Redis数据类型使用场景及有序集合SortedSet底层实现详解
Redis常用数据类型有字符串String、字典dict、列表List、集合Set、有序集合SortedSet,本文将简单介绍各数据类型及其使用场景,并重点剖析有序集合SortedSet的实现。
List的底层实现是类似Linked List双端链表的结构,而不是数组,插入速度快,不需要节点的移动,但不支持随机访问,需要顺序遍历到索引所在节点。List有两个主要的使用场景:
- 记住用户最新发表的博文,每次用户发表了文章,将文章id使用LPUSH加入到列表中,用户访问自己的主页时,使用LRANGE 0 9获取最新10条博文(使用LTRIM 0 9可以取出最新10条文章的同时,删除旧的文章),而不用使用order by sql语句去后端数据库取数据。
- 生产者/消费者模式,生产者往List中加入数据,消费者从List中取数据。当List为空时,消费者rpop返回为NULL,这是会进行轮询,等待一段时间继续去取。轮询模式有如下缺点:
- 客户端和redis耗费cpu和网络带宽等资源执行无效命令。
- 取回NULL后,sleep会使有新数据时,客户端消费不够及时。
为了解决轮询的问题,Redis提供了brpop和blpop实现Blocking读,当List为空时,等待一段时间再返回,当有数据时,按请求顺序返回给各客户端。(当List为空时,可以将请求Blocking读命令的客户端加入此List的Blocking读列表中,有数据时按列表序返回)
集合Set的底层实现是类似Hash,不过value全为NULL,set有求并、交、差集及随机取的功能。使用场景如下:
- 表示对象之间的联系,比如求拥有标签1、2、10的新闻,使用sinter tag:1:news tag:2:news tag:10:news。
- 随机发牌,使用spop,spop随机返回集合中的元素,比如给每位玩家发五张牌,每位玩家调用五次spop即可,为了下次发牌不需要再将牌加入set,可以在这次发牌前调用sunionstore将牌复制。
有序集合SortedSet(t_zset.c),集合中的每个值都带有分数,按分数排序,底层实现较为复杂,用到了ziplist、skiplist和dict数据结构,后文将进行详细介绍。使用场景如下:
- 排行榜问题,比如游戏排行榜,按用户分数排序,并取top N个用户。
在redis中,所有数据类型都被封装在一个redisObject结构中,用于提供统一的接口,结构如下表1:
表1 redisObject
redisObject源码(server.h) |
typedef struct redisObject { unsigned type:4;//对象类型,用于分辨字符串、列表、
|
有序列表有压缩列表ziplist和跳表skiplist两种实现方式,通过encoding识别,当数据项数目小于zset_max_ziplist_entries(默认为128),且保存的所有元素长度不超过zset_max_ziplist_value(默认为64)时,则用ziplist实现有序集合,否则使用zset结构,zset底层使用skiplist跳表和dict字典。创建有序集合的关键代码如下表2:
表2 创建有序集合
zaddGenericCommand函数 |
if (server.zset_max_ziplist_entries == 0 || server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr)) { zobj = createZsetObject(); //创建zset } else { zobj = createZsetZiplistObject();//创建ziplist }
|
ziplist是一个内存连续的特殊双向链表LinkList,减少了内存碎片和指针的占用,用于节省内存,但对ziplist进行操作会导致内存的重新分配,影响性能,故在元素较少时用ziplist。ziplist内存布局如下:
<zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
表3 ziplist在内存中各字节含义
Field |
含义 |
zlbytes(uint32_t) |
ziplist占用的内存字节数,包括zlbytes本身 |
zltail(uint32_t) |
最后一个entry的offset偏移值 |
zllen(uint16_t) |
数据项entry的个数 |
entry(变长) |
数据项 |
zlend(uint8_t) |
标识ziplist的结束,值为255 |
数据项entry的内存结构如下:<prevlen> <encoding> <entry-data>,当保存的是小整型数据时,entry没有entry-data域, encoding本身包含了整型元素值。Entry各字节含义如下表4:
表4 entry各Field含义
Field |
含义 |
prevlen |
上一个数据项entry的长度。当长度小于254字节,则prevlen占1字节,当长度大于或等于254字节,则prevlen占5字节,首字节值为254,剩下4字节表示上一entry长度。 |
encoding |
encoding的值依赖于数据entry-data。首字节的前两个bit为00、01、10,标识entry-data为字符串,同时表示encoding的长度分别为1、2、5字节,除前两个bit,剩下的bit表示字符串长度;前两个bit为11,表示entry-data为整型,接下来的2 bit表示整数类型。entry-data不同类型及encoding如下: 1) |00pppppp| - 1 byte,字符串且长度小于等于63字节(6bit) 2) |01pppppp|qqqqqqqq| - 2 bytes,字符串且长度小于等于16383字节(14bit) 3) |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytes,字符串且长度大于等于16384(后面四个字节表示长度,首字节的低位6bit设为0) 4) |11000000| - 1 bytes,len字段为1字节,后面的entry-data为整型且类型为int16_t (2 bytes) 5) |11010000| - 1 bytes, entry-data为整型且类型为int32_t (4 bytes) 6) |11100000| - 1 bytes, entry-data为整型且类型为int64_t (8 bytes) 7) |11110000| - 1 bytes, entry-data为整型且占3 bytes 8) |11111110| - 1 bytes, entry-data为整型且占1 bytes 9) |1111xxxx| - (with xxxx between 0000 and 1101),xxxx的值从1到13,可用于表示entry-data(1到12),encoding包含entry-data的值,从而不需要entry-data域 10) |11111111| - 用于标识ziplist的结束 |
entry-data |
具体的数据 |
ziplist在内存中的实例如图1,zibytes占4字节(小端存储),值为15,表示此ziplist占用内存15字节;zltail占4字节,值为12,表示最后一个数据项entry(这里是5所在的entry),距离ziplist的开头offset为12字节;entries占2字节,表示数据项数目为2; "00 f3"表示第一个entry(值为2),”00”表示前一个entry的长度为0(prevlen),”f3”对应encoding中的第9种情况(“11110011”),表示数据为整型且值为2;”02 f6”表示第二个entry,”02”表示前一个entry的长度为2(prevlen),”f6”也对应encoding的第9种情况(“11110110”),表示数据为整型且值为6.

图1 ziplist在内存中的实例
ziplist在redis中插入数据的源码及注释如表5:
表5 ziplist插入数据源码
|
ziplist插入逻辑源码(ziplist.c) |
/* Insert item at "p". */ unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) { size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen; unsigned int prevlensize, prevlen = 0; size_t offset; int nextdiff = 0; unsigned char encoding = 0; long long value = 123456789; /* initialized to avoid warning. Using a value that is easy to see if for some reason we use it uninitialized. */ zlentry tail; /* Find out prevlen for the entry that is inserted. */ //插入位置前面一个entry节点占用的字节数prevlen if (p[0] != ZIP_END) {//插入节点不在末尾节点,直接从p的前面字节读 ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); } else {//插入节点在末尾位置,找到末尾节点 unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl); if (ptail[0] != ZIP_END) { prevlen = zipRawEntryLength(ptail); } } /* See if the entry can be encoded */ if (zipTryEncoding(s,slen,&value,&encoding)) {//判断s是否可以转化为整数,并将整数值和enconding分别存在value和encoding指针 /* 'encoding' is set to the appropriate integer encoding */ reqlen = zipIntSize(encoding);//整数值长度 } else { /* 'encoding' is untouched, however zipStoreEntryEncoding will use the * string length to figure out how to encode it. */ reqlen = slen;//字符串长度 } /* We need space for both the length of the previous entry and * the length of the payload. */ //得出新插入节点占用的总字节数reqlen reqlen += zipStorePrevEntryLength(NULL,prevlen); reqlen += zipStoreEntryEncoding(NULL,encoding,slen); /* When the insert position is not equal to the tail, we need to * make sure that the next entry can hold this entry's length in * its prevlen field. */ //插入新节点不在末尾位置,则插入位置p所指向的entry节点的prevlen, //值会变成新插入节点的总长度,且prevlen所占用的字节数可能会变化, //nextdiff表示新插入节点下一节点的prevlen需要空间的变化,负值表示变小, //正值表示扩大 int forcelarge = 0; nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; if (nextdiff == -4 && reqlen < 4) { nextdiff = 0; forcelarge = 1; } /* Store offset because a realloc may change the address of zl. */ offset = p-zl; zl = ziplistResize(zl,curlen+reqlen+nextdiff);//重新分配空间,并将zl的每字节都填充到新分配的内存中 p = zl+offset; //将p后面的数据项进行移动 /* Apply memory move when necessary and update tail offset. */ if (p[0] != ZIP_END) { /* Subtract one because of the ZIP_END bytes */ memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff); /* Encode this entry's raw length in the next entry. */ if (forcelarge)//设置下一个节点的prevlen zipStorePrevEntryLengthLarge(p+reqlen,reqlen); else zipStorePrevEntryLength(p+reqlen,reqlen); /* Update offset for tail */ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen); /* When the tail contains more than one entry, we need to take * "nextdiff" in account as well. Otherwise, a change in the * size of prevlen doesn't have an effect on the *tail* offset. */ zipEntry(p+reqlen, &tail); if (p[reqlen+tail.headersize+tail.len] != ZIP_END) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff); } } else { /* This element will be the new tail. */ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl); } /* When nextdiff != 0, the raw length of the next entry has changed, so * we need to cascade the update throughout the ziplist */ if (nextdiff != 0) { offset = p-zl; zl = __ziplistCascadeUpdate(zl,p+reqlen); p = zl+offset; } /* Write the entry */ //将新数据项放入插入位置 p += zipStorePrevEntryLength(p,prevlen); p += zipStoreEntryEncoding(p,encoding,slen); if (ZIP_IS_STR(encoding)) { memcpy(p,s,slen); } else { zipSaveInteger(p,value,encoding); } ZIPLIST_INCR_LENGTH(zl,1); return zl; }
|
zset在redis中的定义如表6:
表6 zset源码
|
zset定义(server.h) |
typedef struct zset { dict *dict;//字典 zskiplist *zsl;//跳表 } zset;
|
zset同时使用dict和zskiplist实现有序集合的功能,dict是为了快速获得指定元素的分值(zscore命令,时间复杂度为O(1)),zskiplist是为了快速范围查询(zrank、zrange命令)。本文重点讲解跳表的知识。
skiplist是在有序链表的基础上发展而来,在有序链表中进行查找,需要进行顺序遍历,时间复杂度为O(n),同样,进行插入也需要顺序遍历到插入位置,时间复杂度也为O(n)。

图2 有序链表
利用有序的性质,每两个节点多加一个指针,指向下下个节点,如图3所示,新增加的指针可以构成一个新的有序链表,新链表节点个数只有下层链表的一半,当查找元素时,可以从新链表开始向右查找,碰到比查找元素大的节点,则回到下一层链表查找,比如查找元素20,查找路径如下图中标记为红的路径(head->8->17->23,23比20大,到下一层查找,17->20),由于新增的指针,查找元素时不需要和每个节点进行比较,需要比较的节点大概为原来的一半。

图3 双层有序链表
可以在新产生的链表之上,每隔两个节点,再增加一个指针,从而产生第三层链表,如图4所示,红色箭头代表查找路径,从最上层链表开始查找,一次可以跳过四个节点,进一步加快了查找速度。

图4 多层有向链表
skiplist借鉴了多层链表的思想,但多层链表这种严格的2:1关系,会导致插入和删除节点破坏上下层之间的2:1关系,导致插入位置和删除位置及后续的所有节点都需要进行调整。skiplist并不采用这种严格的2:1对应关系,每个节点的层数采用随机生成的方法,节点插入例子如下图5所示,插入节点不会影响其它节点的层数,且只需调整插入节点前后的指针,不需要对所有节点进行调整,降低了插入的复杂度。

图5 skiplist插入节点过程
skiplist随机生成层数level的的代码如表7:
表7 随机生成节点层数
|
zslRandomLevel函数(t_zset.c) |
int zslRandomLevel(void) { //随机生成节点层数,当第i层节点存在时,第i+1节点存在的概率为ZSKIPLIST_P = 1/4 //ZSKIPLIST_MAXLEVEL 64,表示节点的最大层数 int level = 1; while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1; return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; }
|
skiplist时间复杂度为o(),所占用空间的大小依赖于插入元素随机生成的层数,每个元素level至少为1,层数越高,生成的概率越低,节点的层数服从一定的概率分布,如下:
- 节点恰好只有一层的概率为1-p
- 节点层数大于等于2的概率为p,恰好等于2的概率为p(1-p)
- 节点层数大于等于k的概率为pk-1,恰好等于k的概率为pk-1(1-p)
每个节点的平均层数计算如下:
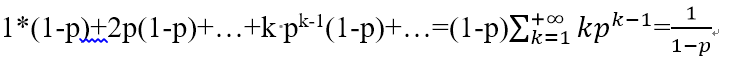
平均层数代表每个节点的平均指针数目,在redis中,p=1/4,因此平均指针数目为1.33。
在redis中skiplist的定义代码如表8,zskiplist表示跳表, zskiplistNode表示跳表中的节点, zskiplistNode包含了分值,每个节点按分值排序,且节点包含后退指针,用于双向遍历。
表8 redis中跳表结构
|
zskiplist及zskiplistNode(server.h) |
/* ZSETs use a specialized version of Skiplists */ typedef struct zskiplistNode { sds ele;//实际存储的数据 double score;//分值 struct zskiplistNode *backward;//后退指针,指向前一个节点 struct zskiplistLevel { struct zskiplistNode *forward;//前进指针,指向下一个节点 unsigned long span;//跨度,表示该层链表的这一节点到下一节点跨越的节点数,用于计算rank } level[];//层级数组,每个层级都有到下一个节点的指针和跨度 } zskiplistNode;//跳表节点 typedef struct zskiplist { struct zskiplistNode *header, *tail;//跳表头节点和尾节点 unsigned long length;//跳表元素个数 int level;//跳表的最高层数(不包括头节点,头节点实际上并不存储数据) } zskiplist;
|
redis中,zskiplist插入元素的代码如表9,在查找插入位置的过程中,记下每层需要更新的前一节点在update数组中。
表9 跳表插入节点源代码
|
zslInsert(t_zset.c) |
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) { zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; unsigned int rank[ZSKIPLIST_MAXLEVEL]; int i, level; serverAssert(!isnan(score)); x = zsl->header; for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */ //rank[i]初始化为rank[i+1],所以rank[i]-rank[i+1]表示在i层走过的节点数 rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele,ele) < 0))) { rank[i] += x->level[i].span; x = x->level[i].forward; } // 记录将要和新节点相连接的节点,x表示新节点在i层连接的上一节点 update[i] = x; } /* we assume the element is not already inside, since we allow duplicated * scores, reinserting the same element should never happen since the * caller of zslInsert() should test in the hash table if the element is * already inside or not. */ level = zslRandomLevel();//随机生成此节点的层数 if (level > zsl->level) { for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; } zsl->level = level; } x = zslCreateNode(level,score,ele); for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward; update[i]->level[i].forward = x; /* update span covered by update[i] as x is inserted here */ //rank[0]表示0层链表,插入节点x左边的节点数 //rank[i]表示i层链表,插入节点x左边的节点数 //rank[0] - rank[i]+1表示i层链表,x前一节点到x的跨度 x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); update[i]->level[i].span = (rank[0] - rank[i]) + 1; } /* increment span for untouched levels */ //在level及之上的每层,update[i]到下一节点的距离由于插入了x节点而加1 for (i = level; i < zsl->level; i++) { update[i]->level[i].span++; } //更新后退指针 x->backward = (update[0] == zsl->header) ? NULL : update[0]; if (x->level[0].forward) x->level[0].forward->backward = x; else zsl->tail = x; zsl->length++; return x; }
|
与平衡树(AVL、红黑树)比,skiplist有如下优点,这也是redis使用跳表做有序集合底层结构而不选用平衡树的原因。
- 占用内存少。通过调节概率p,可以使每个节点的平均指针数发生变化,redis中为1.33,而二叉树每个节点都有两个指针。
- ZRANGE or ZREVRANGE等范围查询更简单。Skiplist可以看作特殊的双向链表,只需找到范围中的最小节点,顺序遍历即可,而平衡树找到范围中的最小节点,仍需中序遍历。
- 和红黑树等比,skiplist实现和调试简单。
参考文献
- An introduction to Redis data types and abstractions.
- Redis内部数据结构详解(4)——ziplist.
- Pugh W. Skip lists: a probabilistic alternative to balanced trees[J]. Communications of the ACM, 1990, 33(6): 668-677.
- Redis为什么用跳表而不用平衡树?
- Is there any particular reason you chose skip list instead of btrees except for simplicity?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号