【论文阅读】IROS2021: PILOT: Efficient Planning by Imitation Learning and Optimisation for Safe Autonomous Driving
参考与前言
完整题目:PILOT: Efficient Planning by Imitation Learning and Optimisation for Safe Autonomous Driving
Summary: 用learning做warm start,然后使用优化进行求解,对比速度上有7倍的提升
Type: IROS
Year: 2021
cite: 3
tag: planning
组织/Sensor: oxford, edinburgh
论文链接:https://arxiv.org/abs/2011.00509;https://ieeexplore.ieee.org/abstract/document/9636862
代码链接:无
pre视频: https://www.youtube.com/watch?v=jK5oUhnJ7xw
同组同一批作者:TRO two-stage论文 主要基于这篇时间问题给出的一种方案;
- 博客园 TRO2022: A Two-Stage Optimization-Based Motion Planner for Safe Urban Driving
- CSDN TRO2022: A Two-Stage Optimization-Based Motion Planner for Safe Urban Driving
1. Motivation
本文主要是想吸收这data-driven和model-based 各自优点,做到efficiency
问题场景
总结 motion planning 可以划分为两类:data-driven 和 model-based;inference in data-driven model对比与其他的传统搜索和优化算法通常也更有效;而model-based 具有更多可解释性,而这些以robustness和runtime为代价
Contribution
-
A robust and scalable framework that imitates an expensive-to-run optimizer
-
Applying this framework to the two-stage optimization based planner
此点主要是速度上的提升,比上次转成MILP问题进行warm,快了7倍的时间
2. Method
提出:planning by imitation learning and optimization
- 使用模仿学习提取expert planner的行为,在线的,expert in the loop dataset augmentation(比如DAgger Dataset Aggregation 18)去持续的丰富整个训练集
- inference time 则是使用network做warm start,然后送到优化问题里进行求解
2.1 框架
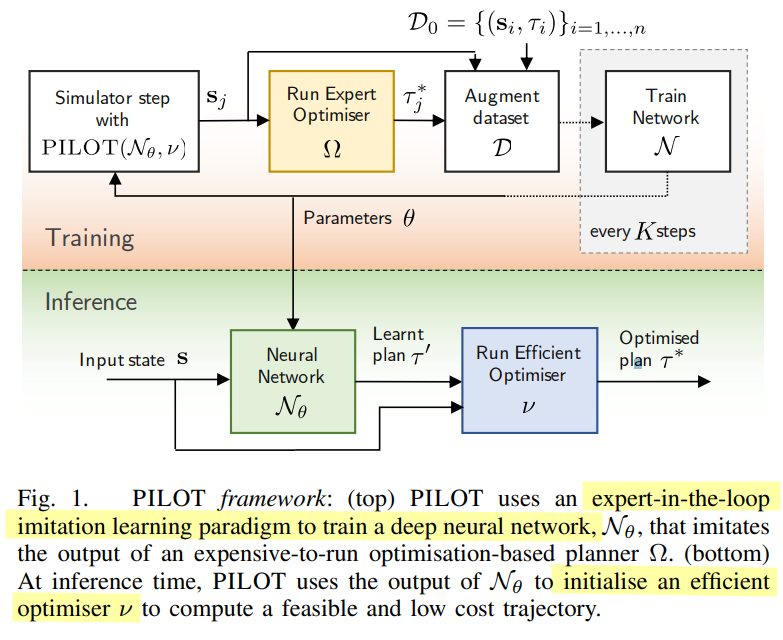
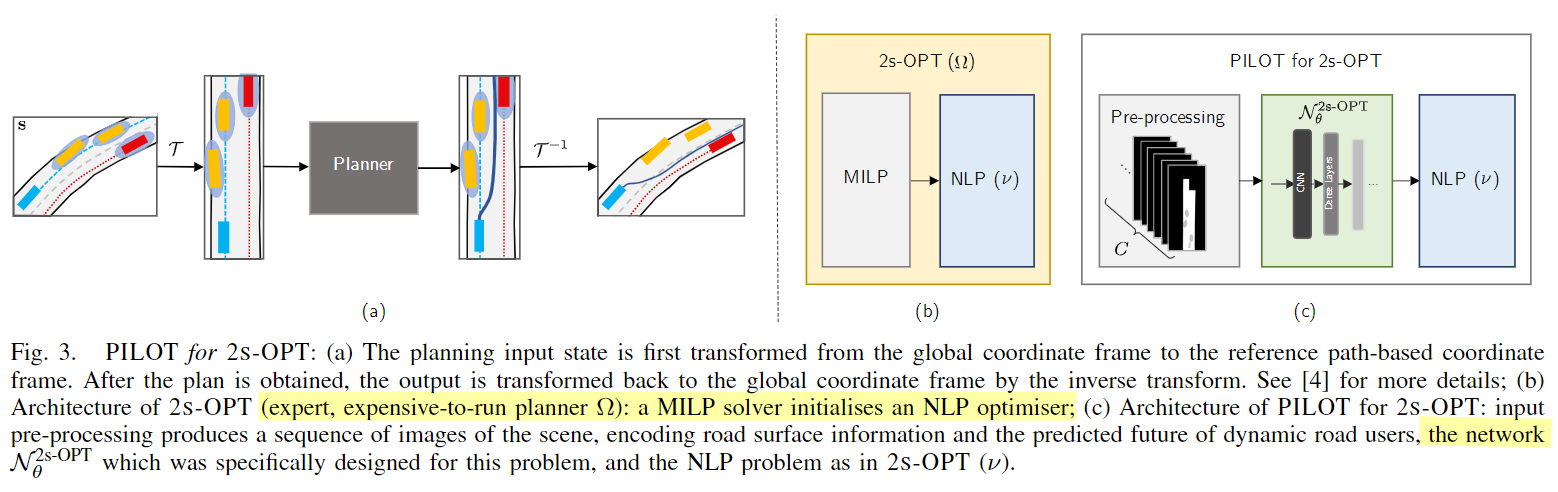
2.2 网络设计
之所以直接进入了网络设计 是因为… 优化的部分在上一篇TRO2022 two-stage进行了详细说明,此部分主要就是如何让网络得到一个warm start以得到一个更为 高效的求解系统
网络框架:
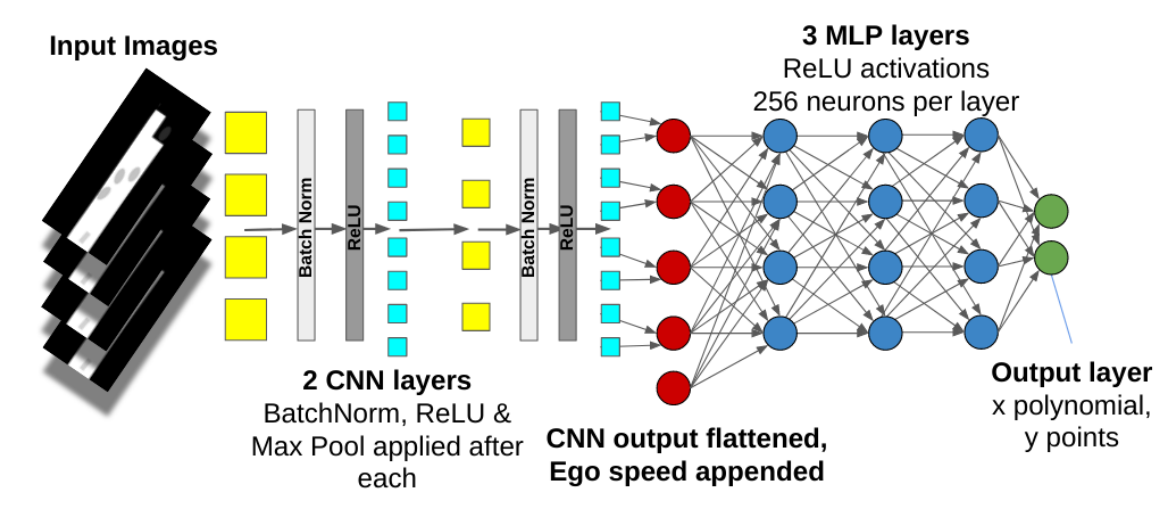
loss设计,期望网络能输出以参考线为坐标轴的一系列轨迹,encoded成一系列向量 \(\rho^{\theta}=\left\{\left(x_{j}, y_{j}\right)\right\}_{j=1, \ldots, N} \in \mathbb{R}^{2 \times N} \text {. }\)loss则是他和expert轨迹的L2 norm,其中 \(\theta\) 为神经网络的参数,D为训练数据,\(\mu\)为正则化参数
2.3 Cost定义
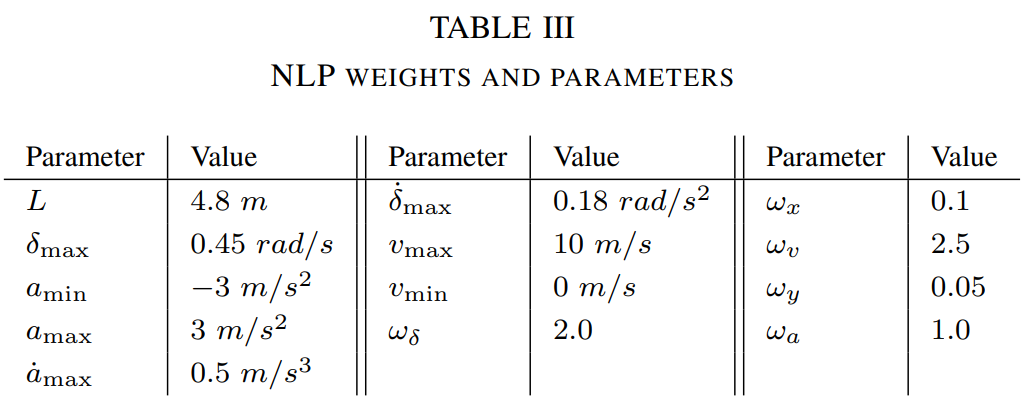
其中和实验表里cost的定义为:
w为权重,\(\theta\) 为速度,reference path,终点位置,控制量:加速度和转向 分别对应公式为: \(\omega_v, \omega_y, \omega_x, \omega_a, \omega_{δ}\) 权重经过了作者的调整
相关参数为如此表:
3. 实验及结果
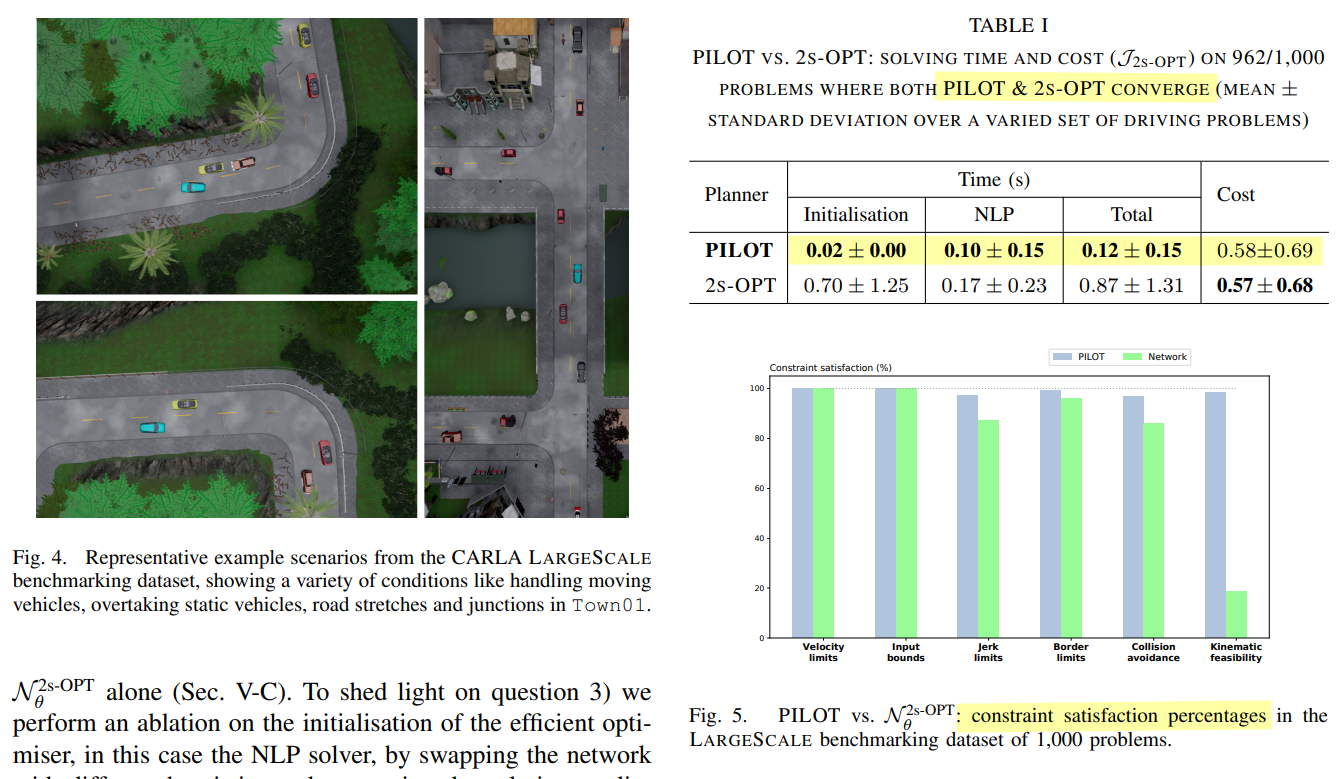

可以看出对比之前2s-OPT来说在提高了速度的面前,仅一点点 求解质量的牺牲,同时对比MILP问题给的初解,虽然converged不比MILP问题,但是对比其他情况下已经是最高的了
None对应无论何时求解都讲车辆状态(包括位置,yaw,速度设为0);ConstVel, Accel, Decel 分别对应初始化时的状态为恒定速度,加速度、减速度等
4. Conclusion
现在就是意义上的做到了求解质量高,也可以达到实时性要求,其中主要和TRO 2s-OPT进行了联动对比(都是同一个作者走的,应该是同一个时间点 那个做完了就开始尝试,网络去学出给初解
在discussion部分,作者说未来的方向可以探索更高级的转接,使用initializations [33]以更小cost给出solution;同时看看其他的损失函数的加入,提高网络提供的初始化质量和弥补专家与优化器之间现有的差距(其实差距不大…)
碎碎念
JG说… 其实这种用神经网络给初解的想法很多,但是怎样给出这个expert很难,所以主要贡献其实还是在expert,或者主要效果还是由expert的好坏决定的
赠人点赞 手有余香 😆;正向反馈 才能更好开放记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号