python爬虫采集网站数据
1.准备工作:
1.1安装requests: cmd >> pip install requests
1.2 安装lxml: cmd >> pip install lxml
1.3安装wheel: cmd >> pip install wheel
1.4 安装xlwt: cmd >> pip install xlwt
2. 编写代码
2.1使用requests.get获取页面
编译结果

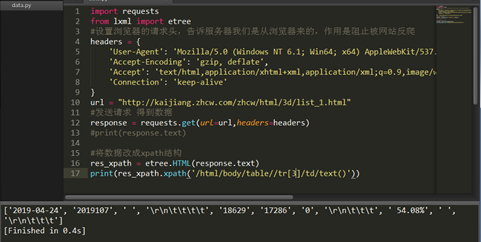
2.2 使用lxml将数据改成xpath结构
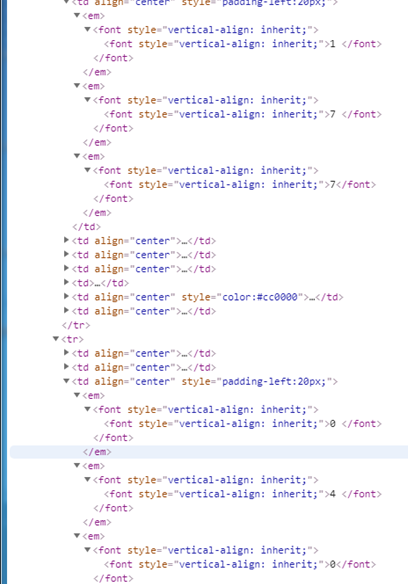
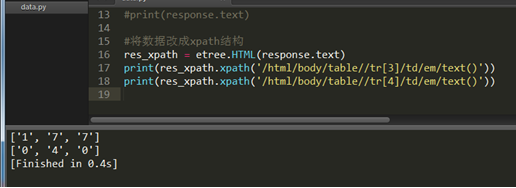
2.3 精确获取数据
2.4 使用for in循环输出数据
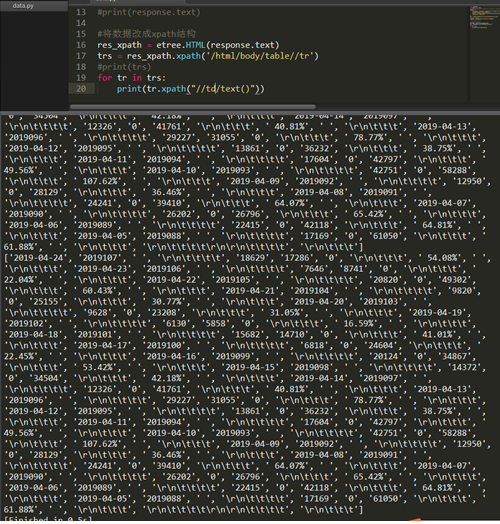
注意:print(tr.xpath(".//td/text()"))中 如果没有加.只会循环相同的内容,上图就是没有加点
正确做法
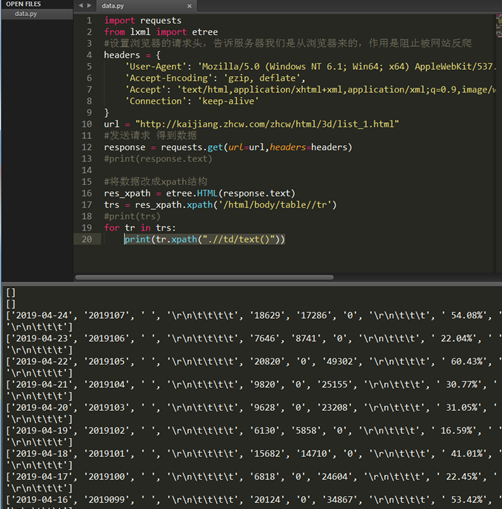
2.5 只获取需要的数据
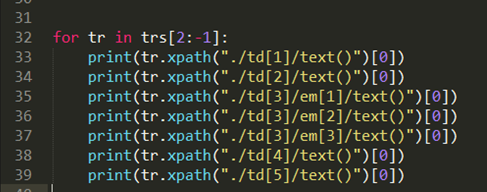
3.使用xlwt创建excel表,存储数据
3.1 创建excel表

运行结果
3.2 将数据添加到excel表中
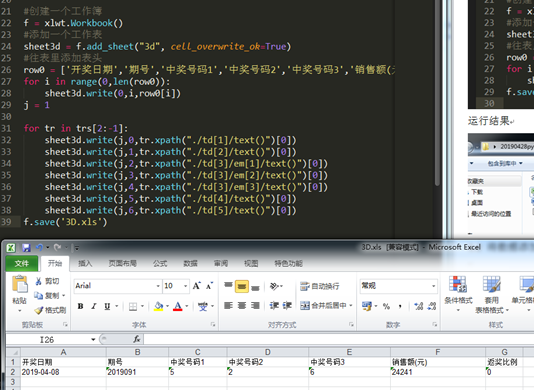
3.3 批量添加数据(让j累加)
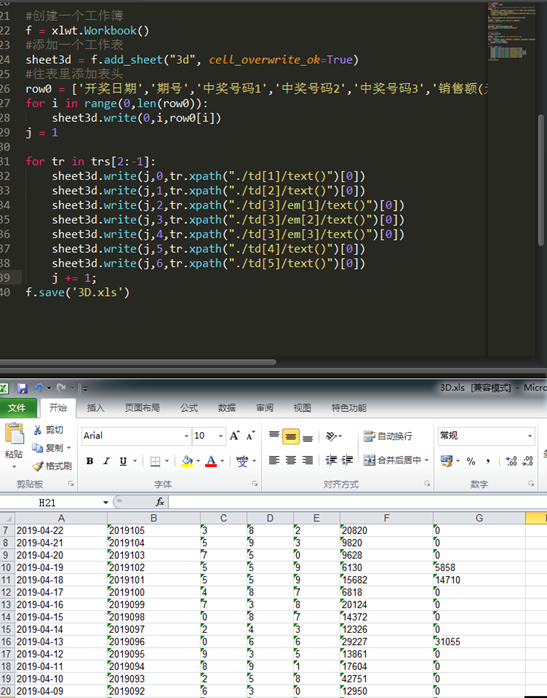
3.4 多页数据添加
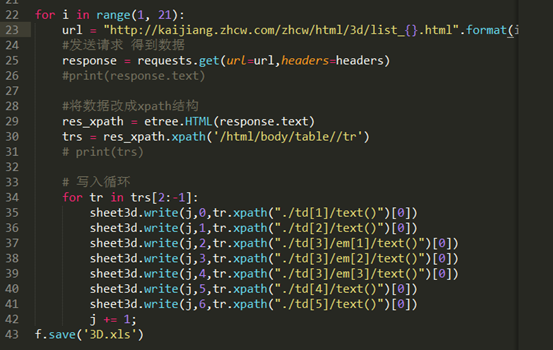
最终代码
import requests from lxml import etree import xlwt #设置浏览器的请求头,告诉服务器我们是从浏览器来的,作用是阻止被网站反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'Connection': 'keep-alive' } #创建一个工作簿 f = xlwt.Workbook() #添加一个工作表 sheet3d = f.add_sheet("3d", cell_overwrite_ok=True) #往表里添加表头 row0 = ['开奖日期','期号','中奖号码1','中奖号码2','中奖号码3','销售额(元)','返奖比例'] for i in range(0,len(row0)): sheet3d.write(0,i,row0[i]) j = 1 for i in range(1, 21): url = "http://kaijiang.zhcw.com/zhcw/html/3d/list_{}.html".format(i) #发送请求 得到数据 response = requests.get(url=url,headers=headers) #print(response.text) #将数据改成xpath结构 res_xpath = etree.HTML(response.text) trs = res_xpath.xpath('/html/body/table//tr') # print(trs) # 写入循环 for tr in trs[2:-1]: sheet3d.write(j,0,tr.xpath("./td[1]/text()")[0]) sheet3d.write(j,1,tr.xpath("./td[2]/text()")[0]) sheet3d.write(j,2,tr.xpath("./td[3]/em[1]/text()")[0]) sheet3d.write(j,3,tr.xpath("./td[3]/em[2]/text()")[0]) sheet3d.write(j,4,tr.xpath("./td[3]/em[3]/text()")[0]) sheet3d.write(j,5,tr.xpath("./td[4]/text()")[0]) sheet3d.write(j,6,tr.xpath("./td[5]/text()")[0]) j += 1; f.save('3D.xls')
venkim.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号