

一、什么是MQ?
MQ全称为Message Queue 消息队列(MQ)是一种应用程序对应用程序的通信方法。
MQ是消费-生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取队列中的消息。这样发布者和使用者都不用知道对方的存在。
队列
概念:先进先出的一种数据结构。(联想到栈,栈是先进后出的数据结构)
消息队列
消息队列可以简单理解为:把要传输的数据放在队列中。
二、消息队列是用来干什么的?
消息队列是一种中间件,它是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削峰,实现高性能,高可用,可伸缩和最终一致性架构。
外卖系统消息推送:
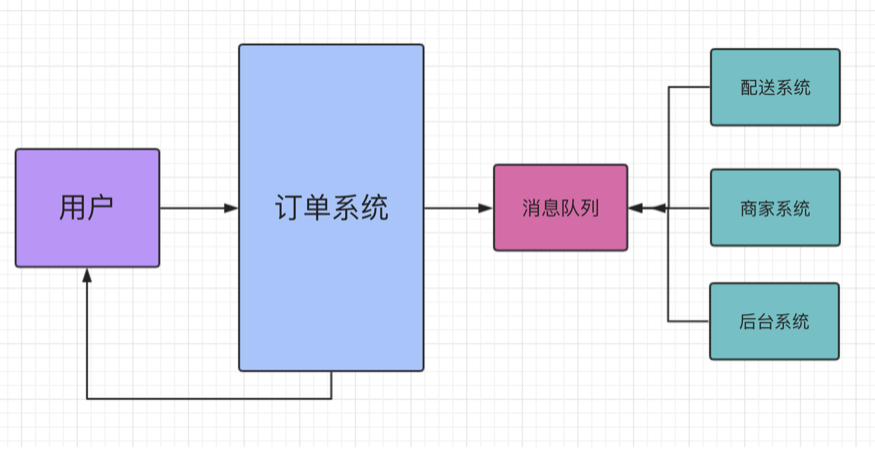
解耦:系统与系统之间直接对接会存在耦合性过高的情况,导致代码在维护的时候会消耗大量的时间和精力。
异步消息:消费者这从消息队列中获取消息后,互不干扰,各自拿到需要的数据后,各做各的。
流量削峰:在接收请求的系统之前创建一个消息队列,每次请求过来都先经过消息队列,这样极大的保护了系统,免受请求过多而宕机的危险
三、RabbitMQ
rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。
安装:内含erlang环境包,以及RabbitMQ软件包 windows版
链接:https://pan.baidu.com/s/1RvC0V8t-HIjqGlDTY6SiCg
提取码:np9h


windows安装rabbitmq 直接下载erlang安装包,和rabbitmq-server安装包 1.下载erlang的安装包 http://erlang.org/download/otp_win64_22.2.exe 2.下载rabbitmq-server服务端安装包 https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.2/rabbitmq-server-3.8.2.exe 3.先安装erlang,再安装rabiitmq 4.配置环境变量,加载erlang和rabbitmq 在admin用户的PATH中,追加erlang和rabbitmq的可执行命令目录,路径即可 ############路径按照自己的来 C:\Program Files\erl10.6\bin; C:\Program Files\RabbitMQ Server\rabbitmq_server-3.8.2\sbin 5.重新开启cmd命令行,重新加载PATH值 6.开启rabbitmq后台管理页面,测试命令是否可以用 rabbitmq-plugins enable rabbitmq_management 7.此时可以访问本地的后台管理界面 http://127.0.0.1:15672/ 8.创建rabbitmq用户,用于连接服务端,创建消息队列 rabbitmqctl add_user admin admin #创建用户,密码 rabbitmqctl set_user_tags admin administrator #设置用户管理员权限 rabbitmqctl set_permissions -p "/" admin ".*" ".*" ".*" #设置用户允许访问所有的队列 9.重启rabbitmq服务端,用yuanhao用户登录 在win中找到服务 -> 找到rabbitmq -> 重启此服务 10.用你的账号密码登录rabbitmq-server服务端 linux安装rabbitmq centos系列 yum install rabbitmq-server erlang -y
四、RabbitMQ工作模式
1. 简单模式
生产者
### 生产者 import pika # 连接RabbitMQ服务端 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) # 实例化一个对象 channel = connection.channel() # 申明一个队列 channel.queue_declare(queue='hello') # 将数据放入队列 channel.basic_publish(exchange='', #空字符串表示默认为简单模式 routing_key='hello', #指定队列名称 body='Hello World!') #放入的数据 print(" [x] Sent 'Hello World!'")
消费者
### 消费者 import pika # 连接RabbitMQ服务端 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 申明一个队列 channel.queue_declare(queue='hello') # 定义回调函数,当消费者从消息队列中拿到数据时,会将数据传给回调函数,并执行。 def callback(ch, method, properties, body): """ 回调函数 """ print(" [x] Received %r" % body) # 从消息队列中获取数据(注意pika版本,这里pika的版本是1.11.0,前面版本的参数会有不同) channel.basic_consume(queue='hello', #指定从哪个消息队列中拿 auto_ack=True, # 默认(自动)应答,消息队列收到消费者的回应后会销毁数据记录。(no_ack=True) on_message_callback=callback) # 设置回调函数 (callback) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 启动监听队列(类似于线程的启动p.start())
注意:为什么要在生产者和消费者中都申明同一个队列?因为生产环境中我们并不能确定是哪个程序先启动的,如果只在生产者中申明了队列,而消费者中没有,那么当消费者先启动是会因为找不到对应的队列而报错,导致程序终止。
所以为了防止意外,两者都进行申明,并且当队列存在时,再次申明不会报错也不会做任何操作。
2.参数
应答参数:auto_ack
作用:应答参数应用于消费者程序中,是告诉消息队列,我已经取到了这个数据,当消息队列得到这个回应后,它会销毁这条数据的记录。
手动应答的应用场景:当消费者程序意外终止时,消息队列还会保留该条数据,消费者程序再次启动时,又可以拿到数据。
如果为自动应答,那么消费者程序会在拿到数据的第一时间给队列发消息告诉队列拿到了数据,队列也会销毁该数据记录,当回调函数执行过程时,程序发生意外终止时,数据就会丢失。
如果为手动应答,那么消费者程序会在回调函数执行 ch.basic_ack(delivery_tag=method.delivery_tag)语句时给队列发送回应,队列才会销毁该数据记录,当回调函数执行过程时,程序发生意外终止时,回应语句并不会执行,消息队列也就收不到回应,那么数据记录也不会在第一时间销毁,当消费者程序再次启动时又可以拿到这条数据。
默认(自动)应答:
auto_ack=True
代码:
channel.basic_consume(queue='hello', #指定从哪个消息队列中拿 auto_ack=True, # 默认(自动)应答 on_message_callback=callback) # 设置回调函数
手动应答:
auto_ack=False
ch.basic_ack(delivery_tag=method.delivery_tag)
代码:
# 定义回调函数,当消费者从消息队列中拿到数据时,会将数据传给回调函数,并执行。 def callback(ch, method, properties, body): """ 回调函数 """ print(" [x] Received %r" % body) ch.basic_ack(delivery_tag=method.delivery_tag) # 手动应答 # 从消息队列中获取数据(注意pika版本,这里pika的版本是1.11.0,前面版本的参数会有不同) channel.basic_consume(queue='hello', #指定从哪个消息队列中拿 auto_ack=False, # 手动应答 on_message_callback=callback) # 设置回调函数
持久化参数
作用:将消息队列中的数据写入磁盘。
为什么使用持久化存储?消息队列中的数据一般都存储在内存中,而当服务器意外断电时,内存中的数据就会丢失,所以为了保护数据,开启持久化存储。
生产者代码:
......
#声明queue channel.queue_declare(queue='hello2', durable=True) # 若声明过,则换一个名字 channel.basic_publish(exchange='', routing_key='hello2', body='Hello World!', properties=pika.BasicProperties(delivery_mode=2,) # 注意:在生产者程序中需要加这个参数,消费者模式中不需要,因为这个方法中没有这个关键字参数 )
......
消费者代码:
# 申明一个队列 channel.queue_declare(queue='hello4',durable=True) ...... # 从消息队列中获取数据(注意pika版本,这里pika的版本是1.11.0,前面版本的参数会有不同) channel.basic_consume(queue='hello4', # 指定从哪个消息队列中拿 auto_ack=False, # 默认(自动)应答,消息队列收到消费者的回应后会销毁数据记录。(no_ack=True) on_message_callback=callback) # 设置回调函数 (callback) ......
分发参数
有两个消费者同时监听一个的队列。其中一个线程sleep2秒,另一个消费者线程sleep1秒,但是处理的消息是一样多。这种方式叫轮询分发(round-robin)不管谁忙,都不会多给消息,总是你一个我一个。想要做到公平分发(fair dispatch),必须关闭自动应答ack,改成手动应答。使用basicQos(perfetch=1)限制每次只发送不超过1条消息到同一个消费者,消费者必须手动反馈告知队列,才会发送下一个。
# 设置在消费者程序中 # 声明一个队列 ..... # 将分发模式调整为公平模式(谁先执行完,给谁发送数据) channel.basic_qos(prefetch_count=1) # 回调函数 .......
3. 完整的简单模式代码
生产者:
### 生产者 import pika # 连接RabbitMQ服务端 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) # 实例化一个对象 channel = connection.channel() # 申明一个队列 channel.queue_declare(queue='hello4', durable=True) # durable 开启持久化存储 # 将数据放入队列 channel.basic_publish(exchange='', # 空字符串表示默认为简单模式 routing_key='hello4', # 指定队列名称 body='Hello World!', # 放入的数据 properties=pika.BasicProperties(delivery_mode=2,) ) print(" [x] Sent 'Hello World!'")
消费者代码:
### 消费者 import pika # 连接RabbitMQ服务端 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 申明一个队列 channel.queue_declare(queue='hello4',durable=True) # 将分发模式调整为公平模式(谁先执行完,给谁发送数据) channel.basic_qos(prefetch_count=1) # 定义回调函数,当消费者从消息队列中拿到数据时,会将数据传给回调函数,并执行。 def callback(ch, method, properties, body): """ 回调函数 """ print(" [x] Received %r" % body) # 手动应答,当 ch.basic_ack(delivery_tag=method.delivery_tag) # 从消息队列中获取数据(注意pika版本,这里pika的版本是1.11.0,前面版本的参数会有不同) channel.basic_consume(queue='hello4', # 指定从哪个消息队列中拿 auto_ack=False, # 默认(自动)应答,消息队列收到消费者的回应后会销毁数据记录。(no_ack=True) on_message_callback=callback ) # 设置回调函数 (callback) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() # 启动监听队列(类似于线程的启动p.start())
3. 交换机模式
原理图:
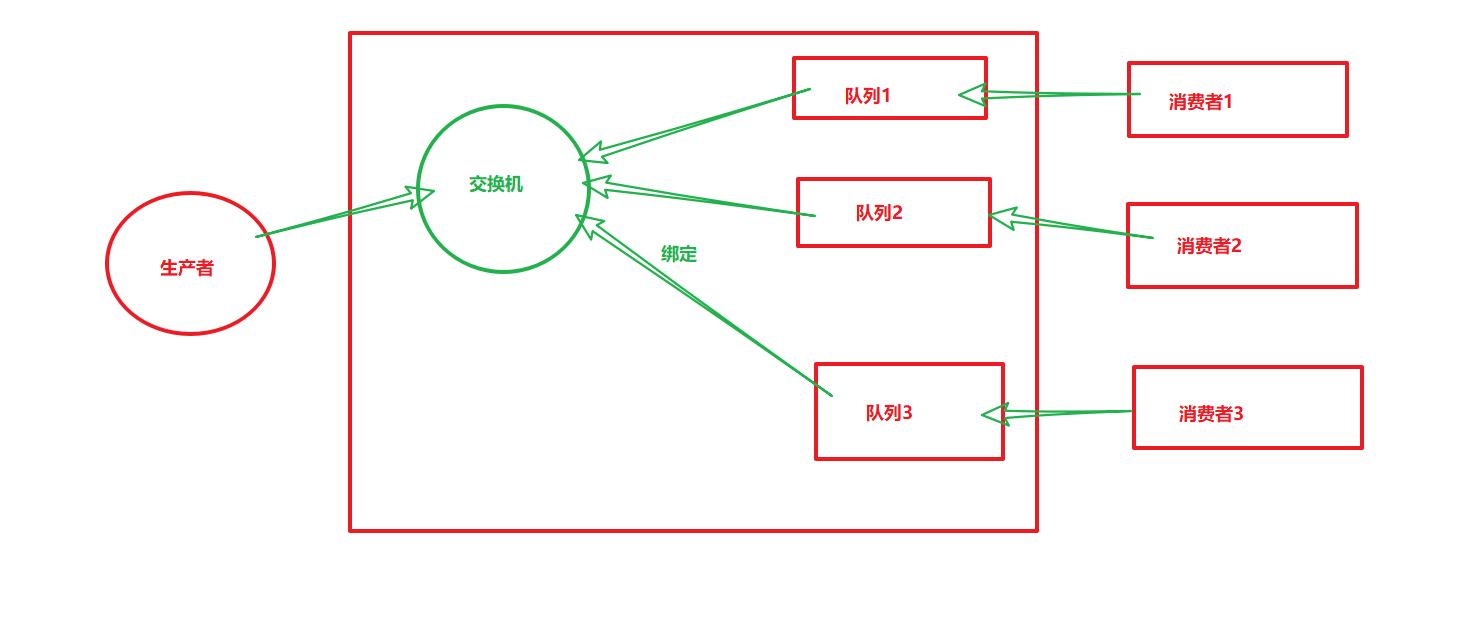
1、发布订阅
发布订阅和简单的消息队列区别:发布订阅会将消息(复制很多份)发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
生产者代码:
# 生产者 import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel()
# 申明交换机的名字和类型,类型的名字是固定的 channel.exchange_declare(exchange='logs', exchange_type='fanout') message = "info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close()
消费者代码:
# 消费者 import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs',exchange_type='fanout')
# 声明(随机名称)消息队列,因为每个消费者都有自己的消息队列,所以名字随意,但不能重复 result = channel.queue_declare("",exclusive=True) queue_name = result.method.queue
# 绑定交换机 channel.queue_bind(exchange='logs',queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=callback) channel.start_consuming()
2、交换机之关键字
生产者:与发布订阅的不同在于生产者发送数据给交换机时,会赋予这条数据关键字,而交换机在分配数据时会根据消费者要接受的的数据的关键字去分配,这样消费者可以拿到自己想要的数据。
代码:
# 生产者 import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs2', exchange_type='direct') # 关键字模式 message = "info: Hello Yuan!" channel.basic_publish(exchange='logs2', routing_key='info', # 关键字模式 body=message) print(" [x] Sent %r" % message) connection.close()
3、交换机之通配符
# 代表多个单词
* 代表一个单词
与关键字的区别:生产者发送数据给交换机时,会赋予这条数据关键字,而交换机在分配数据时会根据消费者要接受的的数据的能够匹配到的关键字去分配,这样消费者也可以拿到自己想要的数据。
生产者代码:
# 生产者 import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs3', exchange_type='topic') message = "info: Hello ERU!" channel.basic_publish(exchange='logs3', routing_key='europe.weather', # 关键字 body=message) print(" [x] Sent %r" % message) connection.close()
消费者代码:
# 消费者 import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs3', exchange_type='topic') result = channel.queue_declare("",exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange='logs3', queue=queue_name, routing_key="#.news") print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(queue=queue_name, auto_ack=True, on_message_callback=callback) channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号