Symbol API
mxnet的python api主要有两个包:Gluon api和Module api。gluon api容易上手和debug,更加新手友好。因为gluon主要依赖NDArray包,属于交互式编程,类似于python的array。而Module api主要依赖于Symbol,由于需要构建symbol graph,是非交互式的,虽不易debug,但是换来了高性能。尽管性能好,但也有一些限制。所以可以利用gluon快速迭代实现,然后转到symbol来更快的训练和推理(当然限制在于可能你的实现symbol无法支持)。
所有模块的API:https://mxnet.apache.org/versions/1.5.0/api/python/index.html
Symbol and NDArray?
为何不利用已有的NDArray?NDArray可以像python一样交互式编程,Gluon就是基于NDArray,Gluon使用这种方法(在hybridization之前)允许灵活和可调试的网络。
MXNet提供了另一种符号式编程接口Symbol,需要先构建一个计算图,类似tensorflow,先建立placeholders用于输入和输出,然后编译这个计算图, 通过绑定到NDArrays后实现运行。Gluon也可以通过利用hybridization方法实现这种操作:在混合式编程中,可以通过使用HybridBlock类或者HybridSequential类构建模型。默认情况下,它们和Block类或者Sequential类一样依据命令式编程的方式执行。当调用hybridize函数后,Gluon会转换成依据符号式编程的方式执行。事实上,绝大多数模型都可以接受这样的混合式编程的执行方式。一个demo如下:
from mxnet import nd, sym from mxnet.gluon import nn import time def get_net(): net = nn.HybridSequential() # 这里创建HybridSequential实例 net.add(nn.Dense(256, activation='relu'), nn.Dense(128, activation='relu'), nn.Dense(2)) net.initialize() return net def benchmark(net, x): start = time.time() for i in range(1000): _ = net(x) nd.waitall() # 等待所有计算完成方便计时 return time.time() - start net = get_net() print('before hybridizing: %.4f sec' % (benchmark(net, x))) net.hybridize() print('after hybridizing: %.4f sec' % (benchmark(net, x)))
before hybridizing: 0.4831 sec
after hybridizing: 0.2670 sec
在模型net根据输入计算模型输出后,例如benchmark函数中的net(x),我们就可以通过export函数将符号式程序和模型参数保存到硬盘。
net.export('my_mlp')
此时生成的.json和.params文件分别为符号式程序和模型参数。它们可以被Python或MXNet支持的其他前端语言读取,如C++、R、Scala、Perl和其他语言。这样,我们就可以很方便地使用其他前端语言或在其他设备上部署训练好的模型。同时,由于部署时使用的是符号式程序,计算性能往往比命令式程序的性能更好。
在MXNet中,符号式程序指的是基于Symbol类型的程序。我们知道,当给net提供NDArray类型的输入x后,net(x)会根据x直接计算模型输出并返回结果。对于调用过hybridize函数后的模型,我们还可以给它输入一个Symbol类型的变量,net(x)会返回Symbol类型的结果。
x = sym.var('data') net(x)
<Symbol dense5_fwd>
Symbol - Neural network graphs
symbol方法的另一个优点是,我们可以在使用函数之前对其进行优化。例如,当我们以命令式的方式执行数学计算时,我们不知道何时运行每个操作,稍后需要哪些值。但是在符号编程中,我们提前声明所需的输出。这意味着我们可以循环使用在中间步骤中分配的内存,比如执行适当的操作。Symbol API还为同一网络使用较少的内存。
Basic Symbol Composition
Basic Operators
symbol基本操作和ndarray很类似,例如:
import mxnet as mx a = mx.sym.Variable('a') b = mx.sym.Variable('b') c = a + b (a, b, c)
# elemental wise multiplication d = a * b # matrix multiplication e = mx.sym.dot(a, b) # reshape f = mx.sym.reshape(d+e, shape=(1,4)) # broadcast g = mx.sym.broadcast_to(f, shape=(2,4)) # plot mx.viz.plot_network(symbol=g, node_attrs={"shape":"oval","fixedsize":"false"})
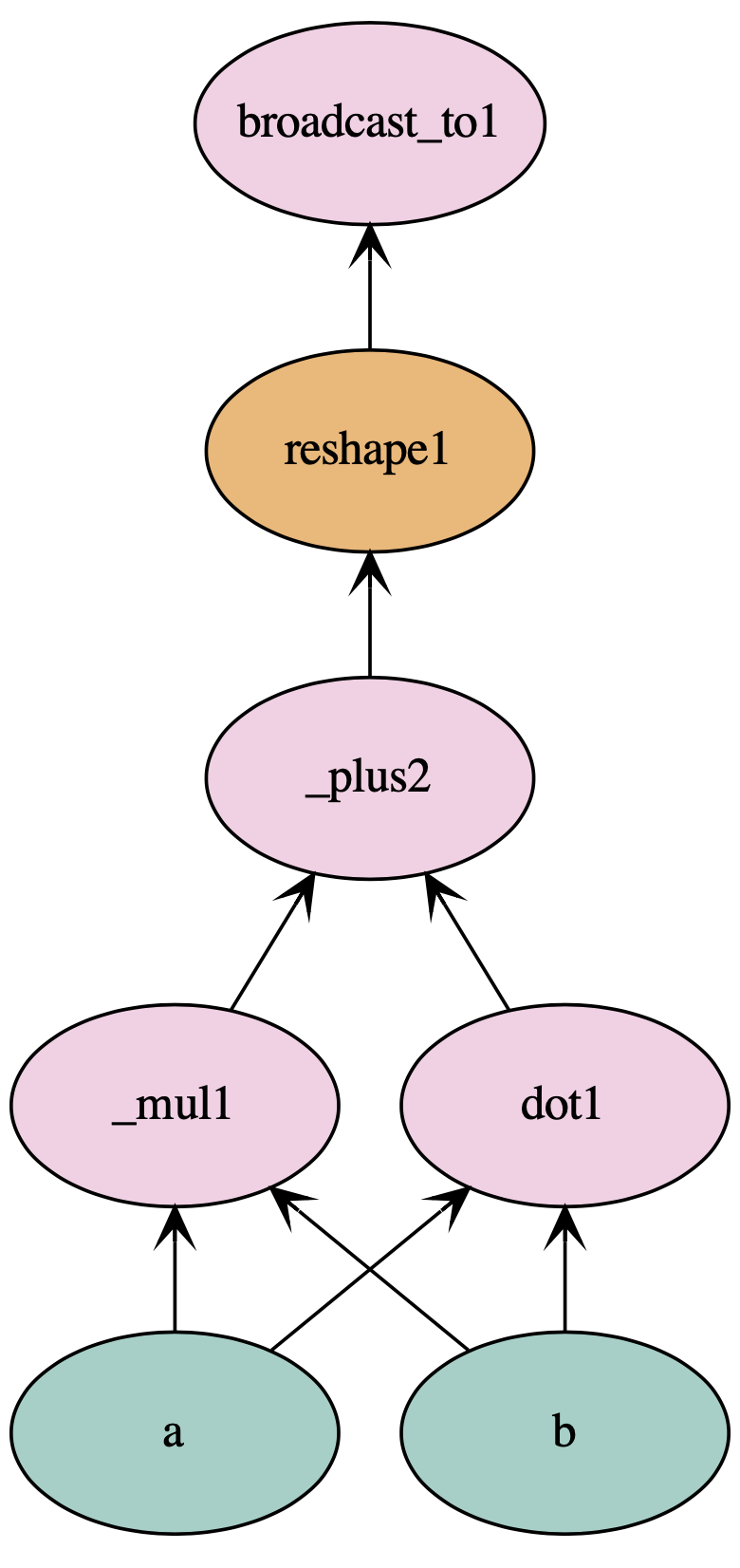
可以看到整个流程被打印出来了,值得注意的是c=a+b其实并没有在这个流程里,因为最后的g并没有依赖c,所以实际上会减少不必要的计算。 而Gluon交互式处理则会step-by-step的执行,从而降低了效率。构建好symbol之后就可以输入ndarray数据来打通训练流程,这个过程通过bind方法实现。
Basic Neural Networks
除了上面的基本操作,还支持大量的神经网络层,下面的例子:
net = mx.sym.Variable('data') net = mx.sym.FullyConnected(data=net, name='fc1', num_hidden=128) net = mx.sym.Activation(data=net, name='relu1', act_type="relu") net = mx.sym.FullyConnected(data=net, name='fc2', num_hidden=10) net = mx.sym.SoftmaxOutput(data=net, name='out') mx.viz.plot_network(net, shape={'data':(100,200)}, node_attrs={"shape":"oval","fixedsize":"false"})
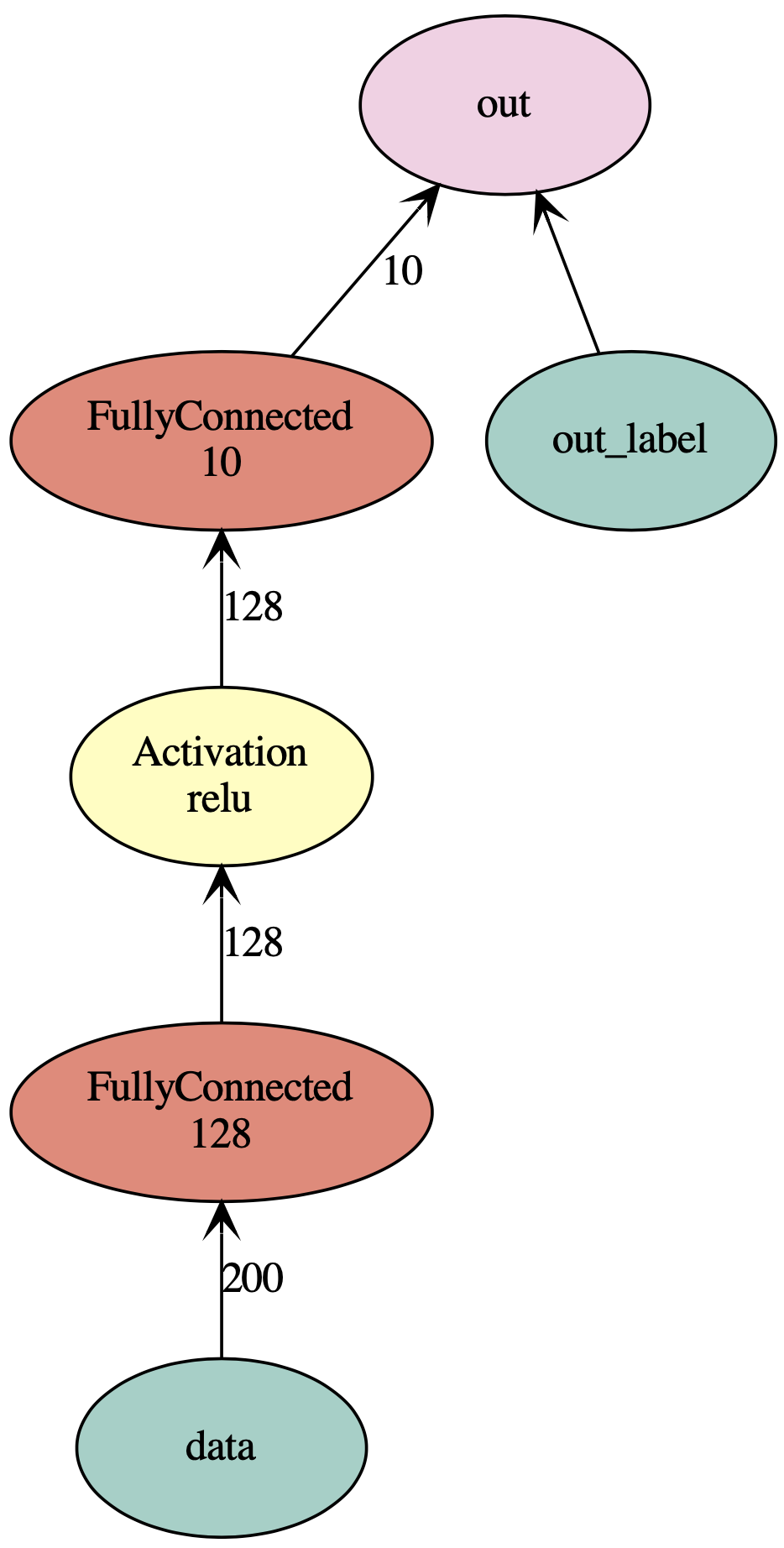
查看参数:
net.list_arguments()
['data', 'fc1_weight', 'fc1_bias', 'fc2_weight', 'fc2_bias', 'out_label']
这些参数的名字也可指定:
net = mx.symbol.Variable('data') w = mx.symbol.Variable('myweight') net = mx.symbol.FullyConnected(data=net, weight=w, name='fc1', num_hidden=128) net.list_arguments()
['data', 'myweight', 'fc1_bias']
可以看到权值的名字已经变了。
More Complicated Composition
更复杂的一些操作:
lhs = mx.symbol.Variable('data1') rhs = mx.symbol.Variable('data2') net = mx.symbol.FullyConnected(data=lhs + rhs, name='fc1', num_hidden=128) net.list_arguments()
['data1', 'data2', 'fc1_weight', 'fc1_bias']
还可以以比前面示例中描述的单个前向合成更灵活的方式构造symbol:
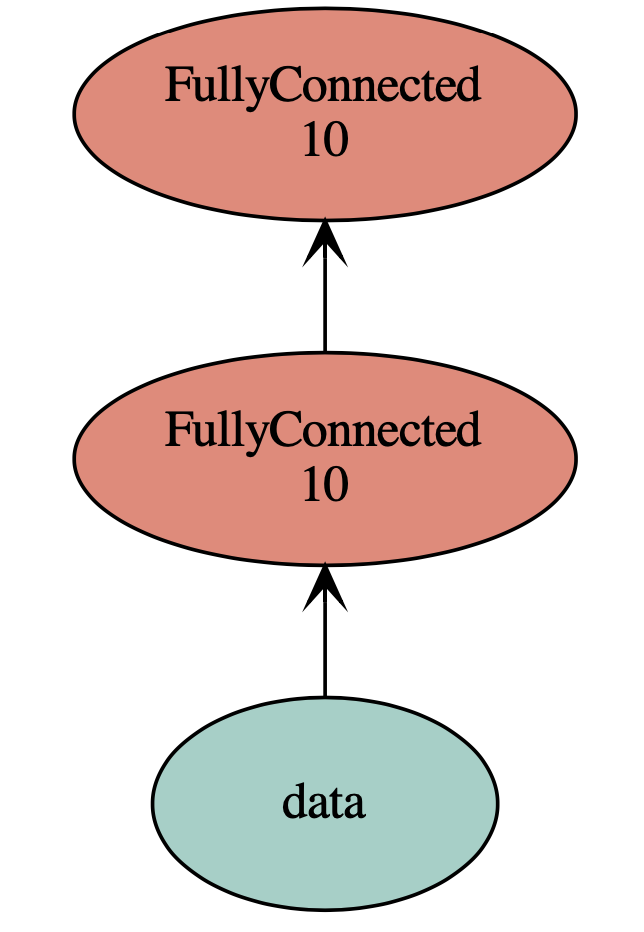
data = mx.symbol.Variable('data') net1 = mx.symbol.FullyConnected(data=data, name='fc1', num_hidden=10) net1.list_arguments() net2 = mx.symbol.Variable('data2') net2 = mx.symbol.FullyConnected(data=net2, name='fc2', num_hidden=10) composed = net2(data2=net1, name='composed') composed.list_arguments()
['data', 'fc1_weight', 'fc1_bias', 'fc2_weight', 'fc2_bias']
上面的net2作为一个函数,将其输入变成为net1,所以是个连接的两个fc层:
网络图:
当构建大网络实可以弄个命名空间来管理:
data = mx.sym.Variable("data") net = data n_layer = 2 for i in range(n_layer): with mx.name.Prefix("layer%d_" % (i + 1)): net = mx.sym.FullyConnected(data=net, name="fc", num_hidden=100) net.list_arguments()
['data', 'layer1_fc_weight', 'layer1_fc_bias', 'layer2_fc_weight', 'layer2_fc_bias']
Modularized Construction for Deep Networks
模块化构建复杂网络:对于谷歌inception网络,可以先构建一个工厂卷积函数:包含卷积、正则、激活等
def ConvFactory(data, num_filter, kernel, stride=(1,1), pad=(0, 0),name=None, suffix=''): conv = mx.sym.Convolution(data=data, num_filter=num_filter, kernel=kernel, stride=stride, pad=pad, name='conv_%s%s' %(name, suffix)) bn = mx.sym.BatchNorm(data=conv, name='bn_%s%s' %(name, suffix)) act = mx.sym.Activation(data=bn, act_type='relu', name='relu_%s%s' %(name, suffix)) return act prev = mx.sym.Variable(name="Previous Output") conv_comp = ConvFactory(data=prev, num_filter=64, kernel=(7,7), stride=(2, 2)) shape = {"Previous Output" : (128, 3, 28, 28)} mx.viz.plot_network(symbol=conv_comp, shape=shape, node_attrs={"shape":"oval","fixedsize":"false"})
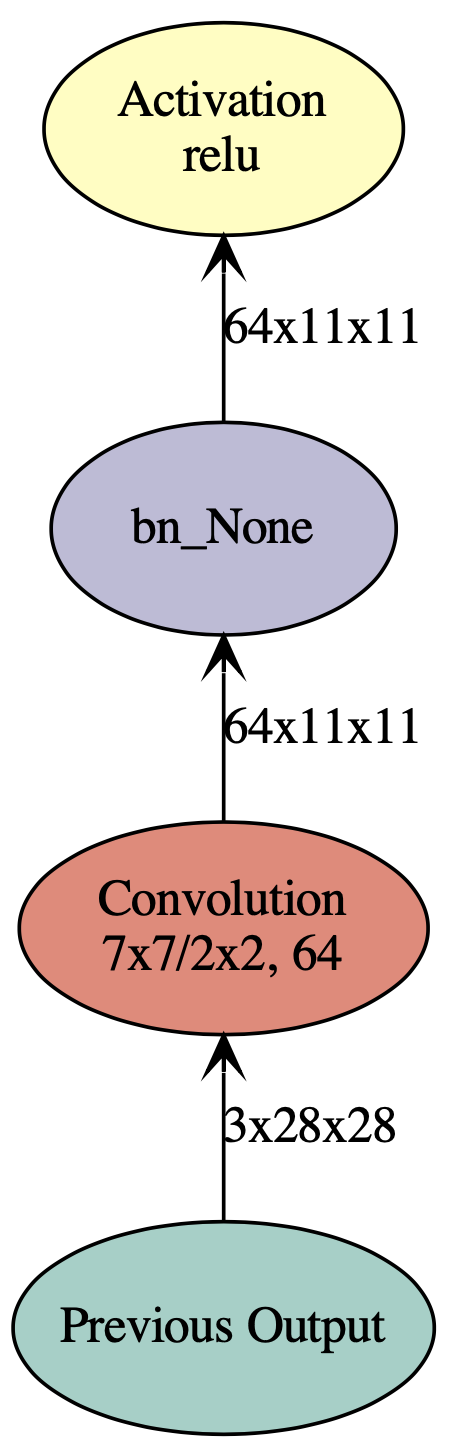
然后可以构建整个网络:
def InceptionFactoryA(data, num_1x1, num_3x3red, num_3x3, num_d3x3red, num_d3x3, pool, proj, name): # 1x1 c1x1 = ConvFactory(data=data, num_filter=num_1x1, kernel=(1, 1), name=('%s_1x1' % name)) # 3x3 reduce + 3x3 c3x3r = ConvFactory(data=data, num_filter=num_3x3red, kernel=(1, 1), name=('%s_3x3' % name), suffix='_reduce') c3x3 = ConvFactory(data=c3x3r, num_filter=num_3x3, kernel=(3, 3), pad=(1, 1), name=('%s_3x3' % name)) # double 3x3 reduce + double 3x3 cd3x3r = ConvFactory(data=data, num_filter=num_d3x3red, kernel=(1, 1), name=('%s_double_3x3' % name), suffix='_reduce') cd3x3 = ConvFactory(data=cd3x3r, num_filter=num_d3x3, kernel=(3, 3), pad=(1, 1), name=('%s_double_3x3_0' % name)) cd3x3 = ConvFactory(data=cd3x3, num_filter=num_d3x3, kernel=(3, 3), pad=(1, 1), name=('%s_double_3x3_1' % name)) # pool + proj pooling = mx.sym.Pooling(data=data, kernel=(3, 3), stride=(1, 1), pad=(1, 1), pool_type=pool, name=('%s_pool_%s_pool' % (pool, name))) cproj = ConvFactory(data=pooling, num_filter=proj, kernel=(1, 1), name=('%s_proj' % name)) # concat concat = mx.sym.Concat(*[c1x1, c3x3, cd3x3, cproj], name='ch_concat_%s_chconcat' % name) return concat prev = mx.sym.Variable(name="Previous Output") in3a = InceptionFactoryA(prev, 64, 64, 64, 64, 96, "avg", 32, name="in3a") mx.viz.plot_network(symbol=in3a, shape=shape, node_attrs={"shape":"oval","fixedsize":"false"})
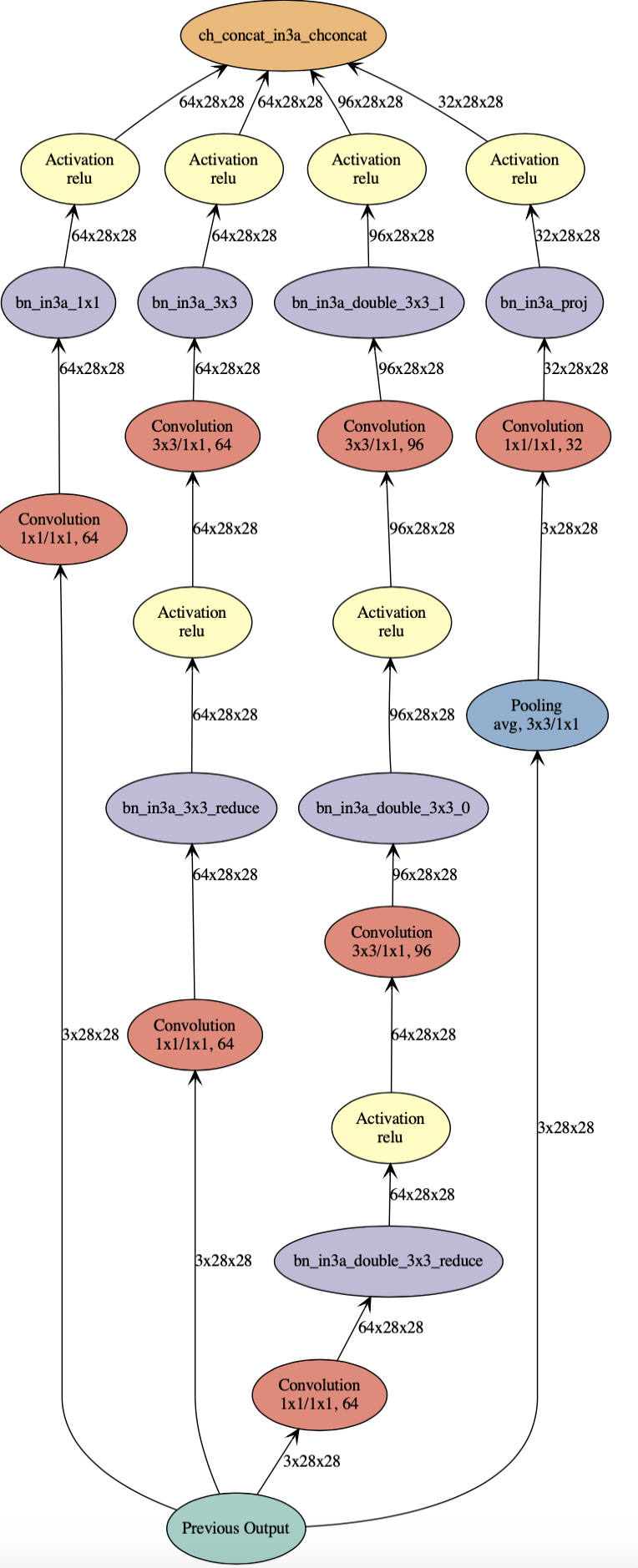
Group Multiple Symbols
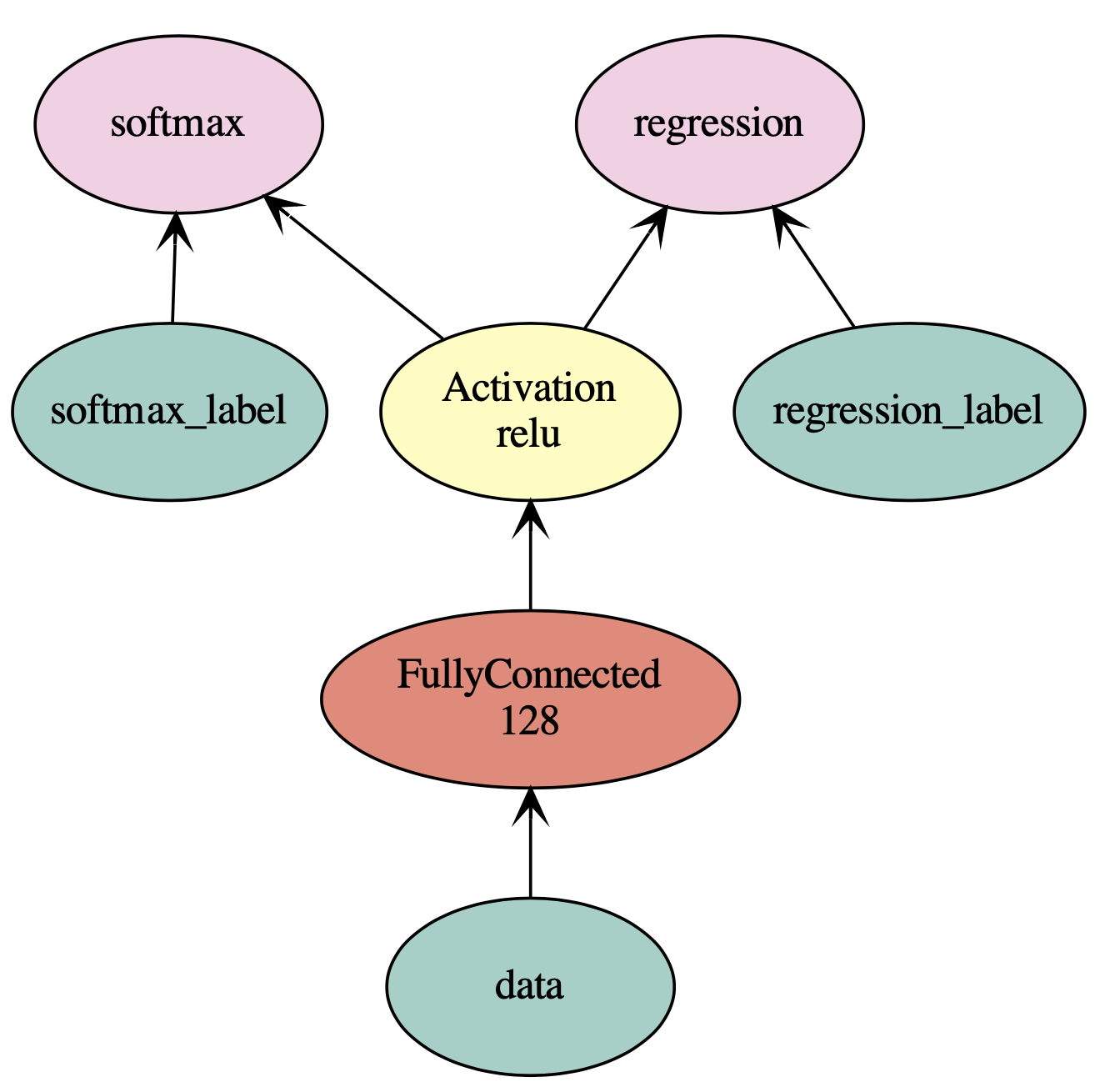
要构造具有多个loss层的神经网络,可以使用mxnet.sym.Group将多个symbol组合在一起。以下示例将两个输出分组:
net = mx.sym.Variable('data') fc1 = mx.sym.FullyConnected(data=net, name='fc1', num_hidden=128) net = mx.sym.Activation(data=fc1, name='relu1', act_type="relu") out1 = mx.sym.SoftmaxOutput(data=net, name='softmax') out2 = mx.sym.LinearRegressionOutput(data=net, name='regression') group = mx.sym.Group([out1, out2]) group.list_outputs()
['softmax_output', 'regression_output']
Relations to NDArray
The pros for NDArray:
- Straightforward.
- Easy to work with native language features (for loop, if-else condition, ..) and libraries (numpy, ..).
- Easy step-by-step code debugging.
The pros for Symbol:
- Provides almost all functionalities of NDArray, such as
+,*,sin,reshapeetc. - Easy to save, load and visualize.
- Easy for the backend to optimize the computation and memory usage.
Symbol Manipulation
symbol和NDArray的一个主要区别是Symbol先声明计算,然后利用数据建立(bind)计算并run。在本节中,我们将介绍直接操作symbol的函数。其中大多数是被高阶包给打包了:Module和Gluon。
Shape and Type Inference
对于每个symbol,我们可以查询其参数、辅助状态和输出。我们还可以根据已知的输入形状或某些参数的类型推断出符号的输出形状和类型,这有助于内存分配。
arg_name = c.list_arguments() # get the names of the inputs out_name = c.list_outputs() # get the names of the outputs # infers output shape given the shape of input arguments arg_shape, out_shape, _ = c.infer_shape(a=(2,3), b=(2,3)) # infers output type given the type of input arguments arg_type, out_type, _ = c.infer_type(a='float32', b='float32') {'input' : dict(zip(arg_name, arg_shape)), 'output' : dict(zip(out_name, out_shape))} {'input' : dict(zip(arg_name, arg_type)), 'output' : dict(zip(out_name, out_type))}
Bind with Data and Evaluate
给symbol输入数据,并实现评估。上面定义的symbol c已经声明了计算流程,为了评估,首先需要给参数,也就是自由变量喂入数据。
通过bind方法可以实现这个过程,bind方法接受 device_context和一个字典:映射自由变量到NDArray。bind方法返回一个执行器executor,这个执行器提供了前向传播forward方法以实现评估,也提供了outputs属性来得到所有的结果。
ex = c.bind(ctx=mx.cpu(), args={'a' : mx.nd.ones([2,3]),
'b' : mx.nd.ones([2,3])})
ex.forward()
print('number of outputs = %d\nthe first output = \n%s' % (
len(ex.outputs), ex.outputs[0].asnumpy()))
number of outputs = 1 the first output = [[2. 2. 2.] [2. 2. 2.]]
可以在GPU上用不同的数据来评估symbol:
gpu_device=mx.gpu() # Change this to mx.cpu() in absence of GPUs. ex_gpu = c.bind(ctx=gpu_device, args={'a' : mx.nd.ones([3,4], gpu_device)*2, 'b' : mx.nd.ones([3,4], gpu_device)*3}) ex_gpu.forward() ex_gpu.outputs[0].asnumpy()
也可以利用eval方法来评估symbol,eval方法相当于结合了bind和forward方法:
ex = c.eval(ctx = mx.cpu(), a = mx.nd.ones([2,3]), b = mx.nd.ones([2,3])) print('number of outputs = %d\nthe first output = \n%s' % ( len(ex), ex[0].asnumpy()))
对于神经网络,更常用的模式是simple_bind,创建所有的参数arrays。然后可以调用forward,backward来得到梯度。
Load and Save
逻辑上,Symbol对应于NDarray。它们都代表一个张量。它们都是操作于输入/输出。我们可以使用pickle序列化Symbol对象,也可以直接使用保存和加载方法,正如NDArray教程中讨论的那样。
在序列化NDArray时,我们序列化其中的张量数据,并以二进制格式直接转储到磁盘。但Symbol使用的是graph的概念。图是由链式算子组成的。它们由输出符号隐式表示。所以,当序列化一个符号时,我们序列化graph。序列化时,Symbol使用更可读的json格式进行序列化。要将符号转换为json字符串,使用tojson方法。
print(c.tojson()) c.save('symbol-c.json') c2 = mx.sym.load('symbol-c.json') c.tojson() == c2.tojson()
Advanced Usages
Type Cast
默认情况下,MXNet使用32位浮点。但为了获得更好的精度性能,我们也可以使用精度较低的数据类型。例如,Nvidia Tesla Pascal gpu(例如P100)改进了16位浮点性能,而GTX Pascal gpu(例如GTX 1080)在8位整数上速度很快。
要根据需要转换数据类型,可以使用mx.sym.cast:
a = mx.sym.Variable('data') b = mx.sym.cast(data=a, dtype='float16') arg, out, _ = b.infer_type(data='float32') print({'input':arg, 'output':out}) c = mx.sym.cast(data=a, dtype='uint8') arg, out, _ = c.infer_type(data='int32') print({'input':arg, 'output':out})
Variable Sharing
要在多个symbol之间共享context,可以将这些符号与同一数组绑定,如下所示:
a = mx.sym.Variable('a') b = mx.sym.Variable('b') b = a + a * a data = mx.nd.ones((2,3))*2 ex = b.bind(ctx=mx.cpu(), args={'a':data, 'b':data}) ex.forward() ex.outputs[0].asnumpy()
Symbol 可视化
1. 可视化结构图,生成一个pdf 文件,以图片形式展示出网络结构:
mx.viz.plot_network(sym, shape={"data":(1, 1, 32, 32)}).view()
其中的(1, 1, 32, 32)是输入的维度,即shape:(bs,c,h,w)
2. 打印输出层维度: 例如这里载入resnet18权重后打印出来,包括每一层的输出和参数以及前一层信息。
sym, arg_params, aux_params = mx.model.load_checkpoint('/Users/bytedance/Downloads/resnet-18', 0) mx.viz.print_summary(sym)
________________________________________________________________________________________________________________________ Layer (type) Output Shape Param # Previous Layer ======================================================================================================================== data(null) 3x224x224 0 ________________________________________________________________________________________________________________________ bn_data(BatchNorm) 3x224x224 6 data ________________________________________________________________________________________________________________________ conv0(Convolution) 64x112x112 9408 bn_data ________________________________________________________________________________________________________________________ bn0(BatchNorm) 64x112x112 128 conv0 ________________________________________________________________________________________________________________________ relu0(Activation) 64x112x112 0 bn0 ________________________________________________________________________________________________________________________ pooling0(Pooling) 64x56x56 0 relu0 ________________________________________________________________________________________________________________________ stage1_unit1_bn1(BatchNorm) 64x56x56 128 pooling0 ________________________________________________________________________________________________________________________ stage1_unit1_relu1(Activation) 64x56x56 0 stage1_unit1_bn1 ________________________________________________________________________________________________________________________ stage1_unit1_conv1(Convolution) 64x56x56 36864 stage1_unit1_relu1 ________________________________________________________________________________________________________________________ stage1_unit1_bn2(BatchNorm) 64x56x56 128 stage1_unit1_conv1 ________________________________________________________________________________________________________________________ stage1_unit1_relu2(Activation) 64x56x56 0 stage1_unit1_bn2 ________________________________________________________________________________________________________________________ stage1_unit1_conv2(Convolution) 64x56x56 36864 stage1_unit1_relu2 ________________________________________________________________________________________________________________________ stage1_unit1_sc(Convolution) 64x56x56 4096 stage1_unit1_relu1 ________________________________________________________________________________________________________________________ _plus0(elemwise_add) 64x56x56 0 stage1_unit1_conv2 stage1_unit1_sc ________________________________________________________________________________________________________________________ stage1_unit2_bn1(BatchNorm) 64x56x56 128 _plus0 ________________________________________________________________________________________________________________________ stage1_unit2_relu1(Activation) 64x56x56 0 stage1_unit2_bn1 ________________________________________________________________________________________________________________________ stage1_unit2_conv1(Convolution) 64x56x56 36864 stage1_unit2_relu1 ________________________________________________________________________________________________________________________ stage1_unit2_bn2(BatchNorm) 64x56x56 128 stage1_unit2_conv1 ________________________________________________________________________________________________________________________ stage1_unit2_relu2(Activation) 64x56x56 0 stage1_unit2_bn2 ________________________________________________________________________________________________________________________ stage1_unit2_conv2(Convolution) 64x56x56 36864 stage1_unit2_relu2 ________________________________________________________________________________________________________________________ _plus1(elemwise_add) 64x56x56 0 stage1_unit2_conv2 _plus0 ________________________________________________________________________________________________________________________ stage2_unit1_bn1(BatchNorm) 64x56x56 128 _plus1 ________________________________________________________________________________________________________________________ stage2_unit1_relu1(Activation) 64x56x56 0 stage2_unit1_bn1 ________________________________________________________________________________________________________________________ stage2_unit1_conv1(Convolution) 128x28x28 73728 stage2_unit1_relu1 ________________________________________________________________________________________________________________________ stage2_unit1_bn2(BatchNorm) 128x28x28 256 stage2_unit1_conv1 ________________________________________________________________________________________________________________________ stage2_unit1_relu2(Activation) 128x28x28 0 stage2_unit1_bn2 ________________________________________________________________________________________________________________________ stage2_unit1_conv2(Convolution) 128x28x28 147456 stage2_unit1_relu2 ________________________________________________________________________________________________________________________ stage2_unit1_sc(Convolution) 128x28x28 8192 stage2_unit1_relu1 ________________________________________________________________________________________________________________________ _plus2(elemwise_add) 128x28x28 0 stage2_unit1_conv2 stage2_unit1_sc ________________________________________________________________________________________________________________________ stage2_unit2_bn1(BatchNorm) 128x28x28 256 _plus2 ________________________________________________________________________________________________________________________ stage2_unit2_relu1(Activation) 128x28x28 0 stage2_unit2_bn1 ________________________________________________________________________________________________________________________ stage2_unit2_conv1(Convolution) 128x28x28 147456 stage2_unit2_relu1 ________________________________________________________________________________________________________________________ stage2_unit2_bn2(BatchNorm) 128x28x28 256 stage2_unit2_conv1 ________________________________________________________________________________________________________________________ stage2_unit2_relu2(Activation) 128x28x28 0 stage2_unit2_bn2 ________________________________________________________________________________________________________________________ stage2_unit2_conv2(Convolution) 128x28x28 147456 stage2_unit2_relu2 ________________________________________________________________________________________________________________________ _plus3(elemwise_add) 128x28x28 0 stage2_unit2_conv2 _plus2 ________________________________________________________________________________________________________________________ stage3_unit1_bn1(BatchNorm) 128x28x28 256 _plus3 ________________________________________________________________________________________________________________________ stage3_unit1_relu1(Activation) 128x28x28 0 stage3_unit1_bn1 ________________________________________________________________________________________________________________________ stage3_unit1_conv1(Convolution) 256x14x14 294912 stage3_unit1_relu1 ________________________________________________________________________________________________________________________ stage3_unit1_bn2(BatchNorm) 256x14x14 512 stage3_unit1_conv1 ________________________________________________________________________________________________________________________ stage3_unit1_relu2(Activation) 256x14x14 0 stage3_unit1_bn2 ________________________________________________________________________________________________________________________ stage3_unit1_conv2(Convolution) 256x14x14 589824 stage3_unit1_relu2 ________________________________________________________________________________________________________________________ stage3_unit1_sc(Convolution) 256x14x14 32768 stage3_unit1_relu1 ________________________________________________________________________________________________________________________ _plus4(elemwise_add) 256x14x14 0 stage3_unit1_conv2 stage3_unit1_sc ________________________________________________________________________________________________________________________ stage3_unit2_bn1(BatchNorm) 256x14x14 512 _plus4 ________________________________________________________________________________________________________________________ stage3_unit2_relu1(Activation) 256x14x14 0 stage3_unit2_bn1 ________________________________________________________________________________________________________________________ stage3_unit2_conv1(Convolution) 256x14x14 589824 stage3_unit2_relu1 ________________________________________________________________________________________________________________________ stage3_unit2_bn2(BatchNorm) 256x14x14 512 stage3_unit2_conv1 ________________________________________________________________________________________________________________________ stage3_unit2_relu2(Activation) 256x14x14 0 stage3_unit2_bn2 ________________________________________________________________________________________________________________________ stage3_unit2_conv2(Convolution) 256x14x14 589824 stage3_unit2_relu2 ________________________________________________________________________________________________________________________ _plus5(elemwise_add) 256x14x14 0 stage3_unit2_conv2 _plus4 ________________________________________________________________________________________________________________________ stage4_unit1_bn1(BatchNorm) 256x14x14 512 _plus5 ________________________________________________________________________________________________________________________ stage4_unit1_relu1(Activation) 256x14x14 0 stage4_unit1_bn1 ________________________________________________________________________________________________________________________ stage4_unit1_conv1(Convolution) 512x7x7 1179648 stage4_unit1_relu1 ________________________________________________________________________________________________________________________ stage4_unit1_bn2(BatchNorm) 512x7x7 1024 stage4_unit1_conv1 ________________________________________________________________________________________________________________________ stage4_unit1_relu2(Activation) 512x7x7 0 stage4_unit1_bn2 ________________________________________________________________________________________________________________________ stage4_unit1_conv2(Convolution) 512x7x7 2359296 stage4_unit1_relu2 ________________________________________________________________________________________________________________________ stage4_unit1_sc(Convolution) 512x7x7 131072 stage4_unit1_relu1 ________________________________________________________________________________________________________________________ _plus6(elemwise_add) 512x7x7 0 stage4_unit1_conv2 stage4_unit1_sc ________________________________________________________________________________________________________________________ stage4_unit2_bn1(BatchNorm) 512x7x7 1024 _plus6 ________________________________________________________________________________________________________________________ stage4_unit2_relu1(Activation) 512x7x7 0 stage4_unit2_bn1 ________________________________________________________________________________________________________________________ stage4_unit2_conv1(Convolution) 512x7x7 2359296 stage4_unit2_relu1 ________________________________________________________________________________________________________________________ stage4_unit2_bn2(BatchNorm) 512x7x7 1024 stage4_unit2_conv1 ________________________________________________________________________________________________________________________ stage4_unit2_relu2(Activation) 512x7x7 0 stage4_unit2_bn2 ________________________________________________________________________________________________________________________ stage4_unit2_conv2(Convolution) 512x7x7 2359296 stage4_unit2_relu2 ________________________________________________________________________________________________________________________ _plus7(elemwise_add) 512x7x7 0 stage4_unit2_conv2 _plus6 ________________________________________________________________________________________________________________________ bn1(BatchNorm) 512x7x7 1024 _plus7 ________________________________________________________________________________________________________________________ relu1(Activation) 512x7x7 0 bn1 ________________________________________________________________________________________________________________________ pool1(Pooling) 512x1x1 0 relu1 ________________________________________________________________________________________________________________________ flatten0(Flatten) 512 0 pool1 ________________________________________________________________________________________________________________________ fc1(FullyConnected) 1000 513000 flatten0 ________________________________________________________________________________________________________________________ softmax(SoftmaxOutput) 1000 0 fc1 ======================================================================================================================== Total params: 11691950 ________________________________________________________________________________________________________________________
3. 对于Gluon中HybridSequential类的输出维度打印:
mx.viz.print_summary( net(mx.sym.var('data')), shape={'data':(1,3,224,224)}, #set your shape here )

 浙公网安备 33010602011771号
浙公网安备 33010602011771号