Hybrid - Faster training and easy deployment
Hybrid - Faster training and easy deployment
相关内容:
- Fast, portable neural networks with Gluon HybridBlocks
- A Hybrid of Imperative and Symbolic Programming
深度学习框架大致可以分为两类:declarative和imperative。对于declarative框架(包括Tensorflow、Theano等),用户首先声明一个固定的计算图,然后端到端地执行它。固定计算图的优点是它的可移植性和运行效率。但是,它不太灵活,因为任何逻辑都必须作为特殊运算符(如scan、while_loop和cond)编码到图中。这也很难调试。
imperative框架(包括PyTorch、Chainer等)正好相反:它们像老式的Matlab和Numpy一样逐个执行命令。这种风格更灵活,更容易调试,但效率较低。
HybridBlock无缝地结合了声明式编程和命令式编程,从而提供了两者的优点。用户可以通过命令式编程快速开发和调试模型,并通过调用以下命令切换到高效的声明式执行:
HybridBlock.hybridize().
HybridBlock
HybridBlock类似于Block但是有一些限制:
- HybridBlock的所有子层也必须是HybridBlock。
- 只能使用同时为NDArray和Symbol实现的方法。例如,不能使用.asnumpy()、.shape等。
- 运行时操作无法更改。例如,不能对每个迭代执行if x:if x。
想利用混合编程,就需要子类化HybridBlock:
import mxnet as mx from mxnet import gluon from mxnet.gluon import nn mx.random.seed(42) class Net(gluon.HybridBlock): def __init__(self, **kwargs): super(Net, self).__init__(**kwargs) with self.name_scope(): # layers created in name_scope will inherit name space # from parent layer. self.conv1 = nn.Conv2D(6, kernel_size=5) self.pool1 = nn.MaxPool2D(pool_size=2) self.conv2 = nn.Conv2D(16, kernel_size=5) self.pool2 = nn.MaxPool2D(pool_size=2) self.fc1 = nn.Dense(120) self.fc2 = nn.Dense(84) # You can use a Dense layer for fc3 but we do dot product manually # here for illustration purposes. self.fc3_weight = self.params.get('fc3_weight', shape=(10, 84)) def hybrid_forward(self, F, x, fc3_weight): # Here `F` can be either mx.nd or mx.sym, x is the input data, # and fc3_weight is either self.fc3_weight.data() or # self.fc3_weight.var() depending on whether x is Symbol or NDArray print(x) x = self.pool1(F.relu(self.conv1(x))) x = self.pool2(F.relu(self.conv2(x))) # 0 means copy over size from corresponding dimension. # -1 means infer size from the rest of dimensions. x = x.reshape((0, -1)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = F.dot(x, fc3_weight, transpose_b=True) return x
⚠️注意上面的前向函数中有F,x;对于pytorch而言这里只有x代表输入数据。下面分析这种情况。
Hybridize
默认情况下,HybridBlock会像标准的Block那样执行(也像pytorch那样),每次调用都会forward起来:
net = Net() net.initialize() x = mx.nd.random_normal(shape=(16, 1, 28, 28)) net(x) x = mx.nd.random_normal(shape=(16, 1, 28, 28)) net(x)
注意上面hybrid_forward中的print(x),这里调用两次net(x),所以会打印两次输出,一切看起来都很normal。可是当调用.hybridize()时就会发生:
net.hybridize() x = mx.nd.random_normal(shape=(16, 1, 28, 28)) net(x) x = mx.nd.random_normal(shape=(16, 1, 28, 28)) net(x)
在调用hybridize()之后,只有第一次前向时会打印一个symbol,之后的前向操作都不会调用hybrid_forward函数,所以前向时不会有任何输出。
hybridize会加速执行并节省内存。如果网络顶层不是HybridBlock,你仍然可以使用.hybridize()来符号化,这时gluon就会试着符号化所有他的孩子。
hybridize也可以接受一些参数来调整performance:
net.hybridize(static_alloc=True) # or net.hybridize(static_alloc=True, static_shape=True)
Serializing trained model for deployment
作为HybridBlock,大多情况是可以很容易序列化的,序列化的模型可在以后用许多语言部署,C,C++和Scala。为此,利用export和SymbolBlock.imports来保存和载入:
# 保存
net(x) net.export('model', epoch=1)
此时将会生成两个文件:model-symbol.json and model-0001.params 。可用任何语言进行载入,当然也可用SymbolBlock进行载入:
import warnings with warnings.catch_warnings(): warnings.simplefilter("ignore") net2 = gluon.SymbolBlock.imports('model-symbol.json', ['data'], 'model-0001.params')
Operators that do not work with hybridize
如果想混合编程,必须在“hybrid_forward”函数中使用F.some_operator,说白了就是用一些特定的操作符。在hybridize之前F为mxnet.nd,之后就会变为mxnet.sym。虽然大多数api在NDArray和Symbol中是相同的,但它们之间存在一些差异。编写F.some_operator和调用hybrize可能不会一直工作。这里列出了一些常用的不能hybridize的NDArray api,并提供了解决方法。
Element-wise Operators
在NDArray api中,如果输入的NDArray具有不同的形状,则会自动广播以下算术和比较api。但是Symbol API不是这样的。它不会自动广播,必须手动指定对预期具有不同形状的符号使用另一组广播运算符。
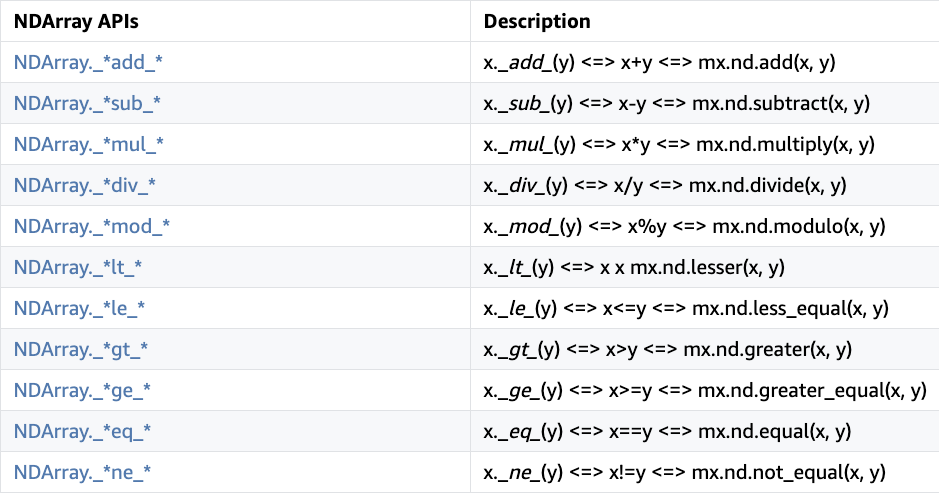
目前的解决方法是使用相应的广播运算符进行运算和比较,以避免在输入形状不同时可能出现的hybridize失败。

例如,如果想给你的输入加一个ndarray,那么应当利用broadcast_add而非 + :
def hybrid_forward(self, F, x): # avoid writing: return x + F.ones((1, 1)) return F.broadcast_add(x, F.ones((1, 1)))
如果用的是➕,那么在hubridize之前是没问题的,而之后就可能导致形状不匹配。
Shape
Gluon的命令式交互非常灵活,允许打印NDArray的形状。但是,symbol没有形状属性。因此要避免在hubrid_forward中打印shape。否则,将出现以下错误:
AttributeError: 'Symbol' object has no attribute 'shape'
Slice
NDArray中索引很正常,而Symbol中的索引【】是得到grouped symbol的输出。在hybrid前后会得到不同的输出:
def hybrid_forward(self, F, x): return x[0]
Not implemented operators
一些在NDArray中常用的operators并没有在Symbol中实现,可能会导致错误:
NDArray.asnumpy:symbol中没这个操作,在hybrid_forward中不要用这个。
mx.nd.array():symbol中没有array的API,目前只有F.ones, F.zeros, or F.full

 浙公网安备 33010602011771号
浙公网安备 33010602011771号