【论文阅读】Learning to drive from a world on rails
引用与参考
代码地址:https://github.com/dotchen/WorldOnRails
论文地址:https://arxiv.org/abs/2105.00636
论文部分
摘要划重点:
- 视觉 只有视觉 → 所以关于加入激光点云的想法还是可以继续
- 行驶数据建立在model-based 使用车辆本身自行车模型 →
- world on rails的意思是:环境并不会随agent的行为而改变(很符合... Carla里的仿真了,车辆不会和你交互 只会按照自己的行程走 特别是在leaderboard测试的)
但是这一点在现实中,并不适用,现实中有车辆交互博弈学习等 → 这也正是用学习的原因
world on rails的假设后:简化学习问题、得知这个世界的动态信息?、自己的车低维度动作、状态空间
通过之前pre-recorded驾驶数据得出自己现在这步骤的影响
- 在已有的数据轨迹中学习世界的模型(learn world model)
- 对于所有pre-recorded轨迹预估action-value
- 训练RV policy,获得action-value function,从而获取所有动作的影响
理论方法总括
首先我们要学习的是一个能由传感器信息做出输入,输出动作的policy \(\pi(I)\)
在训练时的轨迹序列是:\(\tau=\left\{\left(\hat{I}_{1}, \hat{L}_{1}, \hat{a}_{1}\right),\left(\hat{I}_{2}, \hat{L}_{2}, \hat{a}_{2}\right), \ldots\right\}\)
- \(\hat{I}_{t}\) 传感器信息
- \(\hat{L}_{t}\) 驾驶数据,主要是自身车辆和其他参与者的位置、速度、朝向
- \(\hat{a}_{t}\) 做出的动作
戴帽的是从行驶数据中来的,普通的则是free or random变量
我们要利用这些驾驶数据学习的是:关于世界的forward model \(\mathcal{T}\) 和 action-value function \(Q\),整体过程就是 \(L_t\),\(a_t\) 通过 \(\mathcal{T}\) 预测得到\(L_{t+1}\),最后的agent对应的policy \(\pi(I_t)\)仅以传感器信息作为输入

整个算法流程 (公式请看下面定义)
3.1 Forward model分解
驾驶状态 \(L_t\) 和 forward model分成两个部分:
-
仅考虑自身车辆的控制:
\[L_{t+1}^{e g o}=\mathcal{T}^{e g o}\left(L_{t}^{e g o}, L_{t}^{\text {world }}, a_{t}\right) \] -
建模剩下的世界模型:
\[L_{t+1}^{\text {world }}=\mathcal{T}^{\text {world }}\left(L_{t}^{\text {ego }}, L_{t}^{\text {world }}, a_{t}\right) \]又因为假设的原因,world仅和自身有关,所以:\(L_{t+1}^{\text {world }}=\mathcal{T}^{\text {world }}\left(L_{t}^{\text {world }}\right)\),那么从一开始world状态就能知道整个world的模型
由以上,就只需建模对于自身车辆的forward model,这里使用L1进行回归训练 \(\mathcal{T}^{e g o}\):
注意这里的自身车辆状态其实可以通过自行车模型来计算得来
实验处理
在收集到的subset轨迹上,训练自身车辆的forward model \(\mathcal{T}^{e g o}\),收集的数据保证在整个动作空间展开,例如:
- 转向从\([-1,1]\);油门从\([0,1]\);前两者都是均匀采样,刹车是只有\(\{0,1\}\)
正如前面提到的forward model \(\mathcal{T}^{e g o}\) 是由现在的\((x_t,y_t,\theta_t,v_t)\) 来预测下一个时刻车辆的状态:\((x_{t+1},y_{t+1},\theta_{t+1},v_{t+1})\)
在这里可以使用已知的自行车模型作为 \(\mathcal{T}^{e g o}\) 的结构先验:我们仅学习车辆的\(f_b,r_b\);从转向\(s\)到轮转向\(\phi\)的映射;油门和刹车到加速度的映射
-
详情见 代码阅读,是学习学到的这两个参数
3.2 Action-value function
这里我们想要的是一个给出行驶状态和动作,返回一个动作价值函数 [所以从这里可以知道对比lbc的方法 他是把鸟瞰图,或者说激活RGB图像的方式换成了RL里面对于动作价值的概念]
这里的公式就是Bellman基本公式,强化学习书里的,关于value function和q function的区别见:https://www.zhihu.com/question/59122948/answer/1899310296
其中,\(\hat{L}_{t}^{\text {world }}\)是直接记录下来的周围环境(世界)的,不会对\(Q\)造成影响(是假设),所以这整个式子可以简化一下:
其中的\(Q\)值计算由此可得:
- 自身车辆的状态 \(L_{t}^{e g o}\) 由 (位置、朝向、速度) 组成;这样对每一个 \(V_{t}\left(L_{t}^{e g o}\right)\) 状态的价值我们都进行计算,在最后的eval过程中,线性拟合其值如果value falls between bins
实验处理
对于每个时间\(t\) 我们把vaule function弄成一个4D的tensor:\(N_H \times N_W\)是关于位置的;\(N_v\)是关于速度的;\(N_\theta\)是关于朝向的
实验中\(N_H=N_W=96, N_v=4, N_\theta=5\),每个点代表了物理的\(\frac{1}{3} \times \frac{1}{3} m^{2}\)区域,\(2m/s\)的速度范围和\(38°\)的朝向范围
\(\hat{L}_{t}^{e g o}=\left(x_{t}, y_{t}, v, \theta\right)\) 自身车辆的状态是处于整个离散化空间的中间的;对于value fall outside就直接为0
这里同样我们也离散化了我们的转向和油门 \(M_s \times M_t\),然后在转向或踩油门的时候,我们不进行刹车,那么当\(M_s=9,M_t=3\)。整个动作空间就是\(9\times3+1=28\)
reward的设计如下:
规定zero-speed area:比如遇到红灯、接近其他车辆/行人等
- +1:保持在目标车道
- 0:如果偏离了车道,但是+1到0直接的变化不是二值,而是线性拟合smoothly penalized
- +5:如果在zero-speed area里停下了
但是这里zero-speed只会给一次,不会累加了,以免出现车辆直接一直停下不走了
因为有了zero-speed区域,所以关于碰撞的惩罚也就不需要有了 - \(r_{stop}=0.01\) 以避免agent为了躲避而偏离车道 → 这一点我感觉只要不压实线,虚线变道应该是可以的吧 → 可能是对于leaderboard场景的trick设置
最后是通过high-level commands[左转、右转、直走、跟随路径、change right、 change left]来计算的整个动作价值函数
3.3 Policy Distillation
然后再使用 \(Q_{t}\left(\hat{L}_{t}^{e g o}, \cdot\right)\) 去监督学习VP(visuomotor policy) \(\pi(\hat I_t )\) ,所以呢 \(Q_{t}\left(\hat{L}_{t}^{e g o}, \cdot\right)\) 代表了车辆在那个状态下做出哪个动作是最优的,然后优化迭代我们直接通过期望:
其中\(H\) 是entropy regularizer,\(\alpha\) 是温度超参数,这样的处理是为了拿到diverse output policy
实验处理
对于policy network的设计使用的是以RGB作为输入,ResNet34作为网络框架
- flatten ResNet features
- concatenating speed
- 喂到网络里去
- 输出动作空间的分布:categorical distribution over discretized action spaces

-
看了代码知道了 不算是限制在地图里,而是因为读取了地图中的waypoint 来进行reward判断,就是需要沿着车道线行驶不能出界或者偏移 详情见reward的操作
4 实验部分处理
-
通过carla内的行为规划器 [5] Carla之全局规划follow 来收集数据 \(\pi_b\)并没有使用行为规划器来进行,而是直接生成min-max的一系列动作,根据reward 选出最好的进行 做出动作
-
使用autopilot来添加转向的噪音
-
使用上面的数据去学习forward model,而不是直接去使用autopilot去做监督学习
对应每个我都直接放在上面的细节中了
代码运行部分
Carla版本0.9.10.1,python版本3.7,已经在Planning主机上设置好了,
①打开termnial ②输入zsh ③输入carla_wor
运行结构主要由三个大过程组成,第一过程可以直接使用文件夹内的ego_model.th来
Rails系列代码阅读,后续传上来后再一个个贴吧
Stage 0: ego model
这一过程... 我暂时不知道是干啥的 因为按道理说第一过程才是开始收集train_scenario 的才对
-
首先到config.yaml文件,修改ego_data和ego_model的储存位置
ego_data_dir: collection/phase0 ego_model_dir: collection/phase0 main_data_dir: collection main_model_dir: collection -
启动Carla,这里是写的sh文件来启动多个Carla窗口,注意一个carla本身就需要2G显存,正常6G显存电脑建议只启动2个即可
./scripts/launch_carla.sh 2 2000 # ./scripts/launch_carla.sh [NUM RUNNERS] [WORLD PORT] -
启动收集data的脚本
python -m rails.data_phase0 --num-runners=2 --port=2000首先把 在这里我就没有运行下去了,主要是出现了pygame 然后它就自己也没报什么错误,也没保存什么文件就.. 就.. 就停止了

未知错误示意
大概探索了一下,从leaderboard_evaluator.py里出来的,但是因为没办法print所以不知道更具体为什么,猜测原因是ray.remote,
为什么没办法print啊!!!真是的!!!crash_message = "Agent couldn't be set up"被自己气死了!.... emmm 果然猜测是对的,改一下ray.init部分就可以显示了
ray.init(logging_level=40, local_mode=True, log_to_driver=False)-
太绝了啊!这都是什么好东西!
-
查完感觉!超棒!太爽了吧!
关于rails代码详细介绍请跳转吧,写在一起太长了,不过上面的步骤已经能让整个运行起来了:
-
-
错误示意:
Traceback (most recent call last): File "/home/udi/KinZhang/WorldOnRails/leaderboard/leaderboard/scenarios/scenario_manager.py", line 152, in _tick_scenario ego_action = self._agent() File "/home/udi/KinZhang/WorldOnRails/leaderboard/leaderboard/autoagents/agent_wrapper.py", line 88, in __call__ return self._agent() File "/home/udi/KinZhang/WorldOnRails/leaderboard/leaderboard/autoagents/autonomous_agent.py", line 115, in __call__ control = self.run_step(input_data, timestamp) File "autoagents/collector_agents/random_collector.py", line 124, in run_step self.flush_data() File "autoagents/collector_agents/random_collector.py", line 67, in flush_data 'vid': wandb.Video(np.stack(self.rgbs).transpose((0,3,1,2)), fps=20, format='mp4') File "<__array_function__ internals>", line 6, in stack File "/home/udi/anaconda3/envs/carla_py37/lib/python3.7/site-packages/numpy/core/shape_base.py", line 423, in stack raise ValueError('need at least one array to stack') ValueError: need at least one array to stack During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/udi/KinZhang/WorldOnRails/leaderboard/leaderboard/leaderboard_evaluator.py", line 365, in _load_and_run_scenario self.manager.run_scenario() File "/home/udi/KinZhang/WorldOnRails/leaderboard/leaderboard/scenarios/scenario_manager.py", line 136, in run_scenario self._tick_scenario(timestamp) File "/home/udi/KinZhang/WorldOnRails/leaderboard/leaderboard/scenarios/scenario_manager.py", line 159, in _tick_scenario raise AgentError(e) leaderboard.autoagents.agent_wrapper.AgentError: need at least one array to stack ======[Agent] Wallclock_time = 2021-07-08 14:50:50.458292 / 6.338849 / Sim_time = 4.550000067800283 / 0.717682718910227x Stopping the route, the agent has crashed: > need at least one array to stack
-
-
-
这里运行收集的数据是由随机动作得到的数据集,主要作用是用来训练车辆动力学
-
收集完后进行训练此收集数据
python -m rails.train_phase0 --data-dir=[EGO data DIR] # 注意这里的[EGO data DIR] 需要和上面config里的ego_model_dir一致
Stage 1: Q-computation
Tips 前提知晓
- 这个阶段!真的很耗时!两块TiTan XP(和1080Ti差不多)训练10个epochs需要用4天
- 但是这个阶段更耗存储空间(如果要收集到作者有的数据集需要3.4TB in the lmdb format,详情见此issue:https://github.com/dotchen/WorldOnRails/issues/17#issuecomment-858148921)
- 收集数据如果因为空间不够,一定要记得删掉未完成的那一个part不然frame无法正确读取,计算q value的脚本会报错
- 记得提前对 config_nocrash.yaml 文件进行修改config 和 数据路径不然... 会报错的,详情见倒数第二部分可能出现的问题
- 此次使用会出现CUDA报错问题,详情见倒数第二部分可能出现的问题
收集数据
完成上面的车辆参数学习后,我们就可以把我们的动作(油门、方向盘、刹车)转成速度输出了,也就是上面理论部分提到的:
\(\hat{L}_{t}^{e g o}=\left(x_{t}, y_{t}, v, \theta\right)\) 自身车辆的状态是处于整个离散化空间的中间的;对于value fall outside就直接为0
这里主要是收集数据
# Open Carla
./scripts/launch_carla.sh [NUM RUNNERS] [WORLD PORT]
# 这一层设置你想要收集的数据
python -m rails.data_phase1 --scenario={train_scenario, nocrash_train_scenario} --num-runners=[NUM RUNNERS] --port=[WORLD PORT]
-
打开Carla
-
收集数据,
scenario是指在哪个环境下,比如前者就是通过leaderboard来收集数据,后者可指定route在Town01下的4个不同的训练天气所以这个部分总结来看:在一个位置,根据已知的min, max的动作阈值,生成一张动作表,然后通过地图(其实也算是上帝视角)来给各个动作块附上reward,然后选取最大的。reward的标准呢在这里,不得不说一句这个作者代码是真的牛掰... 硬生生看来我好久才理解了
计算Q Value
等待上面数据收集完成后,就可以关闭Carla,运行Q value label的脚本
# Q-labeling
python -m rails.data_phase2 --num-runners=[NUM RUNNERS]
代码阅读:/
运行后可以从wandb上看到一些记录的细节:
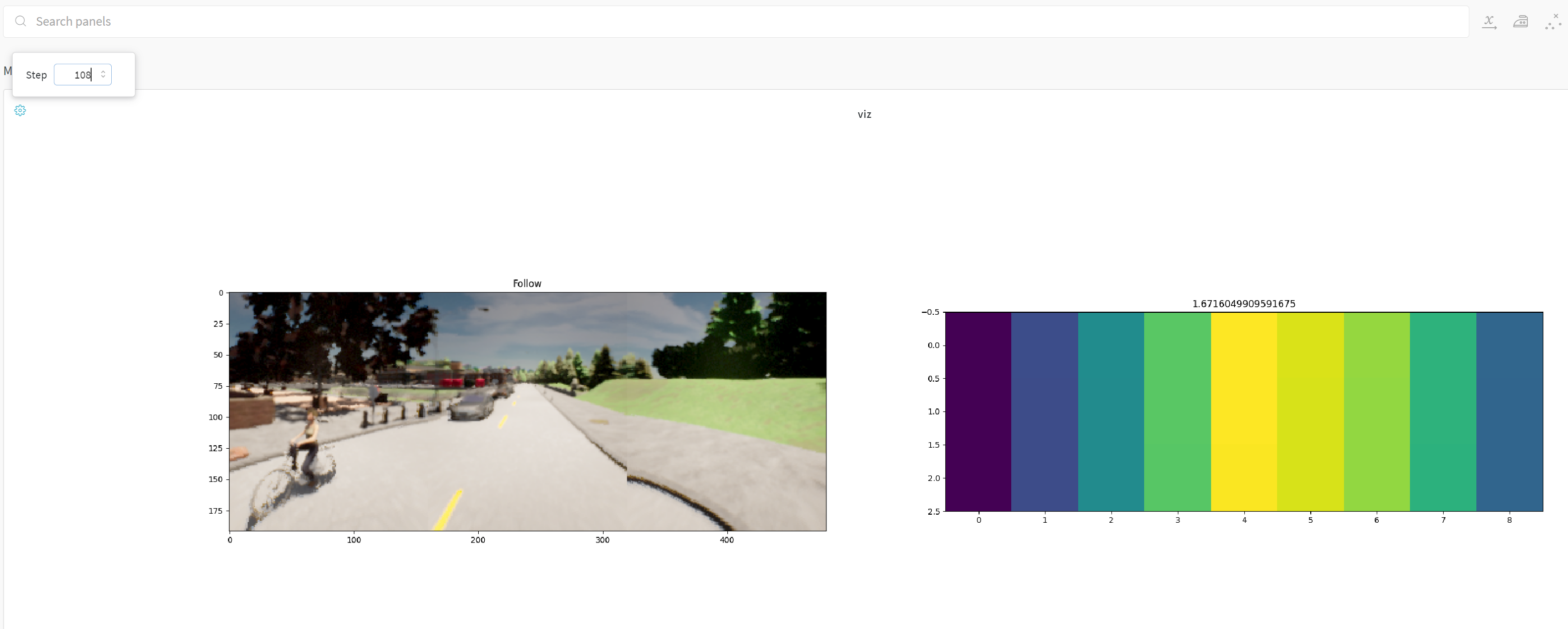
大概可以看到即使只有1W(原作者数据集的1/1000都不到 也是花了1小时才做好的Q value label的过程)
-
因为需要从油门、方向盘、刹车 → 速度 → 预测位置,最后一个预测位置也就是我们需要的state in the world
-
我忘记这个问题为什么问出来了,但是大概是这样的,首先做出的动作,并没有实际做出,而是根据地图的上帝因素进行判断,判断的前提是拿ego_model知晓了 这个动作做出后 位置大概在哪里,然后和地图waypoint偏移什么的来进行比较
-
首先提出这个问题的时候,我还没意识到又是一次上帝视角去判断所有reward;第二动作确实是离散的,收集的频率为4Hz,也就是说动作为保持250ms直到下一次更新?
Stage 2: Image model training
python -m rails.train_phase2
可能会遇到的运行问题
-
ModuleNotFoundError: No module named 'leaderboard.leaderboard_evaluator'
原因:这是因为我下载了leaderboard后,结构是这样的leaderboard/leaderboard/code,
解决方案:
- 把leaderboard复制出来就好了
- 或者是在原主leaderboard下加一个空的__init__.py文件即可
-
> cuda runtime error (38) : no CUDA-capable device is detected at /opt/conda/conda-bld/pytorch_1579040055865/work/aten/src/THC/THCGeneral.cpp:50运行第二阶段的数据收集时,也就是这行
python -m rails.data_phase1 --scenario={train_scenario, nocrash_train_scenario} --num-runners=[NUM RUNNERS] --port=[WORLD PORT]原因:主要错误也指明了,是找不到cuda
解决方案:定位到在q_collector.py文件中device是没有指定哪一个的
参考:https://github.com/pytorch/pytorch/issues/5046
for key, value in config.items(): setattr(self, key, value) os.environ["CUDA_VISIBLE_DEVICES"] = '0' device = torch.device('cuda') ego_model = EgoModel(1./FPS*(self.num_repeat+1)).to(device) -
感觉第二阶段的bug挺多的啊... 整个config中路径都没有被读入哎 emmm我知道了,是我没有看清楚config.yaml,这个data_phase1读取的config是!!!! config_nocrash.yaml真是绝了,应该在readme里面说一声的
Debug小技巧
对于python来说,debug感觉上应该比C/C++轻松不少的,首先是我一开始设置了很久的launch因为这个不是直接运行一个py文件而是 -m脚本方式运行,所以launch中应该要加入其下的Python env但是我加了很久,怎么着都不行,所以就另辟蹊径走到了,直接开一个口进行监听的方式
具体参考:https://blog.csdn.net/m0_37991005/article/details/113342656
步骤:
-
配置launch.json文件
其中launch文件是这样的:注意第一个Debug是我当时设置了很久的环境 也没设对,所以第二个启动时注意选择好VScode界面
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Debug", "type": "python", // PYTHONPATH = ${CARLA_ROOT}/PythonAPI/carla/":"${SCENARIO_RUNNER_ROOT}":"${LEADERBOARD_ROOT} //~/KinZhang/WorldOnRails/PythonAPI/carla/:~/KinZhang/WorldOnRails/leaderboard:~/KinZhang/WorldOnRails/scenario_runner // "python.pythonPath": "~/KinZhang/WorldOnRails/PythonAPI/carla/", "request": "launch", "program": "${file}", "console": "integratedTerminal", "cwd": "${fileDirname}" }, { "name": "Attach Debug", "type": "python", "request": "attach", "connect": { "host": "localhost", "port": 5678 } } ] } -
配置后,首先运行python文件(注意看中间写的
debugpy --listen 5678 --wait-for-client)python -m debugpy --listen 5678 --wait-for-client -m rails.data_phase1 --num-runners=1 --port=2000 -
然后是进入监听状态,再去VSCode里点击:首先选择好对应的那个Python文件,然后再选择好哪一个debug设置,最后点小绿就能debug上了
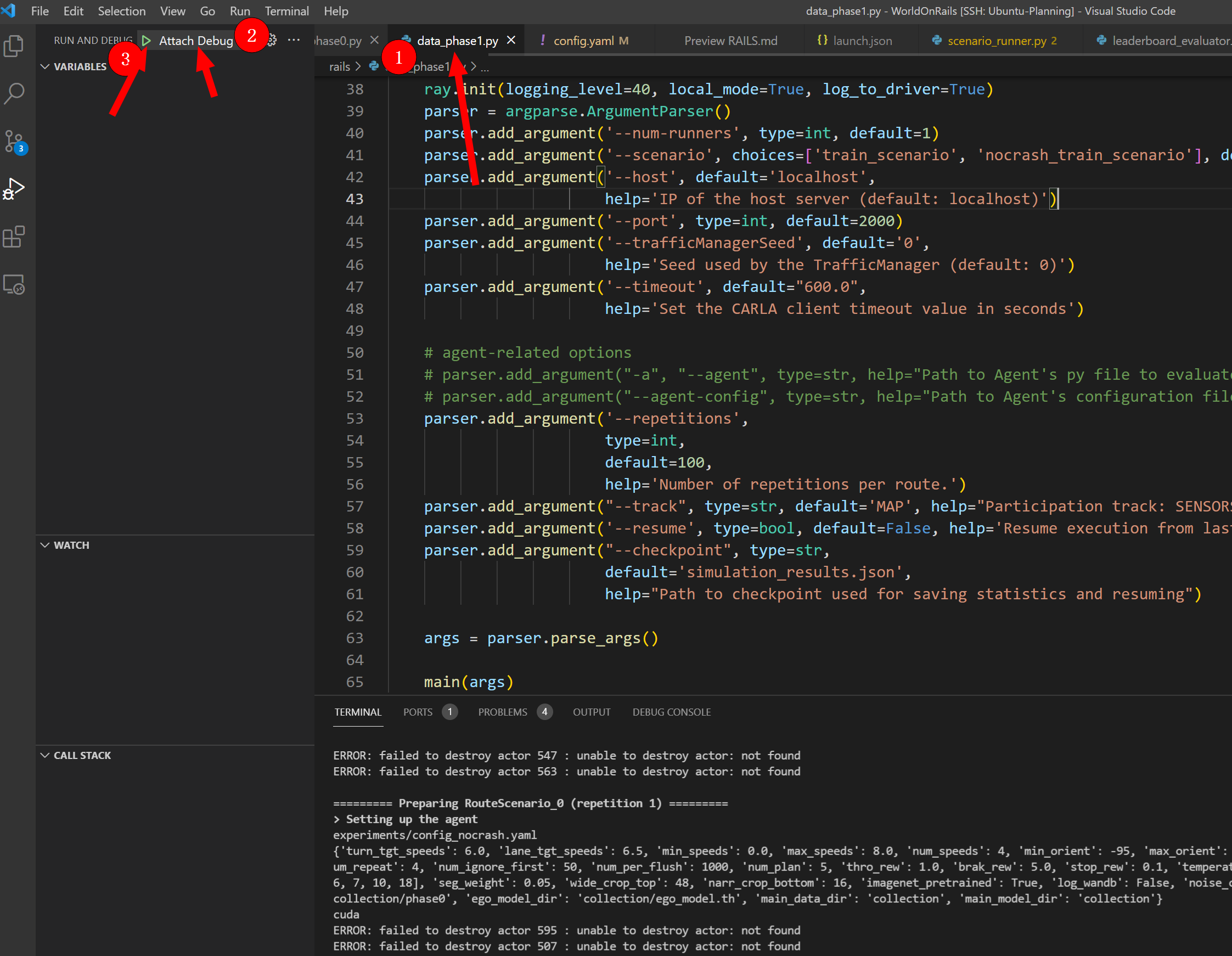
-
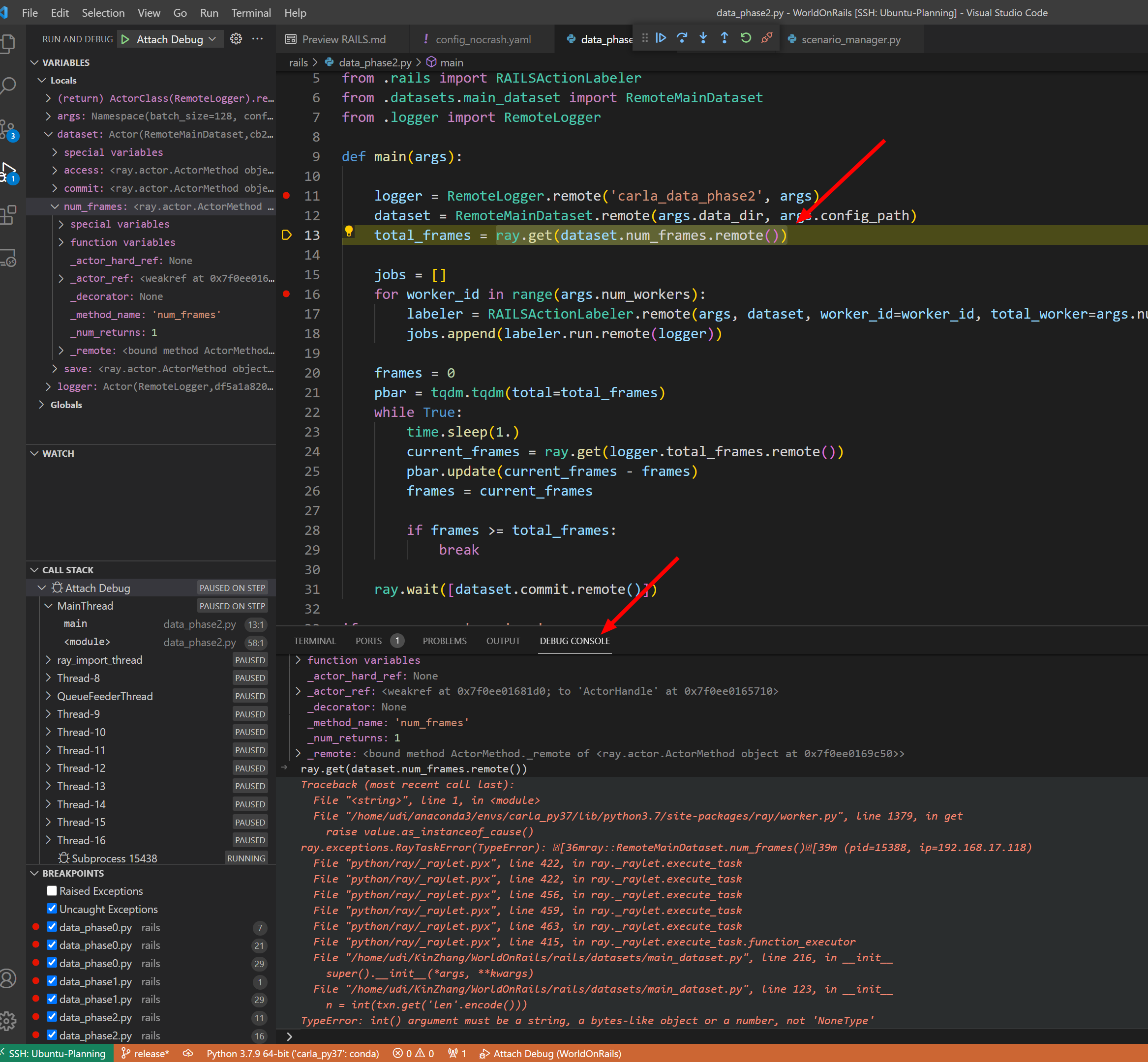
调试示意图:
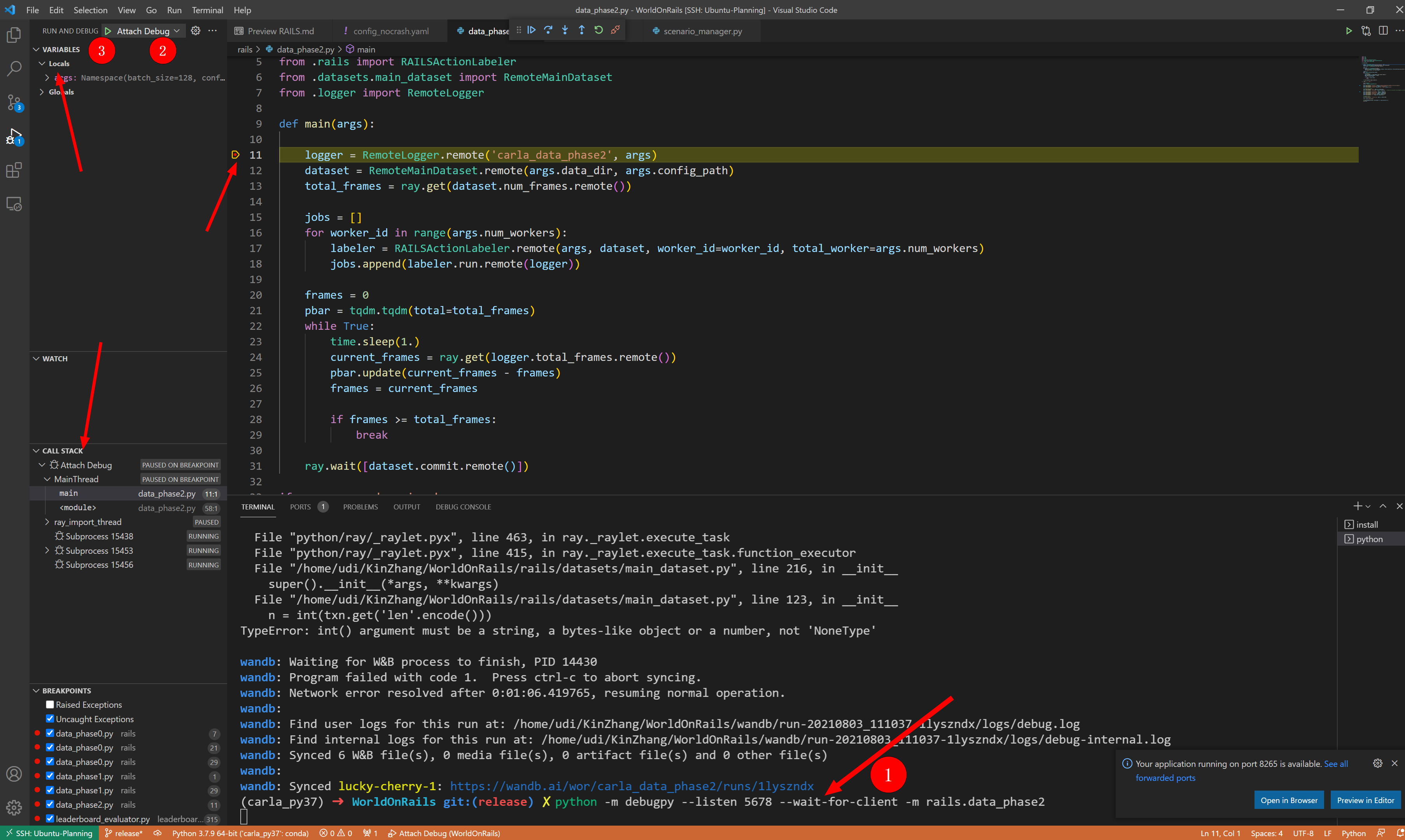
同时可以到下面的debug terminal进行实时的调试测试(python可以 编译后的C/C++类型只能显示显示而已)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号