面向对象设计与构造第一次总结作业
第一次作业——多项式计算
---结构分析
第一次作业我只使用了两个类,正像下面的类图所表示的那样,分别是Poly和ComputePoly。Poly类是不可变的,能保存一个多项式,可以进行加、减运算。ComputePoly是程序的主类,能够读取一个多项式加减运算表达式的字符串,并输出计算结果。parseExpression方法通过调用parsePoly方法和parseOperator方法将输入的字符串转换为Poly对象和运算符列表。compute方法从polyList和opList取出多项式和运算符进行计算,返回计算结果。
总的代码量是248行(后面的度量分析图中可以看到),其中ComputePoly类占167行,Poly类81行;程序总共有28个方法,Poly占10个,而ComputePoly占18个。由于写Poly类的时候参考了教材的写法,Poly还算比较合适,无论是从两个类的代码量还是方法个数来看,ComputePoly都显得不太协调。事实上也如此,ComputePoly做了除计算外所有的事情:处理输入(包括错误处理,提取多项式),将多项式和运算符们存到数组里,调用compute方法得出结果,最后输出结果。这是典型的面向过程式的思路,颇有一点用C语言写程序的味道。

再仔细一想,ComputePoly做这么多事情合适吗?就这个不那么复杂的程序而言,管理ComputePoly所做的事情还是能够接受的,但是再实现一个乘法功能呢?很明显,上面的两个类都需要做修改,对于Poly而言,只需增加一个计算乘法的方法就可以了,但是对ComputePoly来说,第1,4,5,6共4个方法都需要修改。假如按照建议设计那样将ComputePoly进一步分成3个类InputHandler,PolyManager,PolyArithmetic,同样地,输入处理InputHandler要做修改,PolyManager也需要修改,但PolyArithmetic不需要修改。实际该改的都得改,说白了还是前面所说的第1,4,5,6个方法。但是在这样一种设计下进行修改的复杂性就降低了,修改InputHandler时只需要记得正则表达式改一下能匹配乘号,而不需关心乘法和加法在一起时的谁先计算谁后计算的问题;而修改PolyManager时也无需关注输入是否处理好了,只用专心实现calculate方法和appendOperator方法(如下图)。这样一来不用在ComputePoly长长的代码中苦苦寻找某个方法,上改下改,减少出错的可能性,二来也不会被整体的复杂性所烦扰,分解成两个问题后可单独实现。

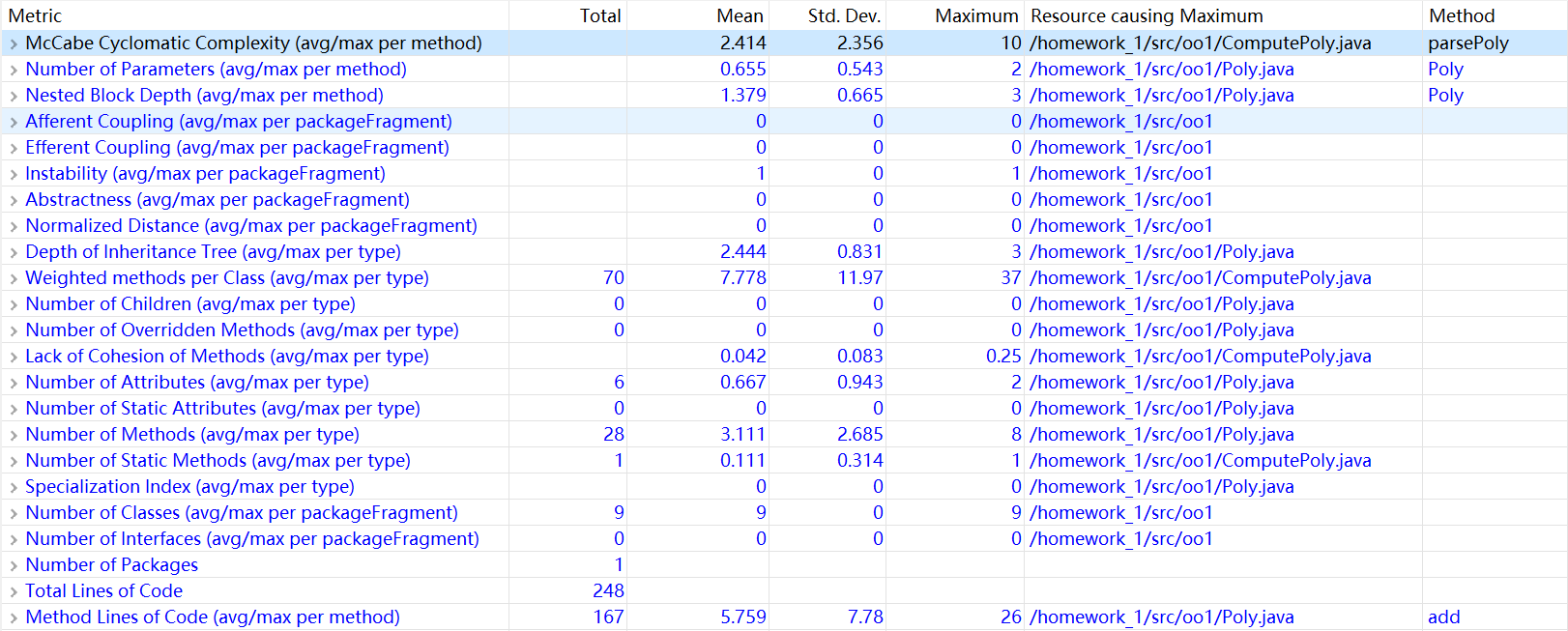
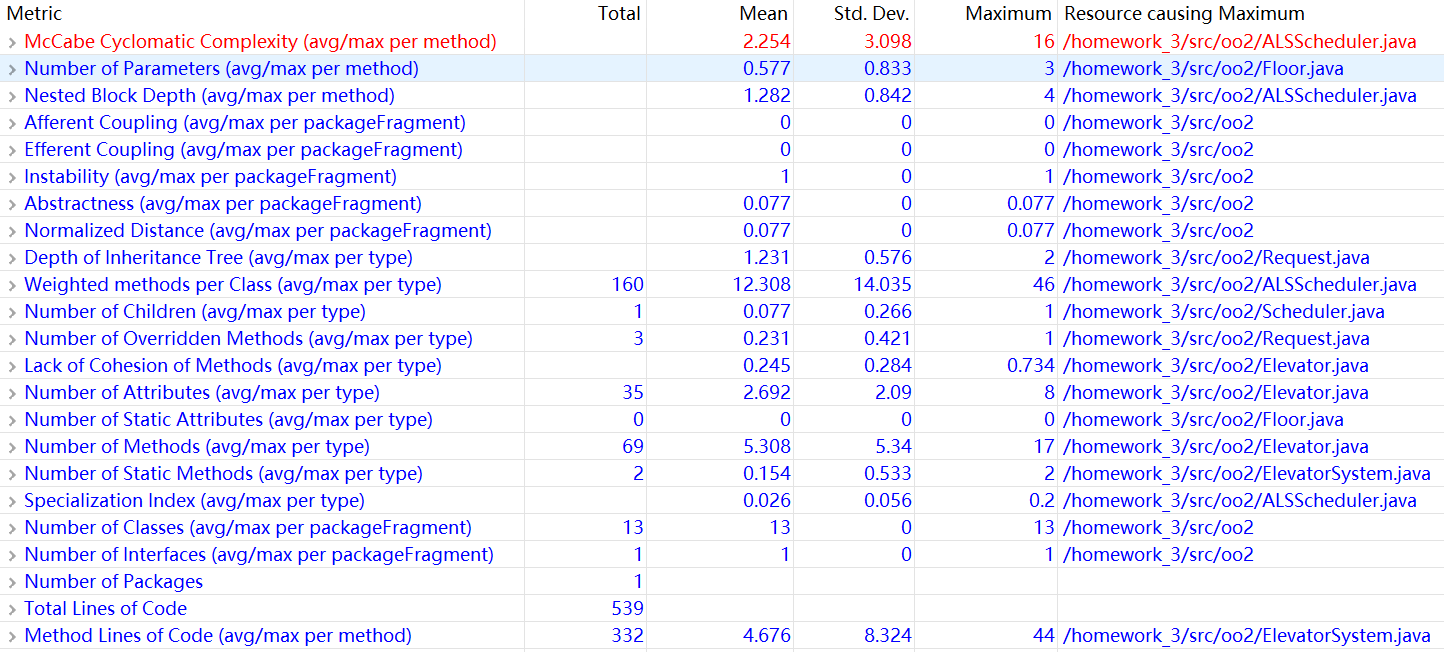
无论如何,在初识面向对象设计前我还是带着面向过程式的思维,幸好能够从教材上学习到如何编写Poly类(非常感谢第一次作业时有这么好一个范例),初步领略了OO之美。下图是用eclipse的metrics插件对第一次作业代码分析得到的结果。重点关注一下第一个McCabe Cyclomatic Complexity,它中文名叫圈复杂度,是流程控制图中独立路径的数目,主要由分支和循环个数决定,越大表明越复杂,测试时所需考虑的情况也就越多(因为每个路径都要被测试),当它非常大的时候,程序的测试就变得十分复杂。这里的最大值是10,还能接受。仔细查看,造成最大值的方法是ComputePoly里的parsePoly方法,原因可能是需要进行输入检查,涉及的不同错误输入种类数较多。
Nested Block Depth是if,while,for的嵌套深度。这里是最大值3,处于正常范围。最大值一个来自Poly的add方法,考虑到实现两个多项式加法的细节,是可以接受的,另一个同样来自parsePoly方法,原因同样是涉及输入错误处理。
再看一下Method Lines of Code,方法的代码行数,这里最大值是26,不算太大。
---BUG分析
此次作业的bug在于正则表达式的匹配,我使用一个正则表达式试着去匹配整个输入的字符串,潜在的危险是堆栈溢出。在分类树上是有“压力测试”这一项的,而且助教也说过注意不要爆栈,但是当时没想明白什么会导致栈溢出,而且是第一次使用正则表达式,主观上也认为压力测试没什么用,就没有构造相应的测试样例,导致了这个bug的产生。bug出现在isCorrectFormat方法中,这个方法检查了输入的字符串是否符合规定的格式。要解决这个问题可采用分段匹配的方式,整个字符串是多个多项式,中间用加减号连接,因此可以分别匹配每个多项式。
测试同学代码时,我使用了每个分支树结点的对应测试用例(除了压力测试)。同学的代码中存在类似以“f”,“ff”,“fff”命名的变量,我尝试着去理解同学的意图,再加上大量的分支循环嵌套,实在是难以揣测。
第二次作业
---结构分析
第二次作业一开始我花了一天的时间理解作业指导书,从头到尾读了好几遍才弄清楚。到第三次作业也是如此,我试着边读边用自己的语言去表达指导书的规定,并且举出例子,然后分条把觉得重要的点写在纸上,这样做有些笨拙和繁琐,不过的确能帮助我理解指导书的意图。
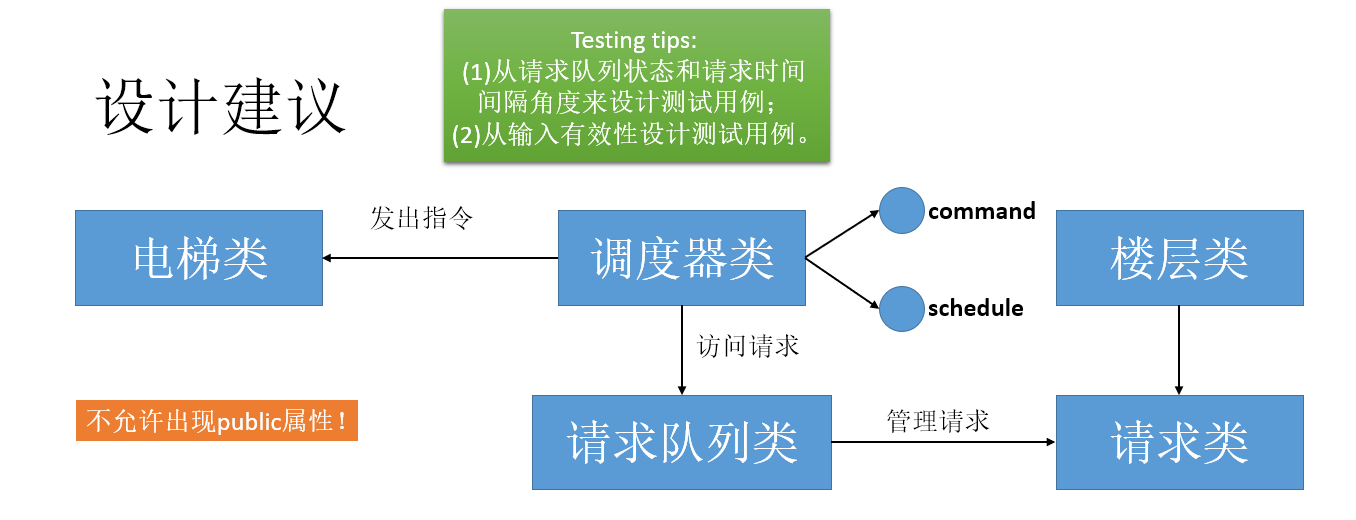
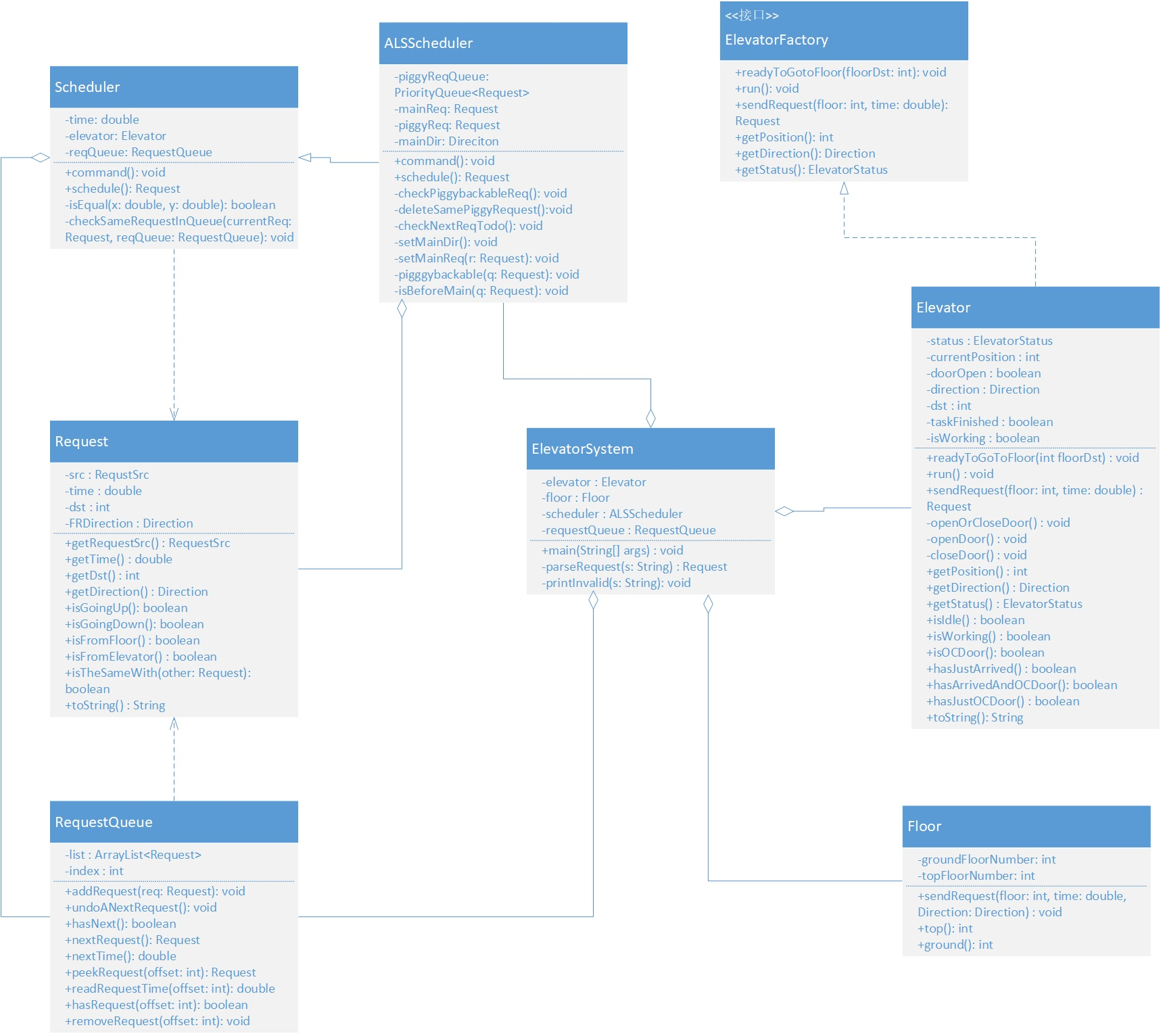
课件中给出了提示,要构造电梯类、调度类、请求类、请求队列类和楼层类共5个类(如下图)。要怎样确定该哪个类该做什么,这是除了理解指导书外另一件头疼的事情。左思右想,苦思冥想,难以划分各个类的职责。另一个问题是调度器类的command和schedule方法,弄得我一头雾水,写完后都没能参透其中奥秘,直到看了互测同学活生生的代码,才恍然大悟。
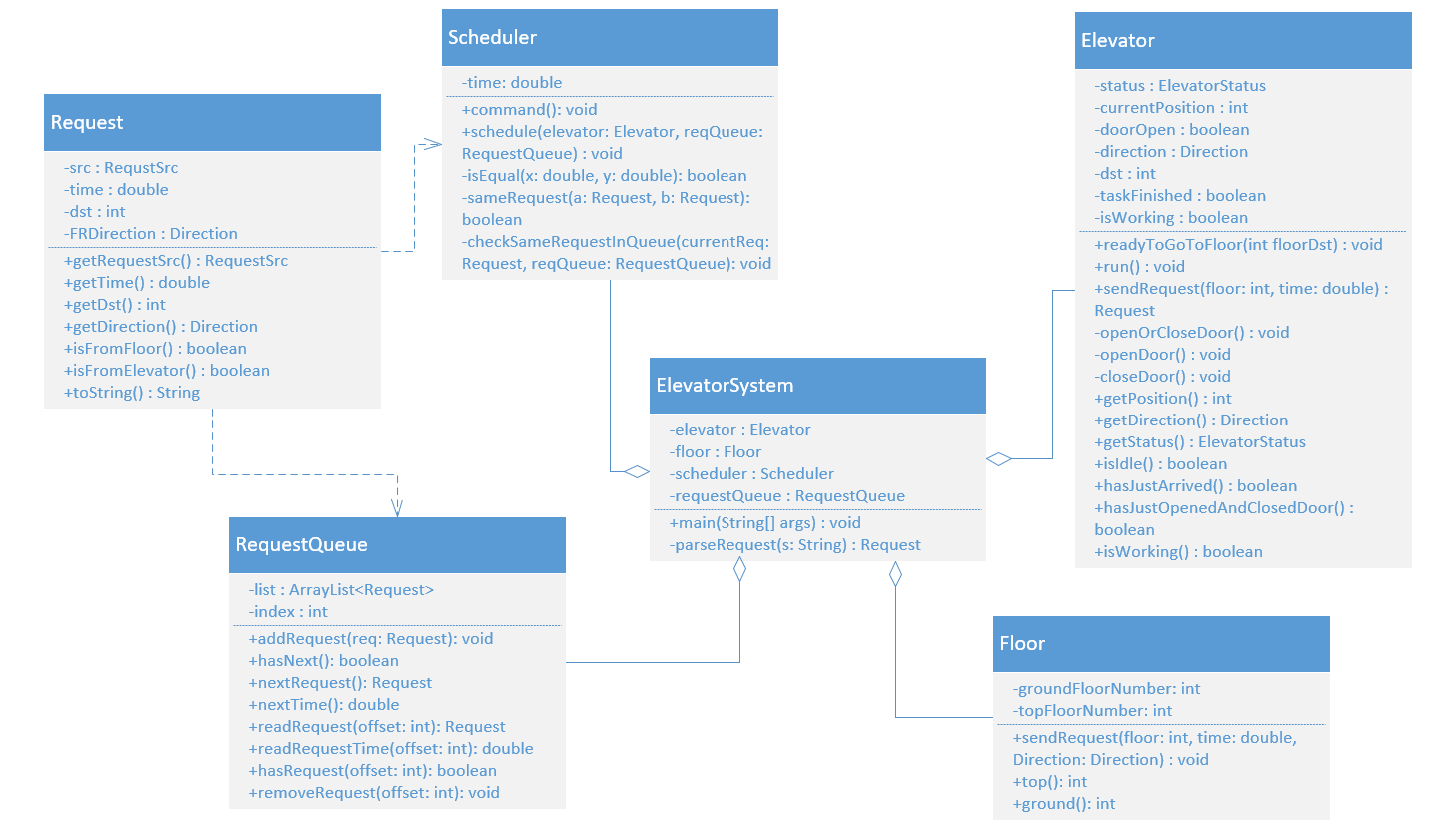
第二次作业的要点是如何把程序功能均衡地分配给各个类,如何让多个类之间协同工作,要避免出现Idiot Class和God Class。从下面的类图中可以看到Floor类就是比较白痴的一个类,它只知道楼层顶楼和底楼的编号。其实,可以考虑让楼层类知道更多的信息,比如某层楼是否有电梯到达。
除了出现了一个Idiot Class外,另一个缺点是,在main方法里展开对输入的处理,这与第一次作业相同,由于自己没能意识到这种做法的坏处,在第二、三次作业时仍没有加以改正。
本次作业的设计是否均衡呢?下面就再用定量的方法分析一下。
每个类的属性个数、方法个数、代码行数如下面的表格所示,其中方法个数包括了构造方法。从数据上看,方差较大。代码行数最多的类是ElevatorSystem,可能是因为在这个类里做了输入处理,如果把输入的处理分开来,应该会更均衡一些。
| 类 | Elevator | ElevatorSystem | Floor | Request | RequestQuue | Scheduler | 均值 | 方差 |
| 属性个数 | 7 | 4 | 2 | 4 | 2 | 1 | 3.3 | 4.6 |
| 方法个数 | 14 | 2 | 4 | 9 | 10 | 6 | 7.5 | 19.1 |
| 类代码行数 | 95 | 107 | 18 | 48 | 38 | 55 | 60.2 | 1170.2 |
一个比较大的数据是电梯类的方法个数14,其中用于状态查询的方法占了一半。由于事先未规划好,在编码的时候为了方便,新增了一些方法。仔细分析会发现一些方法是冗余的,比如getStatus方法,事实上这个方法也从未被调用过。另一个原因可能是题目要求的电梯状态是定义在左开右闭区间上的,有时候为了方便我会使用左闭右开区间,这也增加了一定的复杂性。
再看一下类的职责是否明确。
拿电梯类举例,它总共有14个方法,方法总数占到整个程序约1/3,但仔细看,只发现能够让电梯改变状态的只有前两个方法readyToGotoFloor和run,run方法是让电梯运行到0.5s后的状态,而前者确定电梯的下一个目标。也就是说,别的类只能告诉电梯下一次去哪个楼层,电梯只管去,并且自己决定方向,其他类不能干涉电梯的运动方向。假设其他类能直接修改电梯的方向,那么在这个设计中,如果调度器让电梯向下走,但又是去往楼层数高的地方,这明显是不合适的。电梯内部不存在请求队列,无论何时,电梯都只有一个目标,它不用操心有多少请求在队列中等着它执行,只用听从调度类的指挥就可以了。
从功能的角度上看,电梯的职责是明确而单一的。但是这样做的复杂性在于,电梯调度类需要精心地设计,在每次给电梯发送命令前,需要使用电梯类提供的一系列状态查询方法检查电梯状态(之所以要检查是因为调用readyToGoToFloor会立即改变电梯的运动状态,例如当电梯向上运行时,调用方法让电梯去往比当前楼层数小的楼层,运动方向就会突然改变)。因此,调度类必须充分了解电梯各个状态的含义(尽管它不需要了解电梯是怎样确定自己的状态的)和一些内部细节,否则就可能会导致电梯出故障。这就在一定程度上增加了电梯类与调度类的耦合性,一是使编码时复杂性增加,二来修改、新增功能时容易出错(例如我在写第三次作业的时候就在这上面犯了很多错误)。
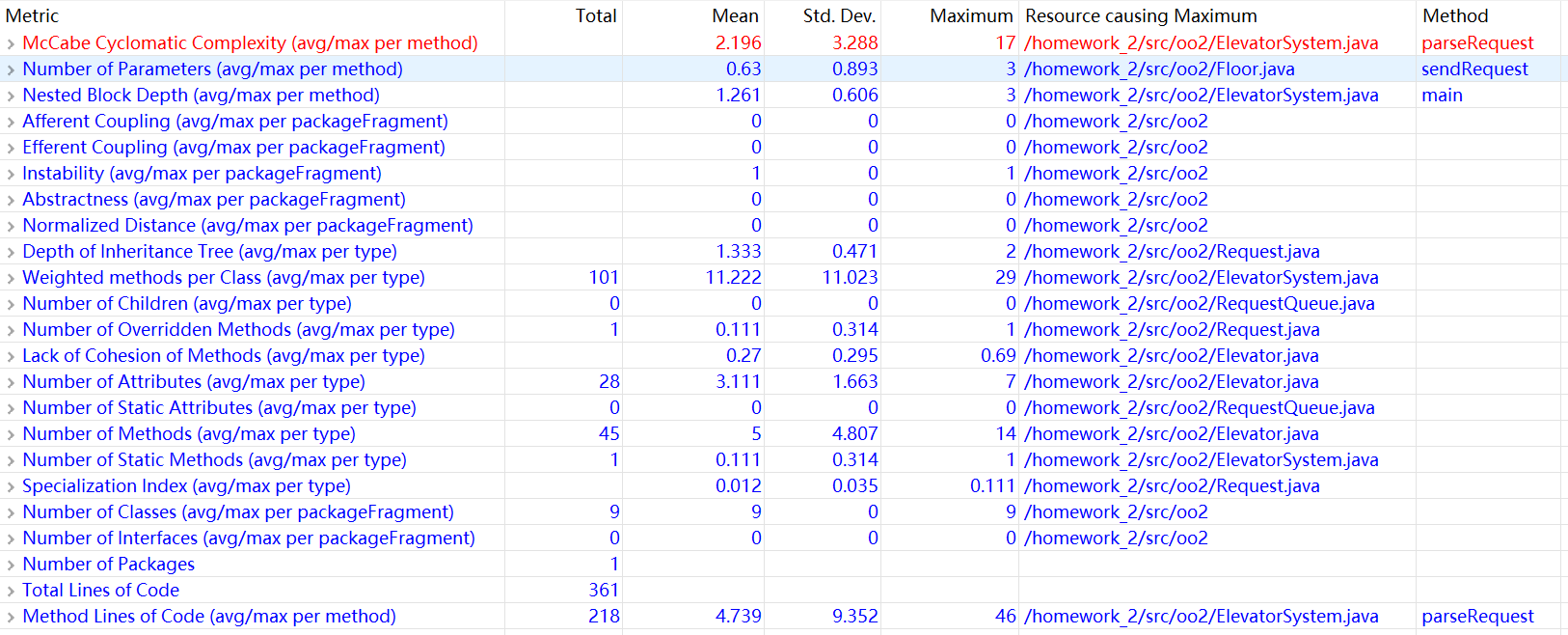
下图是第二次作业的度量分析结果。可以明显地看到标红的圈复杂度较高,最大值是17。进一步细看(图中未给出)可以发现高复杂度的来源主要是ElevatorSystem类的parseRequest方法和main方法,以及Elevator类的run方法。前者是由于输入的错误情况较多,个人写得比较凌乱,判断逻辑复杂,main方法里也做了输入的处理。后者是电梯运行时的逻辑稍微复杂,分支较多,也有两层嵌套的情况。
再看一下每个方法的行数(图中最后一行),最大值是46,与第一次作业相比有所增加,其来源同样是parseRequest和main方法。如果将输入处理部分单独封装在一个类中,并且优化一下错误处理的逻辑,应该能使整体设计均衡一些。
---BUG分析
这次作业的bug是在时间很大时运行的时间较长,需要十几秒,这是由于实现采用了每0.5s进行一次操作的方式。
第三次作业
---结构分析
本次作业在前一次作业的基础上增加了捎带功能,用继承的方式实现了ALSScheduler,对其他的类也做了一些调整。
由于保留了第二次作业的大部分内容,本次作业在均衡性上没有改进,反而由于增加捎带功能后变差。尤其是ALSScheduler,代码行数最多,逻辑也较复杂。
| 类 | Elevator | ElevatorSystem | Floor | Request | RequestQuue | Scheduler | ALSScheduler | 均值 | 方差 |
| 属性个数 | 8 | 4 | 2 | 4 | 2 | 3 | 4 | 3.9 | 4.1 |
| 方法个数 | 17 | 2 | 4 | 12 | 11 | 5 | 12 | 9 | 29.3 |
| 类代码行数 | 108 | 108 | 18 | 59 | 48 | 55 | 141 | 76.7 | 1857.9 |
细心的读者可能会发现这次的圈复杂度下降了1,但这不是因为进行了优化,只是做了点微调。这里最大值16也不是前面提到的输入处理带来的,而是来自ALSScheduler的command方法。为了实现捎带功能,我增加了很多条件判断,既难写,又难以理解和修改。
---BUG分析
- 第一条请求没能够支持前导零和正号。在第二次作业中是没有这个bug的,但这次对第一条请求有了更特殊的要求,要求只能(FR,1,UP,0),我只是用字符串是否相同的方式判断了一下,没能够考虑到特殊中的普遍性。
- 一次开门完成了多条请求,没能按请求发出时间顺序输出。
- 没能实现“一个请求完成后,其附带的顺路捎带请求可能未完成,此时按照时间顺序,将未完成的最先顺路捎带请求升级为主请求”。由于我没能发现不按“时间顺序”与“按时间顺序”有什么区别,经过多次思考后没有想清楚,主观臆测,存在侥幸心理,就导致了这个bug的产生。
上面的3点都是给我互测的同学发现的,这里要感谢这位同学。
最后再分析一下第2、3个bug与设计结构的关系。这两个bug都位于ALSScheduler类中,具体在多个方法中都有体现,究其原因,是使用了Java标准类库中的优先队列。这个队列专用于捎带队列,我按照到达楼层的时间(先后)作为各个请求的优先级,能够最早达到的,排在队首,晚到的,排在后面。问题出在同一时刻进队的请求,在出队时可能失去了输入时的顺序以及请求发出的时间顺序,这就导致了第2个bug的产生。另一方面,当主请求执行结束时,处在捎带队列队首的请求未必是按照请求发出时间最早的。
我能想到的解决办法是专门实现捎带请求队列类,兼顾到达时间顺序与请求时间顺序。在下一次作业中我会尝试着改正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号