

浏览器调试分析
商品列表url分析
打开京东网站,随便输入一个关键字,点开抓包工具(ctrl+F)
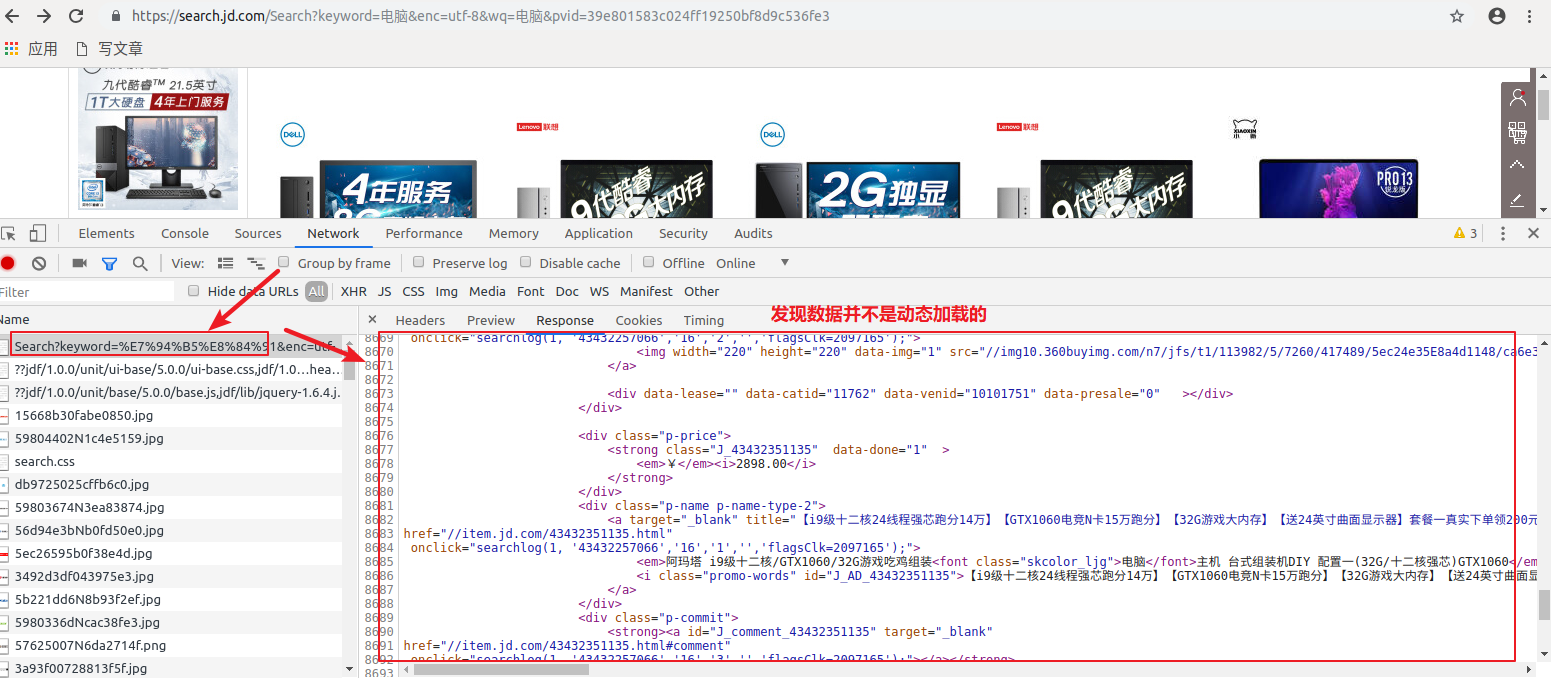
看到不是动态加载的是不是有点激动?但是你拿到的并不是全数据,为什么这么说呢,往下看
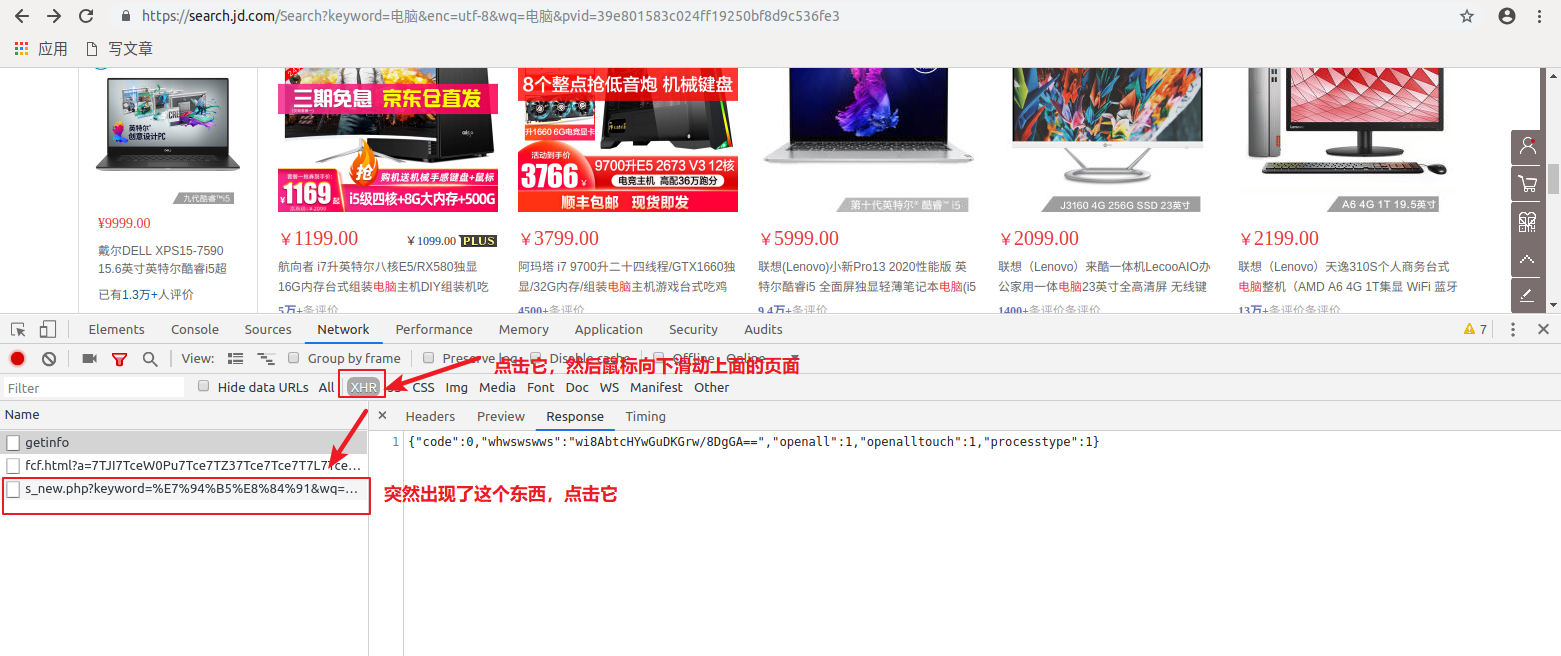
当滑动滚轮时,出现了新数据
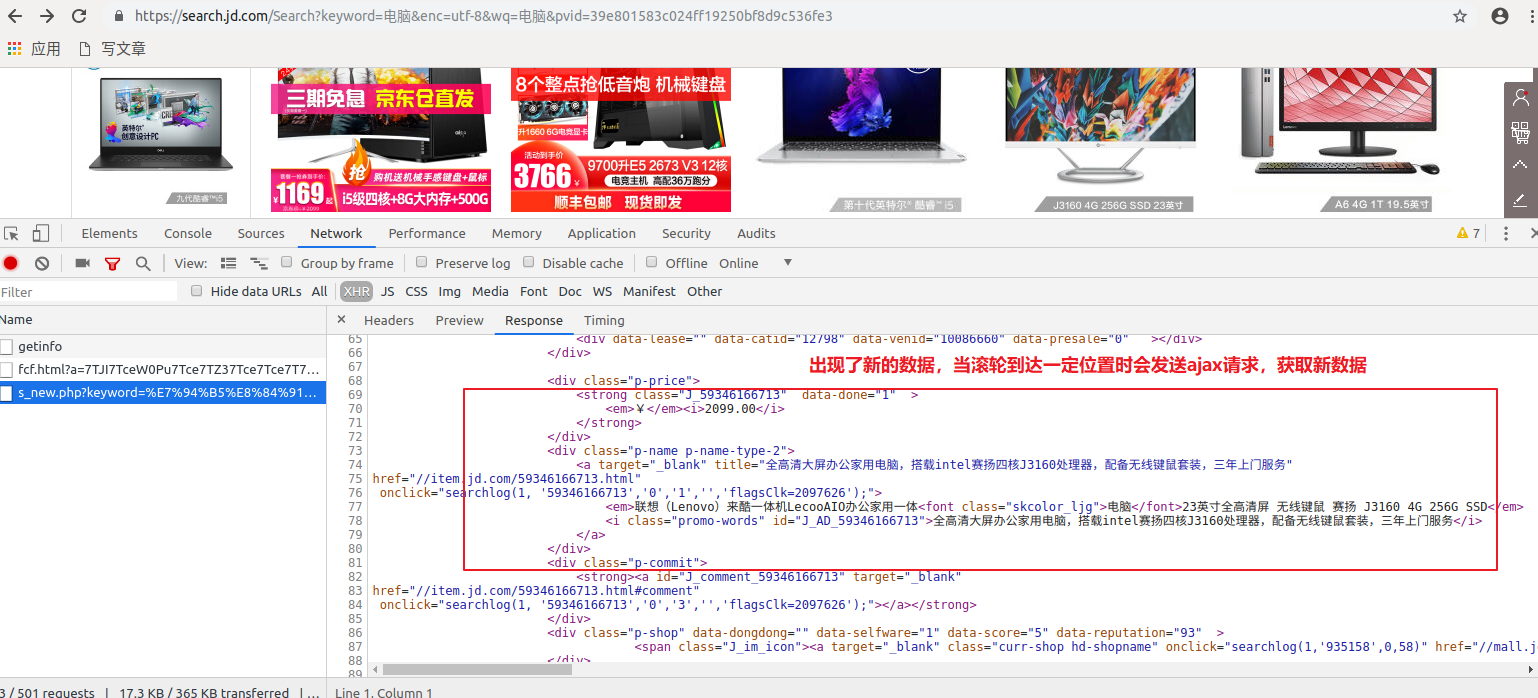
查看请求url及参数
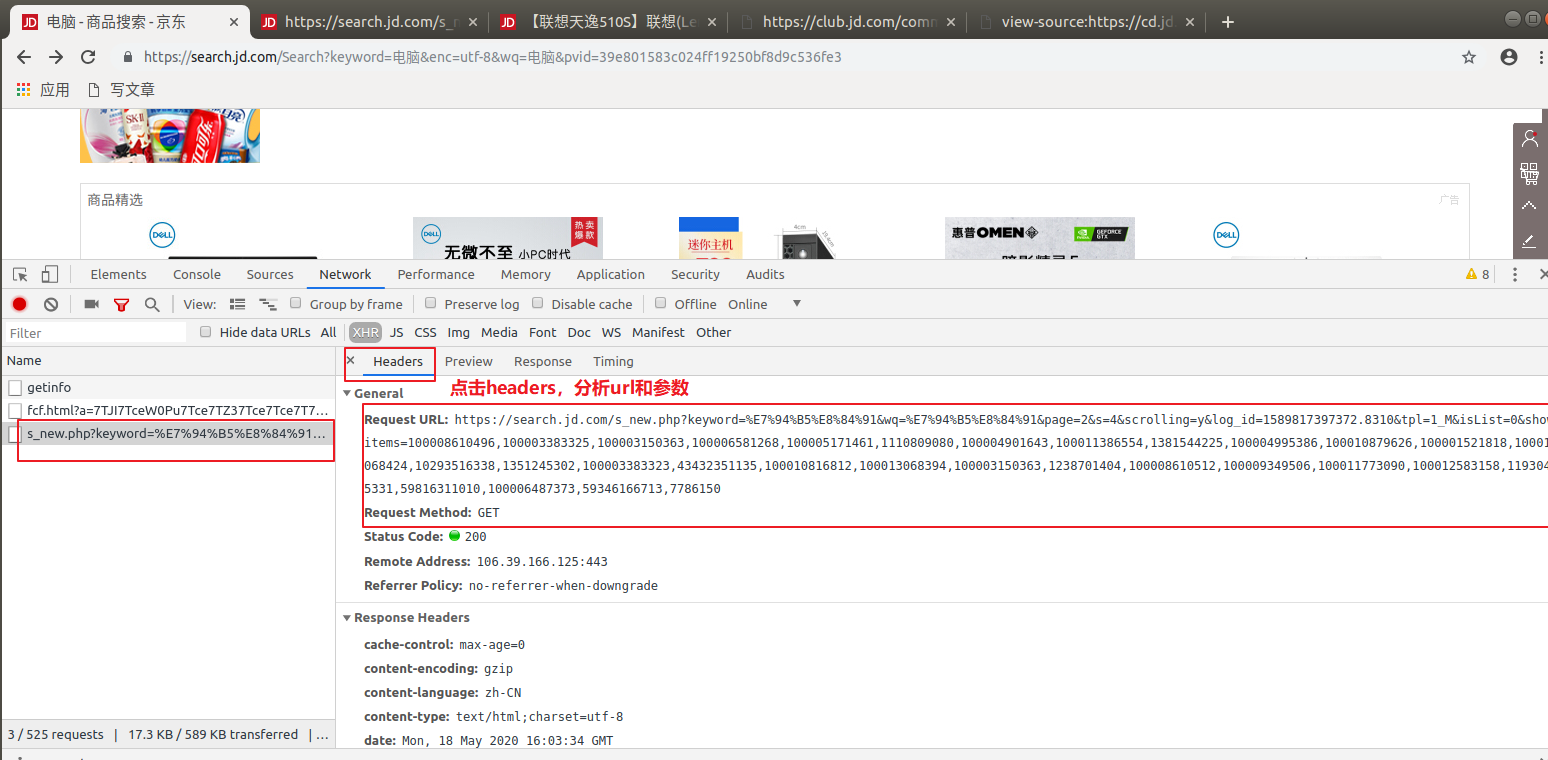
尝试去掉不必要的参数,经过多次的尝试发现,要获取到数据只需要想它发送请求就可以拿到数据:
url:https://search.jd.com/s_new.php?keyword=电脑&page=1&s=30
# 注意page与s的关系,注意最大页码的值(商品页面显示页码为100,那么你在拼接url时,最大页码必须是100*2) 参数: keyword:搜索的关键字 page:页码数 s:每一页的数据条数
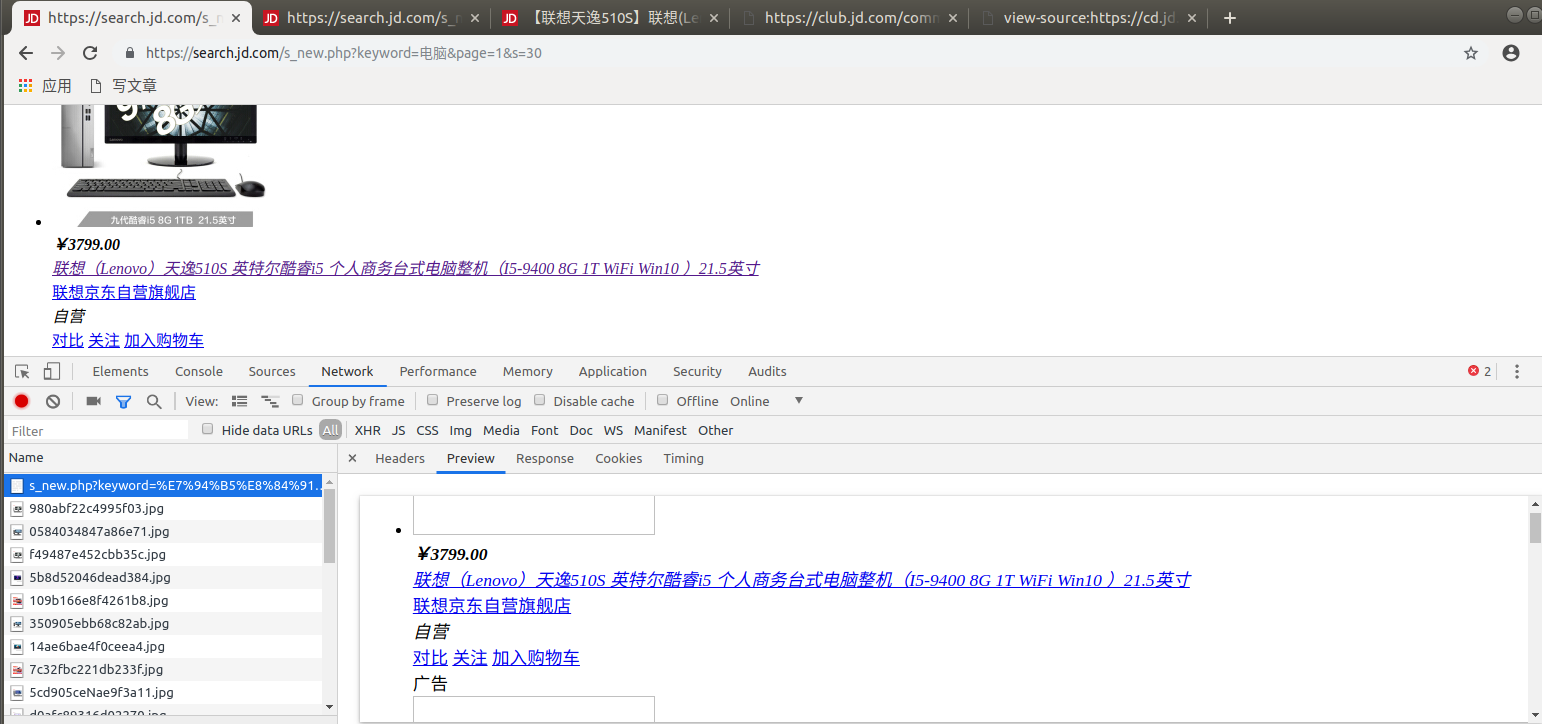
但是,你会发现他只能拿到三十几条左右的数据,而正常是当滚轮滑动到底端时会有六十几条数据,这时候不要慌,因为你会发现当url的page=2&s=60时,就会出现,原来滚轮滑动到底部后获取的新数据
因此,当滚轮滑动到底部时,原来的1页,展示了两页的数据。
既然明白了他们的数据请求方式,那么拿到所有的商品列表就很简单了
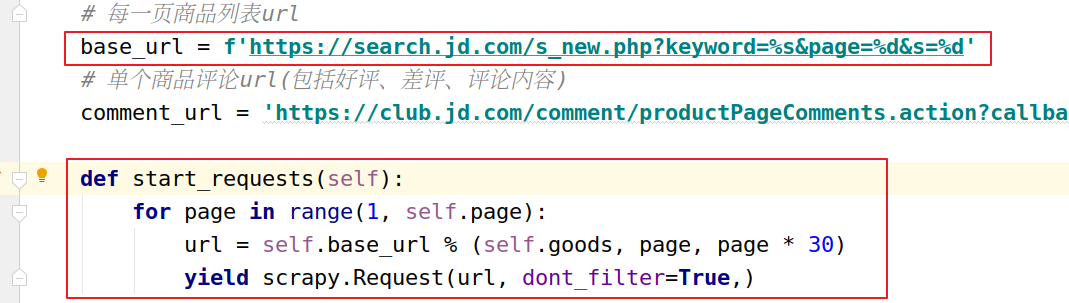
拿到后发送请求获取到response,进行xpath解析就可以了
详情页评论分析
上面我们已经获取了商品列表页需要的数据,记得拿详情页的url
接下来继续分析详情页数据接口的url:随便点击一个商品,抓包,全局搜索
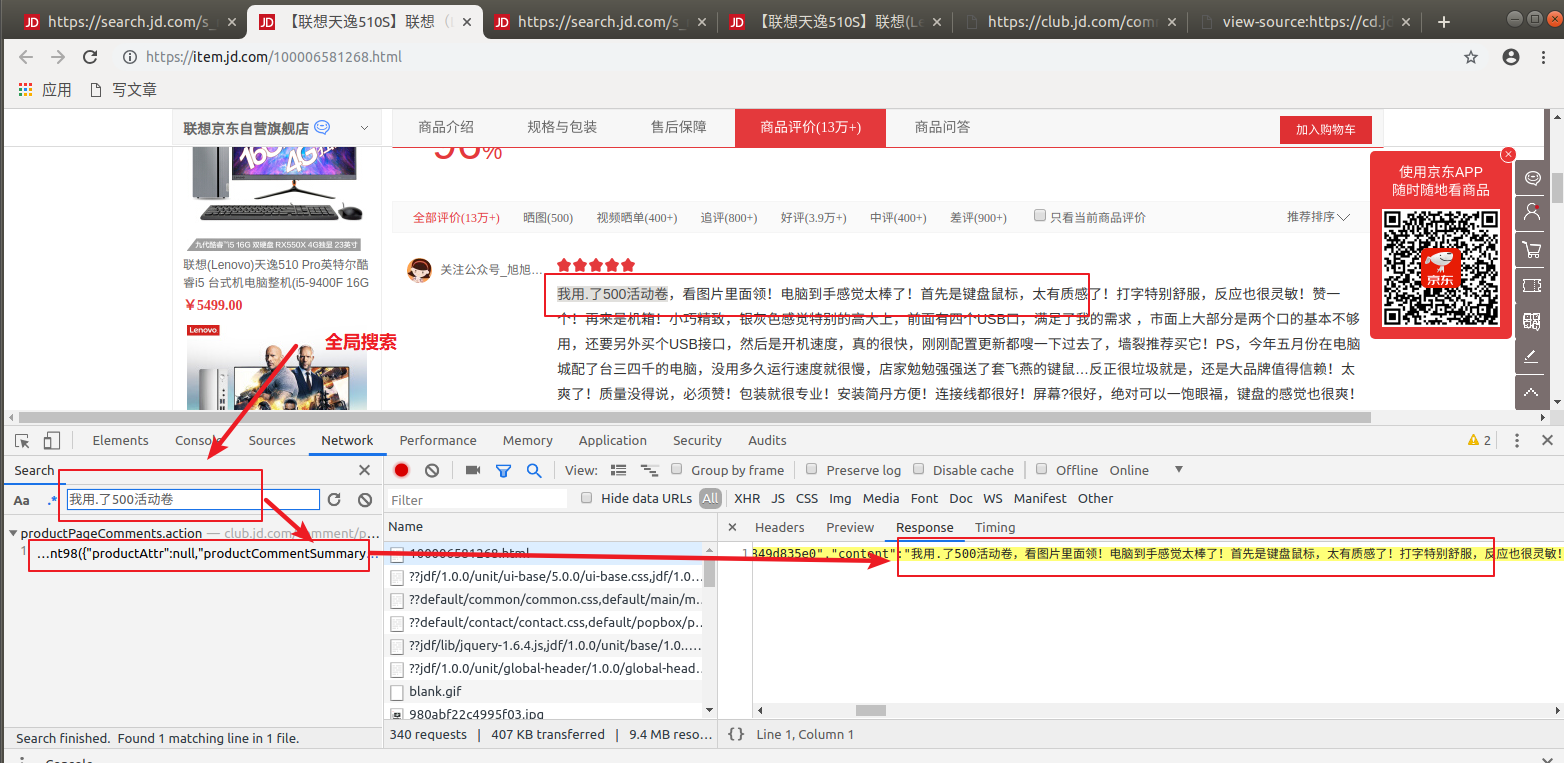
查看请求的url:
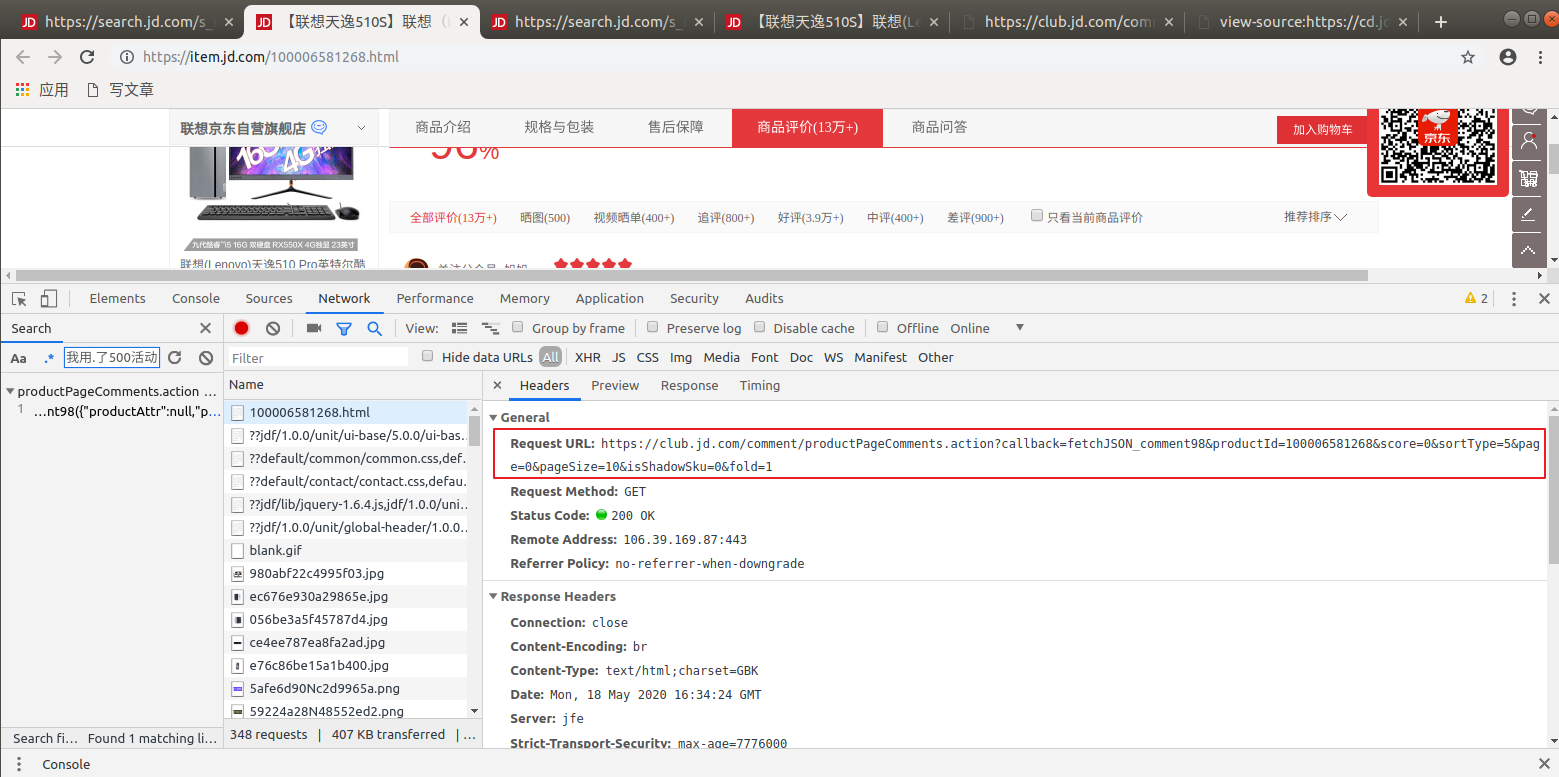
分析url和参数:
将这里的请求url输入浏览器地址栏,看能否拿到数据:
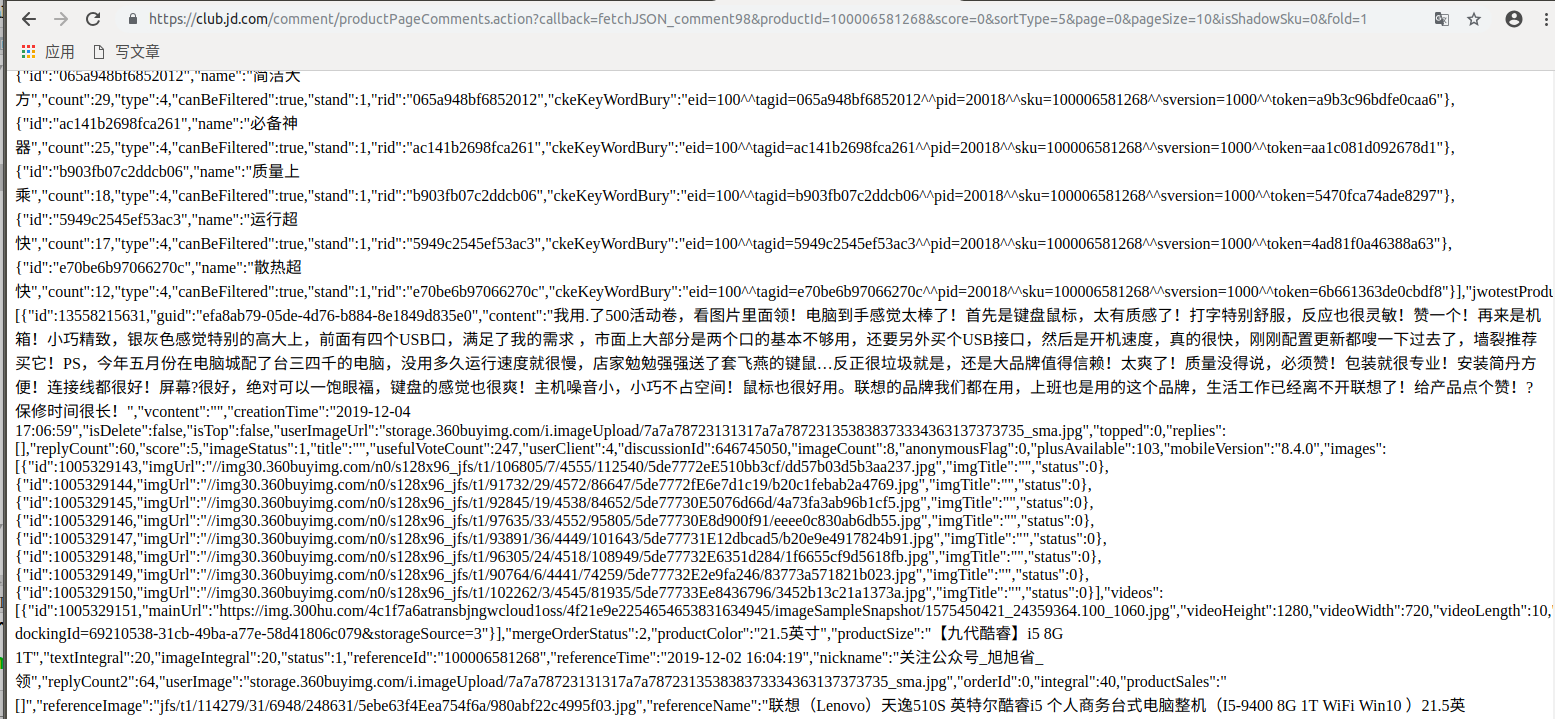
很明显,可以拿到数据,接着我们看携带的参数
url:https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100006581268&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1 参数: callback: fetchJSON_comment98 # 这是个回调函数 productId: 100006581268 # 商品id score: 0 # 不知道啥东西 sortType: 5 # 不知道啥东西 page: 0 # 评论的页码 pageSize: 10 # 每页显示几条数据 isShadowSku: 0 fold: 1
我们虽然拿到这些参数,但是,你会疑惑这些参数是不是通过js动态生成的?怎么获取这些参数呢?
其实:对于这种情况来说,先不要老是想着找它的来源,因为有时候就单纯的获取数据来说,有些参数并不是必须要携带的
这里,我们尝试去掉一些不必要的参数
url:https://club.jd.com/comment/productPageComments.action?productId=100003383325&score=0&sortType=5&page=3&pageSize=10 参数: productId:商品id score:不知道啥东西,但这个必须带 sortType:同上 page:评论的页码 pageSize:每页评论的条数
至此,我们的评论数据接口就搞定了
解决只能爬取70条左右的评论的问题
京东做了反扒机制,当你访问评率过快或者使用单个ip访问的时候只允许你拿70左右的数据,如何解决呢?
ip代理池+设置请求发送的间隔时间:以scrapy框架为例:
IP代理池(本人ip代理是从网上爬取的免费代理,存放在数据库中):
下载器中间件文件:
class AllJdDownloaderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. conn = None cursor = None proxy_list = [] def __init__(self): self.conn = pymysql.Connect(host=MYSQL_IPS_CONNECT['host'], user=MYSQL_IPS_CONNECT['user'], port=MYSQL_IPS_CONNECT['port'], password=MYSQL_IPS_CONNECT['password'], db=MYSQL_IPS_CONNECT['db_name'], charset='utf8') self.cursor = self.conn.cursor() sql = 'select ip,port,http_type from ips' try: self.cursor.execute(sql) # 取数据库中所有的ip all_ip = self.cursor.fetchall() if not all_ip: raise ValueError('您没有代理ip了!') for ips in all_ip: ip, port, http_type = ips self.proxy_list.append(f"{http_type.lower()}s://{ip}:{port}") except Exception as e: print(e) @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): request.meta['http_proxy'] = random.choice(self.proxy_list) request.cookie = COOKIE return None def process_response(self, request, response, spider): print(response['cookies']) if (spider.comment_url.split('?')[0] in request.url): if not response.text: # 如果评论页面数量数据取不到,换代理重新请求 request.meta['http_proxy'] = random.choice(self.proxy_list) return request return response def process_exception(self, request, exception, spider): # 捕获到异常请求,换代理ip,重新发送请求 request.meta['http_proxy'] = random.choice(self.proxy_list) return request def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
设置请求发送间隔时间:
settings.py
DOWNLOAD_DELAY = 2 # 单位秒
然后你就可以开搞了。
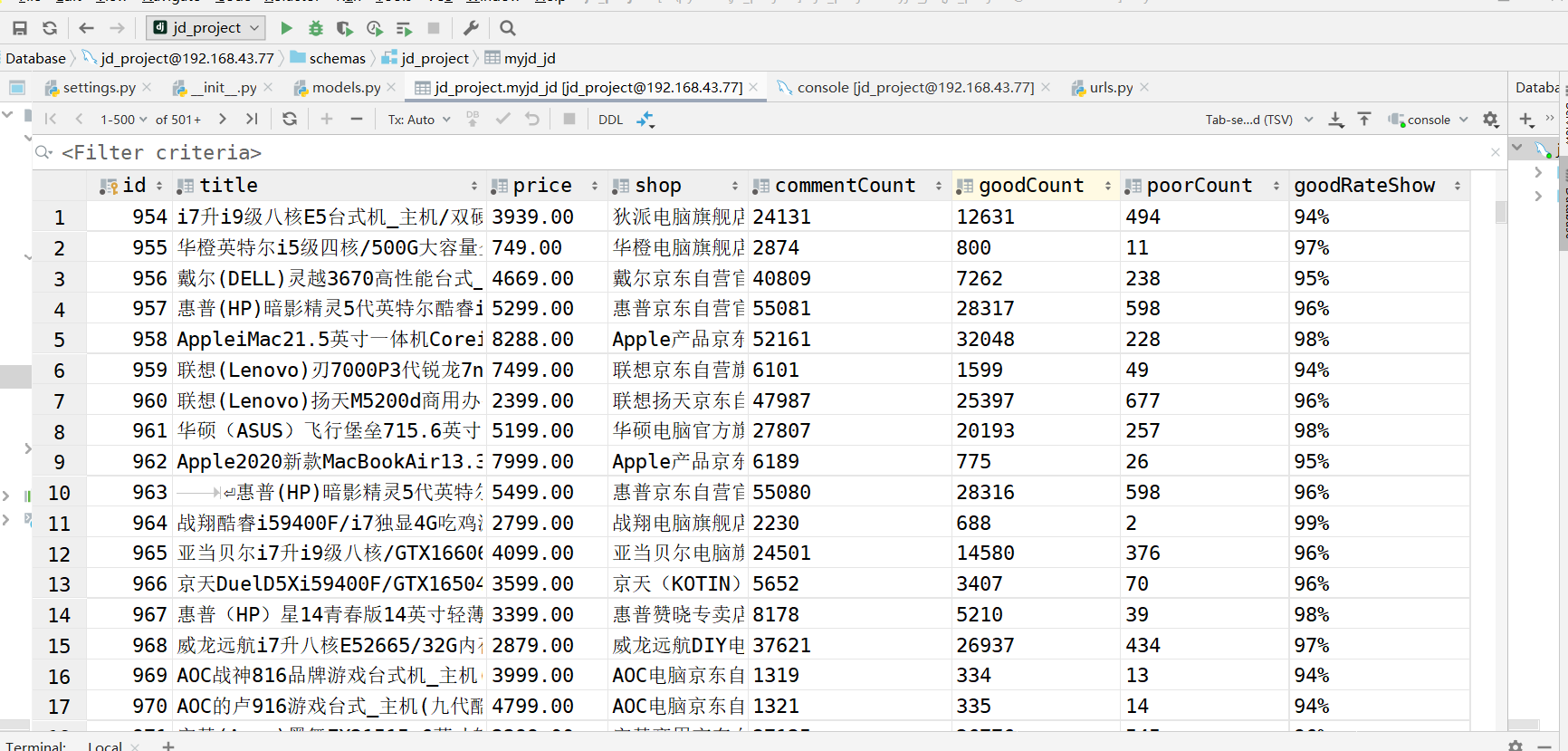
本人此次项目获取的是每个商品的价格、好评、差评、好评度等数据 ,并未爬取评论,但数据接口是相同的,看一下运行结果
总结一下分析的url:
商品列表url: for page in range(1, 200): url = 'https://search.jd.com/s_new.php?keyword=%s&page=%d&s=%d' % ('电脑', page, page * 30) 参数: keyword:搜索关键字 page:列表页码 s:展示的商品数量 评论列表url: for page in range(0,100) url = 'https://club.jd.com/comment/productPageComments.action?productId=%s&score=0&sortType=5&page=%d&pageSize=%d' % ('100003383325',page,10) 参数: productId=100003383325 # 商品id,其他参数不变 score=0 sortType=5 page=0 # 评论页码数, pageSize=10 # 每页评论条数
完。。。。。。。。。。。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号