JAVA常用知识总结(四)——集合
先附一张java集合框架图

下面根据面试中常问的关于集合的问题进行了梳理:
Arraylist 与 LinkedList 有什么不同?
-
1. 是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-
2. 底层数据结构: Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别①);
-
3. 插入和删除是否受元素位置的影响: ① ArrayList② 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行
add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。 当需要对数据进行多次访问的情况下选用ArrayList,当需要对数据进行多次增加删除修改时采用LinkedList。 -
4. 是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于
get(int index)方法)。 -
5. 内存空间占用: ArrayList的空间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
补充内容:RandomAccess接口
1 public interface RandomAccess { 2 }
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
1 public static <T> 2 int binarySearch(List<? extends Comparable<? super T>> list, T key) { 3 if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD) 4 return Collections.indexedBinarySearch(list, key); 5 else 6 return Collections.iteratorBinarySearch(list, key); 7 }
ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
下面再总结一下 list 的遍历方式选择:
- 实现了RadomAcces接口的list,优先选择普通for循环 ,其次foreach (采用ArrayList对随机访问比较快,而for循环中的get()方法,采用的即是随机访问的方法,因此在ArrayList里,for循环较快)
- 未实现RadomAcces接口的ist,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的,采用LinkedList则是顺序访问比较快,iterator中的next()方法,采用的即是顺序访问的方法,因此在LinkedList里,使用iterator较快)
ps:如果在涉及到集合元素的删除操作时,一般调用删除和添加方法都是具体集合的方法,例如:List list = new ArrayList(); list.add(...); list.remove(...);但是,如果在循环的过程中调用集合的remove()方法,就会导致循环出错,因为循环过程中list.size()的大小变化了,就导致了错误。 所以,如果想在循环语句中删除集合中的某个元素,就要用迭代器iterator的remove()方法,因为它的remove()方法不仅会删除元素,还会维护一个标志,用来记录目前是不是可删除状态,例如,你不能连续两次调用它的remove()方法,调用之前至少有一次next()方法的调用。
forEach不是关键字,关键字还是for,语句是由iterator实现的,它们最大的不同之处就在于remove()方法上。forEach就是为了让用iterator循环访问的形式简单,写起来更方便。当然功能不太全,所以但如有删除操作,还是要用它原来的形式
1 public static void remove(List<String> list, String target) { 2 for (String item : list) { 3 if (item.equals(target)) { 4 list.remove(item); 5 break; //增强 for 循环中删除元素后继续循环会报 java.util.ConcurrentModificationException 异常,因为元素在使用的时候发生了并发的修改,导致异常抛出,但是删除完毕马上使用 break 跳出,则不会触发报错。 6 } 7 } 8 } 9 10 11 public static void remove(List<String> list, String target) { 12 Iterator<String> iter = list.iterator(); 13 while (iter.hasNext()) { 14 String item = iter.next(); 15 if (item.equals(target)) { 16 iter.remove(); 17 } 18 } 19 }
ArrayList 与 Vector 区别?
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
哈希表和其他数据结构?
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑
什么是哈希表
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),而在上面我们提到过,在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过某个函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
存储位置 = f(关键字)
其中,这个函数f一般称为哈希函数,这个函数的设计好坏会直接影响到哈希表的优劣。举个例子,比如我们要在哈希表中执行插入操作:
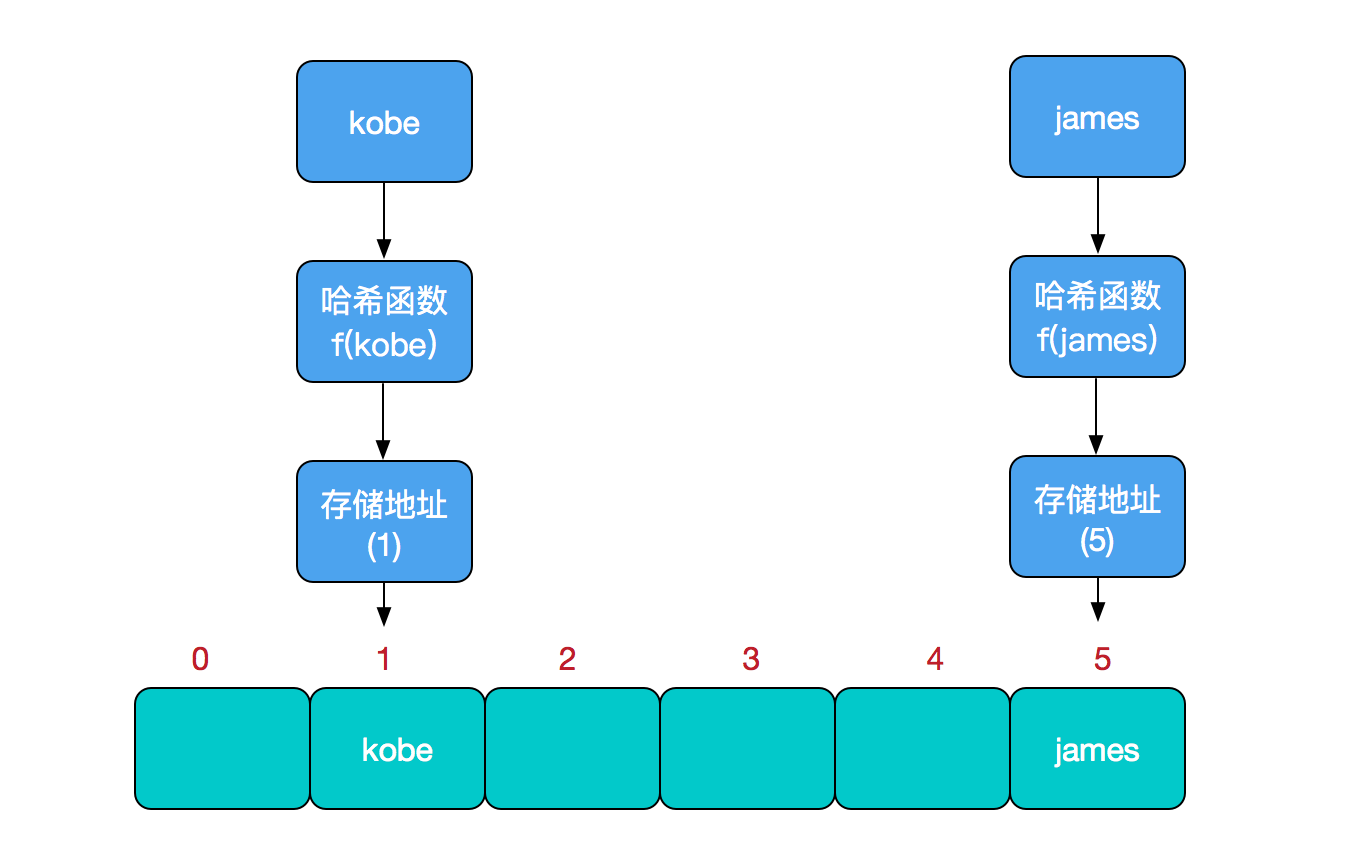
查找操作同理,先通过哈希函数计算出实际存储地址,然后从数组中对应地址取出即可。
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式,
HashMap的底层是如何实现?
https://mp.weixin.qq.com/s/SZqJBLRVIT-Y4SqGoVzP9g 文章有详细介绍,以下谈谈我自己的理解
HashMap③是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。底层数据结构是由数组实现的,每一个数组元素都是个单向链表。HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash函数也难免会出现index冲突的情况,JDK1.8之前采用链表来解决,JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。JDK1.8后,除了对hashmap增加红黑树结果外,对原有造成死锁的关键原因点(新table复制在头端添加元素)改进为依次在末端添加新的元素。虽然JDK1.8后添加红黑树改进了链表过长查询遍历慢问题和resize时出现导致put死循环的bug,但还是非线性安全的,比如数据丢失等等。因此多线程情况下还是建议使用concurrenthashmap。
HashMap 和 Hashtable 的区别
-
线程是否安全: HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过
synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap https://mp.weixin.qq.com/s/1yWSfdz0j-PprGkDgOomhQ 吧!); -
效率: 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-
对Null key 和Null value的支持: HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
-
初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的
tableSizeFor()方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。 -
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
-
继承不同
public class Hashtable extends Dictionary implements Map public class HashMap extends AbstractMap implements Map
注释一:双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表,如下图所示,同时下图也是LinkedList 底层使用的是双向循环链表数据结构。

注释二:ArrayList是一个相对来说比较简单的数据结构,最重要的一点就是它的自动扩容,可以认为就是我们常说的“动态数组”,也就是说,当增加数据的时候,如果ArrayList的大小已经不满足需求时,那么就将数组变为原长度的1.5倍,之后的操作就是把老的数组拷到新的数组里面。例如,默认的数组大小是10,也就是说当我们add10个元素之后,再进行一次add时,就会发生自动扩容,数组长度由10变为了15具体情况如下所示:
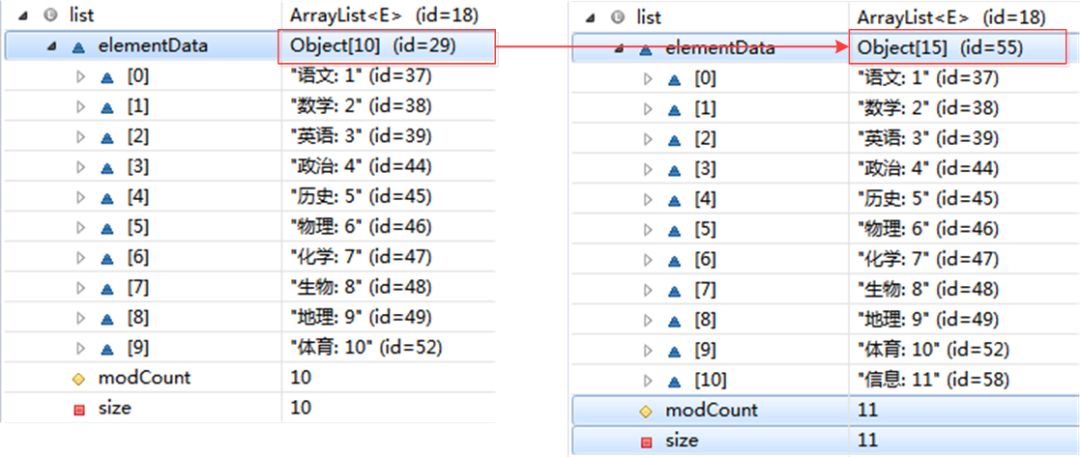
注释三:数组和向量都可以存储对象,但对象的存储位置是随机的,也就是说对象本身与其存储位置之间没有必然的联系。当要查找一个对象时,只能以某种顺序(如顺序查找或二分查找)与各个元素进行比较,当数组或向量中的元素数量很多时,查找的效率会明显的降低。
一种有效的存储方式,是不与其他元素进行比较,一次存取便能得到所需要的记录。这就需要在对象的存储位置和对象的关键属性(设为 k)之间建立一个特定的对应关系(设为 f),使每个对象与一个唯一的存储位置相对应。在查找时,只要根据待查对象的关键属性 k 计算f(k)的值即可。如果此对象在集合中,则必定在存储位置 f(k)上,因此不需要与集合中的其他元素进行比较。称这种对应关系 f 为哈希(hash)方法,按照这种思想建立的表为哈希表。
Hash算法 不是某个固定的算法,它代表的是一类算法
以更好理解的方式来说,Hash算法是摘要算法 :也就是说,从不同的输入中,通过一些计算摘取出来一段输出数据,值可以用以区分输入数据。
所以,MD5 可能是最著名的一种Hash算法 了。
补充:List去重问题
set集合的特点就是没有重复的元素。如果集合中的数据类型是基本数据类型,可以直接将list集合转换成set,就会自动去除重复的元素,这个就相对比较简单。
1 public class Test { 2 3 public static void main(String[] args) { 4 List list = new ArrayList(); 5 list.add(11); 6 list.add(12); 7 list.add(13); 8 list.add(14); 9 list.add(15); 10 list.add(11); 11 System.out.println(list); 12 13 Set set = new HashSet(); 14 List newList = new ArrayList(); 15 set.addAll(list); 16 newList.addAll(set); 17 System.out.println(newList); 18 19 } 20 21 }
当list集合中存储的类型是对象类型的时候,我们就不能简单的只把list集合转换成set集合,当list集合中存储的是对象时,我们需要在对象的实体类中去重写equals()方法和hashCode()方法。
1 public class People { 2 3 private String name; 4 private String phoneNumber; 5 6 public String getName() { 7 return name; 8 } 9 10 public void setName(String name) { 11 this.name = name; 12 } 13 14 public String getPhoneNumber() { 15 return phoneNumber; 16 } 17 18 public void setPhoneNumber(String phoneNumber) { 19 this.phoneNumber = phoneNumber; 20 } 21 22 public People(String name, String phoneNumber) { 23 super(); 24 this.name = name; 25 this.phoneNumber = phoneNumber; 26 } 27 28 @Override 29 public String toString() { 30 return "People{" + 31 "name='" + name + '\'' + 32 ", phoneNumber='" + phoneNumber + '\'' + 33 '}'; 34 } 35 36 @Override 37 public boolean equals(Object arg0) { 38 // TODO Auto-generated method stub 39 People p = (People) arg0; 40 return name.equals(p.name) && phoneNumber.equals(p.phoneNumber); 41 } 42 43 @Override 44 public int hashCode() { 45 // TODO Auto-generated method stub 46 String str = name + phoneNumber; 47 return str.hashCode(); 48 } 49 50 }
public static void main(String[] args) {
List<Student> stu = new ArrayList<Student>();
stu.add(new Student("1","yi"));
stu.add(new Student("3","san"));
stu.add(new Student("3","san"));
stu.add(new Student("2","er"));
stu.add(new Student("2","er"));
//set集合保存的是引用不同地址的对象
Set<Student> ts = new HashSet<Student>();
ts.addAll(stu);
重写equals方法时需要重写hashCode方法,主要是针对Map、Set等集合类型的使用;
- Map、Set等集合类型存放的对象必须是唯一的;
- 集合类判断两个对象是否相等,是先判断equals是否相等,如果equals返回TRUE,还要再判断HashCode返回值是否ture,只有两者都返回ture,才认为该两个对象是相等的。
假设你将
equals覆盖为name相等即相等(张三等于张三),不过你没覆盖hashCode();put(key)操作,由于你的新key和HashMap中原有的老key是两个不同的对象,尽管他们equals,不过由于继承自Object的hashCode()方法给出了两个不同的hashCode,在根据hashCode计算出index这一步,它们两个属于不同的index!所以,要避免出现这个问题,就必须在改写equals()的同时改写hashCode(),以保证对象equals则HashCode一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号