【深度学习 有效炼丹】多GPU使用教程, DP与DDP对比, ray多线程并行处理等 [GPU利用率低的分析]
⬅️ 前言
更新日志:
20220404:新增一个DDP 加载模型时显存分布不均问题,见目录遇到的问题及解决处
主要是上次server12 被自己一个train 直接线程全部拉满了(没错 ... server8 也被拉满过 emm我一开始还没发现 原来是我拉满的)
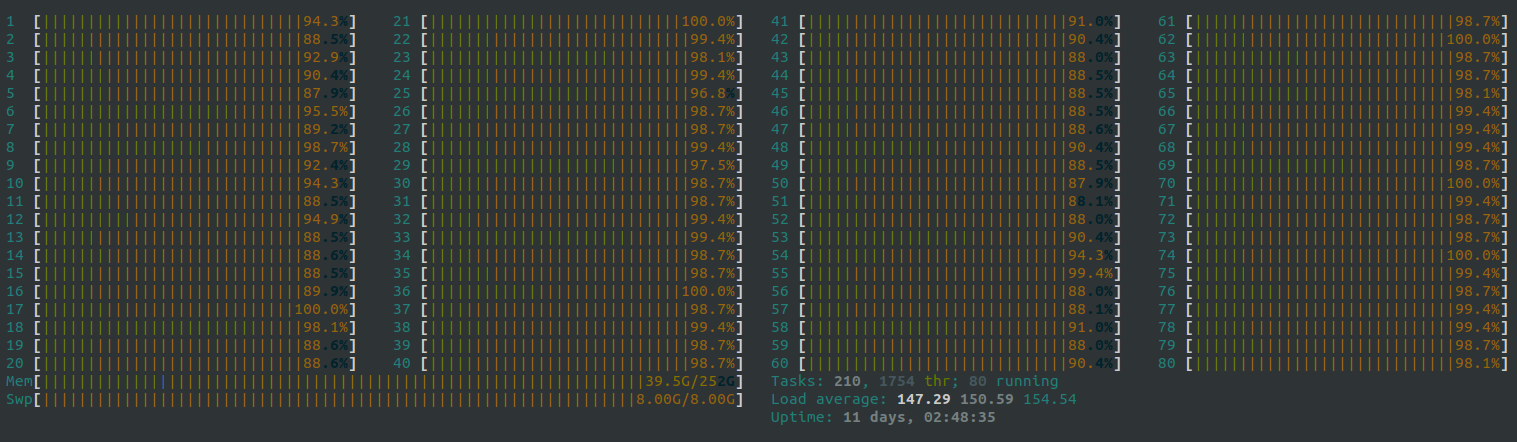
现场实况
后面刘所就跟我说让我看看是不是dataset里面的处理太多了,这样下来GPU占着 使用率也不高,建议先处理完了再直接由load进来 直接训练;因为server上的cpu都不是很好,一开始那样玩会拉慢训练速度,两种选择:
- 把cpu的操作全部放到gpu上去做
- 先把cpu操作做了保存成数据,这样不用每次epoch都做一次操作了
下面主要就是针对前言里面说的两条进行分析与方案确认
✔️ 1. 预处理
📍 最终方案 ( 并发多线程, dataset→pkl )
参考:
线程并发 并行 多机并行等一系列操作:
tips:
Programming in Ray: Tips for first-time users - RISE Lab
详情代码见:暂时还没开源
- 多CPU线程并行 → ray库
- 一个进程运行较多sample → ray.append
相关代码与解释
# 记得改一下 num cpus
sample_in_pre_run = 50
@ray.remote(num_cpus=48)
def write_pkl(save_dir, cur_num, dataset, run_num, pba: ActorHandle):
# print(cur_num, cur_num + run_num)
for i in range(cur_num, min(cur_num + run_num, len(dataset))):
with open(f'{save_dir}/%d.pkl'%(i), 'wb') as fd:
pickle.dump(dataset[i], fd)
pba.update.remote(1)
num_cpus是需要根据自己的线程数设置,不是越多越好!比如服务器上12, 8左右就行,因为每开一个线程就需要很多时间,如果开线程的耗费>>进程的耗费,那还不如单进程自己跑跑跑- 根据上面提示,也就引入了
sample_in_pre_run也就是一个进程里干多少个工作,如果太多 可能进程拖慢了,太少 开线程又浪费了
里面有些操作是进度条可忽略,注意并发的ray 原tqdm进度条会失效!
详情见官方:(也可见上述gitlab中有copy下面进度条)
ray_train_set = ray.put(train_set)
for cur_num in range(0, len(train_set), sample_in_pre_run):
tasks_pre.append(write_pkl.remote(train_dir, cur_num, ray_train_set, sample_in_pre_run))
ray_val_set = ray.put(val_set)
for cur_num in range(0, len(val_set), sample_in_pre_run):
tasks_pre.append(write_pkl.remote(val_dir, cur_num, val_set, sample_in_pre_run))
pb.print_until_done()
tasks = ray.get(tasks_pre)
# 进度条相关
tasks == list(range(num_ticks))
num_ticks == ray.get(actor.get_counter.remote())
-
可以看到每个for里面的进程加上了remote也就是ray所需要的函数,可以看一下上面的walkin
-
把每一个任务都append到tasks_pre后,再统一
ray.get(tasks_pre)即可 -
注意新加了一个
ray.put是因为上服务器大数据的时候发现append操作巨慢,然后查了一下和传入的参数有关,所以把参直接放到put共享下了 -
不要进度条的话 大概简洁版是这样的:
from torch.utils.data import DataLoader from datasets.config import GlobalConfig # 一开始的数据操作都在dataset的get_item里面做了 from datasets.dataloader import CARLA_Data # 一开始的数据操作都在dataset的get_item里面做了 import ray ray.init() sample_in_pre_run = 50 @ray.remote(num_cpus=48) def write_pkl(save_dir, cur_num, dataset, run_num): # print(cur_num, cur_num + run_num) for i in range(cur_num, min(cur_num + run_num, len(dataset))): with open(f'{save_dir}/%d.pkl'%(i), 'wb') as fd: pickle.dump(dataset[i], fd) ray_train_set = ray.put(train_set) for cur_num in range(0, len(train_set), sample_in_pre_run): tasks_pre.append(write_pkl.remote(train_dir, cur_num, ray_train_set, sample_in_pre_run)) ray_val_set = ray.put(val_set) for cur_num in range(0, len(val_set), sample_in_pre_run): tasks_pre.append(write_pkl.remote(val_dir, cur_num, val_set, sample_in_pre_run)) # 一起并发处理 ray.get(tasks_pre)
速度效果对比
最终效果速度对比:
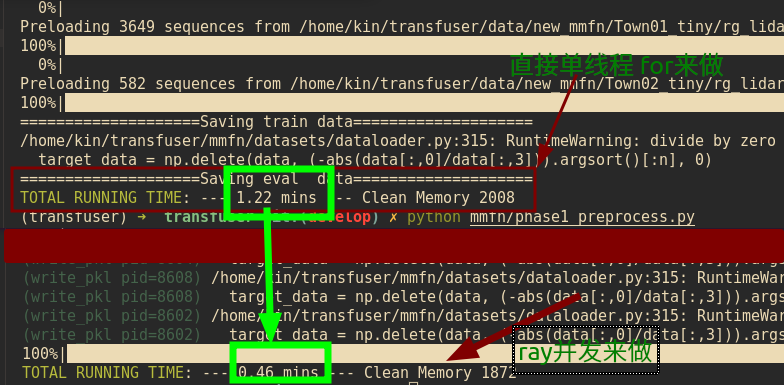
大概是2.5倍的速度 处理速度
-
上面提到了append操作 每次传进dataset太慢 放到put里面 共享了就快了
这之后要是还是很慢的话,就不是CPU的锅了,建议检查一下io的读取速度 如下:
使用率对比
主要就是处理完数据后通过pkl等保存的文件直接再读取一次dataset 比如上面处理完CARLA_Data后再写一个直接load pkl的dataset即可
class PRE_Data(Dataset):
def __init__(self, root, config, data_use='train'):
self.preload_dict = []
preload_file = os.path.join(root, 'rg_mmfn_diag_pl_'+str(self.seq_len)+'_'+str(self.pred_len)+ '_' + data_use +'.npy')
preload_dict = []
if not os.path.exists(preload_file):
# list sub-directories in root
for pkl_file in os.listdir(root):
if pkl_file.split('.')[-1]=='pkl':
pkl_file = str(root) + '/' + pkl_file
preload_dict.append(pkl_file)
np.save(preload_file, preload_dict)
# load from npy if available
preload_dict = np.load(preload_file, allow_pickle=True)
self.preload_dict = preload_dict
print("Preloading sequences from " + preload_file)
def __len__(self):
"""Returns the length of the dataset. """
return len(self.preload_dict)
def __getitem__(self, index):
"""Returns the item at index idx. """
with open(self.preload_dict[index], 'rb') as fd:
data = pickle.load(fd)
return data
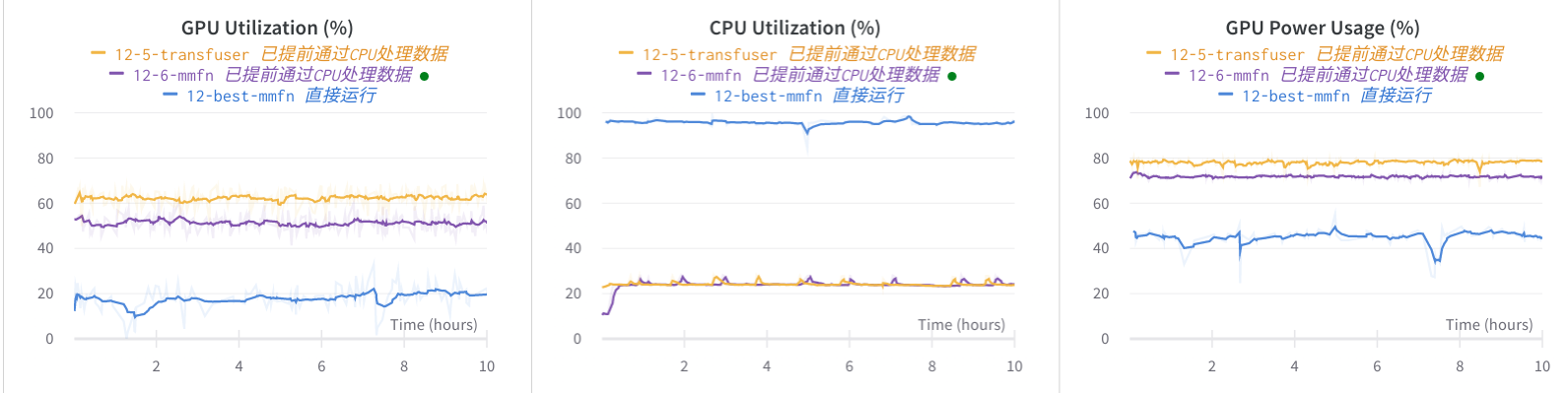
可以看到提前通过处理后,CPU的使用率基本不会在拉满到100%,甚至等同于无(因为同时还有其他人使用这个server
同时GPU使用率也提高了两倍,主要是之前的使用率一直在20%不动,CPU都跑满了都不动
✔️ 2. 单机多卡并行
参考:
官方的DDP教程:
Getting Started with Distributed Data Parallel - PyTorch Tutorials 1.10.1+cu102 documentation
github 211star 中文:
https://github.com/jia-zhuang/pytorch-multi-gpu-training
主要就是调研情况里面的 那个参考链接 的做法,首先根据官方文档 我们看一下 选择 DistributedDataParallel 和 DataParallel 之间的官方给出的区别及效率,官方推荐前者 DistributedDataParallel :Before we dive in, let’s clarify why, despite the added complexity, you would consider using DistributedDataParallel over DataParallel:
- 首先如果不是那么急切的话 其实
DataParallel也行,主要是因为实现起来真的很方便加一行 真就一行 - 而
DistributedDataParallel就不一样了 要加很多行(还行还行),但是呢 是高效的
两者之间的效率对比我并没有做,所以我们就根据官方文档而的来这个结论了
两种方案 理论知识
以下为 官方对比链接人工翻译
- DataParallel 是单进程多线程的,而且只能在一个机器上进行 也就是单机多卡
- DistributedDataParallel 多进程 既可以用于单机训练,也可以用于多机训练
再者因为 DataParallel 跨线程的操作使得 线程之间的 GIL 竞争 、每次迭代间复制模型同步 以及 分散输入 和 集成输出,这些都会导致额外开销,即使在单台机器上,DataParallel 通常也比 DistributedDataParallel 慢。
这是其一,其二呢如果 你的模型太太太 大以至于一个小GPU都装不下,那么 DataParallel 就失效了,因为必须使用 模型并行 将其拆分到多个 GPU 上。 DistributedDataParallel 是与模型并行工作的,而DataParallel 目前没有实现
第三点是小提醒 与对比无关:DDP 与模型并行相结合时,每个 DDP 进程将使用模型并行,所有进程共同使用数据并行。如果模型需要跨越多台机器,或者 模型方案等 不适合数据并行范式,请参阅 RPC API 以获得更通用的分布式训练支持。
理论知识学习完了 进入代码实践部分
代码部分 修改
https://github.com/jia-zhuang/pytorch-multi-gpu-training
正如参考的github中那样 (其实那个写的挺不错的 hhhh 以下为部分重复及补充 因为遇到一些意想不到的情况 emmm 一言难尽)
DataParallel
之所以简单是因为... 只需要一行,只需要把自己的model放进去就行网络
注意参考所说的这点,更为详情 点击参考链接查看
为方便说明,我们假设模型输入为(32, input_dim),这里的 32 表示batch_size,模型输出为(32, output_dim),使用 4 个GPU训练。
nn.DataParallel起到的作用是将这 32 个样本拆成 4 份,发送给 4 个GPU 分别做 forward,然后生成 4 个大小为(8, output_dim)的输出,然后再将这 4 个输出都收集到cuda:0上并合并成(32, output_dim)
可以看出,nn.DataParallel没有改变模型的输入输出,因此其他部分的代码不需要做任何更改,非常方便。但弊端是,后续的loss计算只会在cuda:0上进行,没法并行,因此会导致负载不均衡的问题;如果把loss放在模型里计算的话,则可以缓解上述负载不均衡的问题
# Model
model = TransFuser(config, args.device)
if args.is_multi_gpu:
print(bcolors.OKGREEN + "Multi GPU USE"+ bcolors.ENDC)
model = nn.DataParallel(model)
DistributedDataParallel
实现起来更为麻烦”一“点,因为是多进程
从一开始就会启动多个进程(进程数等于GPU数),每个进程独享一个GPU,每个进程都会独立地执行代码。这意味着每个进程都独立地初始化模型、训练,当然,在每次迭代过程中会通过进程间通信共享梯度,整合梯度,然后独立地更新参数。
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 train.py
所以你运行了一句话 但是类似于一个脚本运行了四个python,所以呢 所有打印和保存都会运行四个,办法就是判断这是args.local_rank是0 的时候再进行这些保存打印操作
CUDA_VISIBLE_DEVICES 为运行时脚本能看到的GPU id,nproc_per_node 为GPU个数,nnodes 为主机个数 单机就是1,train.py 就是你的正常训练代码,注意需要经过以下几点修改:
-
要有local_rank的传入 因为运行的时候 他会出入一个local rank指定
from torch.utils.data.distributed import DistributedSampler parser = argparse.ArgumentParser() parser.add_argument("--local_rank", type=int, default=-1) args = parser.parse_args()-
碎碎念,也可以 走 自己在 程序里指定 的方式, 比如官方所示这样
"""run.py:""" #!/usr/bin/env python import os import torch import torch.distributed as dist import torch.multiprocessing as mp def run(rank, size): """ Distributed function to be implemented later. """ pass def init_process(rank, size, fn, backend='gloo'): """ Initialize the distributed environment. """ os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29500' dist.init_process_group(backend, rank=rank, world_size=size) fn(rank, size) if __name__ == "__main__": size = 2 processes = [] mp.set_start_method("spawn") for rank in range(size): p = mp.Process(target=init_process, args=(rank, size, run)) p.start() processes.append(p) for p in processes: p.join()
-
-
因为每个进程都会初始化一份模型,为保证模型初始化过程中生成的随机权重相同,需要设置随机种子。方法如下:
def set_seed(seed): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) -
train_set给一下DistributedSampler
# Data train_set = PRE_Data(root=config.train_data, config=config, data_use='train') val_set = PRE_Data(root=config.val_data, config=config, data_use='val') # 多GPU训练 train_sampler = DistributedSampler(train_set) val_sampler = DistributedSampler(val_set) dataloader_train = DataLoader(train_set, batch_size=args.batch_size, sampler=train_sampler, num_workers=8, pin_memory=True) dataloader_val = DataLoader(val_set, batch_size=args.batch_size, sampler=val_sampler, num_workers=4, pin_memory=True) -
保存和eval都只需要进行一次即可 → wandb记录和打印等等都只需要一次哈
if epoch % args.val_every == 0 and args.local_rank == 0: trainer.validate(model, dataloader_val, config) if epoch % args.save_every == 0: trainer.save(model, optimizer) # 官方保存 if rank == 0: # All processes should see same parameters as they all start from same # random parameters and gradients are synchronized in backward passes. # Therefore, saving it in one process is sufficient. torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)保存也只需要一次是因为(注释也有):所有进程都应该看到相同的参数,因为它们都从相同的随机参数开始,并且梯度在反向传递中是同步的。 因此,将其保存在一个进程中就足够了。
-
保存模型时应注意只需要保存一次,而且必须在GPU上,cpu会有问题 见后问题栏有提到
torch.save(model.module.state_dict(), os.path.join(self.logdir, 'best_model.pth'))后续导入的时候 一定要注意 1. map到cpu上 2. 映射一下所有layer的东西,见后问题栏也有提示
state_dict = torch.load(os.path.join(self.config_path.model_path, 'best_model.pth'), map_location=torch.device('cpu')) pretrained_dict = {key.replace("module.", ""): value for key, value in state_dict.items()} self.net.load_state_dict(pretrained_dict) -
为保证所有gpu分配均匀显存,请早模型前执行,详情见问题栏
# 就是这两句话 torch.cuda.set_device(args.local_rank) torch.cuda.empty_cache() # 就是这两句话 # Model model = TransFuser(config, args.device) model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
剩余问题 见后续问题部分,请提前进行查看,了解相关会遇到的问题
效果对比
多GPU 速度
相同数据量,两块2080Ti和一块2080Ti的对比,使用 DistributedDataParallel 最终效果速度对比:
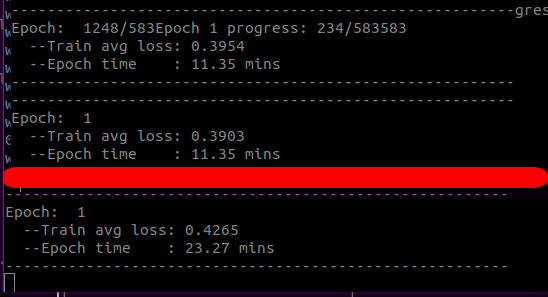
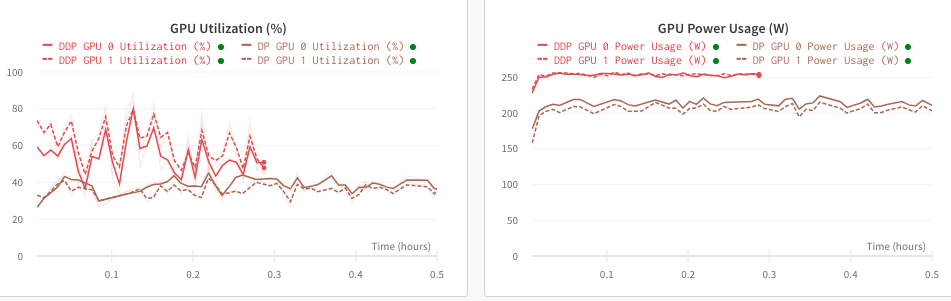
DP 和 DDP 的使用率对比
DP弊端还有就是... GPU利用率很低,不知道是不是因为样本拆成分配的问题,利用率直接掉半,如下图对比所示 同样的数据集和训练 DDP 和 DP(随着GPU数量越多 利用率越低) 的使用率对比
❓ 3. 遇到的问题及解决
DistributedDataParallel
-
RuntimeError: NCCL communicator was aborted
这个问题是我随机遇到的同样模型下 小数据集没啥报错,但是全的时候发现emmm 挺随机的;相关pytorch 讨论区链接如下:
RuntimeError: NCCL communicator was aborted
好像找到原因了,不应该在保存是.cpu 模型文件 因为即使.to 回去 也是会报错的,所以直接保存args.local_rank为0的那个模型就行,因为官方里面也是这么干的...
所有进程都应该看到相同的参数,因为它们都从相同的随机参数开始,并且梯度在反向传递中是同步的。 因此,将其保存在一个进程中就足够了。
-
Pytorch distributed RuntimeError: Address already in use
因为紧急kill掉了 留下了后患,虽然通过命令行kill了所属pid 但是好像还是占着那个默认口,比如通过htop里面的命令行进行选择所有 kill
kill -9 $(pgrep -f "/opt/conda/envs/python37/bin/python -u mmfn" | xargs echo)然后好像口还是没能释放 换一下端口号就行:
python -m torch.distributed.launch --nproc_per_node=4 --master_port 12120 --nnodes=1 mmfn/phase2_train_multipgpu.py -
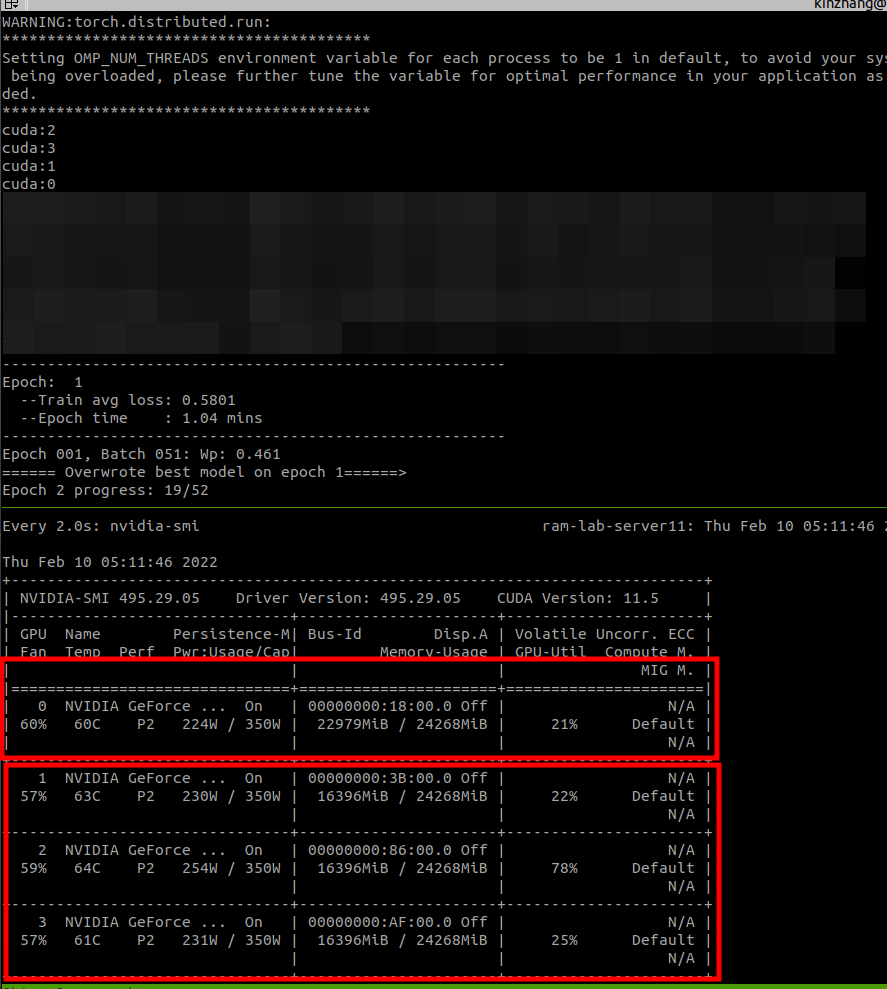
注意 使用了DDP 不知道是需要多匀一些显存的,比如一下,用了一块3090,显存是24G,正常单独GPU训练时 batch_size设置了64,占用了20G显存,那么到DDP这个方案的时候,虽然是多进程运行按理来说应该也设置64,毕竟其他也是3090嘛 但是呢!实际运行的时候 发现第一块需要占用更多的东西,如果GPU越多 他越需要占用(2G/块) → 但是我看华哥的好像... 没有这种现象产生 估计哪里我没注意到
-
现场实况:
杰哥太强了!啊!找到原因啦!他喵... 竟然要在model前说明一下
Extra 10GB memory on GPU 0 in DDP tutorial
# 就是这两句话 torch.cuda.set_device(args.local_rank) torch.cuda.empty_cache() # 就是这两句话 # Model model = TransFuser(config, args.device) model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True) -
-
上面这点 还有可能是需要加载模型再进行下一个模型的训练,那么也有可能导致GPU显存分布不均匀
需要提前load的时候专门
map_locationstate_dict = torch.load(model_name, map_location=self.args.device) self.load_state_dict(state_dict) -
如果resume的话,需要重新组织一下读取的layer id,相关链接:
https://github.com/bearpaw/pytorch-classification/issues/27
Missing keys & unexpected keys in state_dict when loading self trained model
# for DDP model load use state_dict = torch.load(os.path.join(args.logdir, 'best_model.pth')) optimizer.load_state_dict(torch.load(os.path.join(args.logdir, 'best_optim.pth'))) from collections import OrderedDict new_state_dict = OrderedDict() for k, v in state_dict.items(): if 'module' not in k: k = 'module.'+k else: k = k.replace('features.module.', 'module.features.') new_state_dict[k]=v model.load_state_dict(new_state_dict)
DataParallel
这个主要是注意那个batch_size 是分配的,也就是会除GPU个数,如果你的处理里有涉及到这样的情况,则会出现相关数据的size对不上
比如在dataloader里 进行了 对batch里的数据取最大,作为一个长度;然后再到模型的forward里继续处理一次数据 作为长度,那么;四个分散的batch就会有四个不同的size长度,也就会发生一定的问题,前方实况:
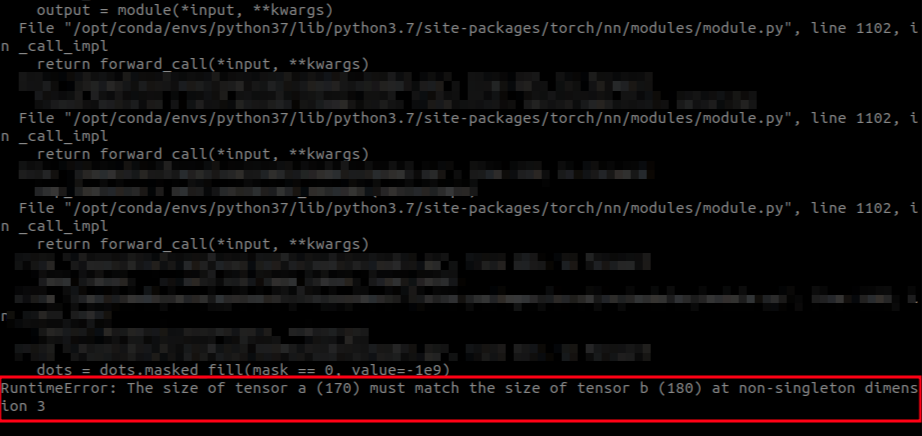
建议措施,所有对数据size的确定在loader部分进行完成
以下为一开始调研情况
相关原因分析
附加:cpu htop参数相关解释:Understanding and using htop to monitor system resources
这里也提到了loader 一个个小的太小了 最好处理成大的再读取:https://github.com/Lyken17/Efficient-PyTorch#data-loader
pkl
已经写了但是直接在loader出来的 也就是batch_size 从这儿就定下来了 → 错误做法
lmdb:https://github.com/dotchen/WorldOnRails/blob/release/docs/DATASET.md
看一下是否能携程lmdb式,loader式有点过于暴力了
赠人点赞 手有余香 😆;正向回馈 才能更好开放记录 hhh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号