

ElasticSearch基本操作
基本使用
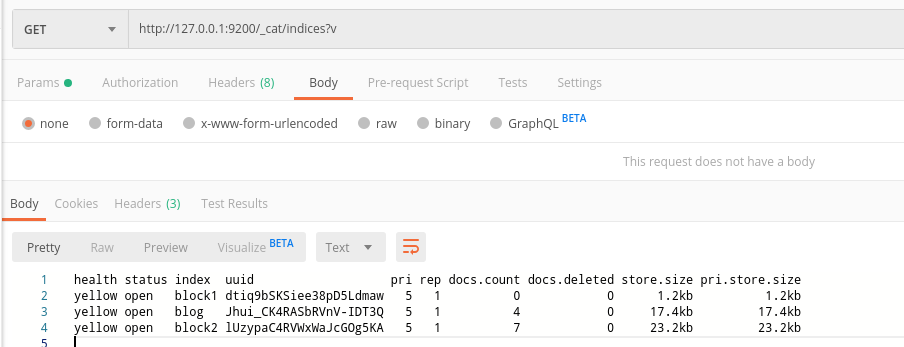
1、查看集群中有哪些索引
GET /_cat/indices?v
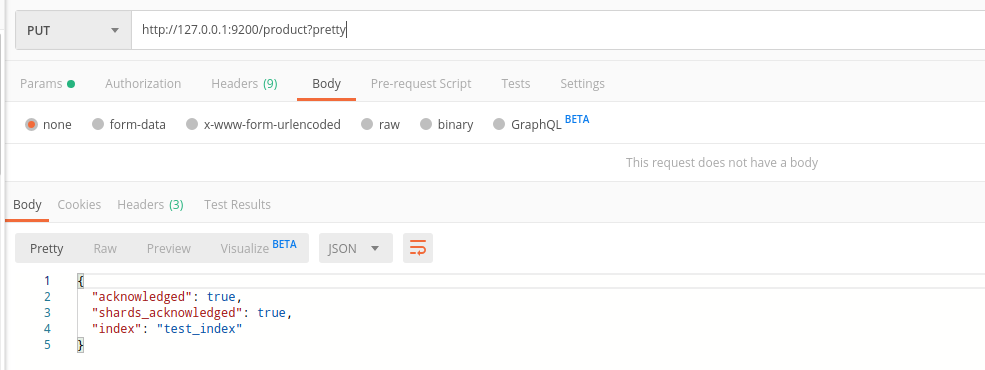
2、创建索引 索引名为product
PUT /product?pretty
3、删除索引
DELETE /product?pretty
4、新增文档并创建索引
语法格式为:
PUT /index/type/id
{
"json数据"
}
index指索引名、type指索引的类型、id是这条数据的id。
PUT /shoes/product/1
{
"name" : "NB 鞋子",
"desc" : "特别好的鞋子",
"price" : 530,
"producer" : "NB producer",
"tags": [ "实用", "美观" ]
}
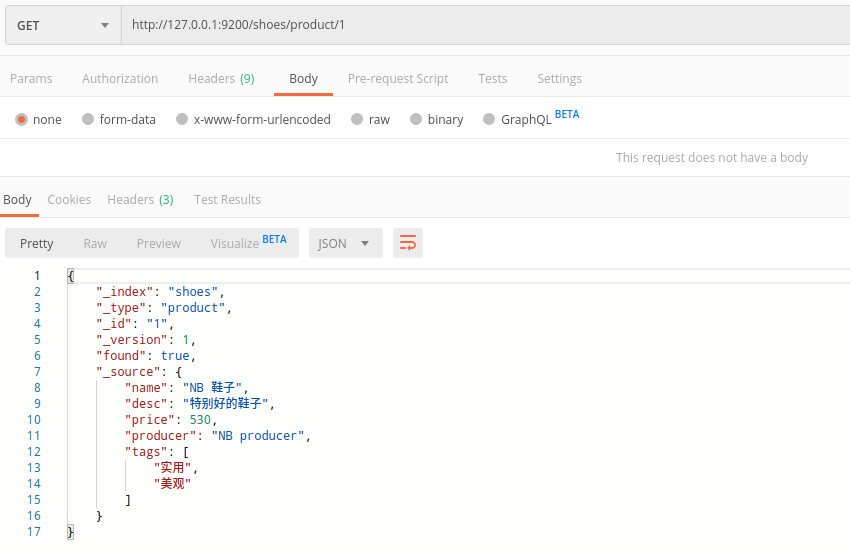
5、查询文档
GET /shoes/product/1
6、修改 修改分为全部修改和部分修改,全部修改就是直接替换,这种替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改
全部修改:
PUT /shoes/product/1
{
"name" : "NB 鞋子",
"desc" : "特别好的鞋子",
"price" : 700,
"producer" : "NB producer",
"tags": [ "耐穿", "美观" ]
}
部分修改:
POST /shoes/product/1/_update
{
"doc":{
"name":"NB 新款鞋子"
}
}
注:partal update实现原理:
partial update指的就是部分更新操作。例如
PUT /index/type/id,创建文档&替换文档,就是一样的语法
一般对应到应用程序中,每次的执行流程基本是这样的:
(1)应用程序先发起一个get请求,获取到document,展示到前台界面,供用户查看和修改
(2)用户在前台界面修改数据,发送到后台
(3)后台代码,会将用户修改的数据在内存中进行执行,然后封装好修改后的全量数据
(4)然后发送PUT请求,到es中,进行全量替换
(5)es将老的document标记为deleted,然后重新创建一个新的document
其实es内部对partal update的实际执行,跟传统的全量替换方式,几乎是一样的。
7、删除
DELETE /shoes/product/1
8、查询
GET /shoes/product/_search
query sring search的由来,因为search参数都t是以http请求的query string来附带的 ,查询返回的参数详解:
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据
搜索商品名称中包含“鞋子”的商品,而且按照售价降序排序:GET /shoes/product/_search?q=name:NB&sort=price:desc
适用于临时的在命令行使用一些工具,比如curl,快速的发出请求,来检索想要的信息;但是如果查询请求很复杂,是很难去构建的
在实际的生产环境中,几乎很少使用query string search
9、各种查询
query DSL DSL:Domain Specified Language,特定领域的语言 http request body:请求体,可以用json的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比query string search肯定强大多了 查询所有的商品 GET /shoes/product/_search { "query": { "match_all": {} } } 查询名称包含NB的商品,同时按照价格降序排序 GET /shoes/product/_search { "query" : { "match" : { "name" : "NB" } }, "sort": [ { "price": "desc" } ] } 分页查询商品,总共3条商品,假设每页就显示1条商品,现在显示第2页,所以就查出来第2个商品 GET /shoes/product/_search { "query": { "match_all": {} }, "from": 1, "size": 1 } 指定要查询出来商品的名称和价格就可以 GET /shoes/product/_search { "query": { "match_all": {} }, "_source": ["name", "price"] } 更加适合生产环境的使用,可以构建复杂的查询 query filter 搜索商品名称包含NB,而且售价大于300元的商品 GET /shoes/product/_search { "query" : { "bool" : { "must" : { "match" : { "name" : "NB" } }, "filter" : { "range" : { "price" : { "gt" : 300 } } } } } }
full-text search(全文检索) 因为我们之前没有对比的数据,所以这里先post数据进去 POST /shoes/product/2 { “name” : “NB 鞋子”, “desc” : “特别好的鞋子”, “price” : 720, “producer” : “NB two producer”, } 然后再来查询,producer这个字段,会先被拆解,建立倒排索引 : GET /shores/product/_search { "query" : { "match" : { "producer" : "NB producer" } } }
phrase search(短语搜索) 跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回 phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回 GET /shores/product/_search { "query" : { "match_phrase" : { "producer" : "NB producer" } } }
highlight search(高亮搜索结果) GET /shores/product/_search { "query" : { "match" : { "producer" : "producer" } }, "highlight": { "fields" : { "producer" : {} } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号