高级人工智能系列(一)——贝叶斯网络、概率推理和朴素贝叶斯网络分类器
高级人工智能系列(一)——贝叶斯网络、概率推理和朴素贝叶斯网络分类器
初学者整理,如有错误欢迎指正。
一、概率论基础
1.1 样本空间 Ω
样本空间是随机试验中所有可能的取值的集合。
比如,掷骰子,结果有1-6 六种可能,那么样本空间即:
\(Ω = \{1, 2, 3, 4, 5, 6\}\)
1.2 事件空间
样本空间的一个子集。
1.3 条件概率
简单地,现有事件A和事件B,
条件概率 P(A|B)表示事件A在事件B发生的条件下发生的概率。
条件概率计算公式:
\(P(A|B)\) = \(P(AB) \over P(B)\)
\(P(A|B_1,B_2,...,B_n)\) = \(P(A,B_1,B_2,...,B_n) \over P(B_1,B_2,...,B_n)\)
根据条件概率公式,可得到乘法公式:
\(P(AB)\) = \(P(A|B) P(B)\)
\(P(A,B_1,B_2,...,B_n)\) = \(P(A|B_1,B_2,...,B_n) P(B_1,B_2,...,B_n)\)
根据上式可以看出,乘法公式可以链式递归。
观察上述乘法公式,等式右侧仍然包含联合概率
\(P(B_1,B_2,...,B_n)\)
\(P(B_1,B_2,...,B_n)\) = \(P(B_1|B_2,...,B_n) P(B_2,...,B_n)\)
\(P(B_2,...,B_n)\) = \(P(B_2|B_3,...,B_n) P(B_3,...,B_n)\)
\(...\)
\(P(B_{n-1},B_n)\) = \(P(B_{n-1}|B_n)P(B_n)\)
整理可得:
\(P(B_1,B_2,...,B_n)\) = \(∏^n_{i=1}P(B_i|B_1,...,B_{i-1})\)
1.4 伯努利大数定律
在日常生活中,我们很自然地会使用频率去估计一个事件的概率。那么其背后的理论是什么?是伯努利大数定律(🌳定绿)。
伯努利大数定律告诉我们:
进行n重伯努利试验(e.g. 抛n次硬币),其中A事件发生了m次,其概率是p,频率是\(m \over n\).那么,存在任意一个正数ε,使得:
\(lim_{n->∞}\) \(P\{|{m \over n} - p| < ε\} = 1\)
即n->∞时,频率是依概率收敛到概率的。
二、贝叶斯法则
我们可以将\(P(A|B)\)和\(P(B|A)\)这两个条件概率通过贝叶斯公式联系起来:
\(P(A|B)\) = \(P(B|A) P(A) \over P(B)\)
- 其中\(P(A|B)\)叫做后验概率,所谓后验概率,就是说A在B发生的条件下发生的概率,是有一个先决条件的;
- \(P(A)\)叫做先验概率,因为\(P(A)\)表示在没有任何前提条件的情况下A发生的概率;
- \(P(B|A)\)叫做似然;
- 而\(P(B)\)叫做归一化常数(即只把\(P(B)\)当作一个系数来对待),它可以通过全概率公式:
\(P(B)\) = \(∑_iP(B|A_i)P(A_i)\)
这里有必要解释一下全概率公式以更好理解。把A看作一个整体,而B是其中的一部分,那么很容易得到P(B)就是B在A中的占比。现在,将A分成n分,即\(A_1\),...,\(A_n\),此时P(B)就变成了B在\(A_i\)中的占比,比上\(A_i\)在A中的占比,i是从1~n的整数。即上述的全概率公式。
三、贝叶斯网络
贝叶斯网络的拓扑结构是一个有向无环图(DAG)。其节点表示随机变量,如果两个节点之间有因果关系或者非条件独立,则两节点之间会建立一条有向边,有向边由父节点指向子节点。
下面是一个警报网络的贝叶斯网络图:
上述贝叶斯网络图表达的意思是:入室盗窃和地震都可能引发警报器报警,而警报器报警可能会让John和Mary给主人打电话以通知主人。
3.1 贝叶斯网络的三种连接方式
贝叶斯网络中节点的连接方式有三种:顺连、分连和汇连(下图依次从左到右)
顺连
当B未知时,变量A的变化会影响B的置信度的变化,从而间接影响C的置信度,所以此时A间接影响C,A和C不独立。当变量B的置信度确定时,A就不能影响B,从而不能影响C,此时A和C独立,因为此时A和C的通道被阻断了。
分连
分连代表一个原因导致多个结果,当变量D已知时,变量E和F之间就不能相互影响,是独立的,而当变量D未知时,D可以在变量E和F之间传递信息,从而使变量E和F相互影响从而不独立。
汇连
汇连与分连恰好相反,代表多个原因导致一个结果,并且当变量J已知时,变量G的置信度的提高会导致变量H的置信度的降低,从而H和H之间会相互影响所以是不独立的。而当J未知时,变量G和H之间置信度互不影响,他们之间是独立的。
总结
- 顺连中,中间变量B未知时,A C不独立,已知时独立;
- 分连中,中间变量D未知时,E F不独立,已知时独立;
- 汇连中,中间变量J未知时,G H独立,已知时不独立。
3.2 贝叶斯网络中的全概率公式与概率表
贝叶斯网络中的全概率公式有Parent原则,即:
\(P(X_i)\) = \(∏P(X_i|Parent(X_i))\)
例如上述贝叶斯网络图中,全概率:
\(P(B,E,A,J,M)\) = \(P(J|A) P(M|A) P(A|B,E) P(B) P(E)\)
如果某些变量不需要,只需要边缘化不需要的变量(即使其不参与运算即可)
ps.倒是不好理解了,直接考虑\(P(X_i)\) = \(∏P(X_i|Parent(X_i))\)更容易理解一些。
那么,如何在贝叶斯网络中进行事件判断?仍然以警报网络为例,可以看到每个事件发生的概率如下图,其中根节点(B、E)是先验概率,非根节点(A、J、M)则是后验概率(条件概率):
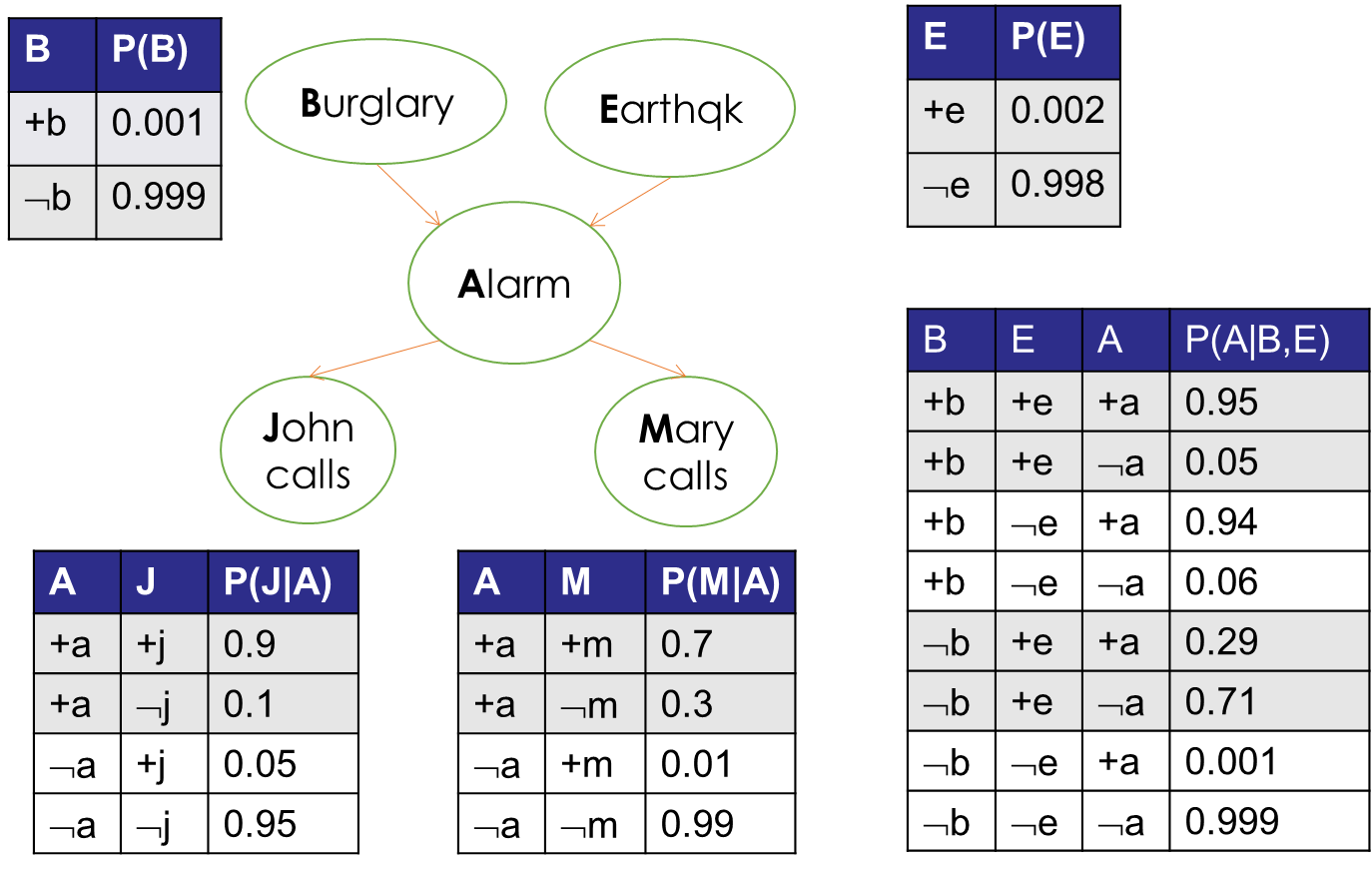
可以看到,上图中每个节点都有一个概率表,表示当前节点在其父节点的条件下(后验概率),不同取值的概率。通过概率表,可以方便地找到每个事件发生与否的可能性。比如:
说明在发生地震、没有发生入室盗窃的情况下,警报器响铃的概率
该事件定在了警报器,那么,只需要在警报器的概率表中寻找“+e、-b、+a”的概率,得到结果0.29。
四、概率推理
概率推理属于推理的一种形式,是根据一系列不确定的信息作出决定时的推理。比如,仍然是第三节中警报网络的例子,其中一个概率推理可以是:
John给主人打电话,警报响了,在这种情况下发生入室盗窃的概率。
实际上,概率推理在实际生活中应用非常广泛,比如医疗行业。我们去医院进行多项检查,会得到很多结果。那么如果推断我们可能会有哪些疾病呢?就可以根据一系列检查数值作为前提,进行概率推理,从而得出患有某种疾病的概率。
概率推理是基于贝叶斯网络及其概率表进行计算的。概率表是根据一个节点的父节点进行条件概率计算得到的,然而只有概率表中的条件概率并不足够推理,但是它可以作为概率推理计算的基础。
概率推理有大类:精确推理和近似推理。我们依次进行介绍。
4.1 精确推理
顾名思义,精确推理需要完整地计算从而得到结果。我们通过例子来理解精确推理。
举一个医疗相关例子:
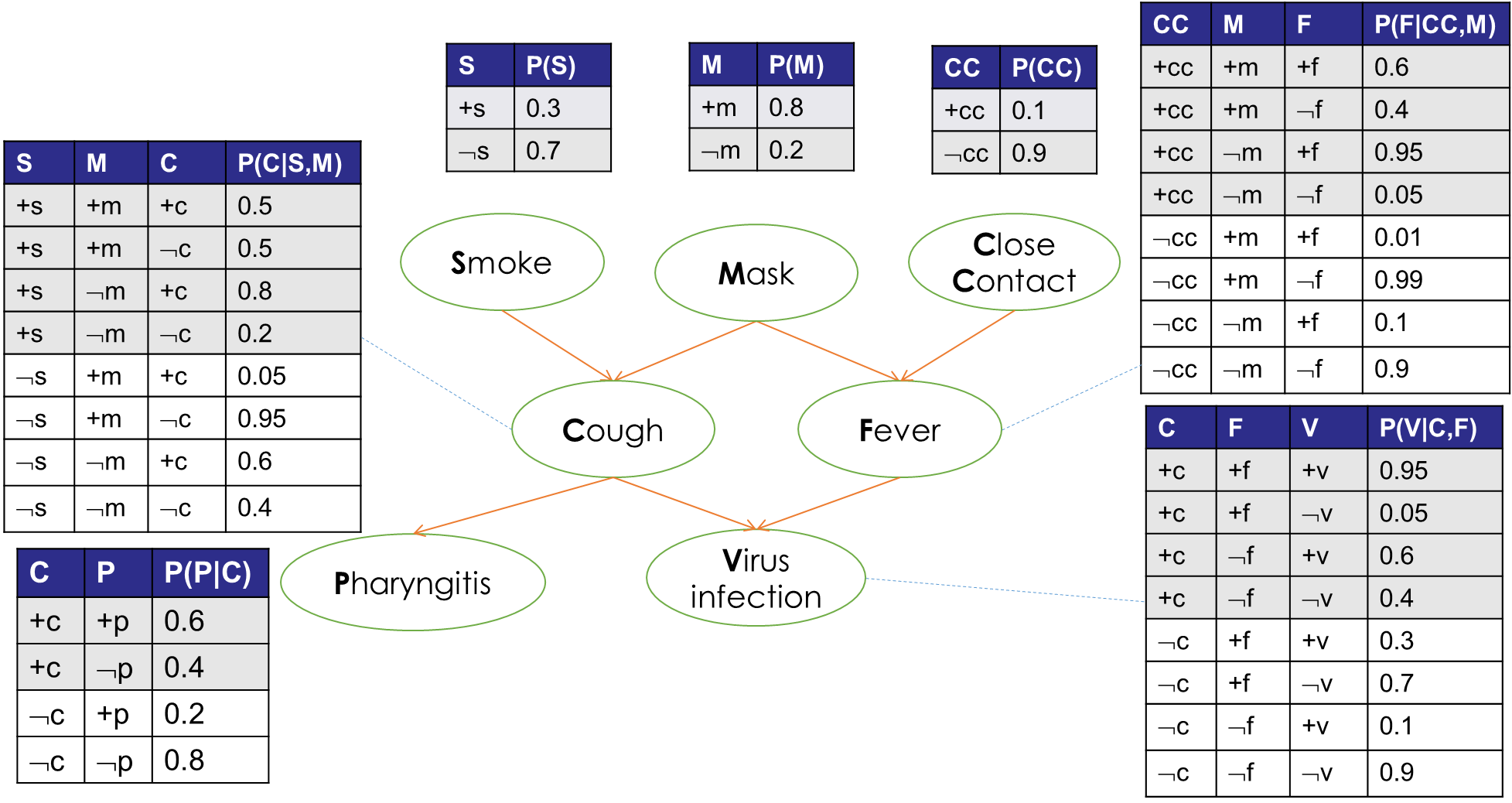
上图是一个贝叶斯网络图,其中概率表已经给出。下面,需要计算:
- 在一个人戴口罩(Mask+)、患了咽炎(Pharyngitis+)且没有密接(Close Contact-)的情况下,他吸烟(Smoke+)的概率。
这看似是一个很奇怪的问题,事实上,通过概率推理,可以得出结果,因为这是一个简单的条件概率:
\(P(S+|M+,P+,CC-)\) = \(P(S+,M+,P+,CC-) \over P(M+,P+,CC-)\)
= \(P(S+,M+,P+,CC-) \over {P(S+,M+,P+,CC-) + P(S-,M+,P+,CC-)}\)
现在,只需要计算\(P(S+,M+,P+,CC-)\)和\(P(S-,M+,P+,CC-)\),即可得到目标结果。
其中,
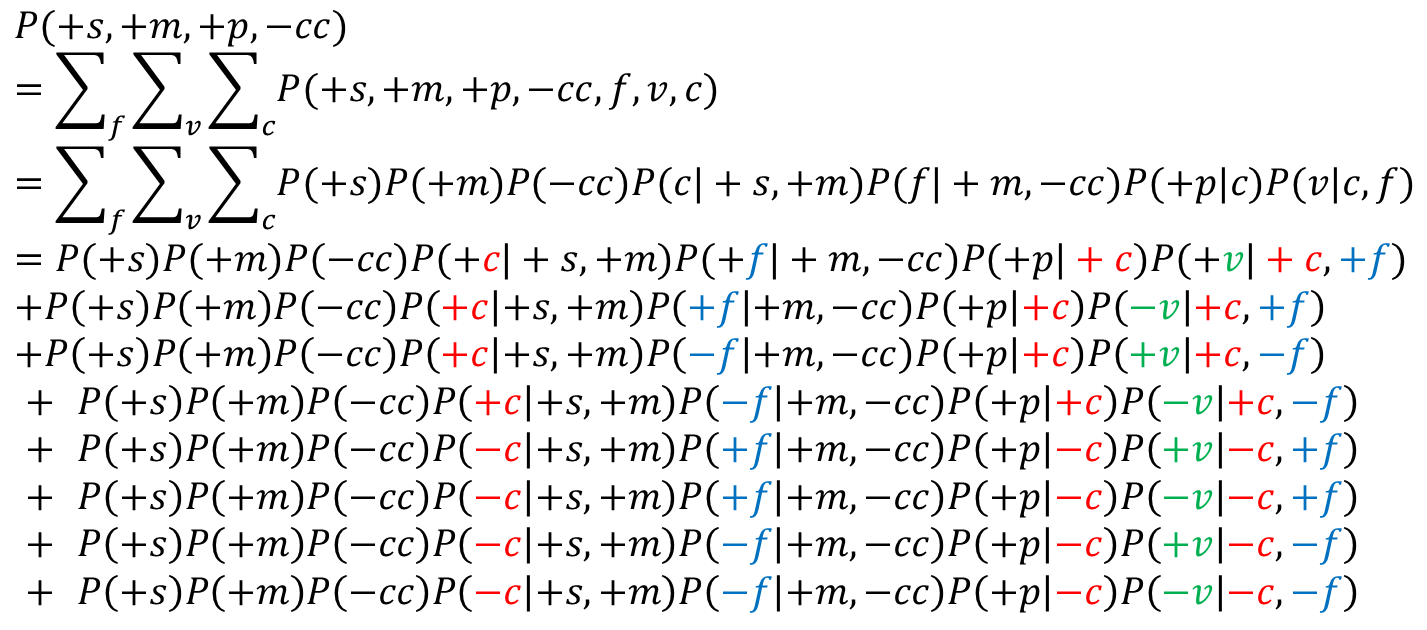
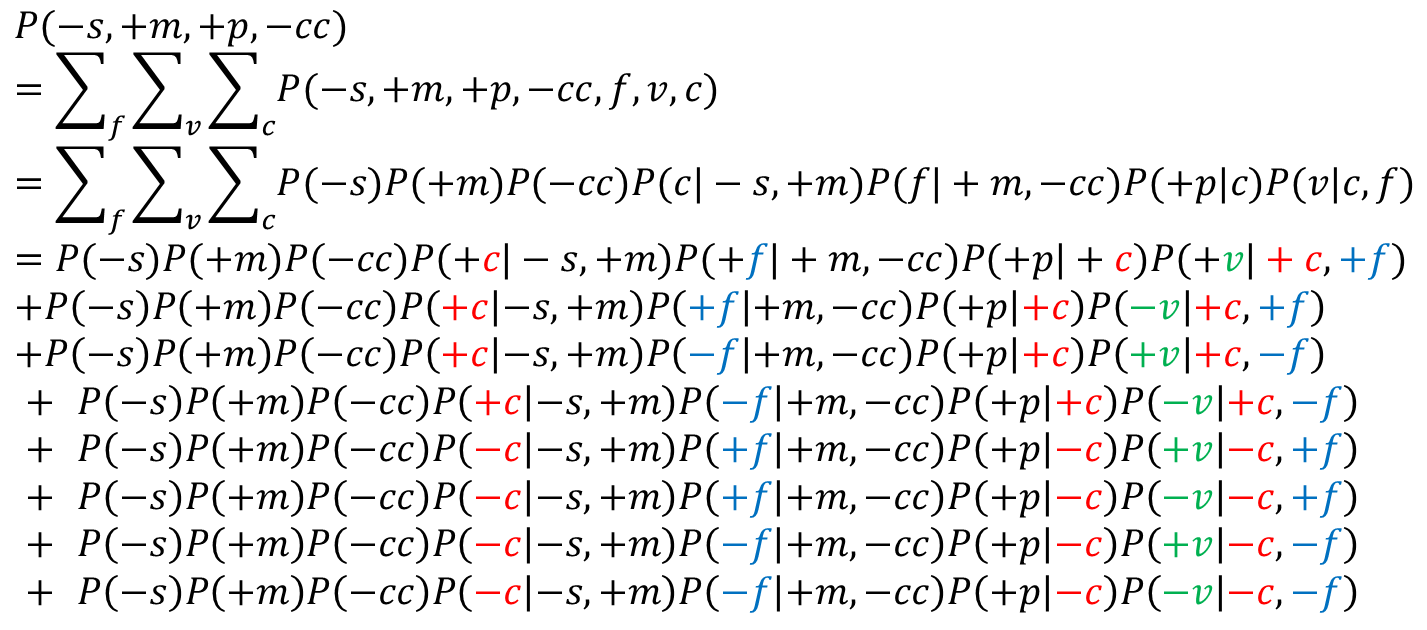
其中,联合概率计算通过3.2节介绍的Parent原则得到,这里不再赘述。
可以看到,未参与联合概率运算的隐变量,需要对其每个可能的取值都取一遍。因为在这个例子中,F,V,C的取值均为“取或不取”两种,所以可以看到,每个隐变量都需要取+和-两个值。这时,∑求和项数为 \(2^n,(n=3)\)个
为何将分母拆成两项?不拆开不也是计算分子和分母两个联合概率吗?其实拆开后更加简单,因为原分母有三个变量已知,S、C、F、V四个变量未知,这样会增加计算项数。即∑求和项数会从\(2^3\)增加到\(2^4\)个。
其中,联合概率分解后的条件概率或先验概率,均可以在概率表中查阅到,进行计算即可得到最终结果。
4.2 近似推理
可以看到,精确推理计算复杂度非常高,上述例子仅仅是三个隐变量,就已经需要大量计算了。在实际情况下,隐变量个数甚至可以为百余个,假设每个变量取值有两个,那么也需要\(2^{100}\)项,这是无法在短时间计算出结果。
此时,需要进行近似推理。近似推理的思想就是采样。采样是以概率论相关知识作为背景的,即:从一个总体中采样,那么得到的样本是可以近似总体的,因为样本和总体具有一致性。
近似推理有三种方法:随机数生成法、拒绝采样和似然加权采样。下面分别进行介绍。
4.2.1 随机数生成法
对于精确计算比较复杂的情况,可以使用随机数生成器进行采样,得到样本来进行近似估计。
举一个例子以更好理解,贝叶斯网络和概率表见下图:

其中,Cloudy表示是否是多云天气;Sprinkler表示草丛浇灌设备是否工作;Rain表示是否下雨;WetGrass表示草丛是否干燥。
现在问:
草丛不是干燥的,那么今天下雨的概率是多少?
如果进行精确推理,需要计算:
\(P(+R|-W)\) = \(P(+R,-W) \over P(-W)\)
= \(P(+R,-W) \over {P(+R,-W) + P(-R,-W)}\)
除W、R外,还有隐变量C,S,即共需要计算 \(2 * 2^2\)项,每项需要计算3次乘法,计算量对于人工来说还是有一些的。
那么,如何使用随机数生成法呢?步骤如下:
- 对于n个节点,需要n个随机数生成器,每个随机数生成器负责一个节点的随机数生成;
- 需要从根节点开始进行随机数生成,直到所有节点均已生成随机数;
- 对于每个节点,根据随机数的范围(0-1)进行选择(e.g. +或者-);
- 需要注意的是,父节点的选择,会影响其选择,具体可通过下面例子感受。
根据上述步骤,我们实际操作一遍。
1.首先根节点C的随机数生成器开始工作,假设生成了随机数0.3,即对应了+C;
2.下面节点S的随机数生成器开始工作,假设生成了随机数0.6。请注意!S是要受父节点C的选择的影响。
因为C选择了+C,那么就要在+C的条件下去对应0.6,得到了结果-S;
3.同理,假设节点R的随机数生成器生成了0.4,那么需要在+C的条件下去对应0.4,得到了结果+R;
4.节点W的随机数生成器生成了0.9,那么需要在-S和+R的条件下对应0.9,得到了结果+W。
这一次生成得到的结果是:
+C -S +R +W (1)
假设接下来生成的结果如下:
-C +S -R -W (2)
+C -S +R -W (3)
+C -S +R +W (4)
-C +S -R +W (5)
...
还记得问题吗?
草丛不是干燥的,那么今天下雨的概率是多少?
如何通过上述生成的5个样本,来估计这个概率?
- 首先,要找到符合结果的样本,即草丛不是干燥的:-W;
- 然后,在符合-W的样本中,去计算下雨:+R的概率。
得到的5个样本中,符合-W的是(2)(3)样本,其中+R的是(3),那么可以得到问题的答案是:50%。
(因为样本过少,得到的结果不够准确。这里是用频率来估计概率,考虑伯努利大数定律,当样本数量足够大时,频率是依概率收敛到概率的。)
4.2.2 拒绝采样
考虑4.2.1中的问题,其中只有W和R两个变量用到了,而隐变量C和S完全没有用到,但是使用随机数生成法时,仍然耗费时间去生成了它们对应的随机数了。
所以,可以考虑在生成随机数的过程中检测是否是一定不符合需要的一个结果,如果是,则在中途就停止本次结果的生成,这可以减少一定的时间耗费。
仍然是4.2.1中的问题,因为我们需要-W和+R的结果,那么,可以在检测到+W或者-R时,直接停止本次结果生成:
+C -S +R (停止) (1)
-C +S (停止) (停止) (2)
+C -S +R -W (3)
+C -S +R (停止) (4)
-C +S (停止) (停止) (5)
...
这就是所谓的拒绝采样,即,拒绝继续采样每个结果中对计算概率无用的部分。
4.2.3 似然加权采样
拒绝采样的确可以减少一定的计算量,但是还不够彻底。因为中途停止的一次结果浪费掉了,但仍然耗费了一定的时间。
那么,可不可以直接生成完全符合目标的依次结果呢?答案是可以的。
仍然以4.2.1中的问题为例:
草丛不是干燥的,那么今天下雨的概率是多少?
其中只有一个条件,那就是-W,那么此时就把-W固定,即相当于让每次结果中W的值都为-W,然后其余的变量结果继续随机生成。通过这样,可以完全减少一个变量的随机生成,假设前5次的结果如下:
+C -S +R | -W (1)
-C +S -R | -W (2)
+C -S +R | -W (3)
+C -S +R | -W (4)
-C +S -R | -W (5)
现在,我们需要在-W的基础上计算+R的概率,得到结果60%。
但是,这真的是正确的吗?不正确。
因为我们定了一个大前提,就是-W。也就是说,现在W一定是-W,这很显然是不正确的。
此时,需要进行似然加权,即给每一行结果加上一个概率权值。这个概率权值,就是我们定的变量值发生的概率是多少,这个概率就是这个变量的概率表中对应本行中其父节点们的取值的那一行。来看例子(下图是4.2.1节中的概率表,为了方便这里再次引用):
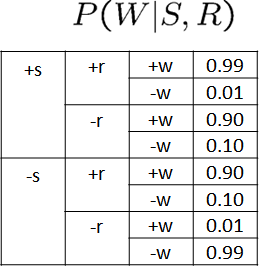
比如:W的父节点们是S和R,在(1)行中,取值是-S和+R,那么就是在\(P(W|S,R)\)这个概率表中找对应-W,-S和+R的那一行,其概率是0.1。依次得到其余行的概率表中的概率:
+C -S +R | -W (1) p = 0.1
-C +S +R | -W (2) p = 0.01
+C -S +R | -W (3) p = 0.1
+C -S -R | -W (4) p = 0.99
-C +S -R | -W (5) p = 0.1
其中p是发生概率,也就是权值。
这个权值代表什么?因为这个权值表示:这一个结果出现的概率是p,可以认为,现在并不是一个结果,而是“p”个结果。比如(1),其p=0.1,可以理解为,如果这一条结果出现了0.1次。
这样,我们在计算频率时,不应该将一行当作一个数据看,而是应该当作p个看,此时,要计算-W的前提下+R出现的概率,就应该是:
\((0.1 + 0.01 + 0.1) \over (0.1+0.01+0.1+0.99+0.1)\) = \(16\%\)
这就是似然加权估计,即,每一条结果不是一个结果,而是出现的概率个结果。
五、朴素贝叶斯网络分类器(Naive Bayesian Classifier)
这里只做简单介绍。
所谓朴素,就是简单的意思。
一个朴素贝叶斯网络只有一个根节点,其余全部是叶子节点:
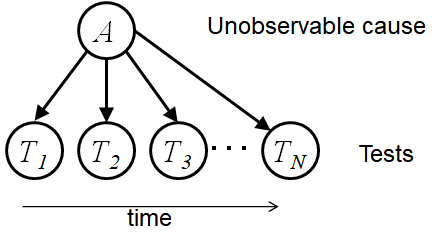
通过这个贝叶斯网络,我们可以计算:
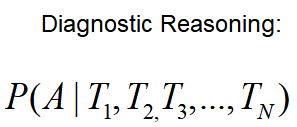
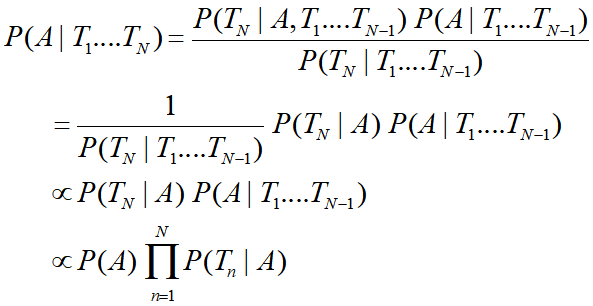
(这里用到了“3.1贝叶斯网络三种连接方式”的知识)
假设\(T_1\)-\(T_n\)是一次体检的各项指标,那么A就可以是体检的一个结果(某项疾病)。
参考资料
1.东北大学 高级人工智能 2022秋
2.https://blog.csdn.net/cxjoker/article/details/81878188
