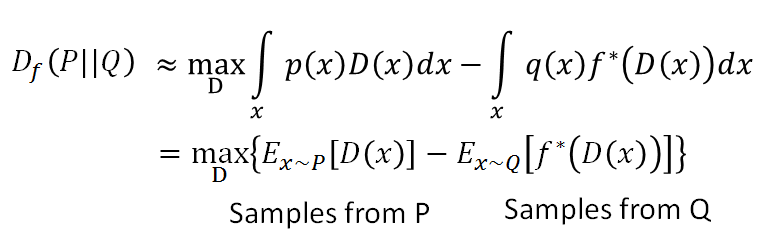
把P、Q代替后有:
![]()
算期望值可以利用sample来近似,要找一个PG 和Pdata越相近越好就是解下面这个式子:找一个G来最小化divergence
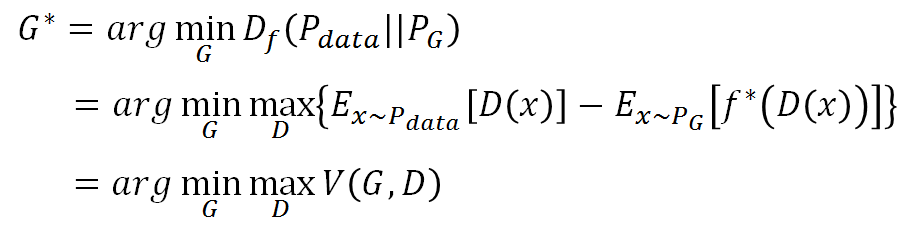
所以这就推出了原生GAN的优化目标: ![]()
原生GAN论文实现:double-loop algorithm:

f-GAN论文实现:Single -step:

注意G、D的update方向不一样。f-GAN论文中列出了各式各样的f-divergence:
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号