
1、如何在下载器中间件的process_request中强制修改request的url
request._set_url(url)
2.设置代理ip的方式
目前用的比较管用的是:
request.meta['http_proxy'] = random.choice(self.proxy_list)
其他的像这种:不怎么管用
request.meta['proxy'] = random.choice(self.proxy_list)
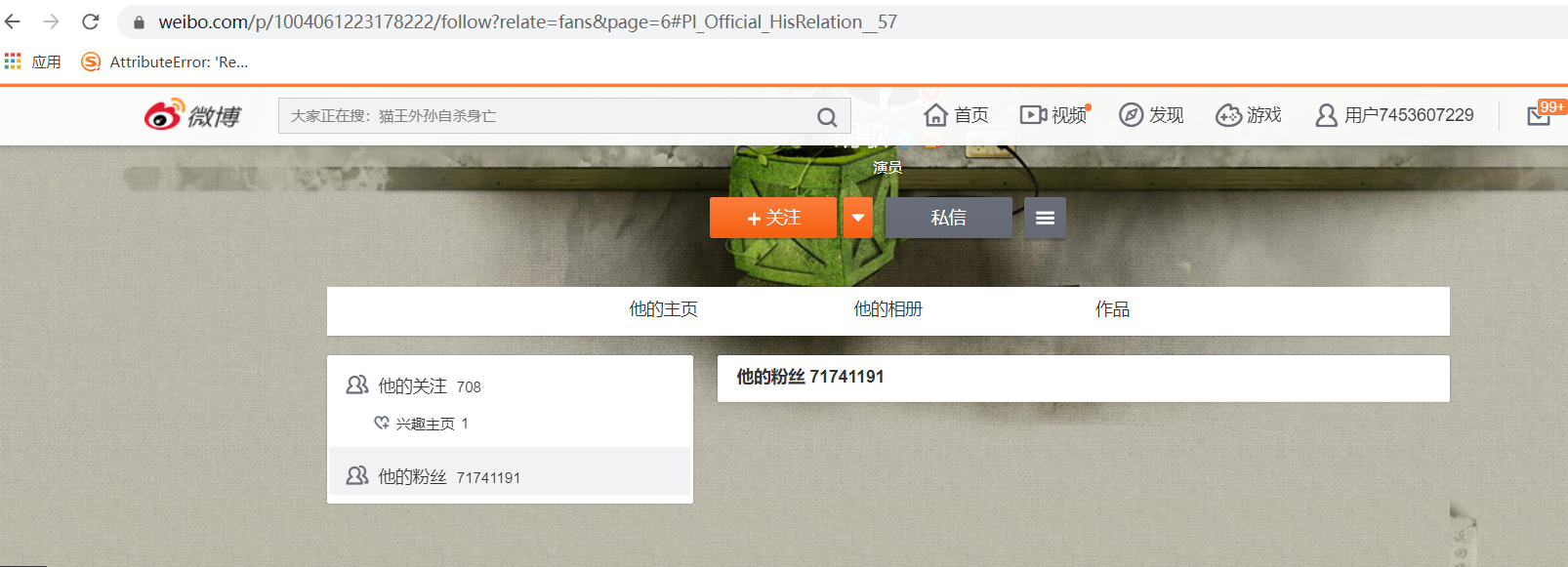
3、关于微博粉丝信息获取:单个博主的粉丝信息只能获取100条。
原因:根据网站提供的接口去调用粉丝信息只能调用5页,每页20条,所以如果根据网站显示的粉丝列表url去拿数据也就只能拿100条,因为服务端只给你提供了100条,爬虫遵循的是可见即可得,人家不提供,你就拿不到,所以。。。。难受。
超过100条显示的页面:
4、总结一下之前的结果吧,之前的需求是想抓取某一博主的所有粉丝,但由于网站提供数据只有很少的数据,所以就将需求该为了递归爬取微博用户的信息,实际跑了一下,使用递归的方式一个博主大概能抓取1000条的用户信息,所以需要放入很多个知名博主的主页url才可以抓取大量的数据。
5、实现:scrapy-redis,将抓取到的数据放入redis的set中去重,最后倒入MongoDB数据库中。
结果:大概放了两个知名博主的主页url抓取了2000条数据。
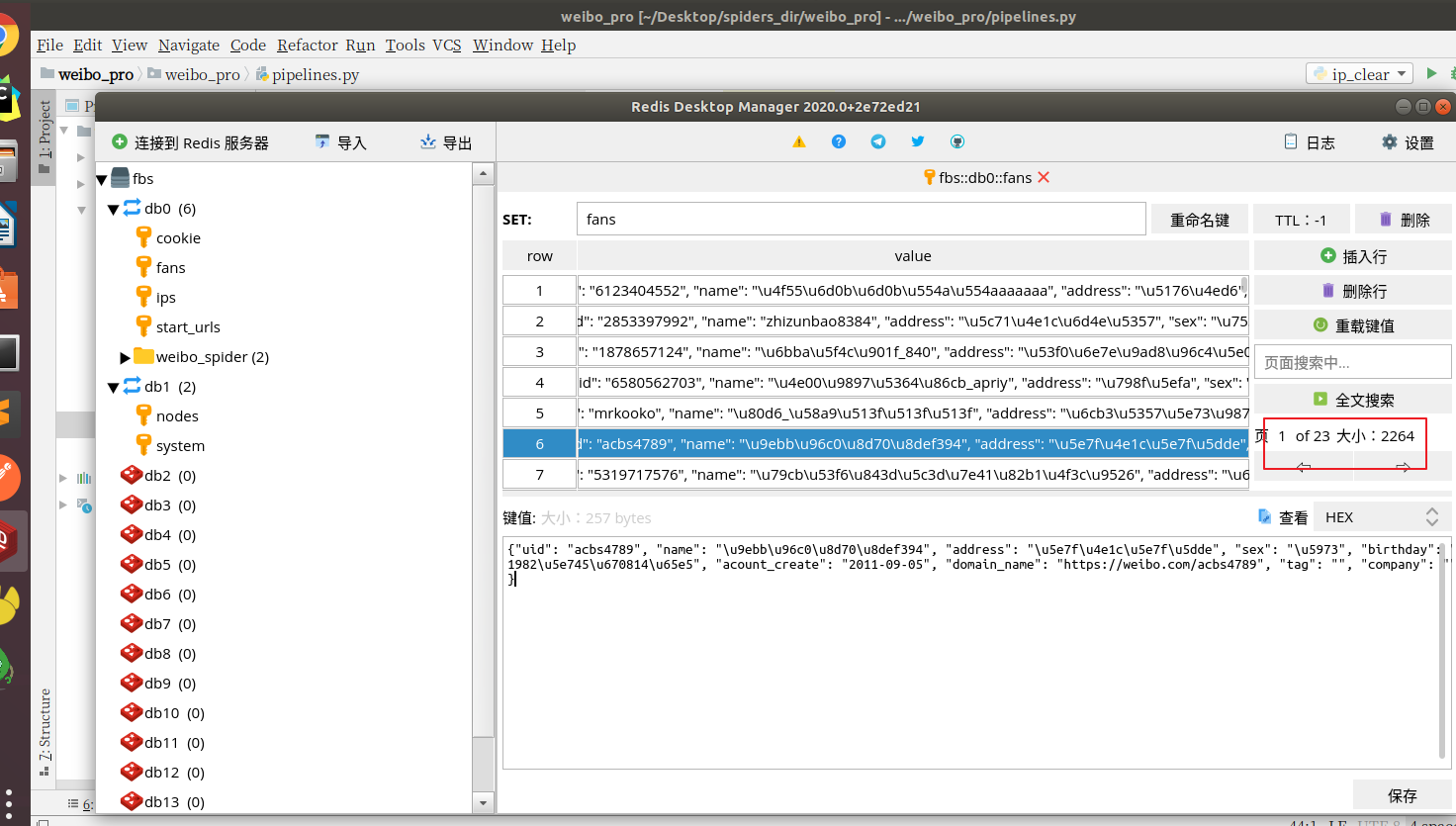
代码:
spider.py
# -*- coding: utf-8 -*- import scrapy import re import time from lxml import etree from weibo_pro.items import WeiboProItem from scrapy_redis.spiders import RedisSpider class WeiboSpiderSpider(RedisSpider): name = 'weibo_spider' # allowed_domains = ['www.weibo.com'] # start_urls = ['https://s.weibo.com/weibo/%s' % (parse.quote(input("输入搜索关键字:>>>").strip()))] redis_key = 'start_urls' def parse(self, response): """ 获取博主的page_id,拼接fansurl,发请求,得到获取粉丝列表所需要携带的参数pids :param response: :return: """ page_id = re.search(r".*?page_id'\]=\'(.*?)\'", response.text).group(1) fans_lst_url = f'https://weibo.com/p/{page_id}/follow?relate=fans' yield scrapy.Request(url=fans_lst_url, dont_filter=True, callback=self.get_fans, meta={"page_id": page_id}) def get_fans(self, response): """ 的到pids,拼接url :param response: :return: """ pids = re.search(r'"(Pl_Official_HisRelation__.*?)"', response.text).group(1).strip(r'\\') page_id = response.meta["page_id"] for page in range(1, 5): fans_lst_url = f'https://weibo.com/p/{page_id}/follow?pids={pids}&relate=fans&page={page}&ajaxpagelet=1&ajaxpagelet_v6=1&__ref=/p/{page_id}/follow?relate=fans&from=rel&wvr=5&loc=hisfan#place&_t=FM_{round(time.time() * 100000)}' # 粉丝列表url yield scrapy.Request(url=fans_lst_url, dont_filter=True, callback=self.fans_info) def fans_info(self, response): """ 解析每一粉丝的详情页url :param response: :return: """ html_str = re.search(r'pl.content.followTab.index.*?"html":.*?"(.*?)"}.*', response.text).group(1).replace( r"\r\n", "").replace(r"\t", "").replace(r'\"', "").replace(r"\/", "/") tree = etree.HTML(html_str.replace(r"\r\n", "").replace(r"\t", "").replace(r'\"', "").replace(r"\/", "/")) li_lst = tree.xpath('//*[@class="follow_list"]/li') for li in li_lst: # 每个粉丝详情url try: fan_info_url = "https://weibo.com/" + li.xpath("./dl/dt/a/@href")[0] # 向每个粉丝的主页发送请求 yield scrapy.Request(url=fan_info_url, dont_filter=True, callback=self.fan_info, meta=response.meta) yield scrapy.Request(url=fan_info_url, dont_filter=True, callback=self.parse) except Exception: pass #### 接受主页的信息,获取详情信息 def fan_info(self, response): """ 获得粉丝主页的信息 获取粉丝的page_id,并发请求 :param response: :return: """ page_id = re.search(r".*?page_id'\]=\'(.*?)\'", response.text).group(1) uid = response.url.split("/")[-1] # # 详细url fan_info_url = f'https://weibo.com/p/{page_id}/info?mod=pedit_more&ajaxpagelet=1&ajaxpagelet_v6=1&__ref=/u/{uid}?is_all=1&_t=FM_{round(time.time() * 100000)}' yield scrapy.Request(url=fan_info_url, callback=self.get_data, dont_filter=True,meta={"uid":uid}) # 详情信息页发请求 def get_data(self, response): """ 提取数据 :param response: :return: """ html = re.search( r'<script>parent.FM.view\({"ns":"","domid":"Pl_Official_PersonalInfo.*?"html":"(.*)?"}\)</script>', response.text) if html: html = html.group(1).replace(r"\r\n", "").replace(r'\"', "").replace(r"\/", "/") tree = etree.HTML(html) li_lst = tree.xpath('//*[@class="clearfix"]/li') dic = { "昵称": "name", "所在地": "address", "性别": "sex", "生日": "birthday", "注册时间": "acount_create", "博客": "blog", "个性域名": "domain_name", "标签": "tag", "公司": "company" } items = WeiboProItem() # 规则化识别数据 item = {} # for li in li_lst: x = "".join(li.xpath('.//text()')).replace(" ", "") for k, v in dic.items(): if k in x: item[v] = x.split(":")[-1] else: item.setdefault(v, "") uid = response.meta["uid"] items['uid'] = uid items['name'] = item['name'] items['address'] = item['address'] items['sex'] = item['sex'] items['birthday'] = item['birthday'] items['acount_create'] = item['acount_create'] items['domain_name'] = item['domain_name'] items['tag'] = item['tag'] items['company'] = item['company'] yield items
middlewares.py
# -*- coding: utf-8 -*- import redis import json import random from scrapy import signals from weibo_pro.settings import REDIS_HOST,REDIS_PORT from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware class WeiboProDownloaderMiddleware: # redis_pool pool = redis.ConnectionPool(host=REDIS_HOST, port=REDIS_PORT, decode_responses=True) @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s @property def get_cookie(self): # cookie池 r = redis.Redis(connection_pool=self.pool) cook = r.lrange("cookie", 0, -1) cookie = random.choice([json.loads(item) for item in cook]) cookie.pop("username") return cookie @property def get_ip(self): # ip池 r2 = redis.Redis(connection_pool=self.pool, decode_responses=True) all_ips = r2.sscan_iter('ips', match=None, count=None) all_ips = [i for i in all_ips] if not all_ips: print("您没有代理ip了,请更新ip库!") while not all_ips: all_ips = r2.sscan_iter('ips', match=None, count=None) all_ips = [i for i in all_ips] ip = random.choice(all_ips) return ip def process_request(self, request, spider): # 设置cookie cookie = self.get_cookie request.cookies = cookie # 注意是:cookies, # 设置代理 request.meta['http_proxy'] = self.get_ip return None def process_response(self, request, response, spider): return response def process_exception(self, request, exception, spider): cookie = self.get_cookie request.cookies = cookie # 设置代理 request.meta['http_proxy'] = self.get_ip return request def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name) # User-Agetn 下载中间件 class RotateUserAgentMiddleware(UserAgentMiddleware): user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/531.21.8 (KHTML, like Gecko) Version/4.0.4 Safari/531.21.10", "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/533.17.8 (KHTML, like Gecko) Version/5.0.1 Safari/533.17.8", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.19.4 (KHTML, like Gecko) Version/5.0.2 Safari/533.18.5", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-GB; rv:1.9.1.17) Gecko/20110123 (like Firefox/3.x) SeaMonkey/2.0.12", "Mozilla/5.0 (Windows NT 5.2; rv:10.0.1) Gecko/20100101 Firefox/10.0.1 SeaMonkey/2.7.1", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_5_8; en-US) AppleWebKit/532.8 (KHTML, like Gecko) Chrome/4.0.302.2 Safari/532.8", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_4; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.464.0 Safari/534.3", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_5; en-US) AppleWebKit/534.13 (KHTML, like Gecko) Chrome/9.0.597.15 Safari/534.13", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.186 Safari/535.1", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.54 Safari/535.2", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7", "Mozilla/5.0 (Macintosh; U; Mac OS X Mach-O; en-US; rv:2.0a) Gecko/20040614 Firefox/3.0.0 ", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.0.3) Gecko/2008092414 Firefox/3.0.3", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1) Gecko/20090624 Firefox/3.5", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.6; en-US; rv:1.9.2.14) Gecko/20110218 AlexaToolbar/alxf-2.0 Firefox/3.6.14", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" ] def __init__(self, user_agent=''): super().__init__() self.user_agent = user_agent # 重写父类的process_request方法 def process_request(self, request, spider): # 这句话用于随机选择user-agent ua = random.choice(self.user_agent_list) # ua池 request.headers['User-Agent'] = ua
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class WeiboProItem(scrapy.Item): # define the fields for your item here like: uid = scrapy.Field() name = scrapy.Field() address = scrapy.Field() sex = scrapy.Field() birthday = scrapy.Field() acount_create = scrapy.Field() blog = scrapy.Field() domain_name = scrapy.Field() tag = scrapy.Field() company = scrapy.Field() pass
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymongo import redis import json from weibo_pro.settings import REDIS_HOST,REDIS_PORT class WeiboProPipeline: r = None mycol = None pool = redis.ConnectionPool(host=REDIS_HOST, port=REDIS_PORT, decode_responses=True) def open_spider(self, spider): myclient = pymongo.MongoClient('mongodb://127.0.0.1:27017') mydb = myclient["weibo_info"] self.mycol = mydb["weibo_user"] self.r = redis.Redis(connection_pool=self.pool,decode_responses=True) def process_item(self, item, spider): items = {} items['uid'] = item['uid'] items['name'] = item['name'] items['address'] = item['address'] items['sex'] = item['sex'] items['birthday'] = item['birthday'] items['acount_create'] = item['acount_create'] items['domain_name'] = item['domain_name'] items['tag'] = item['tag'] items['company'] = item['company'] print(items) # self.mycol.insert_one(items) # 写入mongodb self.r.sadd("fans",json.dumps(items)) # 写入redis集合去重 return item def close_spider(self, spider): # 倒入mongodb for fan in self.r.sscan_iter("fans"): self.mycol.insert_one(json.loads(fan)) pass
settings.py
# -*- coding: utf-8 -*- BOT_NAME = 'weibo_pro' SPIDER_MODULES = ['weibo_pro.spiders'] NEWSPIDER_MODULE = 'weibo_pro.spiders' # Obey robots.txt rules ROBOTSTXT_OBEY = False LOG_LEVEL = 'ERROR' DOWNLOADER_MIDDLEWARES = { 'weibo_pro.middlewares.WeiboProDownloaderMiddleware': 543, 'weibo_pro.middlewares.RotateUserAgentMiddleware': 543, # 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None, } ITEM_PIPELINES = { 'weibo_pro.pipelines.WeiboProPipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, # crawlab平台持久化存储 # 'crawlab.pipelines.CrawlabMongoPipeline': 888 } DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True # redis 连接配置 REDIS_HOST = '192.168.43.77' REDIS_PORT = 6379
启动:向redis中放入某博主的主页url:
127.0.0.1:6379> lpush start_urls https://weibo.com/u/2006277991

 浙公网安备 33010602011771号
浙公网安备 33010602011771号