(转载)基于比较的少样本(one/few-shoting)分类
基于比较的方法
先通过CNN得到目标特征,然后与参考目标的特征进行比较. 不同在于比较的方法不同而已.
基本概念
- 数据集Omniglot:50种alphabets(文字或者文明); alphabet中15-40 characters(字母); 每个字母有20drawers(20个不同的人写的).
- 每次迭代叫mini_batch或者epsiode.
- N-ways指的是有多个类别,N-shot是指于多少个目标进行比较取均值中的最高值作为最后的结果.
- 测试集与训练集中样本的类别不一样.
- cosine(余弦)距离:
- 归纳偏置(inductive bias): 单靠数据本身不足以找到唯一的解, 因为我们需要做一些特别且合理的假设, 以便我们能得到唯一的解.
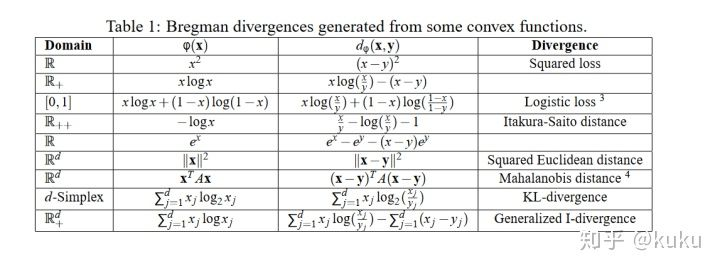
- Bregman divergence(散度): 如果你抽象地定义一种在特定空间里两个点之间的"距离", 然后在这些点满足任意的概率的情况下,这些点的平均值点一定是空间距离这些点的平均距离最小的点.
.可以通过求和再求导的方式得出上述结论(从上面也可以看出距离函数是非负的凸函数).下图展示了满足其性质的距离公式:
Siamese Neural Networks
模型可以分解成特征提取器和比较器:其中特征提取器中的权重是共享.如下图所示:

一路是support(已经知道到标签), 一路是query.比较两者的相似度.(直接相减取绝对值,然后接sigmoid激活,再接全连接层和sigmoid,表示相似程度)
训练
每次迭代从训练集中随机的选择20个类, 从每个类中的20个样本采样5个作为support set, 5个作为query set. 选取的个数影响batch_size的大小. 从上面选取的样本中组成一个mini_batch(输入是成对出现的),一半是相同class,一半是不同类别.同时batch_size也收到硬件的限制,一般取32.
测试
从测试集中随机选取m个类,每个类提供k个样本作为support Set.这就是N-way k-shot.每个query与 个样本进行比较,得到相似分数,然后同类取平均值, 找出类别最高的分数即为这个query的类别.
分析与思考
- 把问题从推理问题变成了判断问题,极大了降低了问题的复杂度.
- 与常规深度学习分类模型不一样, 这里网络学习的是一种比较能力,比较器和特征提取器相辅相成,提高最终性能.而常规学习的是类别具有的特征分布;所以常规模型可以进行很好的迁移,具有很好的语义提取能力.但是这里的模型不能很好的迁移(不一定能具有).
- 我们可以发现,其实训练模型数据并不少,能够组成上千万个不同的batch. 所以从这一点来说, 深度学习依旧是需要很多数据,只不过数据的角度不一样.
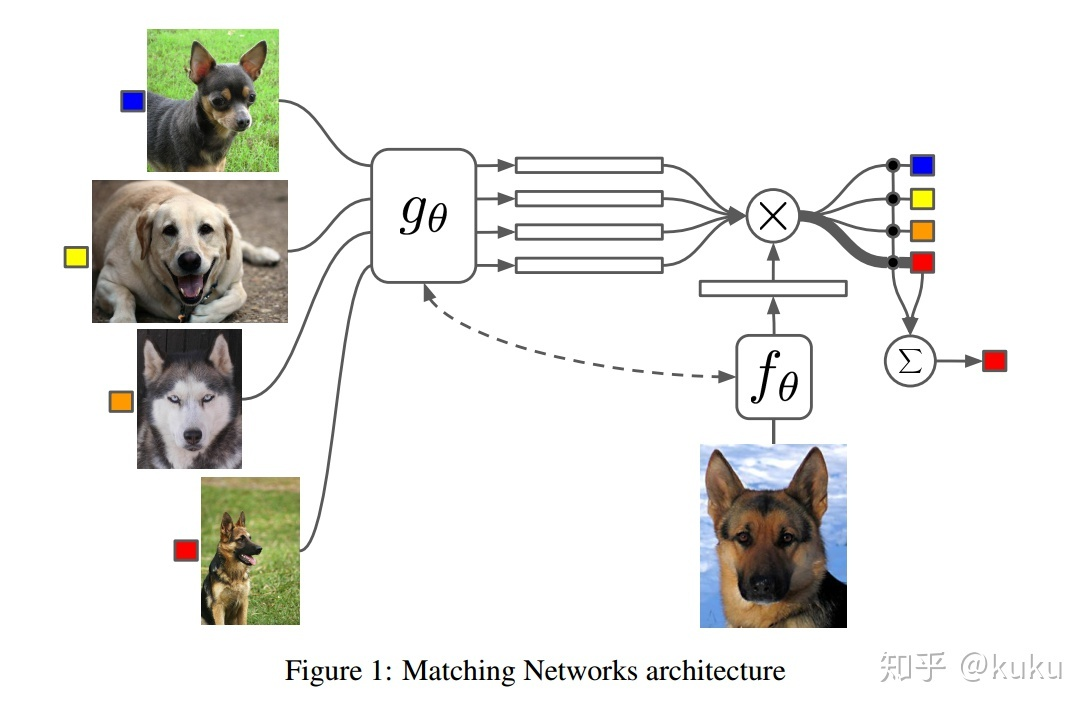
Matching Networks
基本思想
在编码中引入set和注意力的概念, 将所有类别的编码当做一个整体看待,这样可以增强类间差异.同时作者也对训练过程进行的改进, 同时保证了传统机器学习的一个原则, 即训练和测试集要在同样的条件下进行的, 学习的目标由 变成
.最终是一个权重式的最邻近分类器.
步骤
1. 对支持集和测试集的样本进行encode,函数分为 ,得到
,
代表的query样本,
代表的是支持集里面的样本. 图中的虚线表示的是这两部分编码是可以共享的.
2. 再对 的编码进一步处理,处理方法是基于双向的LSTM对support set进行整体embedding(full Context Embedding):
通过如上的编码我们可以发现support set的样本编码产生了相互影响的效果,从而更有利于区分出类别之间的差异.对相似却不同的类别的编码具有好处.
3. 基于attention-LSTM来对测试样本embedding:
计算询问样本特征与support set的特征相似性. 具体计算如下:
根据相似性来计算得到reuse的特征
需要注意的是K是可以随便定的, 最终的 即为最终测试样本的编码.分析可以这里的过程可以理解为一个可学习的加强特征器, 用于加强那些与support set相似但是不明显的特征(如果某个样本的特征与support set中某个样本稍微相似,但是不足以判定类别, 这里就会循环向原始特征中加入能够增强其判别的信息).
4. 得到 的编码后,利用下式得到最终的结果.
其中a的表达式如下:
需要说明的是上式中的 一个N-way大小的向量(一般是one-hot),如果是K-shot,编码处也会发生变化,同时取的是最终y值最大对应的标签.
训练
选择少数几个类别(5类),在每个类别中选择少量的样本(5个),将选出的集合划分成参考集和测试集,利用本次迭代的参考集,计算测试集的误差,计算梯度,更新参数.这样的一个流程称为episode.与孪生网络不同,在一次计算中可以直接得到最终的label, 但是基于比较的思想没有变化.
测试
步骤与训练一样,只是不再更新梯度,同时计算正确率.
Prototypical Network
基本思想
加入适当且合适的偏置归纳,来减轻或者消除过拟合问题.这里的假设是存在一个特征空间使得对于每一类都有一个point cluster围绕一个单一的prototype representation. 分类问题就变成寻找最近原型的问题.对每个类而言模型也可以看成是一个线性模型.
基本步骤
1.计算原型表达
其中 代表的是第k类原型表达,
代表的是support set中第k类的集合.
2. 在类别维度上归一化距离,得到类别标签
训练
- 从K个类内中均匀选择
个类别,(
指的是一个episode的类别数)
- 在从数据集中选择相应类别分别选取
个样本作为support set.
- 再在剩下的数据集中选取
个样本作为测试样本.
- 接下来按照上面的步骤,计算出测试样本的概率和误差,然后利用SGD进行优化.
补充
- 可以将原型模型的解释为线性模型:
- 然后在经过softmax处理,但是我们可以看到第一项在每一类中都有,所以可以在分子分母中约掉.而剩下的则变成:
如果只从分类器的角度看,当问题是one-shot时,matchnet和当前模型等效.
Relation Network for few-shot learning
前文说网络学习的是比较能力,主要是体现在对特征的学习和约束上(这些特征容易通过线性或者最最近邻的方法进行区分),这里将其延伸至比较器,比较方式也是通过网络自己来学习,而不是人工指定,这也符合我们一贯的认识,能让网络做的, 尽量让网络去做. 自己学习了一个非线性比较器.在zero-shot learning中,relation module是学习比较query图像和描述之间关系.
模型
- 首先是一个embedding module将query和support的照片进行编码.
- 然后是一个relation module用来进行比较,算出得分.
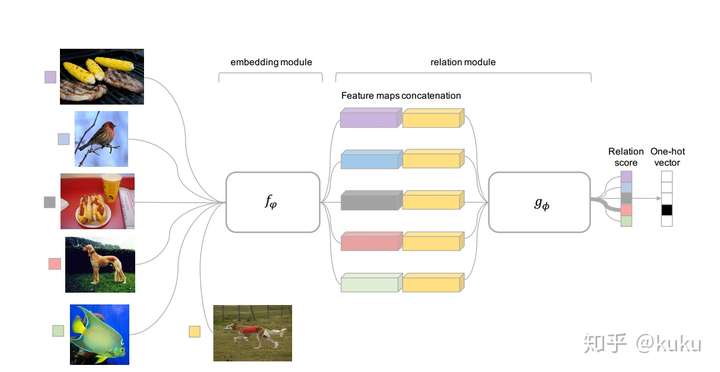
relation module
上面公式输出的是一个在[0,1]之间的值,作者使用的是如下结构来表示 :
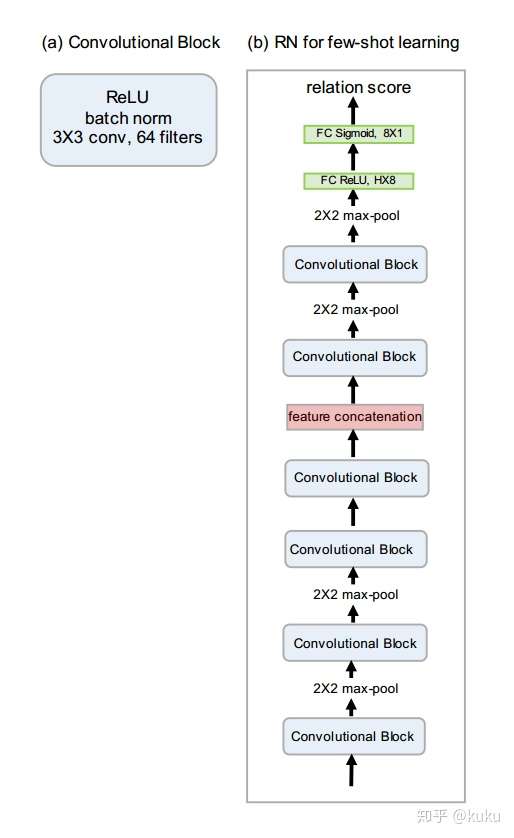
通过上面的公式我们可以看出,不同参考样本连接query样本特征之后在relation module中的权重是共享的,所以在实现的时候,维度变化如下C((S,H,W,D), (Q,H,W,D))-->(Q*S, H,W, D) 然后做卷积,再reshape.需要注意的是作者在K-shot,是将support中相同类别的图像特征相加后,然后于query的特征相连接,这样又变成了上述的one-shot问题.
转载于:
知乎:基于比较的少样本(one/few-shoting)分类
注: 5way1shot是指:测试集有5类,每类只有1张是有标记样本,其余样本都是无标记的。我们需要根据用已有的训练样本(训练样本比较理想,就是类别数很多,都有标签等)来模仿测试过程。具体而言,就拿5way1shot来说(假设训练集有1000类,都有大量有标签数据),每次,我的训练样本是随机选5类,每类选1张图,这5张图经过网络得到5个特征向量,然后怎么计算loss?我需要从这5类里面每类再挑出一些样本也经过网络得到他们的特征向量,然后去和之前那5个向量计算距离(relation),希望他们同一类的距离尽可能小。这样的话,我的网络其实就是学的是relation,而不是简单的分类。那测试的时候,我把有标签的这5张图算个特征向量,其余所有测试集中的图像也都提个特征向量,去和这5个比,看看谁近,近的话就认为是同一个label。

相比之下,借助于之前丰富的知识积累,人类只需看一次就能轻松识别出新的类别。受到人类这种利用少量样本即可识别新类能力的启发,研究者们开始研究小样本学习问题。 在小样本学习问题中,我们假设有一组基类,以及一组新类。每个基类具有足够的训练样本,而每个新类只有少量标记样本。 小样本学习的目的是通过从基类转移知识来学习识别具有少量标注样本的新类别。我们提出一种基于全局类别表征的小样本学习方法,可以应用于:
- 标准小样本学习问题:给定一个大规模的训练集作为基类,可以类比于人类的知识积累,对于从未见过的新类(与基类不重叠),借助每类少数几个训练样本,需要准确识别新类的测试样本。
- 广义小样本学习问题:相比与小样本学习,广义小样本学习中测试样本不仅包含新类,还包含了基类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号