【论文阅读】PRM-RL Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
想着CSDN还是不适合做论文类的笔记,那里就当做技术/系统笔记区,博客园就专心搞看论文的笔记和一些想法好了,【】以后中框号中间的都算作是自己的内心OS 有时候可能是问题,有时候可能是自问自答,毕竟是笔记嘛 心路历程记录;然后可能有很多时候都是中英文夹杂,是因为我觉得有些方法并没有很好地中文翻译的意思,再加上英文能更好的搜索。希望大家能接受这种夹杂写法,或者直接关掉这个看原文
前言:这是一篇18年关于PRM里面用RL来做的,是阿冰哥在分享会上分享的,特此来细读做个笔记;前提紧要:PRM: MATLAB - PRM路径规划算法
PRM: Python -【机器人路径规划】概率路线图(PRM)方法
摘要部分:
We present PRM-RL, a hierarchical method for long-range navigation task completion that combines samplingbased path planning with reinforcement learning (RL). The RL agents learn short-range, point-to-point navigation policies that capture robot dynamics and task constraints without knowledge of the large-scale topology. Next, the sampling-based planners provide roadmaps which connect robot configurations that can be successfully navigated by the RL agent. The same RL agents are used to control the robot under the direction of the planning, enabling long-range navigation. We use the Probabilistic Roadmaps (PRMs) for the sampling-based planner. The RL agents are constructed using feature-based and deep neural net policies in continuous state and action spaces. We evaluate PRM-RL, both in simulation and on-robot, on two navigation tasks with non-trivial robot dynamics: end-toend differential drive indoor navigation in office environments, and aerial cargo delivery in urban environments with load displacement constraints. Our results show improvement in task completion over both RL agents on their own and traditional sampling-based planners. In the indoor navigation task, PRMRL successfully completes up to 215 m long trajectories under noisy sensor conditions, and the aerial cargo delivery completes flights over 1000 m without violating the task constraints in an environment 63 million times larger than used in training.
重点:用featured-based和deep neural net policies在连续状态和动作空间里构建了RL agent,让RL agent在满足dynamic and task constrain,但不知道环境信息的情况下去学习 short-range, point-to-point navigation policies,
- sampling-based planner (PRM) provide roadmaps 【使用PRM采样可行点】
- RL agents are used to control the robot under the direction of planning, enabling long-range navigation 【RL通过其来规划方向?从而实现长距离,emmm 传统的PRM在这里的劣势是太长了规划时间太长嘛?那RL的学习也不见得很快...】
I. Introduction
这里点明了整个planning的两点:规划器、控制器,而本文RL学的是规划器里的活,也就是路径点?
介绍了sampling-based planners:PRMs, RRTs等,都可以在configuration space里规划出路径点,但是就算规划出了collision-free path,机器人也不能单纯的跟踪这条路径,还有以下三点要求:
- satisfy the constraints of the task 【不太懂这个是啥 任务的限制?任务有啥限制?】
- handle changes in the environment
- compensate for sensor noise, measurement errors, and unmodeled system dynamics
[RL agents have been successfully applied to several permutations of the navigation task and video games] 还有这段话中的permutations是啥意思?导航和游戏中不同的组合都可以适用嘛?..所以navigation task and video games的permutations是啥样的?【怎么读着读着做阅读理解了】
使用PRM-RL就可以同时弥补各自的缺点,两人的分工为:
- an RL agent is trained to execute a point-to-point task locally, learning the task constraints, system dynamics and sensor noise independent of long-range environment structure.
- PRM-RL build a roadmap (PRM build a roadmap) 用PRM方法构建roadmap
- using RL agent to determine connectivity 然后使用RL机器人去决定点的连接(或者是从这个点到下一个点的控制?)
- 而PRM-RL 连接两个C-space点得出trajectory的条件是:1. consistently perform the local point-to-point task between them;2. collision-free
整个过程就是:PRM在地图上(二值化的那种)构建好roadmaps,也就是一系列的可行点,在小地图里训练RL,simulator with noisy sensors and dynamics designed to emulate the unprocessed, noisy sensor input of the actual robot。最后机器人在这个地图里仅用雷达躲避静态障碍物【所以RL是规划器?控制器?感觉用PRM没有规划只给出了一大堆点,继续看看再回答】
II. Related Work
在这里面介绍了有文章在RL前引入PRM技术是为了state space dimensionality reduction 降维状态空间【妙啊!还记得上一篇的状态空间是五维的】,然后相反的这篇文章是applied RL on the full state space as a local planner for PRMs.【这是怎么了?降维不香嘛?】
在这篇文章里,the RL agent act as the local planner 也就是有全局的global trajectory了;虽然也有对PRMs的修改以使其能适用于我们约定的三点要求,但是在我们的方法里:RL local planner does Monte Carlo path rollouts with deterministic collision checking but noisy sensors and dynamics 这里基本点明了RL里用到的和解决的问题,用到蒙特卡洛方法进行采样?来决定collision checking和传感器噪音【这是咋个学习法?】,最后当且仅当路径consistently navigated我们才添加这个edges
在最后一段内容有点多,DDPG用来作为我们的local planner; CAFVI用来做无人机送货的planner;所以整个是:Model-predictive control(MPC), action filtering, and hierarchical policy approximations 比如用RL 来提供policy
- Deep Deterministic Policy Gradient(DDPG): is current state-of-the-art algorithm 适用于高维度状态与动作空间 也可以在噪音情况下学习如何控制机器人
- Continuous Action Fitted Value Iteration(CAFVI): is a feature-based continuous state and action reinforcement algorithm 适用于连续状态和动作的强化算法,多机器人任务,flying inverted pendulums和障碍物避障
III. Method **IMPORTANT PART
整个方法的总览如下图:
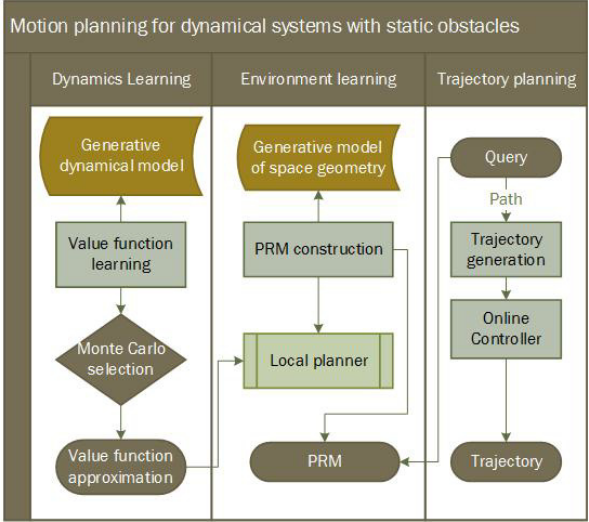
分开学习task和system dynamics能够使PRM-RL适用于新环境中【不过这里的system dynamics是个啥意思?机器人运行的动力学嘛?】
整个方法的三个步骤 概述:
- RL agent training:训练RL to perform a task on an environment comparable to the deployment environment【这里but with a small state space to make learning more tractable没有看懂是啥个意思,是有部分的状态空间不变吗】
使用的是蒙特卡洛仿真过程,不管learning用的是哪个算法(DDPG,CAFVI等) 我们还是训练多个策略并把最适合的放入下一个PRM-RL的stage【这个有点像策略评估、改进那个过程了】然后把这个best policy/value function传递到下一步roadmap creation中 - roadmap creation:PRM builder用RL学到的最优策略作为local planner(具体进算法1的伪代码),然后对环境learns a roadmap
- roadmap querying:这一步就是构建好了roadmap后对其进行的查询作用【如果是这样的话 图中的箭头 PRM和Query的应该是双向的?】
整个算法的伪代码:后面的ABC三步都是在解释这个

A. RL agent training [第一步]
在C-space中选取起点终点,这里对于state space point里的需要满足task constraints \(L(s)\)【task constraints主要是针对无人机的cargo constraints?】 \(\left\| {p\left( s \right) - p\left( g \right)} \right\| \le \epsilon\)表示现在的状态足够靠近终点,搜索结束,在式子1后面用马尔科夫过程描述了一遍:
RL 训练的过程就是点到点的导航navigation,而用强化学习的目的就是从离散时间点到多维状态动作空间的MDP,随后就是对室内和无人机的状态空间的定义,The transition probability \(P:S \times A \rightarrow \reals\),然后在室内导航仿真的时候为激光雷达加入方差0.1的高斯噪音,整个过程和强化学习中描述的基本一致,\(R: S \rightarrow \reals\)然后再去学习policy\(\pi(\mathbf{s})=\mathbf{a}\),其中\(\mathbf{s}\in S\)为观测状态,\(\mathbf{a} \in A\)为动作空间,\(\mathbf{a}=(v_l,v_r) \in \reals\),动作空间两维两速度决定, the agent should perform to maximize long-term return or value:
对于训练中rewards的定义,也就是在怎样的情况下他能得到reward
- 到达终点的时候
- 对于室内导航,stay away obstacles
- 对于空中机器人,minimize the load displacement
【这里是有点问题的,因为在强化学习书本中3.2节最后的部分曾经说过:结论:The reward signal is your way of communicating to the robot what you want it to achieve, not how you want it achieved.【在第17章也进一步的进行了讨论】而这里对于stay away obstacle就是一种how I want it achieved的表现方式了吧?】
在图2(a)中训练完成后,agents就可以在不同的环境中通过observing the world规划路径,而这个规划是在状态空间,比C-space更高的维度
B. PRM construction
这里的构建和PRM的构建并没有很大的区别,加了一下对噪音的阈值,整个三个过程在我的理解上是这样的:

C. PRM-RL Querying
见 B部分的图解释...不过主要的训练方法DDPG[21]文献可能需要后续再深入看一下,再去复现这一套的训练和实践过程
以上理论就结束了,整个理论看起来比较简单但其中自己的疑惑也挺多,主要集中在是否能在这样的假设下实现,或者是说单纯的强化学习规划小两点是普通的而这篇文章high dimensional也并没有在理论上进行很好的体现
- 关于室内导航为什么对于终点位置用polar coordinate 极坐标表示,直接xy笛卡尔不行嘛?
- reward是否会偏离想实现的东西
IV. Results
这个部分我就只分析室内导航了
A. Indoor Navigation
每一个从C-free space选取的roadmap都会经过100 queries的评估,评估方面:
- the cost of building roadmap
- the qualities of the planner trajectories
- the actual performance of the agent in simulation
- the experimental results
1) Roadmap construction evaluation
从结果表1中可以看到Local planner决定的是Number of edges和碰撞检测的次数【这个碰撞检测他好像没有定义呀... 是add edge的过程中?但是伪代码里没加可能只是评估】,因为SL没有noisy sensor observation所以collision check 10-20 times higher than RL,但是在其他方面比如roadmaps built with RL local planner are more densely connected with 15% & 50% more edges 这样也就保证了RL能通过一些狭窄路口
2) Expected trajectory characteristics
这一环节是对应实际的成功率和期待中的成功率(也就是噪音造成的失败概率计入)在第一部分已经说明了:to build the PRMs, we use an 85% success rate to connect the edges, over 20 trails. 然后在表2中我们能看到生成waypoints点的分布,\(0.85^{6.05}\)与\(0.85^{12.62}\)是建筑2与建筑3的lower bounds这个lower bounds的概念是因为对比就算成功率不如expected里的 但是lower bound的差值PRM-SL的就不是很好
3) Actual trajectory characteristics
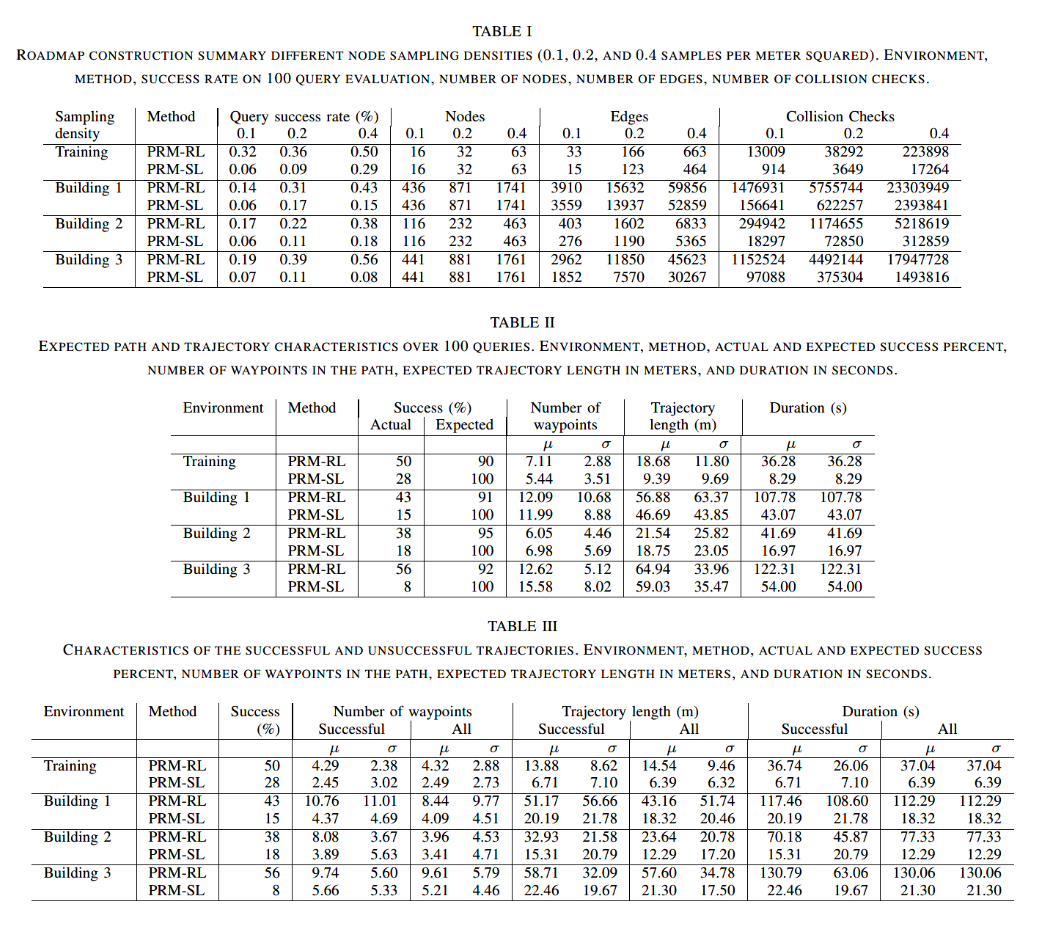
以上这三点主要都是根据这三张表进行分析,第一部分是表1,第二部分是表2,第三部分则是表3,查看在成功与所有的情况对比number of waypoints,trajectory length, duration【不过这里我的唯一问题是:为啥这里的all会和表2里的数据不一样?难道是测试次数的原因但是表3也没表明over 100 queries】还有就是RL和SL的失败标准都是:\(\left\| {p\left( s \right) - p\left( g \right)} \right\| > \epsilon\)吗?
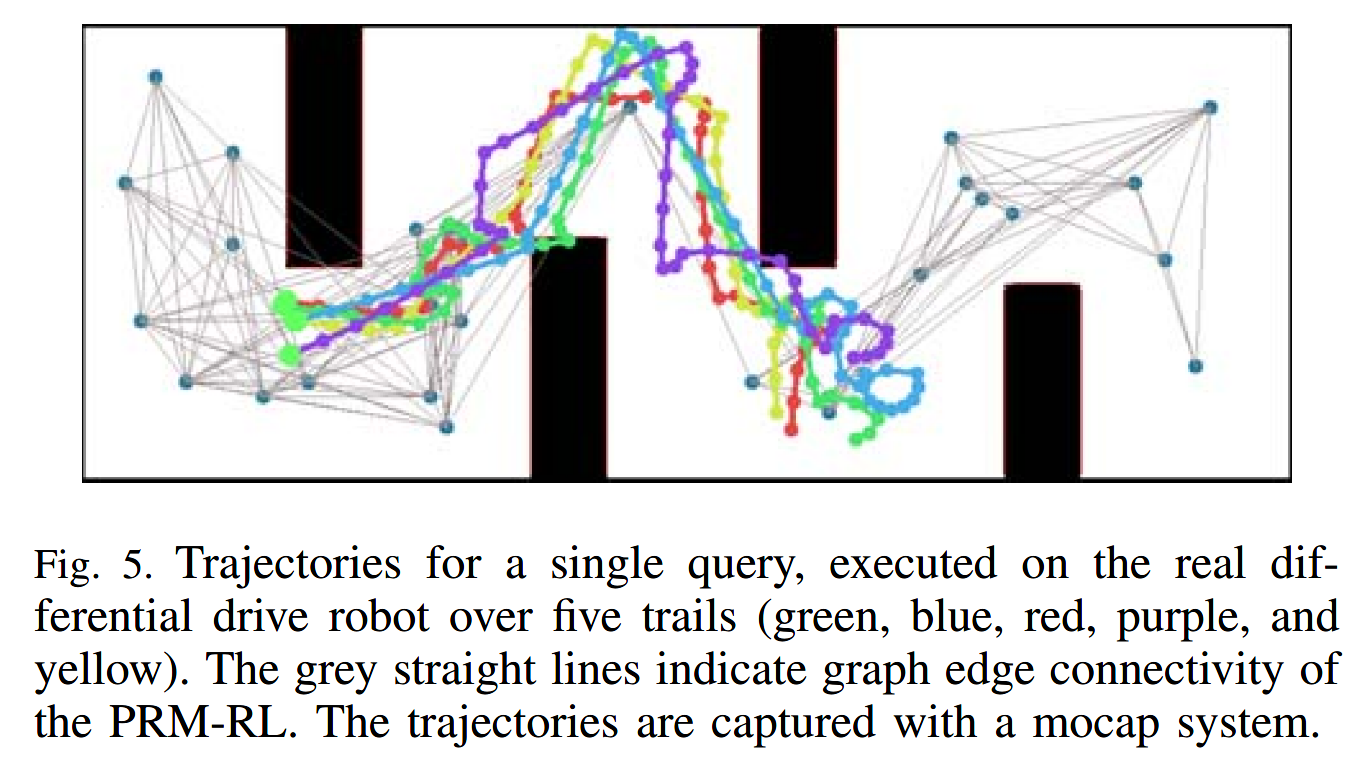
4) Physical robot experiments
这个点我没看懂他在分析什么.... 这五个标准都没有什么解释,就是five trails到底各自调整了什么参数或者是学习的方式有了改变??
V Conclusion
总结就是摘要,很短就是PRM-RL展开进行实践与sampling-based planner进行对比,然后这篇我自己的疑惑点也一大堆太菜了 回去请教完阿冰哥我再回来答一部分,不过致谢部分也有信息,一是关于仿真的环境是Torin Adamson[5],然后运动规划用的包是Parasol Lab[30] motion planning library,可以记录一下后续用以研究?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号