JAVA常用知识总结(七)——Spring
-
如果一个接口有2个不同的实现, 如何Autowire某一个指定的实现?
1、通过增加@Qualifier(实现类的名字):
@Autowired @Qualifier("GirlStudentImpl") private Student student;
2、也可以通过@Resource(name=”*“)装配,则编程更加简洁:
@Resource(name="GirlStudentImpl") private Student student;
-
Spring注解(annotation-driven和annotation-config)的区别
如果你想使用@Autowired注解,那么就必须事先在 Spring 容器中声明 AutowiredAnnotationBeanPostProcessor Bean。传统声明方式如下
<bean class="org.springframework.beans.factory.annotation. AutowiredAnnotationBeanPostProcessor "/>
如果想使用@ Resource 、@ PostConstruct、@ PreDestroy等注解就必须声明CommonAnnotationBeanPostProcessor
如果想使用@PersistenceContext注解,就必须声明PersistenceAnnotationBeanPostProcessor的Bean。
如果想使用 @Required的注解,就必须声明RequiredAnnotationBeanPostProcessor的Bean。同样,传统的声明方式如下:
<bean class="org.springframework.beans.factory.annotation.RequiredAnnotationBeanPostProcessor"/>
一般来说,这些注解我们还是比较常用,尤其是Antowired的注解,在自动注入的时候更是经常使用,所以如果总是需要按照传统的方式一条一条配置显得有些繁琐和没有必要,于是spring给我们提供<context:annotation-config/>的简化配置方式,自动帮你完成声明。启动注解装配
不过,我们使用注解一般都会配置扫描包路径选项
<context:component-scan base-package=”XX.XX”/>
该配置项其实也包含了自动注入上述processor的功能,因此当使用 <context:component-scan/> 后,就可以将 <context:annotation-config/> 移除了
<mvc:annotation-driven/>
相当于注册了DefaultAnnotationHandlerMapping①和AnnotationMethodHandlerAdapter两个bean,配置一些messageconverter。即解决了@Controller注解的使用前提配置。并提供了:数据绑定支持,@NumberFormatannotation支持,@DateTimeFormat支持, @Valid支持,读写XML的支持(JAXB),读写JSON的支持(Jackson)。
-
@Component, @Controller, @Repository, @Service 有何区别?
-
@Component:这将 java 类标记为 bean。它是任何 Spring 管理组件的通用构造型。spring 的组件扫描机制现在可以将其拾取并将其拉入应用程序环境中。
-
@Controller:这将一个类标记为 Spring Web MVC 控制器。标有它的 Bean 会自动导入到 IoC 容器中。
-
@Service:此注解是组件注解的特化。它不会对 @Component 注解提供任何其他行为。您可以在服务层类中使用 @Service 而不是 @Component,因为它以更好的方式指定了意图。
-
@Repository:这个注解是具有类似用途和功能的 @Component 注解的特化。它为 DAO 提供了额外的好处。它将 DAO 导入 IoC 容器,并使未经检查的异常有资格转换为 Spring DataAccessException,在注解了
@Repository的类上如果数据库操作中抛出了异常,就能对其进行处理,转而抛出的是翻译后的spring专属数据库异常,方便我们对异常进行排查处理。
-
-
@RequestParam 和 @PathVariable @RequestBody 以及不加的区别?
@RequestParam
@RequestParam 是 获取请求参数的值,也就是 ? 后面的那些值 ,也可以是post请求中参数的值
请求路径:http://www.test.com/user/query?username=zhangsan&age=20
请求参数:username=zhangsan&age=20
@RequestMapping(value = "/user/query")
public String query(@RequestParam(value="username") String username) {
System.out.println("username = " + username); //此处打印:username = zhangsan
return SUCCESS;
}
通过@RequestParam 获取 不同请求对应的值:
.../query?username=zhangsan 获取 username 等于 zhangsan
.../query?username= 获取 username==""
.../query 获取 username==null
@RequestParam 默认必传的,不能为null
如上面例子,请求路径是 http://www.test.com/user/query?age=20 ,程序一定会报错的,
如果username不传时, 就是null ,而 @RequestParam 默认是必传的。
解决方法是
第1种: 请求路径改为 http://www.test.com/user/query?username=&age=20 表示 username=="",不为null;
第2种: required=false,具体如下:
@RequestParam(value="username",required=false) String username
@PathVariable
@PathVariable 是 处理 URL 中的参数值
URL 中的 { xxx } 占位符可以通过 @PathVariable("xxx") 绑定到操作方法的入参中。
请求路径 : http://www.test.com/user/031267/view?username=zhangsan&age=20
请求URL : http://www.test.com/user/031267/view
@RequestMapping(value = "/user/{userid}/view") //占位符 userid
public String view ( @PathVariable("userid") String userid){ //@PathVariable 中指定 userid
System.out.println("userid= "+userid); //此处可以获取:userid= 031267
return SUCCESS;
}
带占位符的URL 是Spring3.0 新增的功能,该功能在SpringMVC 向REST目标挺进发展过程中具有里程碑的意义。
@RequestBody
@RequestBody的作用其实是将json格式的数据转为java对象,可以省去我们在后台将json转成java对象
-
BeanFactory和ApplicationContext以及FactoryBean的区别?
BeanFacotry是spring中比较原始的Factory。如XMLBeanFactory就是一种典型的BeanFactory。原始的BeanFactory无法支持spring的许多插件,如AOP功能、Web应用等。
ApplicationContext接口,它由BeanFactory接口派生而来,ApplicationContext包含BeanFactory的所有功能,通常建议比BeanFactory优先
BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean,两者都是接口。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似。不同于普通Bean的是:如果一个Bean实现了FactoryBean<T>接口,根据该Bean的ID从BeanFactory中获取的实际上是FactoryBean的getObject()返回的对象,而不是FactoryBean本身,如果要获取FactoryBean对象,请在id前面加一个&符号来获取②。
-
Spring Bean 的作用域?

当scope=”prototype”时,容器会延迟初始化bean(如果一个bean的scope属性为scope="pototype"时,即使设置了lazy-init="false"也会延迟),Spring读取xml文件的时候,并不会立刻创建对象,而是在第一次请求该bean时才初始化(如调用getBean方法时),因此谈及prototype作用域的bean时,在某些方面可以将Spring容器的角色看作是Java new操作的替代者,任何迟于该时间点的生命周期事宜都得交由客户端来处理。
Spring容器可以管理singleton作用域下bean的生命周期,在此作用域下,Spring能够精确地知道bean何时被创建,何时初始化完成,以及何时被销毁。而对于prototype作用域的bean,Spring只负责创建,当容器创建了bean的实例后,bean的实例就交给了客户端的代码管理,Spring容器将不再跟踪其生命周期,并且不会管理那些被配置成prototype作用域的bean的生命周期。
-
SpringMVC的控制器是不是单例模式,如果是,有什么问题,怎么解决?
Spring MVC默认是Singleton的,所以会产生一个潜在的安全隐患。根本核心是instance变量保持状态的问题。这意味着每个request过来,系统都会用原有的instance去处理,这样导致了两个结果:
一是我们不用每次创建Controller,
二是减少了对象创建和垃圾收集的时间;
由于只有一个Controller的instance,当多个线程同时调用它的时候,它里面的instance变量就不是线程安全的了,会发生窜数据的问题。
当然大多数情况下,我们根本不需要考虑线程安全的问题,比如dao,service等,除非在bean中声明了实例变量。因此,我们在使用spring mvc 的contrller时:
- 应避免在controller中定义实例变量。
- 或者将控制器的作用域从单例改为原型,即在spring配置文件Controller中声明 scope="prototype",每次都创建新的controller
- 在Controller中使用ThreadLocal变量
-
Spring MVC的五大组键 ?
-
前端控制器 (DispatcherServlet) -
映射处理器(HandlerMapping) -
处理器(Controller) -
模型和视图(ModelAndView) -
视图解析器(ViewResolver)
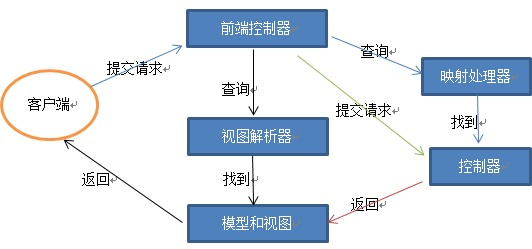
文字解析: 客户端请求提交到DispatcherServlet 由DispatcherServlet控制器查询一个或多个HandlerMapping,找到处理请求的Controller DispatcherServlet将请求提交到Controller Controller调用业务逻辑处理后,返回ModelAndView DispatcherServlet查询一个或多个ViewResoler视图解析器,找到ModelAndView指定的视图 视图负责将结果显示到客户
-
spring中的设计模式?
spring中常用的设计模式为:
单例模式(Singleton):保证一个类仅有一个实例,并提供一个访问它的全局访问点。
spring中的单例模式完成了后半句话,即提供了全局的访问点BeanFactory。但没有从构造器级别去控制单例,这是因为spring管理的是是任意的java对象。
核心提示点:Spring下默认的bean均为singleton,可以通过singleton=“true|false” 或者 scope=“?”来指定
代理(Proxy):在Spring的Aop中,使用的Advice(通知)来增强被代理类的功能。Spring实现这一AOP功能的原理就使用代理模式(1、JDK动态代理。2、CGLib字节码生成技术代理。)对类进行方法级别的切面增强,即,生成被代理类的代理类, 并在代理类的方法前,设置拦截器,通过执行拦截器重的内容增强了代理方法的功能,实现的面向切面编程。
模板方法(Template Method):定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。Template Method使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
Template Method模式一般是需要继承的。这里想要探讨另一种对Template Method的理解。spring中的JdbcTemplate,在用这个类时并不想去继承这个类,因为这个类的方法太多,但是我们还是想用到JdbcTemplate已有的稳定的、公用的数据库连接,那么我们怎么办呢?我们可以把变化的东西抽出来作为一个参数传入JdbcTemplate的方法中。但是变化的东西是一段代码,而且这段代码会用到JdbcTemplate中的变量。怎么办?那我们就用回调对象吧。在这个回调对象中定义一个操纵JdbcTemplate中变量的方法,我们去实现这个方法,就把变化的东西集中到这里了。然后我们再传入这个回调对象到JdbcTemplate,从而完成了调用。这可能是Template Method不需要继承的另一种实现方式吧。
工厂方法(Factory Method):通常由应用程序直接使用new创建新的对象,为了将对象的创建和使用相分离,采用工厂模式,即应用程序将对象的创建及初始化职责交给工厂对象。
-
常见的三种注入方式?
1:field注入 @Controller public class FooController { @Autowired //@Inject private FooService fooService; //简单的使用例子,下同 public List<Foo> listFoo() { return fooService.list(); } //承接上面field注入的代码,假如客户端代码使用下面的调用(或者再Junit测试中使用) //这里只是模拟一下,正常来说我们只会暴露接口给客户端,不会暴露实现。 FooController fooController = new FooController(); fooController.listFoo(); // -> NullPointerException } 缺点显而易见,对于IOC容器以外的环境,除了使用反射来提供它需要的依赖之外,无法复用该实现类。而且将一直是个潜在的隐患,因为你不调用将一直无法发现NPE的存在。 2: 构造器注入 推荐 @Controller public class FooController { private final FooService fooService; @Autowired public FooController(FooService fooService) { this.fooService = fooService; } //使用方式上同,略 } 3:setter注入 @Controller public class FooController { private FooService fooService; //使用方式上同,略 @Autowired public void setFooService(FooService fooService) { this.fooService = fooService; } }
-
spring的4种事务特性,5种隔离级别,7种传播行为?
4种特性:
(1)原子性
事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。
(2)一致性
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。
(3) 隔离性(关于事务的隔离性数据库提供了多种隔离级别)
一个事务的执行不能干扰其它事务。即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
(4)持久性
事务完成之后,它对于数据库中的数据改变是永久性的。该修改即使出现系统故障也将一直保持。
并发下事务会产生的问题
举个例子,事务A和事务B操纵的是同一个资源,事务A有若干个子事务,事务B也有若干个子事务,事务A和事务B在高并发的情况下,会出现各种各样的问题。"各种各样的问题",总结一下主要就是五种:第一类丢失更新、第二类丢失更新、脏读、不可重复读、幻读。五种之中,第一类丢失更新、第二类丢失更新不重要,不讲了,讲一下脏读、不可重复读和幻读。
1、脏读
所谓脏读,就是指事务A读到了事务B还没有提交的数据,比如银行取钱,事务A开启事务,此时切换到事务B,事务B开启事务-->取走100元,此时切换回事务A,事务A读取的肯定是数据库里面的原始数据,因为事务B取走了100块钱,并没有提交,数据库里面的账务余额肯定还是原始余额,这就是脏读。
2、不可重复读
所谓不可重复读,就是指在一个事务里面读取了两次某个数据,读出来的数据不一致。还是以银行取钱为例,事务A开启事务-->查出银行卡余额为1000元,此时切换到事务B事务B开启事务-->事务B取走100元-->提交,数据库里面余额变为900元,此时切换回事务A,事务A再查一次查出账户余额为900元,这样对事务A而言,在同一个事务内两次读取账户余额数据不一致,这就是不可重复读。
3、幻读
所谓幻读,就是指在一个事务里面的操作中发现了未被操作的数据。比如学生信息,事务A开启事务-->修改所有学生当天签到状况为false,此时切换到事务B,事务B开启事务-->事务B插入了一条学生数据,此时切换回事务A,事务A提交的时候发现了一条自己没有修改过的数据,这就是幻读,就好像发生了幻觉一样。幻读出现的前提是并发的事务中有事务发生了插入、删除操作。
5种隔离级别:
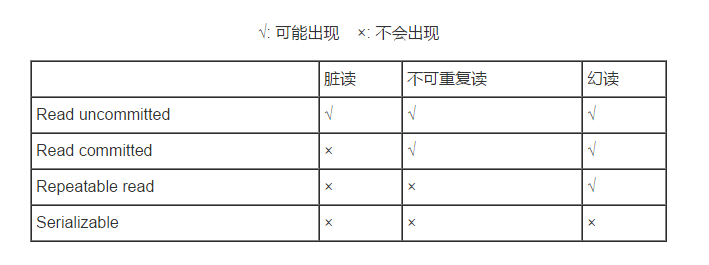
- DEFAULT 这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别. (Mysql 默认:可重复读 Oracle 默认:读已提交)
- read uncommited:是最低的事务隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。
- read commited:保证一个事物提交后才能被另外一个事务读取。另外一个事务不能读取该事物未提交的数据。
- repeatable read:这种事务隔离级别可以防止脏读,不可重复读。但是可能会出现幻象读。它除了保证一个事务不能被另外一个事务读取未提交的数据之外还避免了以下情况产生(不可重复读)。
- serializable:这是花费最高代价但最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读之外,还避免了幻象读(避免三种)。
@Transactional(isolation=Isolation.DEFAULT) public void method(){}
7种传播行为:
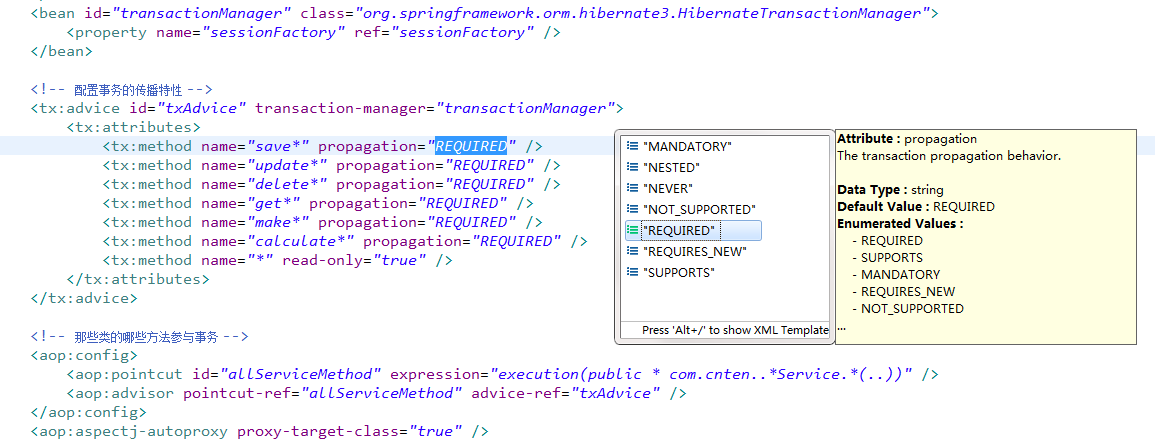
支持当前事务的情况:
-
TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
-
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
-
TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况:
-
TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
-
TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
-
TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
挂起的解读:
例如 方法A支持事务
方法B不支持事务。
方法A调用方法B。
在方法A开始运行时,系统为它建立Transaction,方法A中对于数据库的处理操作,会在该Transaction的控制之下。
这时,方法A调用方法B,方法A打开的 Transaction将挂起,方法B中任何数据库操作,都不在该Transaction的管理之下。
当方法B返回,方法A继续运行,之前的Transaction恢复,后面的数据库操作继续在该Transaction的控制之下 提交或回滚。
PROPAGATION_REQUIRES_NEW 和 PROPAGATION_NESTED 的最大区别在于:
PROPAGATION_REQUIRES_NEW 完全是一个新的事务, 而 PROPAGATION_NESTED
则是外部事务的子事务, 如果外部事务 commit, 潜套事务也会被 commit,
这个规则同样适用于 roll back. 而且嵌套事务最有价值的点在于
ServiceA { /** * 事务属性配置为 PROPAGATION_REQUIRED */ void methodA() { try { ServiceB.methodB(); } catch (SomeException) { // 执行其他业务, 如 ServiceC.methodC(); } } }
嵌套事务最有价值的地方, 它起到了分支执行的效果, 如果 ServiceB.methodB 失败, 那么执行 ServiceC.methodC(), 而 ServiceB.methodB 已经回滚到它执行之前的 SavePoint, 所以不会产生脏数据(相当于此方法从未执行过), 这种特性可以用在某些特殊的业务中, 而 PROPAGATION_REQUIRED 和 PROPAGATION_REQUIRES_NEW 都没有办法做到这一点. (题外话 : 看到这种代码, 似乎似曾相识, 想起了 prototype.js 中的 Try 函数 )
-
Spring事务和hibernate事务的区别?
对于传统的基于特定事务资源的事务处理而言(如基于JDBC的数据库访问),Spring并不会对其产生什么影响,我们照样可以成功编写并运行这样的代码。同时,Spring还提供了一些辅助类可供我们选择使用,这些辅助类简化了传统的数据库操作流程,在一定程度上节省了工作量,提高了编码效率。
对于依赖容器的参数化事务管理而言,Spring则表现出了极大的价值。Spring本身也是一个容器,只是相对EJB容器而言,Spring显得更为轻便小巧。我们无需付出其他方面的代价,即可通过Spring实现基于容器的事务管理(本质上来讲,Spring的事务管理是基于动态AOP)。
hibernate事务:
hibernate是JDBC的轻量级对象封装,hibernate本身不具备Transaction处理功能,Hibernate的Transaction实际上是JDBC的Transaction封装或者JTATransaction的封装.具体分析如下:
Hibernate Transaction可以配置JDBCTransaction或者JTATransaction这取决与你在Hibernate.properties中的配置
Hibernate的事务是对底层数据库的JDBC/JTA等的封装 Spring则是对Hibernate等事务的封装
-
Spring IOC的初始化过程?

-
Spring MVC配置中的总结?
在很多配置中一般都会吧Spring-common.xml和Spring-MVC.xml进行分开配置,这种配置就行各施其职一样,显得特别清晰。
在Spring-MVC.xml中只对@Controller进行扫描就可,作为一个控制器,其他的事情不做。
在Spring-common.xml中只对一些事务逻辑的注解扫描。
(1)在Spring-MVC.xml中有以下配置:
<!-- 扫描@Controller注解 --> <context:component-scan base-package="com.xx.controller"> <context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" /> </context:component-scan>
可以看出要把最终的包写上,而不能这样写base-package=”com.xx”。这种写法对于include-filter来讲它都会扫描,而不是仅仅扫描@Controller。
(2)在Spring-common.xml中有如下配置:
<!-- 配置扫描注解,不扫描@Controller注解 --> <context:component-scan base-package="com.xx"> <context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller" /> </context:component-scan>
可以看到,这是要扫描com.xx包下的所有子类,不包含@Controller。
注释一:Spring2.5引入注解式处理器支持,通过@Controller 和 @RequestMapping注解定义我们的处理器类。并且提供了一组强大的注解:
需要通过处理器映射DefaultAnnotationHandlerMapping和处理器适配器AnnotationMethodHandlerAdapter来开启支持@Controller 和 @RequestMapping注解的处理器。
Spring 3.0.x中使用了mvc:annotation-driven后,默认会帮我们注册默认处理请求,参数和返回值的类,其中最主要的两个类:DefaultAnnotationHandlerMapping 和 AnnotationMethodHandlerAdapter ,分别为HandlerMapping的实现类和HandlerAdapter的实现类,从3.1.x版本开始对应实现类改为了RequestMappingHandlerMapping和RequestMappingHandlerAdapter。
注解二:举例,FactoryBean接口如下:
public interface FactoryBean<T> { T getObject() throws Exception; Class<?> getObjectType(); boolean isSingleton(); }
我们有个Person对象,里面包含 name,address,age。set、get方法不写了
public class Person {
private String name;
private String address;
private int age;
}
那么如果我们要在Spring中配置该对象的话,需要这么配置:
<bean id="personBean" class="com.xx.Person">
<property name="name" value="lulu" />
<property name="address" value="address1" />
<property name="age" value="24" />
</bean>
那么现在我们可以通过getBean("personBean")来获取该对象。那么我们来看下如果通过实现FactoryBean以后该怎么写呢?来看下我们的PersonFactoryBean的代码:
public class PersonFactoryBean implements FactoryBean<Person>{
private String personInfo;
public Person getObject() throws Exception {
Person person = new Person () ;
String [] infos = personInfo.split ( "," ) ;
person.setName(infos[0]);
person.setAddress(infos[1]);
person.setAge(Integer.parseInt(infos[2]));
return person;
}
public Class<Person> getObjectType() {
return Person.class;
}
public boolean isSingleton() {
return true;
}
}
我们看到,这里PersonFactoryBean实现了FactoryBean接口,那么自然也要实现它定义的方法。这里我们是通过一个personInfo字符串解析得到Person对象,那么我们在配置Spring的时候就可以这么配置:
<bean id="personFactory" class="com.xx.PersonFactory">
<property name="personInfo" value="king,address2,24"></property>
</bean>
OK,那么这个时候我们getBean("personFactory")得到的就是Person对象而不是PersonFactoryBean对象。具体调用到了getObject方法,所以结果很明显。context.getBean("&personFactory")则为PersonFactoryBean对象

 浙公网安备 33010602011771号
浙公网安备 33010602011771号