
总体思路
破解字体反爬:
1. 获取字体文件,
2.Unicode解码字体文件,保存为ttf文件,
3.打开ttf文件,查看映射关系创建映射字典(字形与实际字体之间的关系)(或者可以设定自动识别)
4.通过code与name的关系,寻找name与字形之间的关系,得到code(需要做hex)与字形关系之间的关系
5.第二次获取响应时,直接通过code与字形之间的关系,得到实际的字体,并将code替换成实际字体
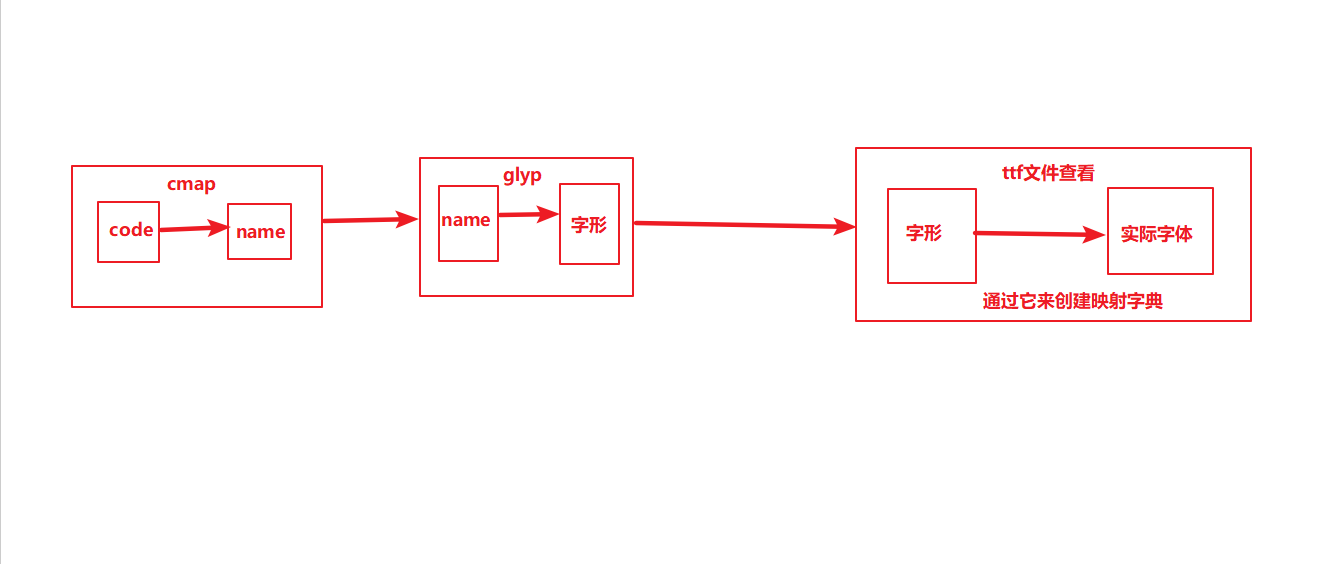
破解过程
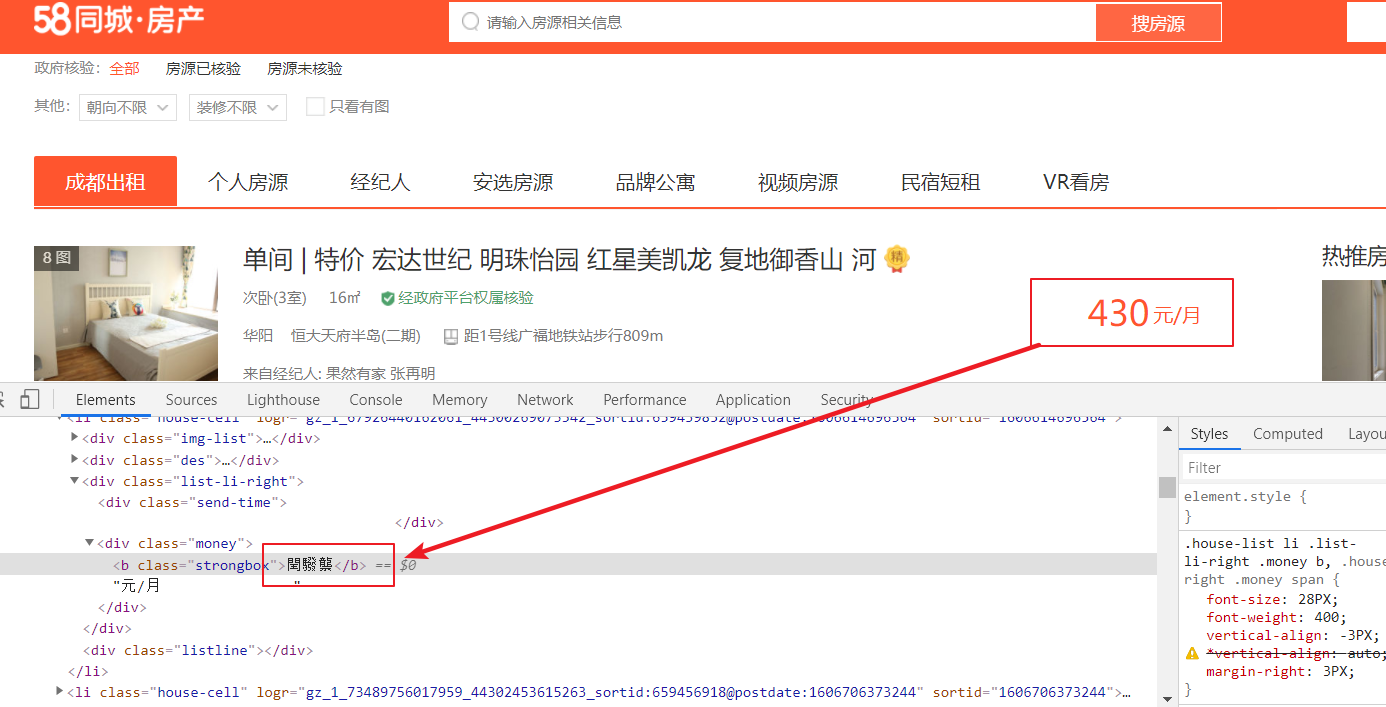
可以明显的看到显示正常但html中的是乱码。
1.获取字体文件
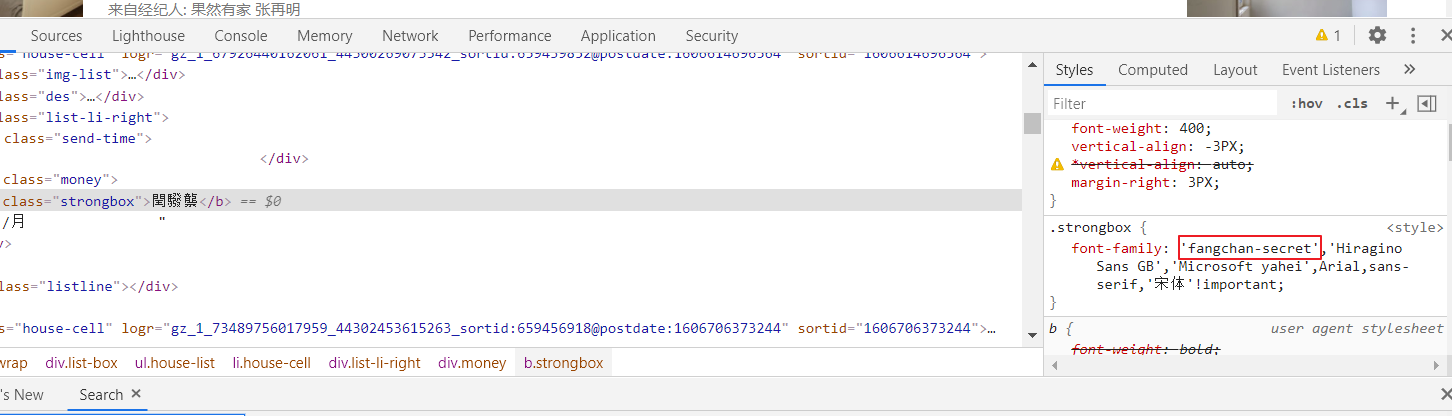
如上所示,字体文件隐藏在css中,点击右上角的style。

上图中那一段密文就是我们需要的ttf文件(这一段密文是可变的,但其中的映射关系不变)
获取那段代码然后保存为ttf文件,查看字形与实际字体的对应关系
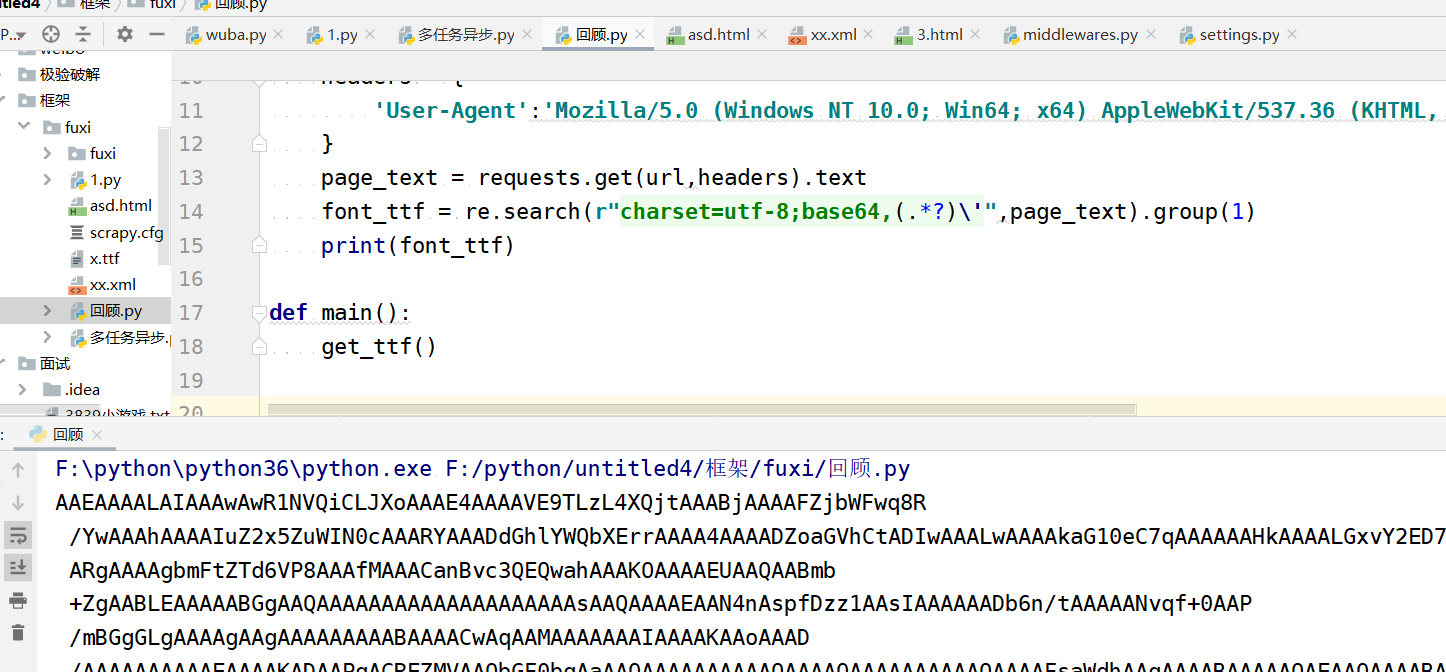
进行base64解码(为什么是bs64呢,因为font-face中标明了是base64)并保存为ttf文件,使用Fontcreator打开,可以看到字形与实际字体的对应关系,也就是映射
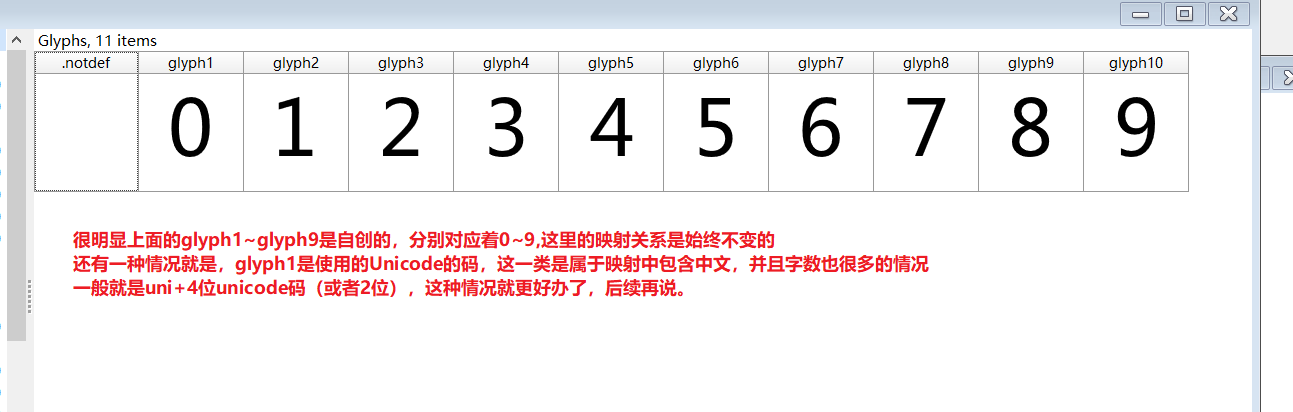
因为是自定义的字形,且个数不多,手动建立映射表
这里我手动建:
font_dict = { 'glyph1': '0', 'glyph2': '1', 'glyph3': '2', 'glyph4': '3', 'glyph5': '4', 'glyph6': '5', 'glyph7': '6', 'glyph8': '7', 'glyph9': '8', 'glyph10': '9', }
2.将ttf文件保存为xml文件,通过xml文件分析code,name,字形之间的关系
import re import requests import base64 from fontTools.ttLib import TTFont import io def get_ttf(): url = 'https://cd.58.com/chuzu/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36' } page_text = requests.get(url,headers).text font_ttf = re.search(r"charset=utf-8;base64,(.*?)\'",page_text).group(1) font = TTFont(io.BytesIO(base64.b64decode(font_ttf))) # 放入到内存中,以字节形式存在 font.saveXML("wuba.xml") def main(): get_ttf() if __name__ == '__main__': main()
分析xml文件
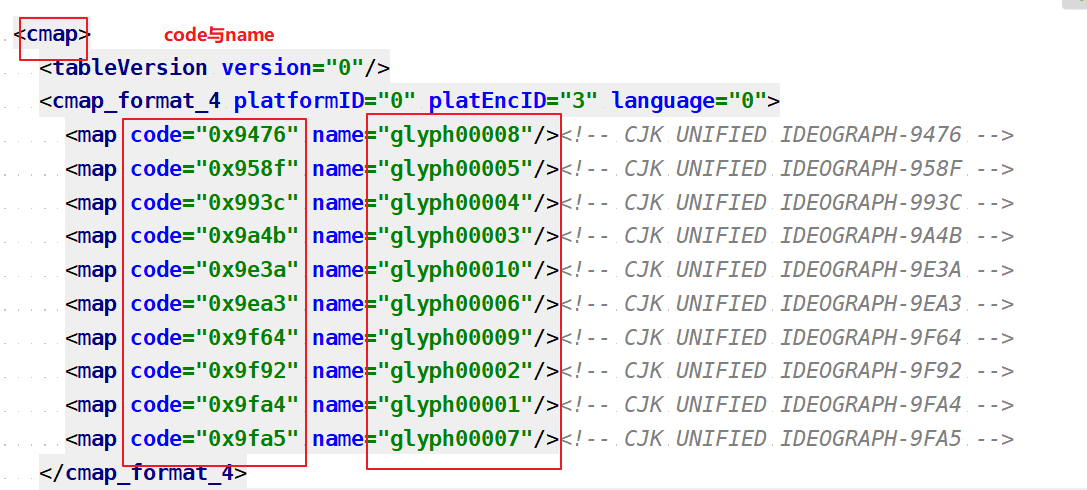
回顾一下上文中提到的三个关系:code ——>name,name——>字形,字形——>实际字体(值)
前面说过:code与name是变化的,但字形与实际值是不变的,然后我们分析一下name与字形之间的关系
name:glyph0001
字形:glyph1
很明显中间多了几个零而已,处理一下,直接让code与字形对应起来,下一次请求过来时,直接通过code找到字形,最终找到值做code替换。
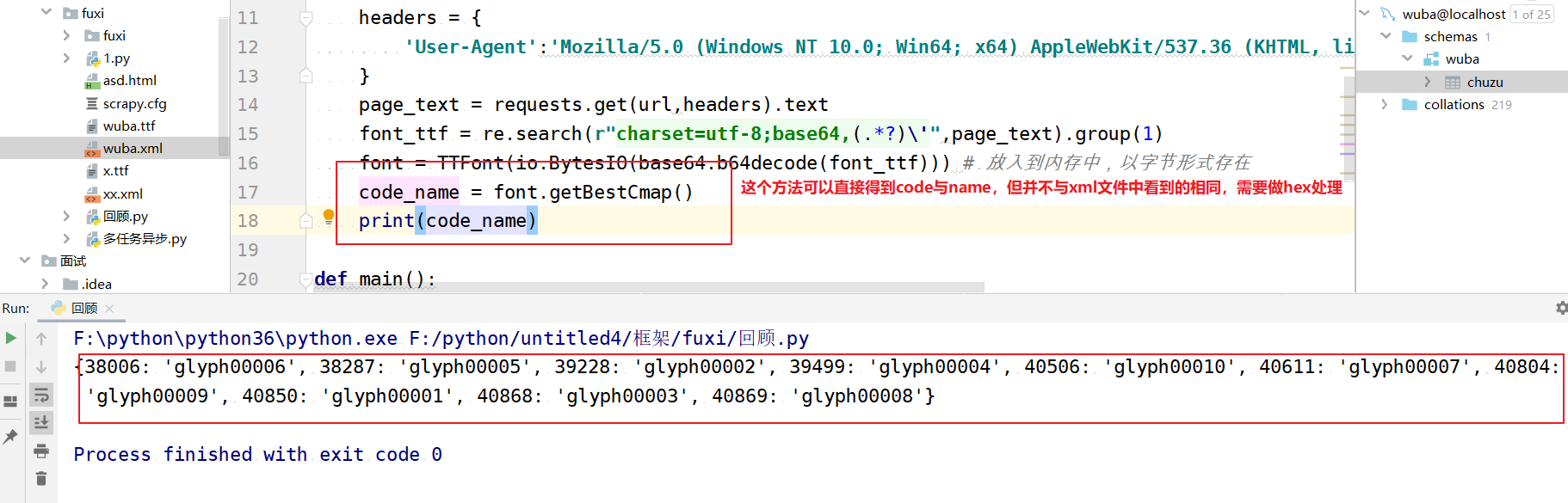
处理转换一下数据:
梳理一下:当获取到响应的html时,我们会先拿到ttf文件,然后通过fonttools模块处理code,转换name为字形,通过映射字典自动转换为值,这样code与值就直接对应上了
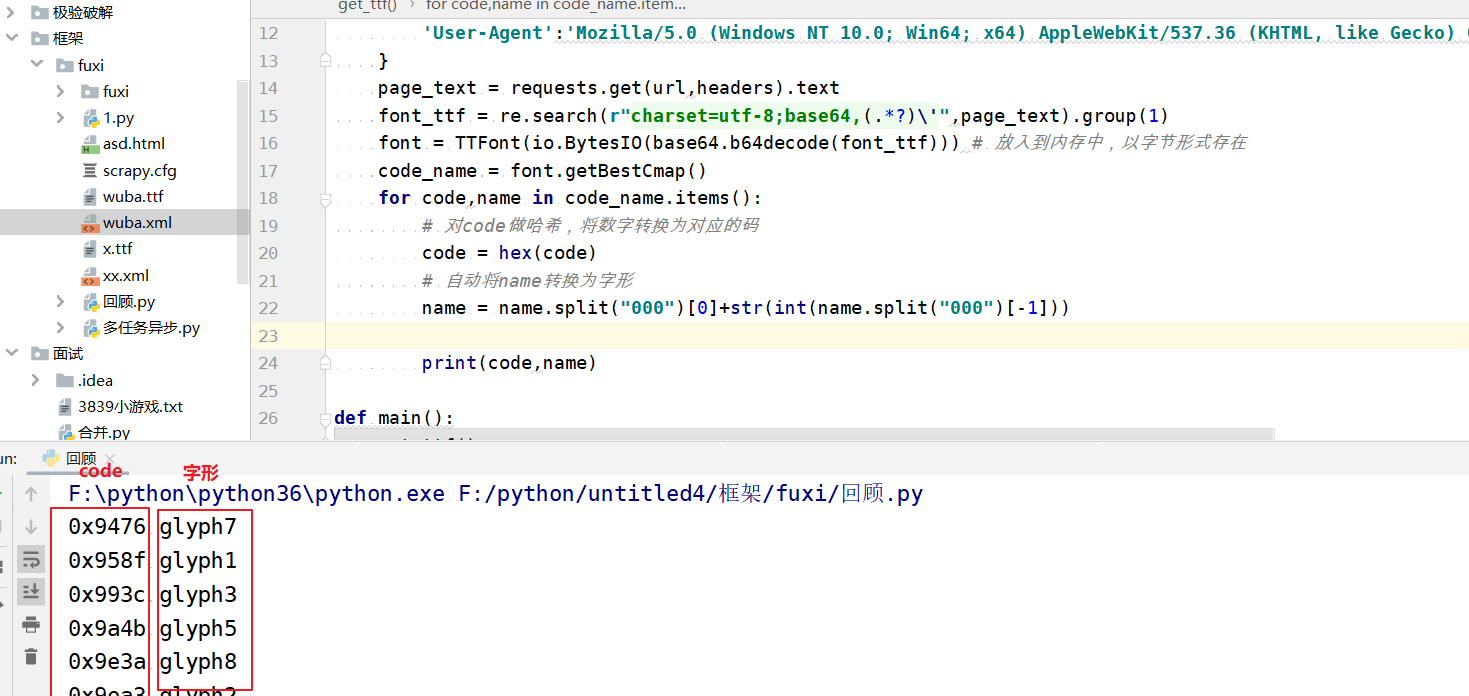
到这里我们还需要处理一下code,因为现在得到的code与html中的文本是有一点小差别的
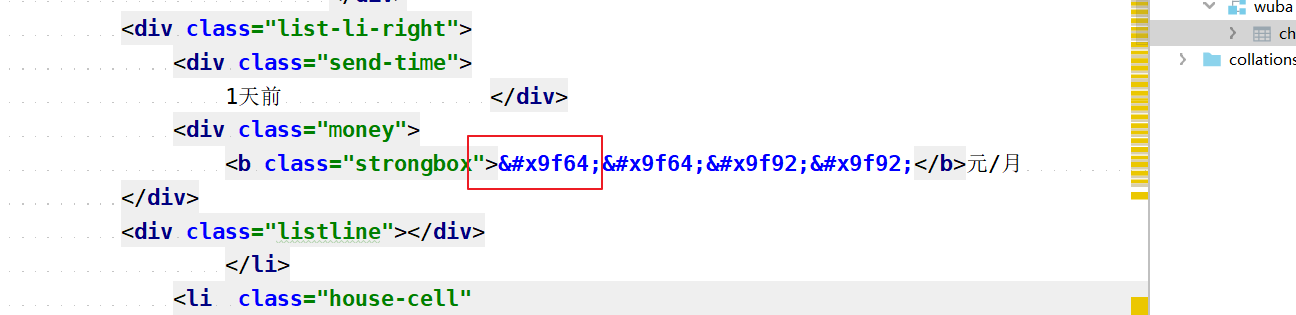
可以看到0变成了&#后面多了";"
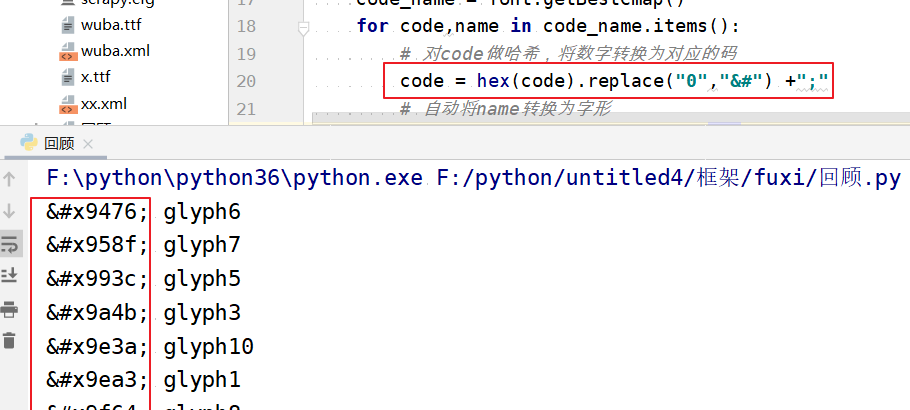
解析来,code直接映射值,然后替换html中的文本
# -*- coding: utf-8 -*- # __author__ = "maple" import re import requests import base64 from fontTools.ttLib import TTFont import io def get_ttf(): url = 'https://cd.58.com/chuzu/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36' } font_dict = { 'glyph1': '0', 'glyph2': '1', 'glyph3': '2', 'glyph4': '3', 'glyph5': '4', 'glyph6': '5', 'glyph7': '6', 'glyph8': '7', 'glyph9': '8', 'glyph10': '9', } page_text = requests.get(url,headers).text font_ttf = re.search(r"charset=utf-8;base64,(.*?)\'",page_text).group(1) font = TTFont(io.BytesIO(base64.b64decode(font_ttf))) # 放入到内存中,以字节形式存在 code_name = font.getBestCmap() for code,name in code_name.items(): # 对code做哈希,将数字转换为对应的码 code = hex(code).replace("0","&#") +";" # 自动将name转换为字形 name = name.split("000")[0]+str(int(name.split("000")[-1])) code_value = font_dict[name] # 通过name找到值 page_text = page_text.replace(code,code_value) # 执行替换操作,将code替换为值 def main(): get_ttf() if __name__ == '__main__': main()
3.数据解析
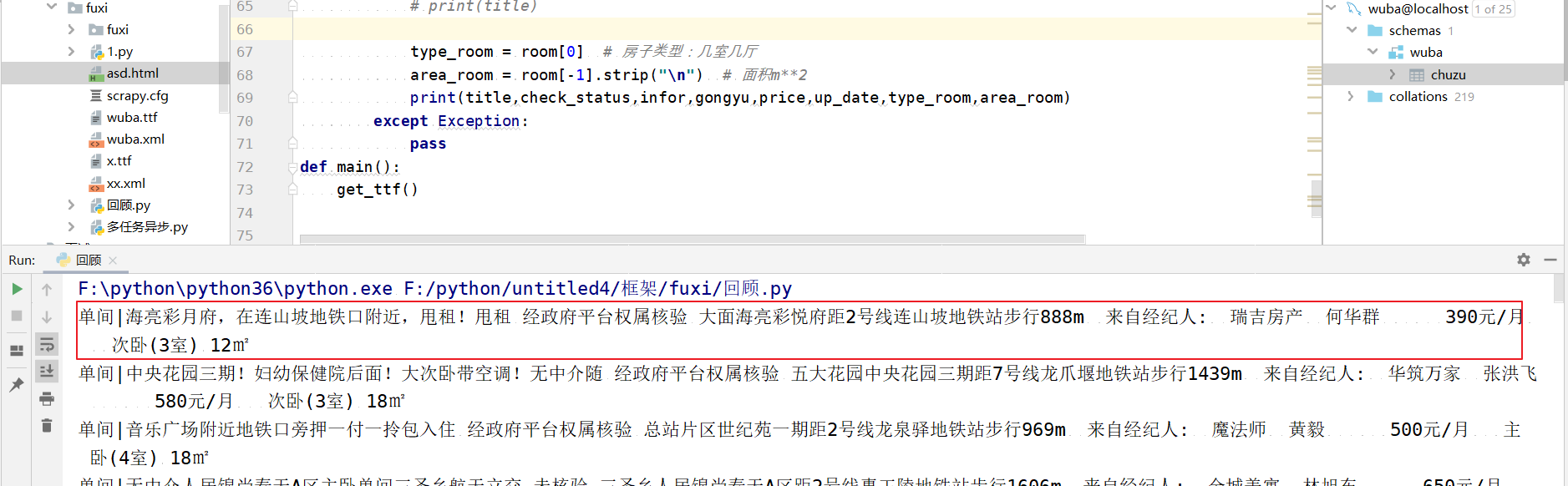
最后写入数据库或这redis即可
代码:
# -*- coding: utf-8 -*- # __author__ = "maple" import re import requests import base64 from fontTools.ttLib import TTFont from lxml import etree import io def get_ttf(): url = 'https://cd.58.com/chuzu/' headers = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36' } font_dict = { 'glyph1': '0', 'glyph2': '1', 'glyph3': '2', 'glyph4': '3', 'glyph5': '4', 'glyph6': '5', 'glyph7': '6', 'glyph8': '7', 'glyph9': '8', 'glyph10': '9', } page_text = requests.get(url,headers).text font_ttf = re.search(r"charset=utf-8;base64,(.*?)\'",page_text).group(1) font = TTFont(io.BytesIO(base64.b64decode(font_ttf))) # 放入到内存中,以字节形式存在 code_name = font.getBestCmap() for code,name in code_name.items(): # 对code做哈希,将数字转换为对应的码 code = hex(code).replace("0","&#") +";" # 自动将name转换为字形 name = name.split("000")[0]+str(int(name.split("000")[-1])) code_value = font_dict[name] # 通过name找到值 page_text = page_text.replace(code,code_value) # 执行替换操作,将code替换为值 tree = etree.HTML(page_text) for li in tree.xpath("/html/body/div[6]/div[2]/ul/li"): try: # 标题 title = li.xpath("./div[@class='des']/h2/a/text()")[0].replace(" ", "").strip('\n') # 房屋类型及面积 room = li.xpath("./div[@class='des']/p[@class='room']/text()")[0].replace(" ", "").split( "\xa0") # \xa0是不间断空白符 # 核验 check_status = li.xpath("./div[@class='des']/p[@class='room']/i/text()")[0] # 地点 infor = "".join(li.xpath("./div[@class='des']/p[@class='infor']//text()")).replace("\xa0", "").replace("\n", "").replace( " ", "").replace(":", "\:") # 来源 gongyu = "".join(li.xpath("./div[@class='des']/p[3]//text()|./div[@class='des']/div//text()")).replace(" ", "").replace( "\n", " ") # 价格 price = "".join(li.xpath('./div[@class="list-li-right"]/div[@class="money"]//text()')).replace(" ", "").replace( "\n", " ") # 发布时间 up_date = "".join(li.xpath('./div[@class="list-li-right"]/div[@class="send-time"]//text()')).replace(" ", "").replace( "\n", " ") # 来源 # print(title) type_room = room[0] # 房子类型:几室几厅 area_room = room[-1].strip("\n") # 面积m**2 print(title,check_status,infor,gongyu,price,up_date,type_room,area_room) except Exception: pass def main(): get_ttf() if __name__ == '__main__': main()
使用多任务异步协程
# -*- coding: utf-8 -*- # __author__ = "maple" # -*- coding: utf-8 -*- # __author__ = "maple" import io import re import requests import base64 import pymysql import json import asyncio import aiohttp from fontTools.ttLib import TTFont from lxml import etree # 数据库连接 conn = pymysql.connect(host='localhost', user='root', password='123456', db='wuba', charset='utf8') async def get_ttf(url): """ 获取ttf文件,ttf文件中字形与实际字体对应关系不变 :return:返回字体文件和响应文本 """ headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36", } async with aiohttp.ClientSession() as sess: async with await sess.get(url=url, headers=headers) as response: page_text = await response.text() font_sert = re.search(r"charset=utf-8;base64,(.*?)\'", page_text).group(1) font = base64.b64decode(font_sert) return font, page_text def page_source(task): """ 回调函数,处理文本,数据解析 :param font: :param page_text: :return: """ # 字体形状 --> 实际的字体 font_dict = { 'glyph1': '0', 'glyph2': '1', 'glyph3': '2', 'glyph4': '3', 'glyph5': '4', 'glyph6': '5', 'glyph7': '6', 'glyph8': '7', 'glyph9': '8', 'glyph10': '9', } # 获取结果 font,page_text = task.result() font = TTFont(io.BytesIO(font)) # 不保存,从内存中读取 for code, name in font['cmap'].getBestCmap().items(): # 38006 glyph00002 code做哈希变为0x993c # print(code,name) code = str(hex(code)).replace("0", "&#") + ";" name = name.split("000")[0] + str(int(name.split("000")[-1])) # 将glyph00008变成字体形状glyph8 # 餼 glyph8 real_text = str(font_dict[name]) page_text = page_text.replace(code, real_text) tree = etree.HTML(page_text) for li in tree.xpath("/html/body/div[6]/div[2]/ul/li"): try: # 标题 title = li.xpath("./div[@class='des']/h2/a/text()")[0].replace(" ", "").strip('\n') # 房屋类型及面积 room = li.xpath("./div[@class='des']/p[@class='room']/text()")[0].replace(" ", "").split( "\xa0") # \xa0是不间断空白符 # 核验 check_status = li.xpath("./div[@class='des']/p[@class='room']/i/text()")[0] # 地点 infor = "".join(li.xpath("./div[@class='des']/p[@class='infor']//text()")).replace("\xa0", "").replace("\n", "").replace( " ", "").replace(":", "\:") # 来源 gongyu = "".join(li.xpath("./div[@class='des']/p[3]//text()|./div[@class='des']/div//text()")).replace(" ", "").replace( "\n", " ") # 价格 price = "".join(li.xpath('./div[@class="list-li-right"]/div[@class="money"]//text()')).replace(" ", "").replace( "\n", " ") # 发布时间 up_date = "".join(li.xpath('./div[@class="list-li-right"]/div[@class="send-time"]//text()')).replace(" ", "").replace( "\n", " ") # 来源 # print(title) type_room = room[0] # 房子类型:几室几厅 area_room = room[-1].strip("\n") # 面积m**2 items = { "title": title, "check_status": check_status, "infor": infor, "gongyu": gongyu, "price": price, "up_date": up_date, "type_room": type_room, "area_room": area_room, } json.dumps(items) # 持久化存储调用 storage(items, conn) except Exception: pass def storage(items, conn): """ 持久化存储 :param items: :param conn: :return: """ ex = conn.cursor() title = items['title'] type_room = items['type_room'] area_room = items['area_room'] infor = items['infor'] gongyu = items['gongyu'] price = items['price'] check_status = items['check_status'] up_date = items['up_date'] sql = r""" insert into chuzu(title,type_room,area_room,infor,gongyu,price,check_status,up_date) values('%s','%s','%s','%s','%s','%s','%s','%s') """ % (title, type_room, area_room, infor, gongyu, price, check_status, up_date) try: ex.execute(sql) conn.commit() except Exception as e: print(e) conn.rollback() def main(): task_list = [] for num in range(1, 71): url = f'https://cd.58.com/chuzu/pn{num}/' # 协程对象 c = get_ttf(url) # 任务对象 task = asyncio.ensure_future(c) # 绑定回调 task.add_done_callback(page_source) # 将任务对象放到列表中,后续提交给任务循环对象 task_list.append(task) # 创建事件循环对象 loop = asyncio.get_event_loop() # 提交并执行 loop.run_until_complete(asyncio.wait(task_list)) if __name__ == '__main__': main()
成果:
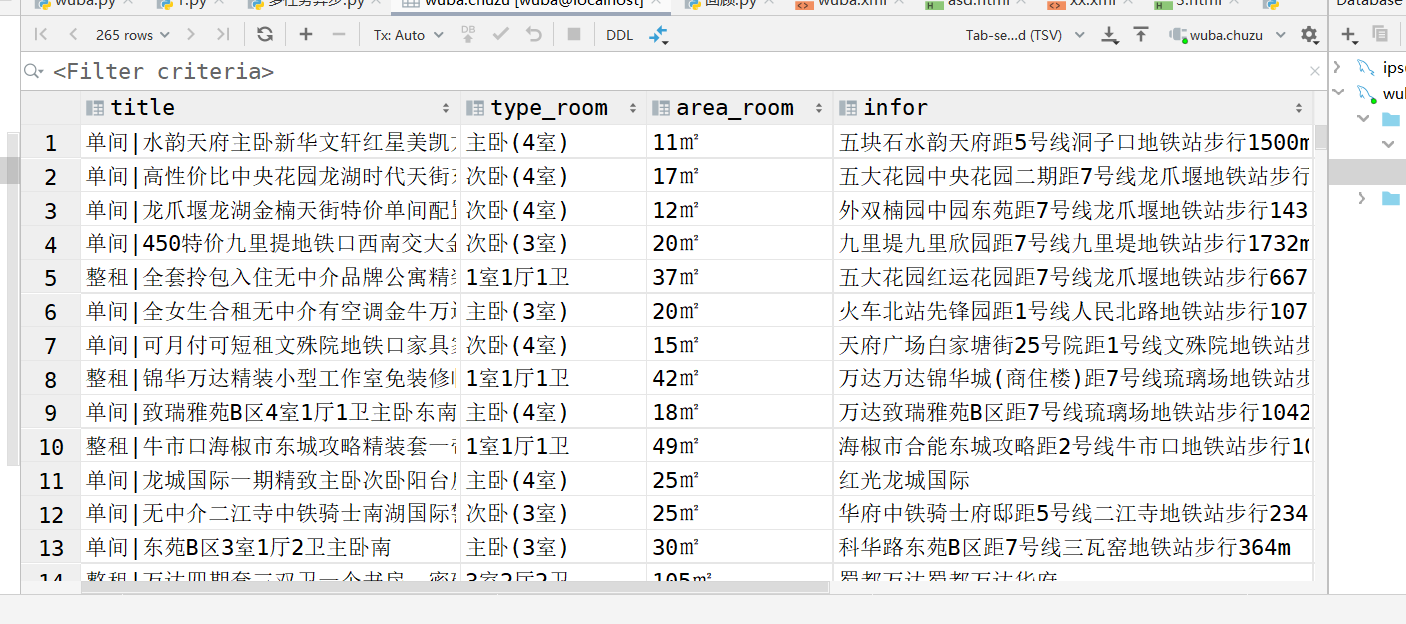

 浙公网安备 33010602011771号
浙公网安备 33010602011771号