机器学习:4.K均值算法--应用
1. 应用K-means算法进行图片压缩
读取一张图片
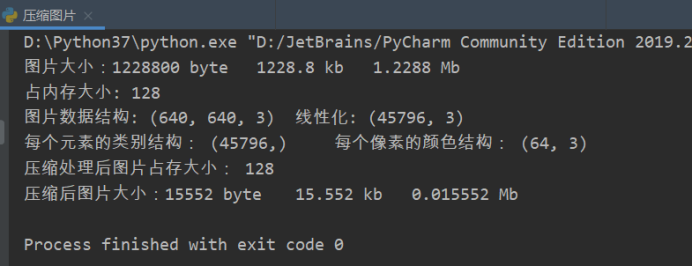
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
实现代码部分:
from sklearn.cluster import KMeans import matplotlib.pyplot as plt import matplotlib.image as img import numpy as np import sys plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 # image0 = img.imread("./machine_learning/data/015.jpg") # 读取本地的一张图片,Console运行的相对路径 image0 = img.imread("../data/015.jpg") # 读取本地的一张图片,Run运行的相对路径 plt.imshow(image0) plt.title("015.jpg-原图") # plt.show() # img.imsave('./tmp/015.jpg', image0) # Console运行的相对路径 img.imsave('../tmp/015.jpg', image0) # Run运行的相对路径 image = image0[::3, ::3] # 调节图片尺寸大小 X = image.reshape(-1, 3) # 线性化处理 print("图片大小:{} byte\t{} kb\t{} Mb".format(image0.size, image0.size / 1e3, image0.size / 1e6)) print("占内存大小:", sys.getsizeof(image0)) print("图片数据结构:", image0.shape, "\t线性化:", X.shape) plt.imshow(image) plt.title("015.jpg-降低分辨率后") # plt.show() # 用kmeans对图片像素颜色进行聚类 n_colors = 64 # (255*255*255)# 图片颜色聚类,64类中心 km_model = KMeans(n_colors) # 对X进行聚类 labels = km_model.fit_predict(X) # 一维数组,每个元素的类别 colors = km_model.cluster_centers_ # 二维(64, 3),每个像素的颜色 print("每个元素的类别结构:", labels.shape, "\t每个像素的颜色结构:", colors.shape) # for i in labels: # print(i, end='\t') new_image = colors[labels].reshape(image.shape) # 以聚类中收替代原像素颜色,还原二维数组 new_image = new_image.astype(np.uint8) # 将二维数组的数据类型转化成uint8 plt.imshow(new_image) plt.title("015.jpg-压缩后") # plt.show() new_image = new_image[::3, ::3] # 将图片再次压缩 print("压缩处理后图片占存大小:", sys.getsizeof(new_image)) print("压缩后图片大小:{} byte\t{} kb\t{} Mb".format(new_image.size, new_image.size / 1e3, new_image.size / 1e6)) plt.imshow(new_image) plt.title("new_image.jpg-压缩后") # plt.show() # 压缩前后对比 plt.figure(figsize=(12, 6)) # 定制大小画布 plt.subplot(1, 2, 1) # 放置的一行两列,位置1 plt.title("原图") plt.imshow(image0) plt.subplot(1, 2, 2) # 放置的一行两列,位置2 plt.title("最终压缩图") plt.imshow(new_image) # 类型转换,小数点转化为整形 plt.suptitle("压缩前后对比") plt.show() # img.imsave('./machine_learning/tmp/new_image.jpg', new_image) img.imsave('../tmp/new_image.jpg', new_image)
测试结果如下:
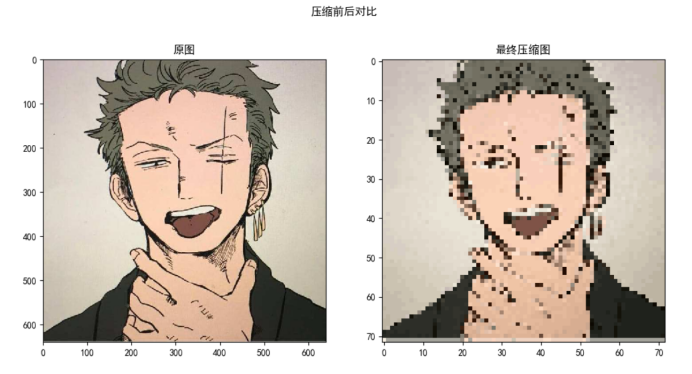
压缩图片的效果对比:
操作以及保存路径:
2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
解决案例:利用学生成绩对学生进行分组
数据来源:一位高中师弟里获取的。
研究内容:将学生的各科成绩进行KMeans模型训练,通过聚类分析将学生分成四大类。这个聚类分析,可以给学校提供对学生分班之类的数据参考,也可以对此进行因材施教。
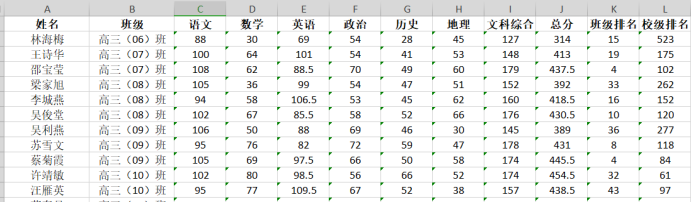
部分数据截图:
实现代码如下:
import numpy as np from sklearn.cluster import KMeans import pandas as pd import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 path = r'./machine_learning/data/dianhai10.xlsx' # Console运行的相对路径 # path = r'../data/dianhai10.xlsx' # Run运行的相对路径 df = pd.read_excel(path) df = pd.DataFrame(df) df.info() # 查看索引、数据类型和内存信息 # 数据预处理 df1 = df[ ['姓名', '语文', '数学', '英语', '文科综合']] score = np.array(df1.iloc[:, 1:5].fillna(value=0).astype(int)) # 把成绩切割出来 # 构建模型 km_model = KMeans(n_clusters=4) # 分四类 # 训练模型 km_model.fit(score) # 模型的预测 km_pre = km_model.predict(score) # 预测聚类结果 kc = km_model.cluster_centers_ # 聚类中心 print("聚类结果:", km_pre) print("聚类中心:", kc) g1 = np.array(df1[km_pre == 0]['姓名']) # 取名字 g2 = np.array(df1[km_pre == 1]['姓名']) # 取名字 g3 = np.array(df1[km_pre == 2]['姓名']) # 取名字 g4 = np.array(df1[km_pre == 3]['姓名']) # 取名字 print(g1.shape, g2.shape, g3.shape, g4.shape) g = [g1, g2, g3, g4] print("聚类结果所对应的学生:", g) # 散点图 plt.scatter(df1.iloc[:, 0], km_pre, c=km_pre, s=50, cmap='rainbow', alpha=0.5) plt.title("每个学生的分组情况") plt.xlabel("学生") plt.ylabel("聚类结果") plt.xticks([]) plt.show()
测试结果如下:
读取数据:
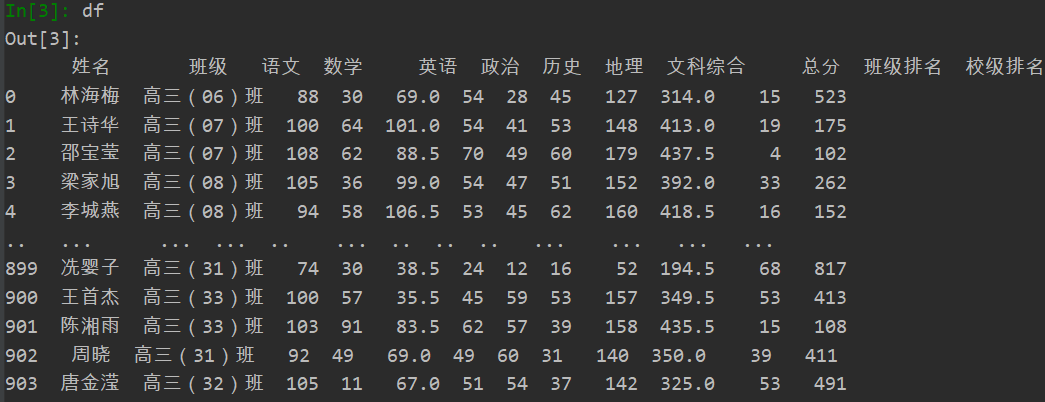
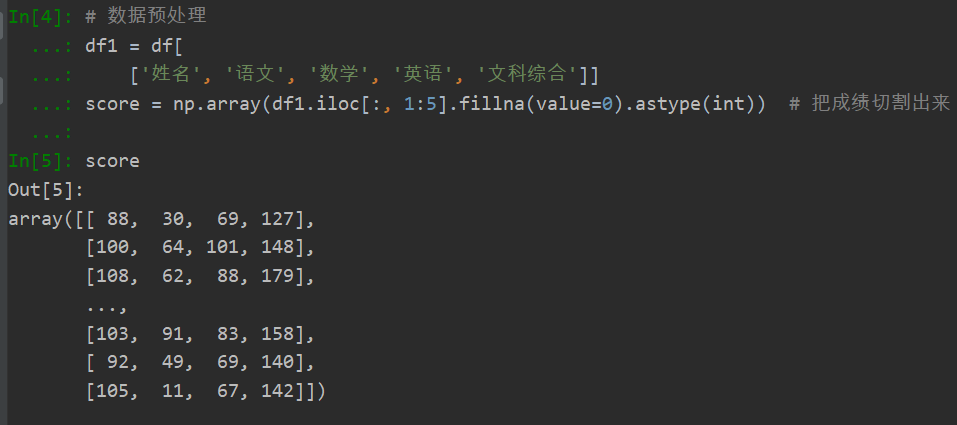
数据预处理:
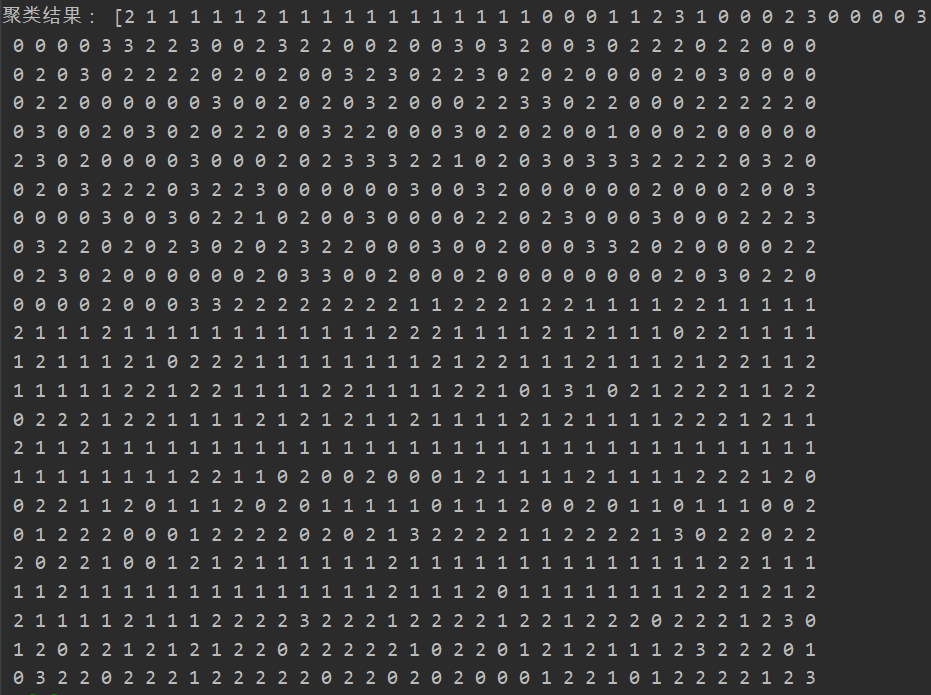
聚类结果:
聚类中心:

分类数据情况:
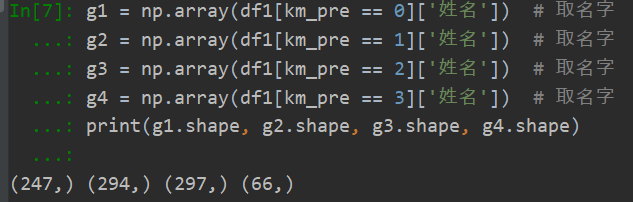
四类的学生名字部分截图:
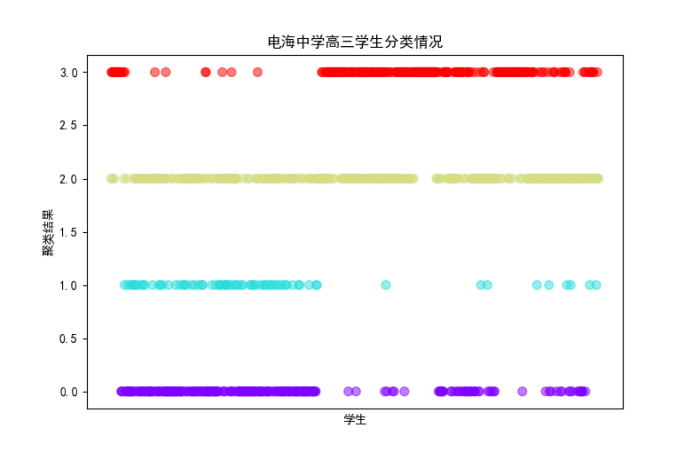
散点图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号