机器学习:3.K均值算法
1). 扑克牌手动演练k均值聚类过程:>30张牌,3类
①随机在扑克牌中抽取30张牌,当中取3张聚类中心10,4,2 进行分类

②计算三堆牌的平均值分别为11,5,2。
③以11,5,2为新的聚类中心来分类

④计算平均值,均值不变,分类结束。
2). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。(加分题)
算法代码如下:
# 自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示。 import numpy as np from sklearn.datasets import load_iris import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 # 获取鸢尾花数据集 iris = load_iris() n = len(iris.data) # 鸢尾花花瓣数据的长度 x = iris.data[:, 0] # 获取花瓣长度 y = np.zeros(n) # 初始化数组 # 1) 选取数据空间中的K个对象作为初始中心,每个对象代表一个聚类中心; # # 初始聚类中心数组(选中心) def initcenter(x, k): # 选择后k个样本作为初始类中心 return x[0:k].reshape(k) # 2) 对于样本中的数据对象,根据它们与这些聚类中心的欧氏距离,按距离最近的准则将它们分到距离它们最近的聚类中心(最相似)所对应的类; # ①数组中的值,与聚类中心最小距离所在类别的索引号(求距离) def nearest(kc, i): d = abs(kc - i) # 距离绝对值 w = np.where(d == np.min(d)) return w[0][0] # ②对数组的每个值分类(归类) def xclassify(x, y, kc): for i in range(x.shape[0]): y[i] = nearest(kc, x[i]) return y # 3)更新聚类中心:将每个类别中所有对象所对应的均值作为该类别的聚类中心,计算目标函数的值; # 求新类中心 def kcmean(x, y, kc, k): list1 = list(kc) flag = False for i in range(k): m = np.where(y == i) n = np.mean(x[m]) if list1[i] != n: list1[i] = n flag = True # 聚类中心发生变化 return (np.array(list1), flag) # 4) 判断聚类中心和目标函数的值是否发生改变,若不变,则输出结果,若改变,则返回2)。 k = 3 # 类中心个数,即最终分类的我类别数 kc = initcenter(x, k) # 聚类中心 flag = True while flag: y = xclassify(x, y, kc) kc, flag = kcmean(x, y, kc, k) print("聚类结果:", y) print("聚类中心:", kc) # 散点图 plt.scatter(x, x, c=y, s=50, cmap='rainbow', alpha=0.5) plt.title("鸢尾花花瓣长度数据做聚类的散点图") plt.xlabel('花瓣长度') # 横坐标 plt.ylabel('聚类结果') # 纵坐标名称 plt.show()
测试结果如下:
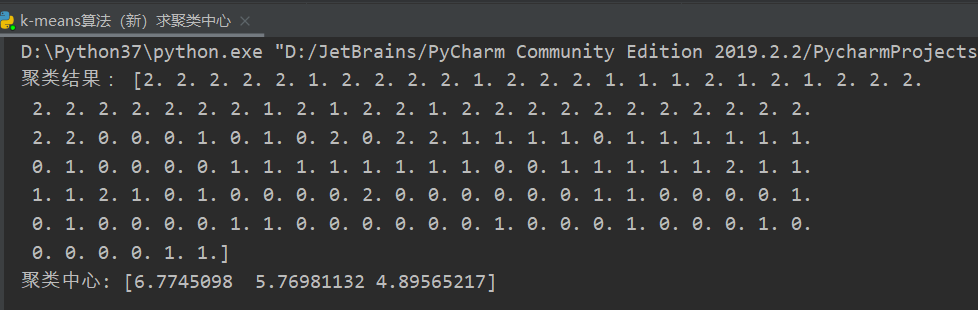
鸢尾花花瓣长度数据做聚类的散点图如下:

3). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
算法代码如下:
# 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示 from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 iris = load_iris() # 获取鸢尾花数据集 x = iris.data[:, 0] # 获取鸢尾花花瓣长度数据 x = x.reshape(-1, 1) # 将数据扁平化处理 # 调用sklearn库实现对鸢尾花数据进行聚类分析 km_model = KMeans(n_clusters=3) # 构建模型 km_model.fit(x) # 训练模型 # y = km_model.predict(x) # 预测模型 kc = km_model.cluster_centers_ # 聚类中心 y = km_model.labels_ # 查看聚类结果 print("聚类中心:", kc) # print("预测结果:", y) print("聚类结果", y) # 散点图 plt.scatter(x[:, 0], x[:, 0], c=y, s=50, cmap='rainbow', alpha=0.5) plt.title("鸢尾花花瓣长度数据做聚类的散点图") plt.xlabel('花瓣长度') # 横坐标 plt.ylabel('聚类结果') # 纵坐标名称 plt.show()
测试结果如下:
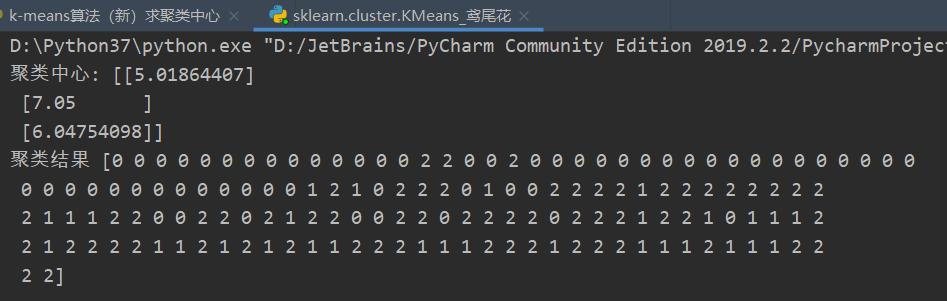
鸢尾花花瓣长度数据做聚类的散点图如下:

4). 鸢尾花完整数据做聚类并用散点图显示.
算法代码如下:
# 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示 from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = 'SimHei' # 设置中文显示 iris = load_iris() # 获取鸢尾花数据集 x = iris.data # 获取鸢尾花花瓣长度完整数据 # 调用sklearn库实现对鸢尾花数据进行聚类分析 km_model = KMeans(n_clusters=3) # 构建模型 km_model.fit(x) # 训练模型 # y = km_model.predict(x) # 预测模型 kc = km_model.cluster_centers_ # 聚类中心 y = km_model.labels_ # 查看聚类结果 print("聚类中心:", kc) # print("预测结果:", y) print("聚类结果", y) # 散点图 plt.scatter(x[:, 2], x[:, 3], c=y, s=50, cmap='rainbow', alpha=0.5) plt.title("鸢尾花花瓣长度完整数据做聚类的散点图") plt.xlabel('花瓣长度') # 横坐标 plt.ylabel('聚类结果') # 纵坐标名称 plt.show()
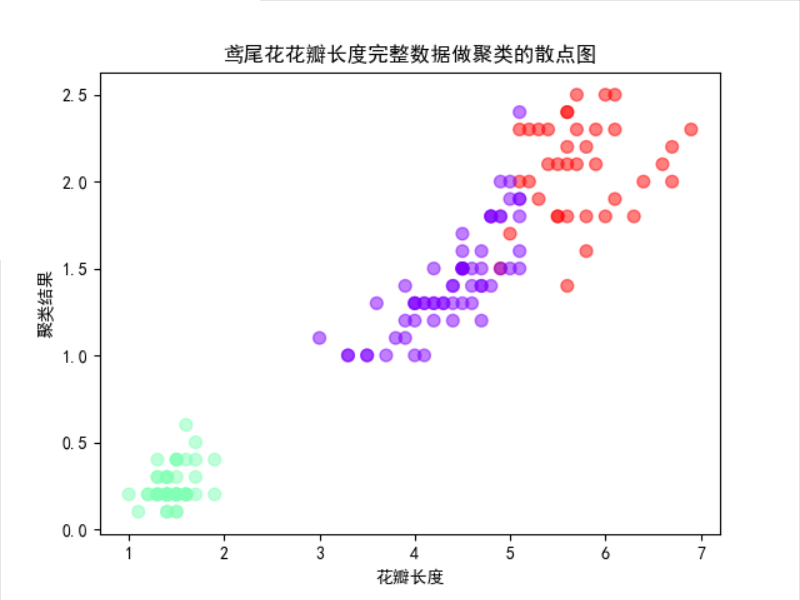
测试结果如下:
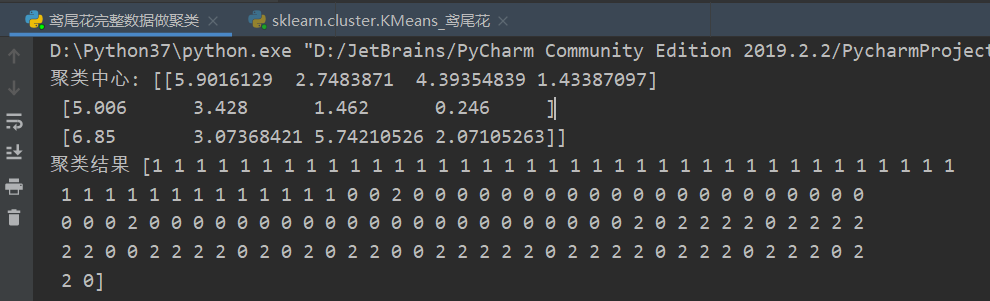
鸢尾花花瓣长度完整数据做聚类的散点图如下:
5).想想k均值算法中以用来做什么?
1.文档分类器:根据标签、主题和文档内容将文档分为多个不同的类别。
2.识别犯罪地点:使用城市中特定地区的相关犯罪数据,分析犯罪类别、犯罪地点以及两者之间的关联,可以对城市或区域中容易犯罪的地区做高质量的勘察。
3.客户分类:聚类能过帮助营销人员改善他们的客户群,并根据客户的购买历史、兴趣或活动监控来对客户类别做进一步细分。
4.保险欺诈检测:机器学习在欺诈检测中也扮演着一个至关重要的角色,在汽车、医疗保险和保险欺诈检测领域中广泛应用。
5.乘车数据分析:面向大众公开的Uber乘车信息的数据集,为我们提供了大量关于交通、运输时间、高峰乘车地点等有价值的数据集。
6.网络分析犯罪分子:网络分析是从个人和团体中收集数据来识别二者之间的重要关系的过程。网络分析源自于犯罪档案,该档案提供了调查部门的信息,以对犯罪现场的罪犯进行分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号