Redis部署架构
部署架构
单节点(Single)
优点
-
架构简单,部署方便
-
高性价比:缓存使用时无需备用节点(单实例可用性可以用 supervisor 或 crontab 保证),当然为了满足业务的高可用性,也可以牺牲一个备用节点,但同时刻只有一个实例对外提供服务
-
高性能
缺点
-
不保证数据的可靠性
-
在缓存使用,进程重启后,数据丢失,即使有备用的节点解决高可用性,但是仍然不能解决缓存预热问题,因此不适用于数据可靠性要求高的业务
-
高性能受限于单核CPU的处理能力(Redis是单线程机制),CPU为主要瓶颈,所以适合操作命令简单,排序/计算较少场景
主从复制(Replication)
基本原理
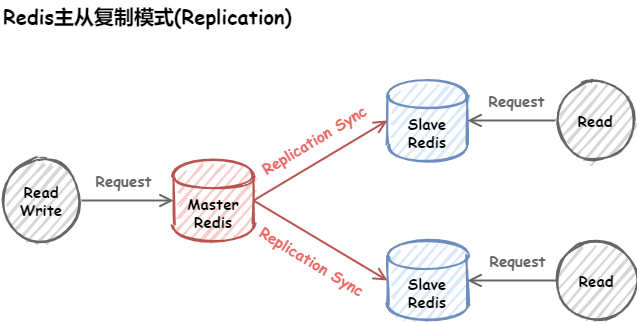
主从复制模式中包含一个主数据库实例(Master)与一个或多个从数据库实例(Slave),如下图:

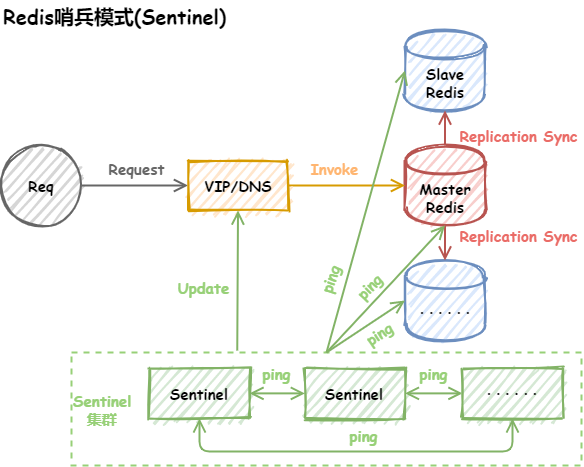
哨兵(Sentinel)
Sentinel主要作用如下:
- 监控:Sentinel 会不断的检查主服务器和从服务器是否正常运行
- 通知:当被监控的某个Redis服务器出现问题,Sentinel通过API脚本向管理员或者其他的应用程序发送通知
- 自动故障转移:当主节点不能正常工作时,Sentinel会开始一次自动的故障转移操作,它会将与失效主节点是主从关系的其中一个从节点升级为新的主节点,并且将其他的从节点指向新的主节点

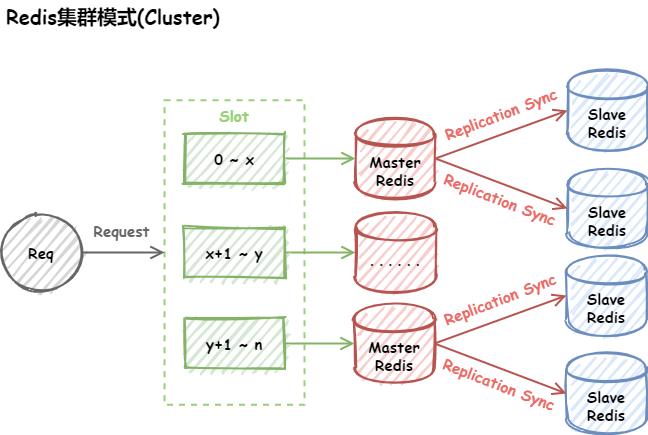
集群(Cluster)

环境搭建
Redis安装及配置
Redis的安装十分简单,打开redis的官网 http://redis.io 。
-
下载一个最新版本的安装包,如 redis-version.tar.gz
-
解压
tar zxvf redis-version.tar.gz -
执行 make (执行此命令可能会报错,例如确实gcc,一个个解决即可)
如果是 mac 电脑,安装redis将十分简单执行brew install redis即可。安装好redis之后,我们先不慌使用,先进行一些配置。打开redis.conf文件,我们主要关注以下配置:
port 6379 # 指定端口为 6379,也可自行修改
daemonize yes # 指定后台运行
单节点(Single)
安装好redis之后,我们来运行一下。启动redis的命令为 :
$ <redishome>/bin/redis-server path/to/redis.config
假设我们没有配置后台运行(即:daemonize no),那么我们会看到如下启动日志:
93825:C 20 Jan 2019 11:43:22.640 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
93825:C 20 Jan 2019 11:43:22.640 # Redis version=5.0.3, bits=64, commit=00000000, modified=0, pid=93825, just started
93825:C 20 Jan 2019 11:43:22.640 # Configuration loaded
93825:S 20 Jan 2019 11:43:22.641 * Increased maximum number of open files to 10032 (it was originally set to 256).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.3 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6380
| `-._ `._ / _.-' | PID: 93825
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
主从复制(Replication)
Redis主从配置非常简单,过程如下(演示情况下主从配置在一台电脑上):
第一步:复制两个redis配置文件(启动两个redis,只需要一份redis程序,两个不同的redis配置文件即可)
mkdir redis-master-slave
cp path/to/redis/conf/redis.conf path/to/redis-master-slave master.conf
cp path/to/redis/conf/redis.conf path/to/redis-master-slave slave.conf
第二步:修改配置
## master.conf
port 6379
## master.conf
port 6380
slaveof 127.0.0.1 6379
第三步:分别启动两个redis
redis-server path/to/redis-master-slave/master.conf
redis-server path/to/redis-master-slave/slave.conf
启动之后,打开两个命令行窗口,分别执行 telnet localhost 6379 和 telnet localhost 6380,然后分别在两个窗口中执行 info 命令,可以看到:
# Replication
role:master
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
主从配置没问题。然后在master 窗口执行 set 之后,到slave窗口执行get,可以get到,说明主从同步成功。这时,我们如果在slave窗口执行 set ,会报错:
-READONLY You can't write against a read only replica.
因为从节点是只读的。
哨兵(Sentinel)
Sentinel是用来监控主从节点的健康情况。客户端连接Redis主从的时候,先连接Sentinel,Sentinel会告诉客户端主Redis的地址是多少,然后客户端连接上Redis并进行后续的操作。当主节点挂掉的时候,客户端就得不到连接了因而报错了,客户端重新向Sentinel询问主master的地址,然后客户端得到了[新选举出来的主Redis],然后又可以愉快的操作了。
哨兵sentinel配置
为了说明sentinel的用处,我们做个试验。配置3个redis(1主2从),1个哨兵。步骤如下:
mkdir redis-sentinel
cd redis-sentinel
cp redis/path/conf/redis.conf path/to/redis-sentinel/redis01.conf
cp redis/path/conf/redis.conf path/to/redis-sentinel/redis02.conf
cp redis/path/conf/redis.conf path/to/redis-sentinel/redis03.conf
touch sentinel.conf
上我们创建了 3个redis配置文件,1个哨兵配置文件。我们将 redis01设置为master,将redis02,redis03设置为slave。
vim redis01.conf
port 63791
vim redis02.conf
port 63792
slaveof 127.0.0.1 63791
vim redis03.conf
port 63793
slaveof 127.0.0.1 63791
vim sentinel.conf
daemonize yes
port 26379
sentinel monitor mymaster 127.0.0.1 63793 1 # 下面解释含义
上面的主从配置都熟悉,只有哨兵配置 sentinel.conf,需要解释一下:
mymaster # 为主节点名字,可以随便取,后面程序里边连接的时候要用到
127.0.0.1 63793 # 为主节点的 ip,port
1 # 后面的数字 1 表示选举主节点的时候,投票数。1表示有一个sentinel同意即可升级为master
启动哨兵
上面我们配置好了redis主从,1主2从,以及1个哨兵。下面我们分别启动redis,并启动哨兵:
redis-server path/to/redis-sentinel/redis01.conf
redis-server path/to/redis-sentinel/redis02.conf
redis-server path/to/redis-sentinel/redis03.conf
redis-server path/to/redis-sentinel/sentinel.conf --sentinel
启动之后,可以分别连接到 3个redis上,执行info查看主从信息。
模拟主节点宕机情况
运行上面的程序(注意,在实验这个效果的时候,可以将sleep时间加长或者for循环增多,以防程序提前停止,不便看整体效果),然后将主redis关掉,模拟redis挂掉的情况。现在主redis为redis01,端口为63791
redis-cli -p 63791 shutdown
集群(Cluster)
上述所做的这些工作只是保证了数据备份以及高可用,目前为止我们的程序一直都是向1台redis写数据,其他的redis只是备份而已。实际场景中,单个redis节点可能不满足要求,因为:
- 单个redis并发有限
- 单个redis接收所有数据,最终回导致内存太大,内存太大回导致rdb文件过大,从很大的rdb文件中同步恢复数据会很慢
所以需要redis cluster 即redis集群。Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误。Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令.。Redis 集群的优势:
- 自动分割数据到不同的节点上
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令
为了配置一个redis cluster,我们需要准备至少6台redis,为啥至少6台呢?我们可以在redis的官方文档中找到如下一句话:
Note that the minimal cluster that works as expected requires to contain at least three master nodes.
因为最小的redis集群,需要至少3个主节点,既然有3个主节点,而一个主节点搭配至少一个从节点,因此至少得6台redis。然而对我来说,就是复制6个redis配置文件。本实验的redis集群搭建依然在一台电脑上模拟。
配置 redis cluster 集群
上面提到,配置redis集群需要至少6个redis节点。因此我们需要准备及配置的节点如下:
# 主:redis01 从 redis02 slaveof redis01
# 主:redis03 从 redis04 slaveof redis03
# 主:redis05 从 redis06 slaveof redis05
mkdir redis-cluster
cd redis-cluster
mkdir redis01 到 redis06 6个文件夹
cp redis.conf 到 redis01 ... redis06
# 修改端口, 分别配置3组主从关系
启动redis集群
上面的配置完成之后,分别启动6个redis实例。配置正确的情况下,都可以启动成功。然后运行如下命令创建集群:
redis-5.0.3/src/redis-cli --cluster create 127.0.0.1:6371 127.0.0.1:6372 127.0.0.1:6373 127.0.0.1:6374 127.0.0.1:6375 127.0.0.1:6376 --cluster-replicas 1
注意,这里使用的是ip:port,而不是 domain:port ,因为我在使用 localhost:6371 之类的写法执行的时候碰到错误:
ERR Invalid node address specified: localhost:6371
执行成功之后,连接一台redis,执行 cluster info 会看到类似如下信息:
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:1515
cluster_stats_messages_pong_sent:1506
cluster_stats_messages_sent:3021
cluster_stats_messages_ping_received:1501
cluster_stats_messages_pong_received:1515
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:3021
我们可以看到cluster_state:ok,cluster_slots_ok:16384,cluster_size:3。
拓展方案
分区(Partitioning)
指在面临单机的存储空间瓶颈时,即将全部数据分散在多个Redis实例中,每个实例不需要关联,可以是完全独立的。
使用方式
- 客户端处理
和传统的数据库分库分表一样,可以从key入手,先进行计算,找到对应数据存储的实例在进行操作。- 范围角度,比如orderId:1orderId:1000放入实例1,orderId:1001orderId:2000放入实例2
- 哈希计算,就像我们的hashmap一样,用hash函数加上位运算或者取模,高级玩法还有一致性Hash等操作,找到对应的实例进行操作
- 使用代理中间件
我们可以开发独立的代理中间件,屏蔽掉处理数据分片的逻辑,独立运行。当然Redis也有优秀的代理中间件,譬如Twemproxy,或者codis,可以结合场景选择是否使用
缺点
- 无缘多key操作,key都不一定在一个实例上,那么多key操作或者多key事务自然是不支持
- 维护成本,由于每个实例在物理和逻辑上,都属于单独的一个节点,缺乏统一管理
- 灵活性有限,范围分片还好,比如hash+MOD这种方式,如果想动态调整Redis实例的数量,就要考虑大量数据迁移
主从(Master-Slave)
分区暂时能解决单点无法容纳的数据量问题,但是一个Key还是只在一个实例上。主从则将数据从主节点同步到从节点,然后可做读写分离,将读流量均摊在各个从节点,可靠性也能提高。主从(Master-Slave)也就是复制(Replication)方式。
使用方式
- 作为主节点的Redis实例,并不要求配置任何参数,只需要正常启动
- 作为从节点的实例,使用配置文件或命令方式
REPLICAOF 主节点Host 主节点port即可完成主从配置
缺点
- slave节点都是只读的,如果写流量大的场景,就有些力不从心
- 故障转移不友好,主节点挂掉后,写处理就无处安放,需要手工的设定新的主节点,如使用
REPLICAOF no one晋升为主节点,再梳理其他slave节点的新主配置,相对来说比较麻烦
哨兵(Sentinel)
主从的手工故障转移,肯定让人很难接受,自然就出现了高可用方案-哨兵(Sentinel)。我们可以在主从架构不变的场景,直接加入Redis Sentinel,对节点进行监控,来完成自动的故障发现与转移。并且还能够充当配置提供者,提供主节点的信息,就算发生了故障转移,也能提供正确的地址。
使用方式
Sentinel的最小配置,一行即可:
sentinel monitor <主节点别名> <主节点host> <主节点端口> <票数>
只需要配置master即可,然后用redis-sentinel <配置文件> 命令即可启用。哨兵数量建议在三个以上且为奇数。
使用场景问题
- 故障转移期间短暂的不可用,但其实官网的例子也给出了
parallel-syncs参数来指定并行的同步实例数量,以免全部实例都在同步出现整体不可用的情况,相对来说要比手工的故障转移更加方便 - 分区逻辑需要自定义处理,虽然解决了主从下的高可用问题,但是Sentinel并没有提供分区解决方案,还需开发者考虑如何建设
- 既然是还是主从,如果异常的写流量搞垮了主节点,那么自动的“故障转移”会不会变成自动“灾难传递”,即slave提升为Master之后挂掉,又进行提升又被挂掉
集群(Cluster)
Cluster在分区管理上,使用了“哈希槽”(hash slot)这么一个概念,一共有16384个槽位,每个实例负责一部分槽,通过CRC16(key)&16383这样的公式,计算出来key所对应的槽位。
使用方式
配置文件
cluster-enabled yes
cluster-config-file "redis-node.conf"
启动命令
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 \
--cluster-replicas 1
存在问题
- 虽然是对分区良好支持,但也有一些分区的老问题。如如果不在同一个“槽”的数据,是没法使用类似mset的多键操作
- 在select命令页有提到, 集群模式下只能使用一个库,虽然平时一般也是这么用的,但是要了解一下
- 运维上也要谨慎,俗话说得好,“使用越简单底层越复杂”,启动搭建是很方便,使用时面对带宽消耗,数据倾斜等等具体问题时,还需人工介入,或者研究合适的配置参数
常见问题
题目:保证Redis 中的 20w 数据都是热点数据 说明是 被频繁访问的数据,并且要保证Redis的内存能够存放20w数据,要计算出Redis内存的大小。
-
保留热点数据:对于保留 Redis 热点数据来说,我们可以使用 Redis 的内存淘汰策略来实现,可以使用allkeys-lru淘汰策略,该淘汰策略是从 Redis 的数据中挑选最近最少使用的数据删除,这样频繁被访问的数据就可以保留下来了
-
保证 Redis 只存20w的数据:1个中文占2个字节,假如1条数据有100个中文,则1条数据占200字节,20w数据 乘以 200字节 等于 4000 字节(大概等于38M);所以要保证能存20w数据,Redis 需要38M的内存
题目:MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
限定 Redis 占用的内存,Redis 会根据自身数据淘汰策略,加载热数据到内存。所以,计算一下 20W 数据大约占用的内存,然后设置一下 Redis 内存限制即可。
题目:假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用 keys 指令可以扫出指定模式的 key 列表。对方接着追问:如果这个 Redis 正在给线上的业务提供服务,那使用 keys 指令会有什么问题?这个时候你要回答 Redis 关键的一个特性:Redis 的单线程的。keys 指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用 scan 指令,scan 指令可以无阻塞地提取出指定模式的 key 列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用 keys 指令长。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号