JDK源码分析实战系列-PriorityQueue
完全二叉树
一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
特殊之处是这个类型可以通过数组来实现,一个节点的两个子节点的只需要计算下标获得,分别是[2*n+1]和[2*(n+1)],想象一下一个数组紧凑存储节点的效果,数组没有任何空间浪费的话,看起来是那么完美,因为使用数组实现就不需要存储子节点和父节点的地址了。
堆
百度百科了一下:
- 堆中某个结点的值总是不大于或不小于其父结点的值。
- 堆总是一棵完全二叉树。
PriorityQueue
Priority queue represented as a balanced binary heap: the two children of queue[n] are queue[2n+1] and queue[2(n+1)]
The element with the lowest value is in queue[0], assuming the queue is nonempty
优先级队列在JDK中有一个教科书式的示范实现,以上是JDK源码对实现的注释。和前面介绍的完全二叉树一样,存储元素时使用的父子节点在数组中的下标使用[2n+1] 和[2(n+1)]的公式计算,如果是反过来算父节点的下标位置公式是:(n-1)>>> 1。
PriorityQueue就是一个小顶堆的实现,也是被认为实现优先级队列最高效的方式。
下面就是对PriorityQueue的实现分析。
插入元素操作
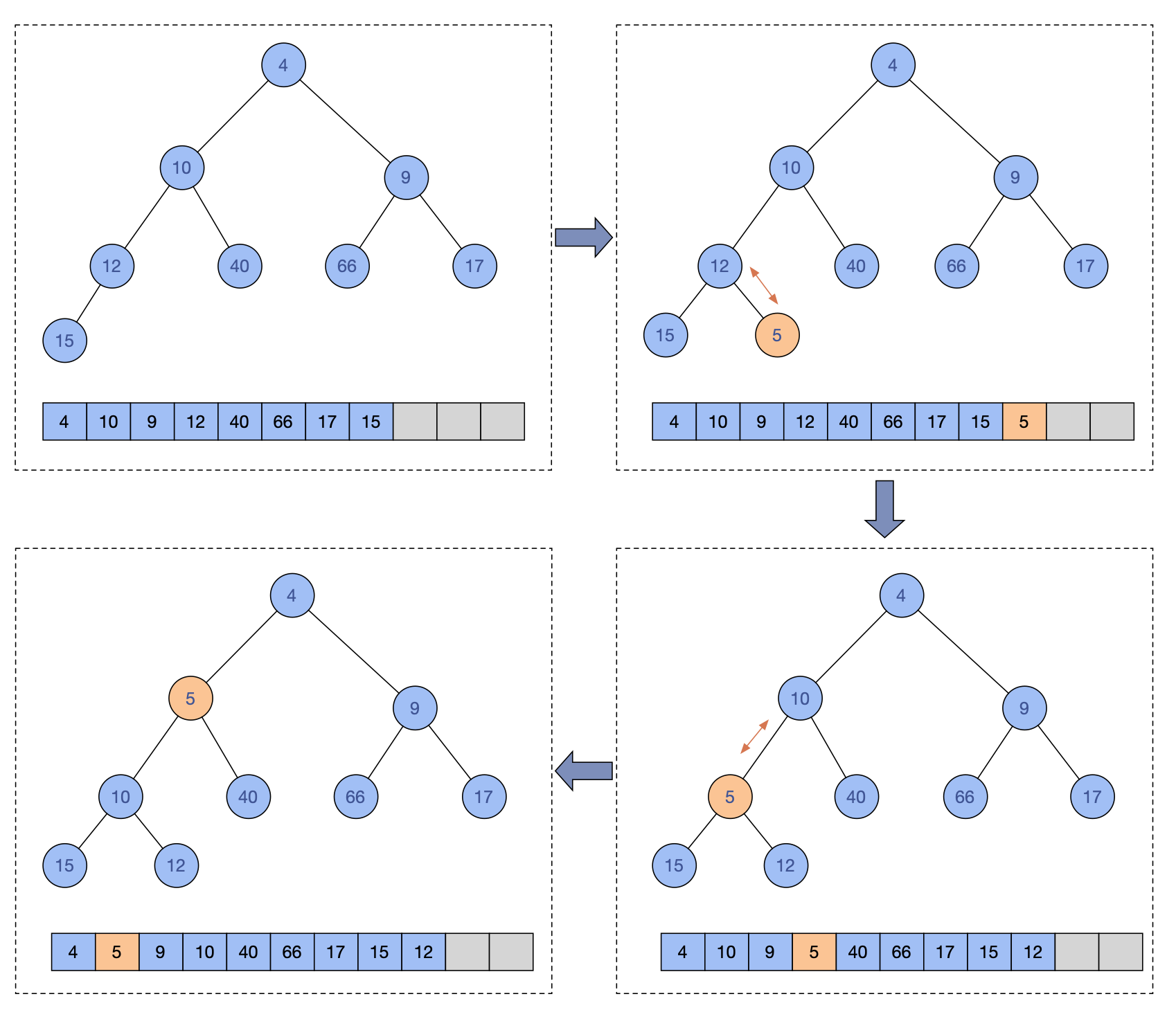
插入元素的时候先判断了是否需要扩容,扩容在后面会提到,核心的逻辑是,元素先加到队尾,然后进行siftUp,使得新加入的元素调整成符合小顶堆的要求。
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
// 扩容
grow(i + 1);
// 最后一个位置下标加1
size = i + 1;
if (i == 0)
// 第一个元素情况
queue[0] = e;
else
// 节点从尾部加入,然后上移操作,直到保持堆处于正确状态
siftUp(i, e);
return true;
}
PriorityQueue支持元素实现Comparable,也支持初始化时传入一个Comparator作为比较算子。所以siftUp区分了两种实现,都是差不多的,选一个分析一下,siftUp是调整堆的核心操作,这个操作是把元素从参数k位置开始,和父节点进行比较,如果比父节点小,就和父节点交换,不断重复,直到父节点比自己大或等于,或者自己已经移动到根节点才停止。
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
// 父节点下标
int parent = (k - 1) >>> 1;
// 父节点值
Object e = queue[parent];
// 新增值大于父节点,那就符合成为这个父节点下子节点的要求
if (key.compareTo((E) e) >= 0)
break;
// 当前的父节点下移动
queue[k] = e;
// k改为父节点下标,下一轮循环从父节点开始
k = parent;
}
// 退出循环出来的,直接把值赋值给k下标即可
queue[k] = key;
}
每增加一个元素,PriorityQueue就需要调整一次以确保小顶堆的排序,写操作是有一定消耗的。
结合siftUp方法实现,再看一个插入一个元素的流程示意图:
查询元素
查询操作其实就是遍历数组找出元素,不要感到惊讶,就是这么朴素无华,本质原因PriorityQueue的特性并不是快速定位某个元素的。是这里可能会有误解以为堆这种数据结构保证了左节点必然小于或大于右节点这样的规则,那么查找一个值可以是更有效率的二分法方式,而事实上堆并没有这个特性,所以查询一个元素就需要直接遍历全部元素。
public boolean contains(Object o) {
return indexOf(o) != -1;
}
private int indexOf(Object o) {
if (o != null) {
// 遍历数组
for (int i = 0; i < size; i++)
// 比较查出想要找的元素
if (o.equals(queue[i]))
return i;
}
// 如果不存在就返回-1 contains判断是否不等于-1
return -1;
}
这样就知道contains操作实践复杂度是O(n),数据量大的话需要考虑避免使用。
删除元素操作
删除操作的流程:先查出元素在数组中的下标,然后从数组中删除这个下标的元素,最后,此时这个堆中间就可能出现缺失一个元素的情况,所以需要进行调整这个堆的元素最终成为一个正确的小顶堆。前面查找删除比较简单,关键是调整环节,下面详细解析一下这部分的源码:
public boolean remove(Object o) {
int i = indexOf(o);
if (i == -1)
return false;
else {
removeAt(i);
return true;
}
}
private E removeAt(int i) {
// assert i >= 0 && i < size;
modCount++;
// 数组最后一个元素的下标
int s = --size;
if (s == i) // removed last element
queue[i] = null;
else {
// 数组最后一个元素的值
E moved = (E) queue[s];
// 将数组最后一个元素从位置上删除
queue[s] = null;
// 将元素从要删除的数组下标i位置开始下移
// 下移只能在i下标是非叶子节点情况,并且子节点大于移动的值才会发生下移
siftDown(i, moved);
// 这个判断表示如果i下标已经是叶子节点而没有下移,或者i下标不是叶子节点在和子节点比较后而无需下移
if (queue[i] == moved) {
// 既然没有进行下移,那么说明在i这个位置上,放moved这个值是最小的,但是还不能保证和自己的父节点比是不是大于等于的,所以需要进行上移的操作
siftUp(i, moved);
// 上移结束后,如果i下标的元素和moved不一致证明在这个i下标之前的元素已经因为上移操作有了变化,而返回这个从数组最后取得的元素
if (queue[i] != moved)
return moved;
}
}
return null;
}
从一个堆中删除一个元素后,就会出现一个空缺的位置,接下去怎么操作呢?源码中是将数组中最后一个元素来填补这个空缺,然后从这个元素开始进行下移(siftDown)操作,如果没有移动,就进行上移(siftUp),无论上移还是下移都是在通过元素的交换最终确定填补的元素应该处于的的适当位置,所以最终不会出现空缺的情况,并且能够调整出一个正确的新堆。
和siftUp相似,siftDown操作也是区分两种方式,这里也只挑一个看就行了。
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
// 这个half是最后一个节点无符号右移计算得到
// 这个计算得到的位置是叶子节点的开始位置,所以下面的while条件是小于这个位置
int half = size >>> 1; // loop while a non-leaf
// 因为这里是操作下移,如果已经是叶子节点就没有下移的必要了
while (k < half) {
// 自己左侧子节点下标
int child = (k << 1) + 1; // assume left child is least
// 自己左侧子节点值
Object c = queue[child];
// 自己右侧子节点下标
int right = child + 1;
// 右节点可能没有,比如左节点已经是数组最后一个值了,所以判断了一下right < size
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
// 如果如果左节点值大于右节点值,就把更小的右节点值赋值给c
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
// 如果自己比左节点值小,说明不能下移了,就退出循环
break;
// 执行到这里,说明自己作为父节点,并不比子节点小
// 那么就把前面从左右子节点中找出来最小的值赋值给k下标的位置
queue[k] = c;
// k值变更为较小的值的下标
k = child;
}
// 循环退出后,k下标的位置放自己
queue[k] = key;
}
siftDown它的核心逻辑是将一个元素往树的下层进行比较,找到比自己小的就进行交换。注意,这种比较是需要比较自己子节点的左右节点的,毕竟这棵树只保证父节点小于子节点,并不保证左右的节点大小顺序。
图例示意一个删除操作:
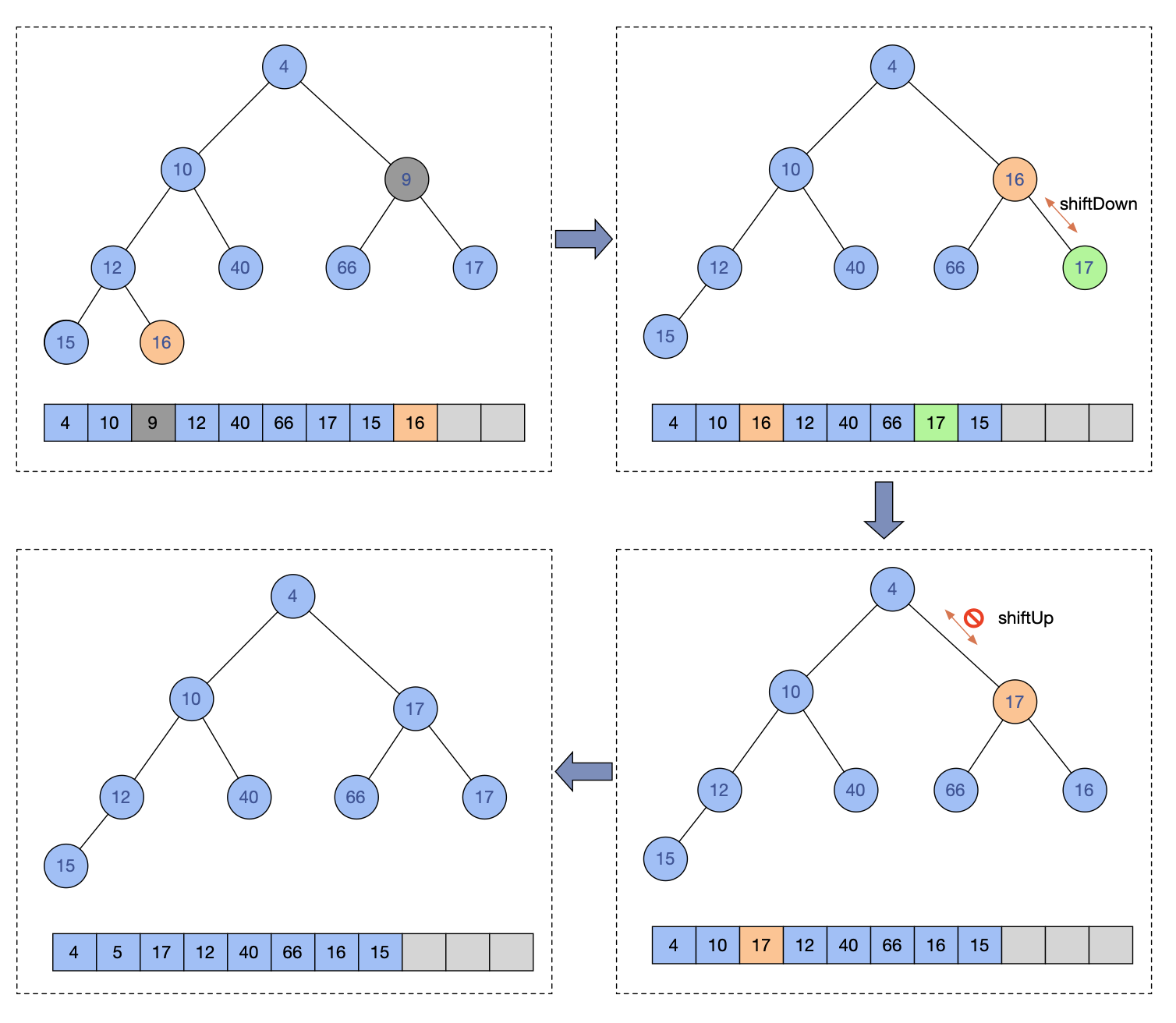
删除9值节点,把16节点先移动到删除的下标,然后进行shiftDown,发现是右节点更小,就进行交换,然后删除下标节点进行shiftUp操作,发现不能在上移,就结束操作。
获取顶部元素
poll是肯定要用的方法,毕竟花了这么大劲把最小值排到了根节点上。
可是取出根节点的元素,又会出现少一个元素的情况,按照上面的经验,肯定是那数组最后的元素,放到根节点上来,然后进行下移操作就行了,因为已经是从根上开始,所以没有上移的情况再需要考虑了。
public E poll() {
// 空的情况
if (size == 0)
return null;
// 数组有值的最后一个下标
int s = --size;
modCount++;
// 根节点,返回值
E result = (E) queue[0];
// 最后一个元素
E x = (E) queue[s];
// 清空根节点
queue[s] = null;
if (s != 0)
// 下移
siftDown(0, x);
return result;
}
扩容
在插入数据的时候就会先判断是否需要扩容,容量不足是容器都需要面对的问题,毕竟作为专业选手,合理使用资源是时刻需要注意的。
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
// 64区分两种扩容数量策略
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
// 虽然是无限优先级队列,最大的容量溢出还是要控制的
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
// minCapacity 是size+1获得 如果此时size已经是MAX_VALUE 那么minCapacity会变成负数,溢出抛出OutOfMemoryError异常
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
如果想用大顶堆怎么办?
非常简单,比较上元素实现Comparable的时候反着来就行了。
关于如何获得顺序数据
我们已经清楚PriorityQueue使用数组存储,按照数组下标顺序便利并不是顺序的,这一点是显而易见的。而不断获取头节点并删除,也可以遍历一个ProirityQueue,这种遍历方式就可以保证这个数据结构的顺序输出,因为ProirityQueue在操作的时候始终保证一点,头节点是最小元素。
虽然这一点过于细节,因为有助于更好的理解,就展开一下,如果通过迭代器遍历的时候,相当对数组从头到尾进行遍历,所以并不是确保顺序性,如果使用poll()遍历,那么是确保了顺序性,因为每次poll的时候相当于都需要调整出最小值到头节点上。
第一种遍历方式:
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(10);
for (int i = 10; i >=2; i--) {
priorityQueue.add(i);
}
for (Integer e : priorityQueue) {
System.out.print(e + ",");
}
}
输出结果:2,3,5,4,8,9,6,10,7,
第二种遍历方式:
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(10);
for (int i = 10; i >=2; i--) {
priorityQueue.add(i);
}
Integer t;
while ((t = priorityQueue.poll()) != null) {
System.out.print(t + ",");
}
}
输出结果:2,3,4,5,6,7,8,9,10,
排序复杂度:
这里堆PriorityQueue排序的复杂度做一个简单分析,建堆后,通过poll遍历一个有序的元素列表,这个过程每次都是把最后的元素放到根节点上进行下移,排序过程的时间复杂度是O(nlogn),建堆的时间复杂度O(n),整体的时间复杂度O(nlogn)。
但是我们在排序过程中每次都是把最后面的元素移动到根节点,理论上来说这个移动的元素必然是需要移动的,这一点是有优化空间的。可以看出,堆的排序交换次数是偏多的。
使用场景
1,高性能定时器 这个在jdk中的ScheduledExecutorService有使用,以后分析可以关联起来。
2,Top K 问题,实际业务研发会使用到。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号